
회사에서 IOT 데이터를 스트리밍하기 위하여 Kafka를 사용하고 있다.
DevOps Engineer로서 운영 관점에서 Kafka를 잘 사용하는 방법을 공부하고자 카프카 시리즈를 시작한다!
첫 게시물이니
카프카의 아주 아주 기본적인 개념들을 정리해 보고자 한다!🙂
프로듀서, 컨슈머, 브로커, 주키퍼
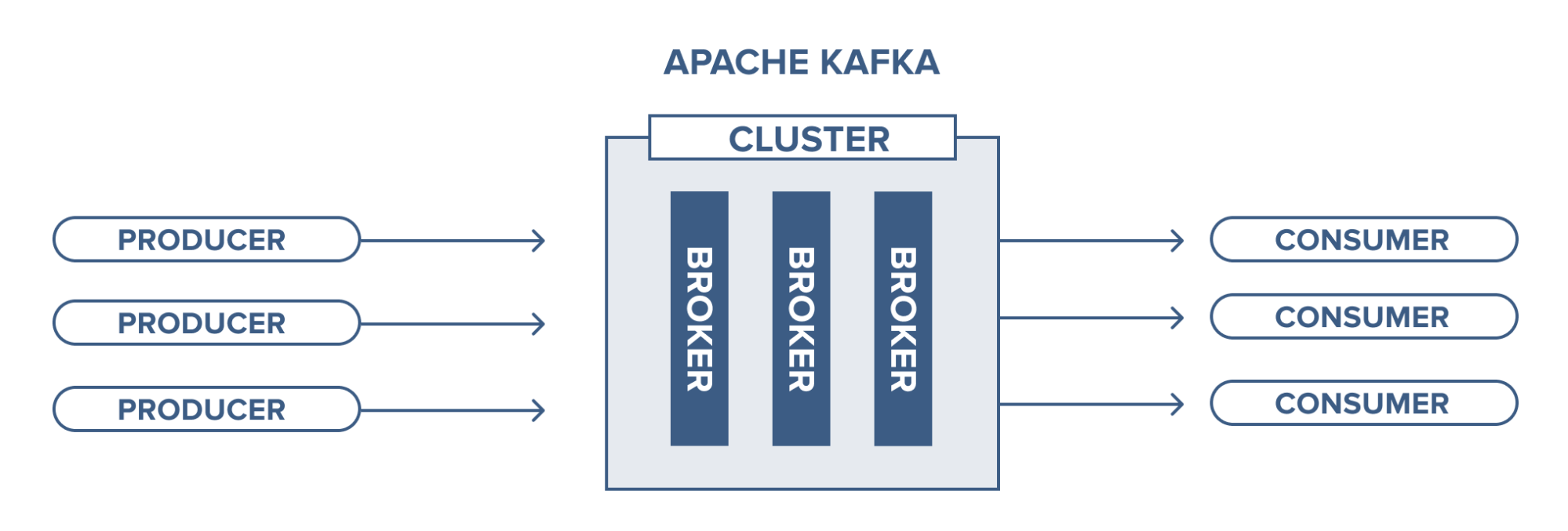
- 프로듀서 :
- 카프카에서 메세지를 생성하고, 해당 메세지를 카프카 클러스터에 전송하는 클라이언트
- 한 개, 혹은 여러개의 토픽으로 메세지를 보낼 수 있다.
- 컨슈머 :
- 카프카에서 메세지를 읽는 클라이언트
- 한 개, 혹은 여러개의 토픽에서 메세지를 가져올 수 있다.
- 파티션마다 한 컨슈머만 데이터를 가져갈 수 있다.
- 브로커 :
- 카프카 애플리케이션이 설치된 서버를 의미한다.
- 주키퍼 :
- 브로커 health check 등 카프카 클러스터의 상태를 관리한다.
토픽, 파티션, 오프셋
- 토픽 :
- 카프카는 토픽(topic)이라는 곳에 데이터를 저장한다.
