카프카란?

아파치 카프카는 링크드인에서 처음 개발되었고, 대용량, 대규모 메시지 데이터를 빠르게 처리하도록 개발된 메시징 플랫폼이다.
데이터 파이프라인을 구축할 때 가장 많이 고려되는 시스템 중 하나이다.
Netflix, Airbnb, 카카오, 네이버 등의 주요 기업들에서 사용하고 있다.
카프카의 탄생 배경
카프카의 탄생배경을 알면 카프카를 한번에 이해할 수 있다.
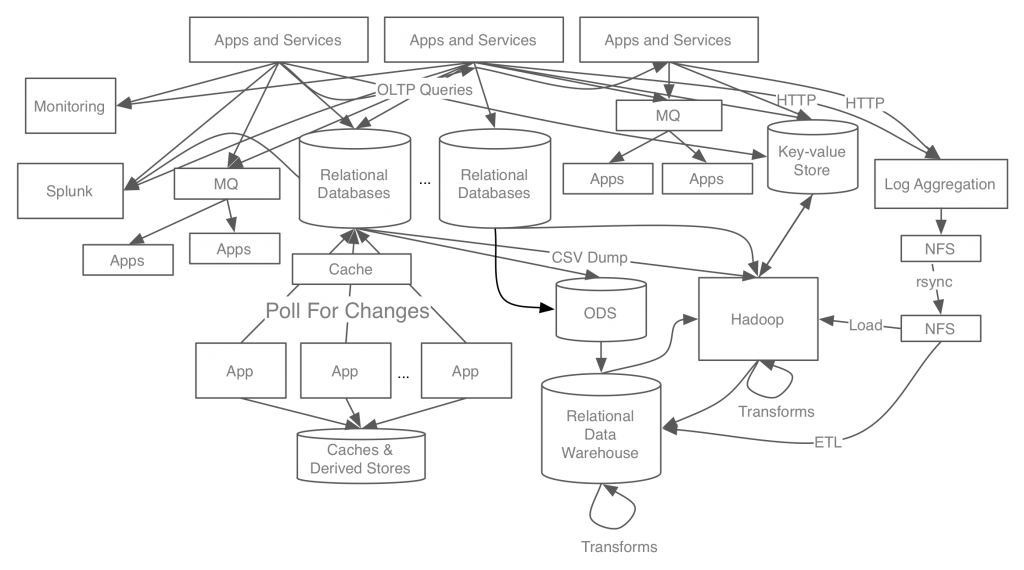
위 그림은 카프카가 개발되기 전 링크드인의 과거 데이터 시스템 구성도이다.
자세히 보지 않더라도 복잡해 보인다.
수년간 이러한 구조가 무분별한 확산되어 어려움을 겪은 후
2010년 데이터 스트림 모델링에 초점을 맞춘 시스템 구축을 위해 카프카 프로젝트가 시작된다.
