오렐리앙 제롱, 『Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow』, 박해선, 한빛미디어-OREILLY(2020), p352-410.
Learned
퍼셉트론 (Perceptron)
- 퍼셉트론(Perceptron): 가장 간단한 인공 신경망 구조 중 하나
- TLU(threshold logic unit) or LTU(linear threshold unit)를 기반으로함
- TLU는 입력의 가중치 합을 계산 한 뒤, 계단 함수를 적용하여 결과를 출력
- 층이 하나뿐인 TLU로 구성됨
- 다층 퍼셉트론(Multi-Layer Perceptron; MLP)
- 퍼셉트론을 여러 개 쌓아올린 신경망
- XOR 문제를 풀 수 있음
가중치 (Weight)
- 은닉층의 연결 가중치를 랜덤하게 초기화하는 것이 중요
- 가중치와 편향을 0으로 초기화하면 층의 모든 뉴런이 완전 일치함
- 가중치 랜덤 초기화 -> 대칭성이 깨지므로 역전파가 전체 뉴런을 다양하게 훈련 가능
- ex. keras.Dense 층은 연결 가중치를 무작위로 초기화, 편향은 0으로 초기화
- 클래스 샘플 가중치
fit()메서드 호출 시,class_weight매개변수로 조정- 적게 등장하는 클래스는 높은 가중치를 부여, 많이 등장하는 클래스는 낮은 가중치를 부여
- 샘플별 가중치
fit()메서드 호출 시,sample_weight매개변수로 조정- 어떤 샘플은 전문가에 의해 레이블이 할당되고, 다른 샘플은 크라우드소싱 플랫폼을 사용해 레이블이 할당되었을 때 도움됨 (전자에 높은 가중치를 부여)
튜닝 (Tuning)
- 검증 손실이 여전히 감소하면 모델이 아직 수렴하지 않은 것으로 볼 수 있음
- 모델 성능에 만족되지 않다면, 하이퍼파라미터를 튜닝해야됨
- 학습률(learning rate)을 가장 먼저 확인
- 다른 옵티마이저로 테스트
- 다른 하이퍼파라미터를 바꾼 경우 학습률을 다시 튜닝해야됨
- 층 수, 뉴런 수, 활성화 함수를 튜닝
- 학습률
- 가장 중요한 하이퍼파라미터
- 최적의 학습률은 최대 학습률의 절반 정도
- 좋은 학습률을 찾기 위한 방법 예시
- 매우 낮은 학습률 (ex. )에서 시작하여 점진적으로 매우 큰 학습률 (ex. 10)까지 수백 번 반복하여 모델을 훈련하는 것
- 일반적으로 상승점보다 약 10배 낮은 지점이 최적의 학습률
- 배치 크기
- 모델 성능과 훈련 시간에 큰 영향을 미칠 수 있음
- 큰 배치 크기를 사용한다는 것은 GPU를 효율적으로 활용할 수 있다는 것
- 실전에서 큰 배치를 사용하면 훈련 초기에 종종 불안정하게 훈련됨
- 학습률 예열(warming up)을 사용하면 큰 배치 크기를 시도할 수 있음
- 만약 훈련이 불안정하거나 성능이 별로라면 작은 배치를 사용하는 것을 권장
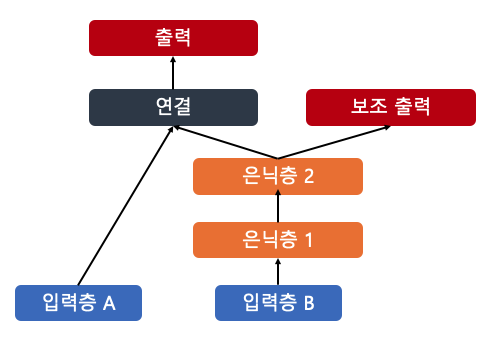
모델링
- 보조 출력
- 하위 네트워크가 나머지 네트워크에 의존하지 않고 그 자체로 유용한 것을 학습하는지 확인 가능
- 각 출력은 자신 만의 손실 함수가 필요 -> 모델 컴파일 시, 손실 리스트 전달
- keras는 나열된 손실을 모두 더하여 최종 손실을 구해 훈련에 사용
output = keras.layers.Dense(1, name="main_output")(concat)
aux_output = keras.layers.Dense(1, name="aux_output")(hidden2)
model = keras.models.Model(inputs=[input_A, input_B],
outputs=[output, aux_output])
model.compile(loss=["mse", "mse"], loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(learning_rate=1e-3))
history = model.fit([X_train_A, X_train_B], [y_train, y_train], epochs=20,
validation_data=([X_valid_A, X_valid_B], [y_valid, y_valid]))- 서브클래싱
- 동적인 구조가 필요할 때 활용
- 명령형(imperative) 프로그래밍 스타일
keras.Model상속call메서드를 통해 원하는 계산 사용 가능- 유연성이 높아짐
- 텐서플로 저수준 연산을 사용 가능
- 모델 구조가
call메서드 안에 숨겨 있기 때문에, 모델을 저장하거나 복사할 수 없음
- 동적인 구조가 필요할 때 활용
- 전이 학습 (transfer learning)
- 네트워크를 처음부터 훈련하는 경우는 거의 없음
- 비슷한 작업에서 가장 뛰어난 성능을 낸, 사전 훈련된 네트워크 일부를 재사용하는 것이 일반적
- 훈련 속도는 훨씬 빠르고, 데이터도 훨씬 적게 필요함
Log
- 훈련 로그는 프로파일링 트레이스(profiling trace) 파일도 포함함
- 전체 디바이스에 걸쳐서 모델 각 부분에 얼마나 시간이 소요되었는지 보여줌
- 성능 병목 지점을 찾는데 큰 도움을 줌

Data Scientist, Data Analyst