- 비유하자면 이메일 주소와 비슷함
- 토픽의 이름은 카프카 내에서 고유하다.
- 파티션 :
- 토픽의 병렬처리를 위해 여러개의 파티션(partition)이라는 단위로 나뉜다.
- 카프카에서는 파티셔닝을 통해 단 하나의 토픽이라도 높은 처리량을 수행할 수 있다.
- 파티션 번호는 0부터 시작
토픽을 생성할 때 파티션 수를 설정하는데, 초기 생성 후 얼마든지 늘릴 수 있지만 절대로 줄일 수 없다.
따라서 생성할 때 최대한 작게 생성한 후, 메세지 처리량이나 컨슈머의 LAG 등을 모니터링하면서 조금씩 늘려가는 방법이 가장 좋다.
컨슈머의 LAG :
프로듀서가 보낸 메세지 수(카프카에 남아 있는 메세지 수) - 컨슈머가 가져간 메세지 수따라서 LAG이라는 지표를 통해 컨슈머에 지연이 없는지 확인할 수 있다.
- 오프셋 :
- 파티션의 메세지가 저장되는 위치
- 순차적으로 증가하는 숫자(64비트의 정수)형태이다.
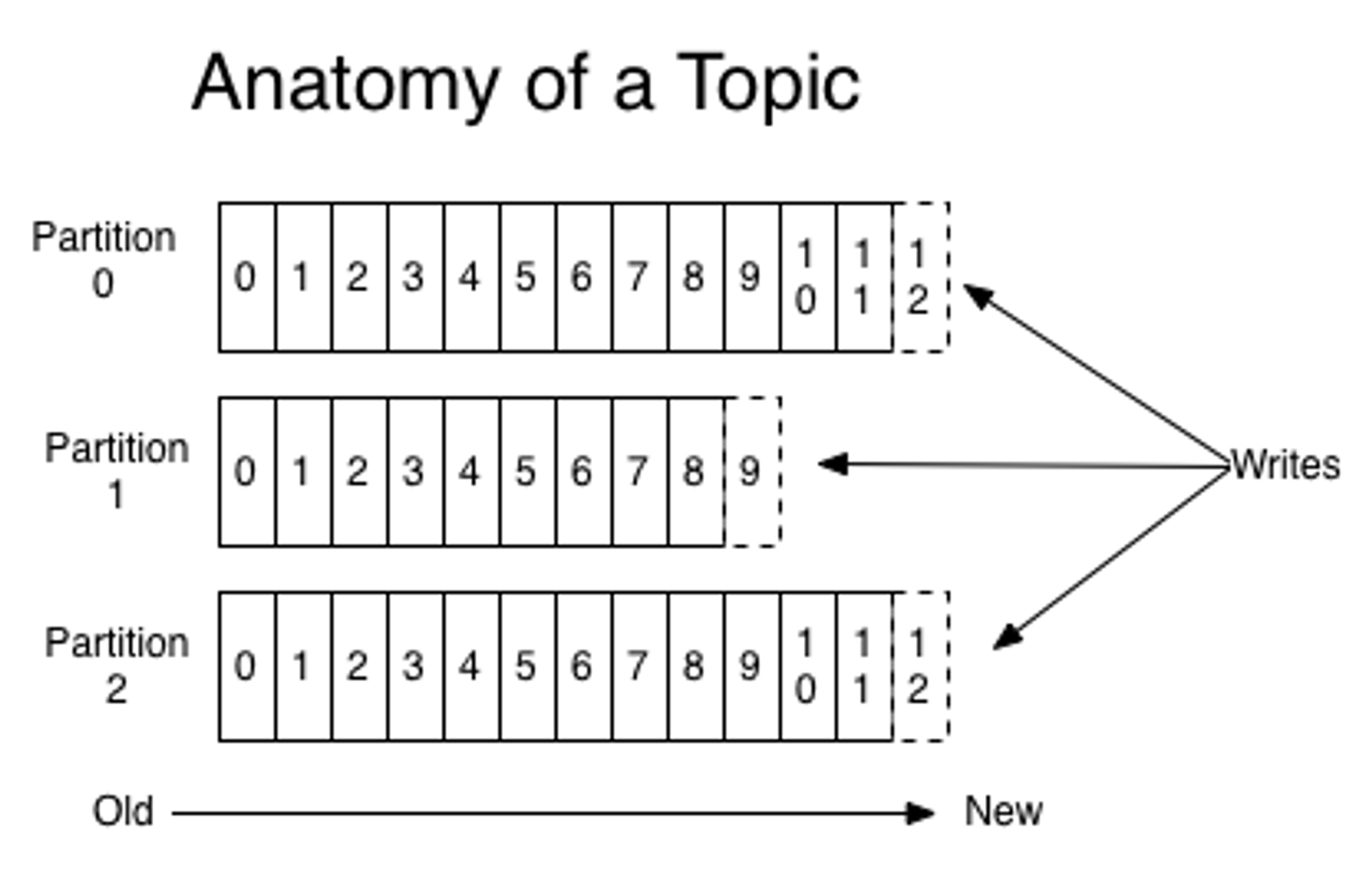
- 위 그림에서 1개의 토픽이 3개의 파티션에 나눠져있다.
- 프로듀서로부터 전송되는 메세지들의 쓰기 동작이 각 파티션별로 이뤄진다.
- 파티션마다 순차적으로 증가하는 숫자들이 바로 오프셋이다.
- 카프카에서는 오프셋을 통하여 메세지의 순서를 보장하고 컨슈머에서는 마지막으로 읽은 위치도 기억할 수 있다.
세그먼트
-
세그먼트 :
- 프로듀서에 의해 브로커로 전송된 메세지는 토픽의 파티션에 저장되며, 각 메세지는 세그먼트(segment)라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장된다.
- 카프카에 모든 메세지를 단일 파일로 저장하는 것이 아니라, 세그먼트라는 단위로 나뉘어서 저장된다.
-
프로듀서는 항상 활성 세그먼트(active segment)에 write를 한다.