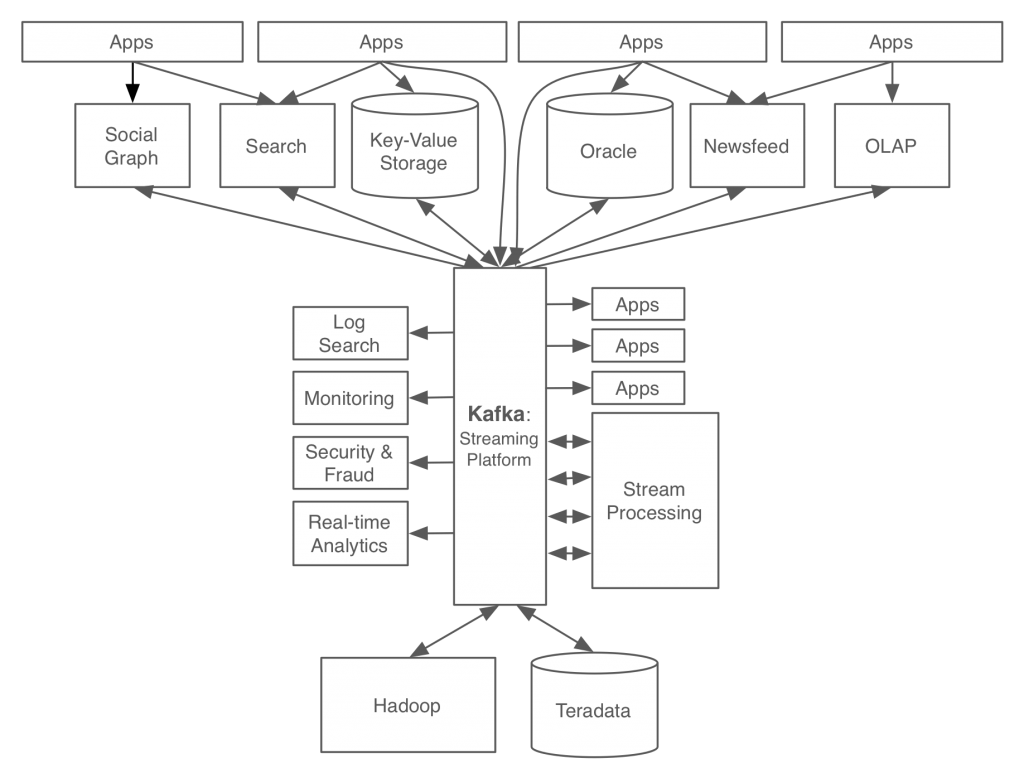
위 그림은 카프카를 이용한 링크드인의 데이터 처리 시스템이다.
카프카를 적용한 결과, 서비스 아키텍처가 예전과는 비교할 수 없을정도로 깔끔해진 것을 확인할 수 있다.
사내에서 발생하는 모든 이벤트/데이터 흐름을 중앙에서 관리하고 있다.
이와같이 새로운 데이터 처리 시스템에서는, 링크드인 사용자가 프로필을 업데이트하면이 정보가 바로 카프카로 전달된다.
카프카의 도입과 함께 링크드인은 놀랄만한 규모로 성장했고, 오늘날 약 1조개 이상의 메세지를 하루에 처리하고 있다.
카프카의 동작 방식
메세징 시스템
카프카는 기본적으로 메세징 서버로 동작한다.
따라서 카프카의 동작 방식을 알기 위해서는 메세징 시스템에 대한 이해가 필요하다.
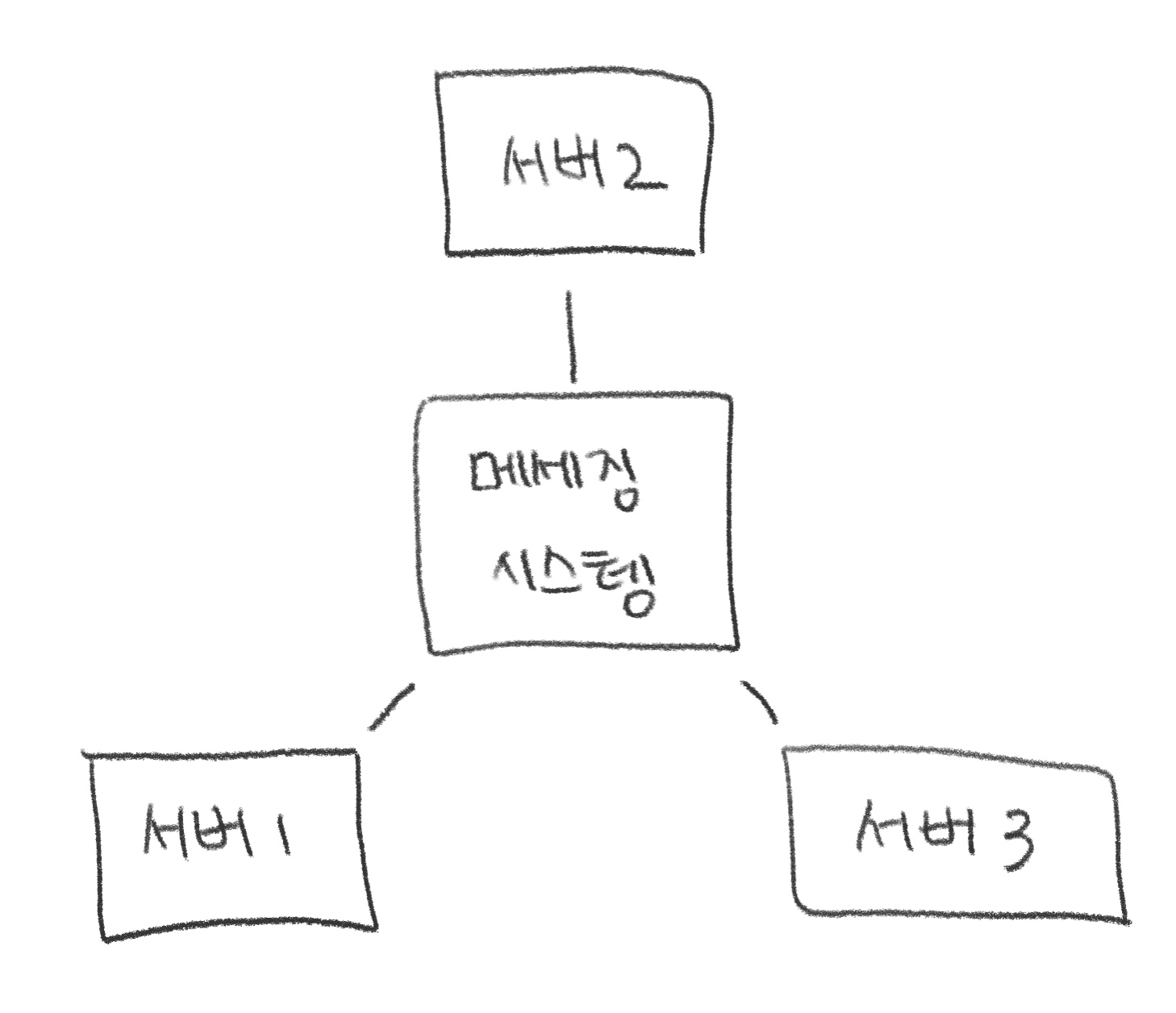
하나 이상의 데이터 소스로부터 데이터를 받는 애플리케이션을 떠올려보자.
이 경우 메세징 시스템은 서로 다른 프로그램끼리 정보를 교환하기 위한 통합 채널로 활용이 가능하다.
애플리케이션메세징 시스템을 설계하는 경우 유념해야 할 원칙이 있다.
-
느슨한 경계
어느쪽에서 변경사항이 생기더라도 다른 프로그램에서는 영향을 받지 않아야한다. 상호간에 의존성을 최소화 해야한다는 것이다. -
공용 인터페이스 정의
애플리케이션 간에 데이터 교환을 위해 공용으로 규정된 데이터 형식을 보장한다. -
응답 속도
메세지 전송 -> 수신에 소요되는 시간
심각한 지연은 메세지 손실을 발생시킬 수 있다. -
신뢰성
일시적인 가용성 문제가 발생해도 정보를 교환하는 관련 애플리케이션에 영향을 주지 않는 것을 말한다.
Publish/Subscribe (펍/섭) 시스템
메세지라고 불리는 데이터 단위를 Publisher(보내는측)에서
카프카에 토픽이라고 불리는 데이터 저장소에 저장하면,
Subscriber(가져가는 측)이 원하는 토픽에서 데이터를 가져갑니다.