-
세그먼트 사이즈 limit에 도달하면 새로운 세그먼트 파일이 활성화된다.
-
세그먼트 파일의 이름은 첫번째 메세지의 파일 이름을 사용하여 생성된다.
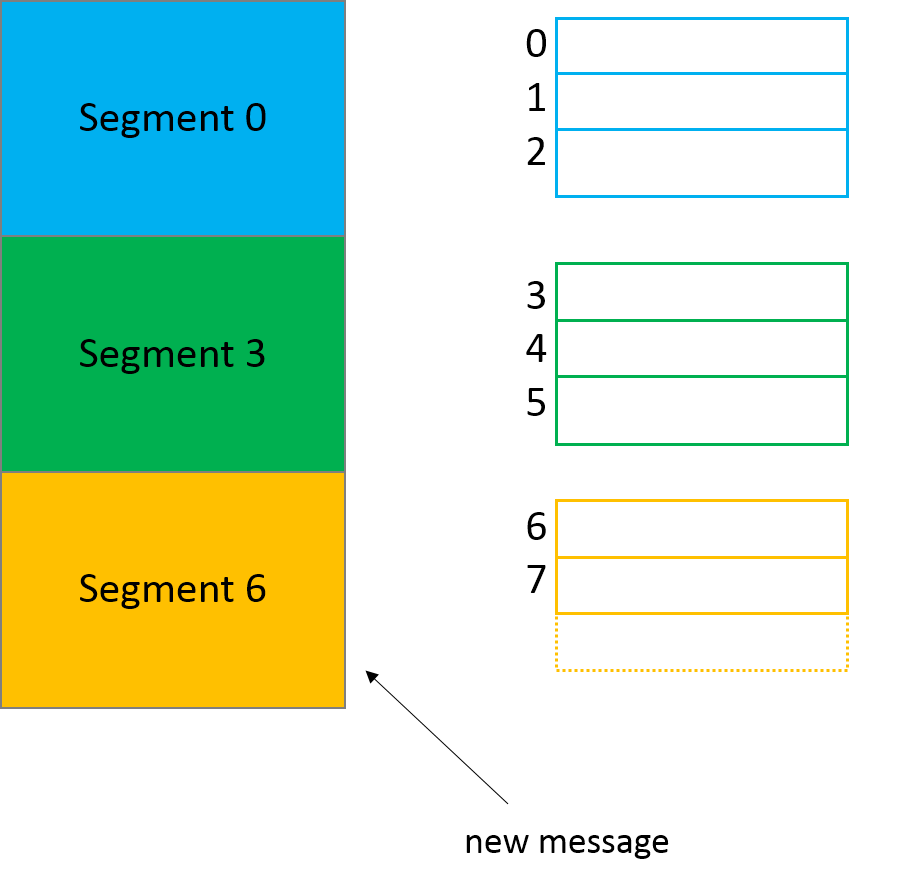
- 위 그림을 살펴보면 세그먼트0에는 오프셋 0~2의 메세지가 있고,
- 현재 활성 세그먼트는 6으로, 첫번째 메세지의 오프셋이 6이다.
리플리케이션
- 리플리케이션 :
- 카프카에서는 가용성을 위해 리플리케이션(Replication)이라는 기능을 제공한다.
- 각 메세지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에게 분산시키는 동작을 의미한다.
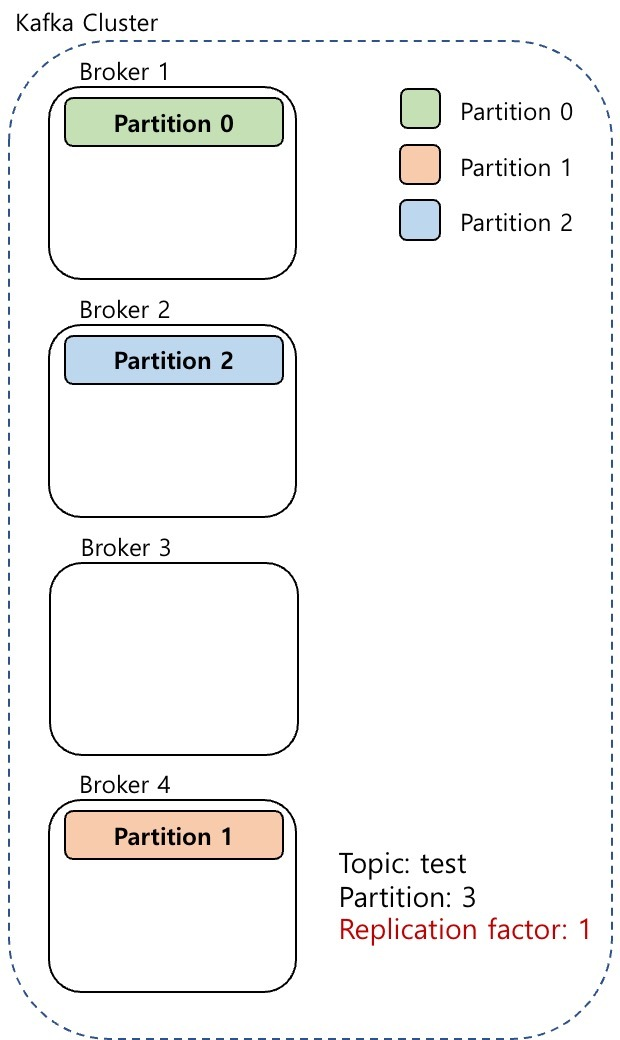
- 위 그림은 test라는 토픽에 파티션이 3개고 리플리케이션이 1개일 때의 예시이다.
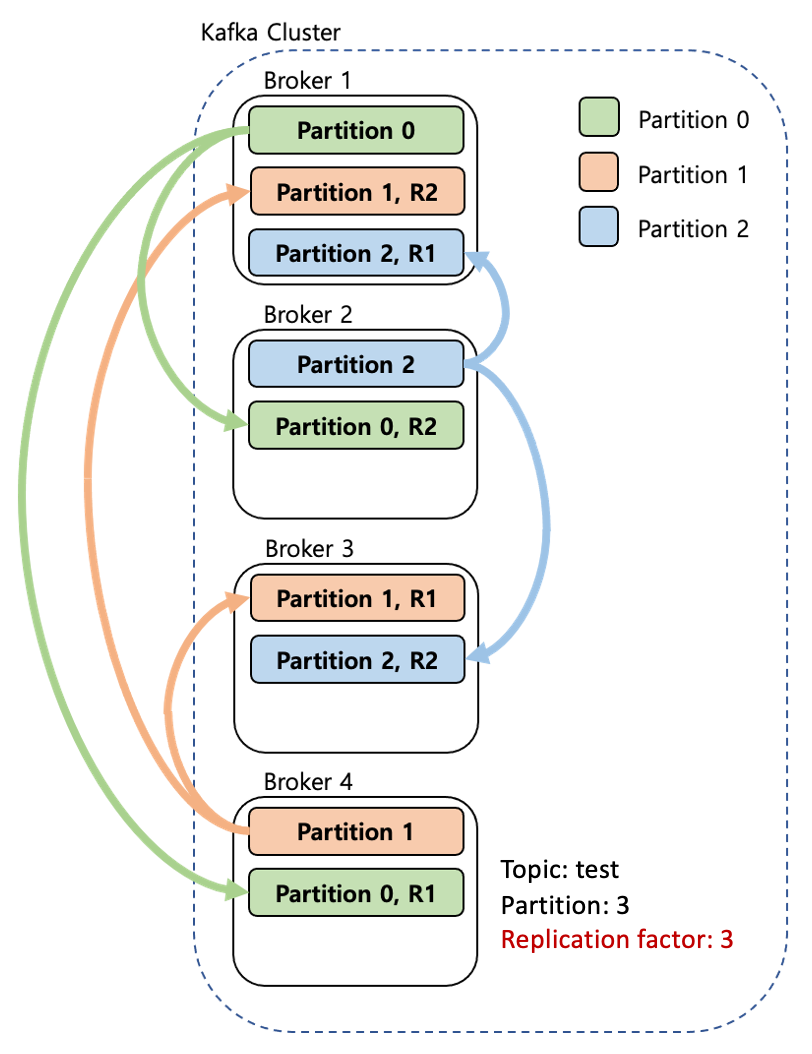
- 위 그림은 리플리케이션을 3으로 설정했을 때의 그림이다.
- 파티션이 3개씩 리플리케이션 되었다.
리플리케이션을 설정할 때 아래와 같은 trade-offs를 고려해야 한다.
- 장점 : 데이터 가용성이 훨씬 증가한다.
- 단점 : 각 복제본마다 추가 저장 용량이 필요하므로 네트워크 트래픽과 데이터 디스크 사용량이 증가될 수 있다.
상황에 따라서 복제에 대한 오버헤드를 줄여 최대한 브로커를 효율적으로 사용하는 것이 권장된다.
- 테스트 환경 : 리플리케이션 팩터의 수 1로 설정
- 운영 환경(로그성 메세지, 약간의 유실 허용) : 리플리케이션 팩터의 수 2로 설정
- 운영 환경(유실을 허용하지 않음) : 리플리케이션 팩터의 수 3로 설정
출처 :

킹왕짱 Cloud Engineer 지니박박구리 블로그