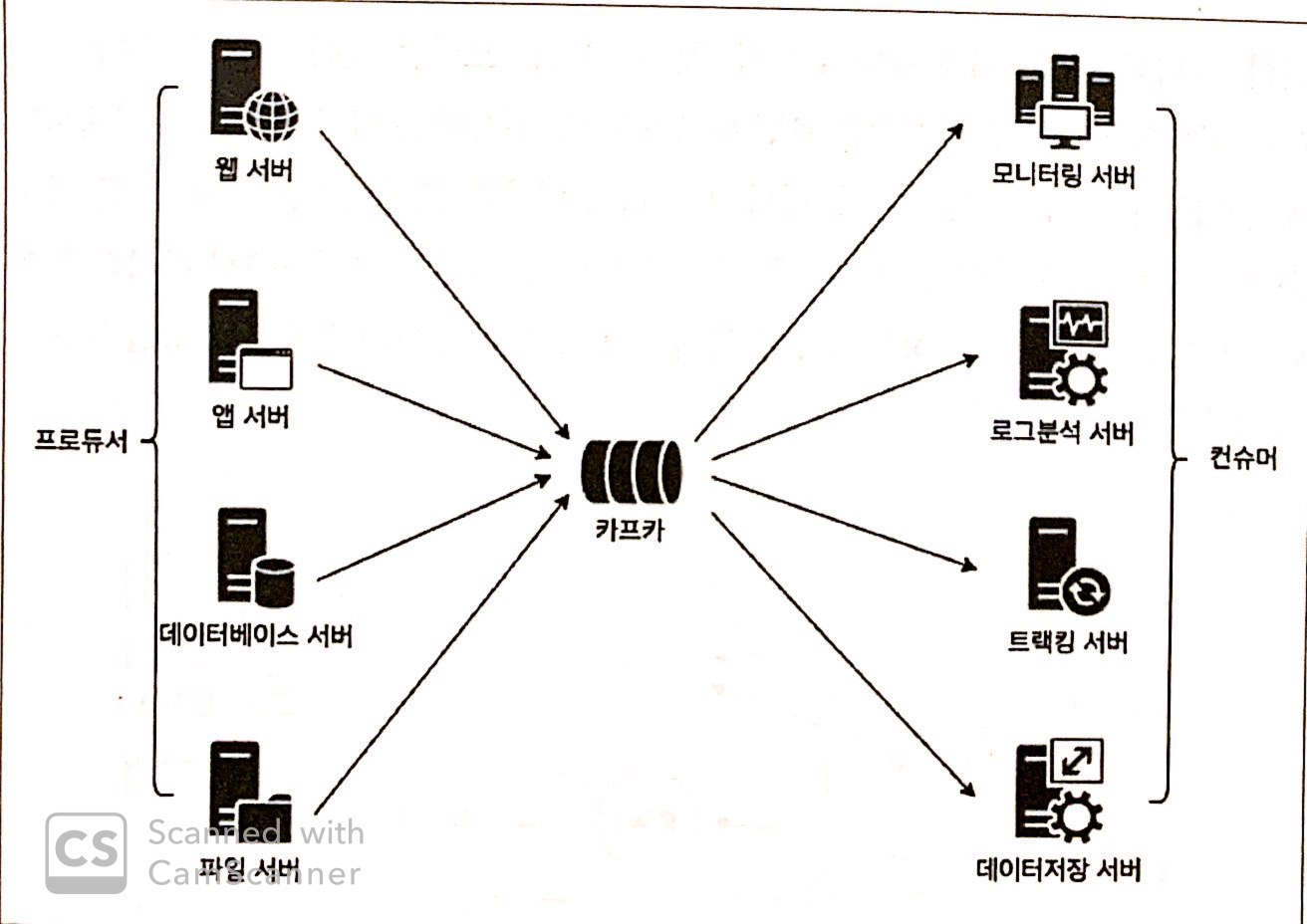
중앙에 메세징 시스템 서버(카프카)를 두고 메세지를 보내고(publish) 받는(subscribe) 형태의 통신을 펍/섭 모델이라고 한다.
멀티 프로듀서, 멀티 컨슈머
카프카는 하나의 토픽에 여러 프로듀서 혹은 컨슈머들이 접근 가능한 구조이다.
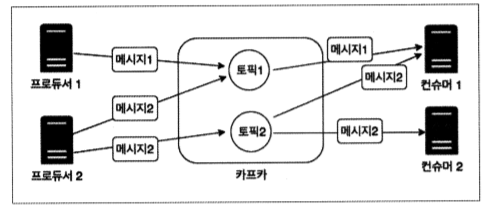
카프카의 구조
데이터 모델
- 토픽 : 메세지를 받을 수 있도록 논리적으로 묶은 개념
- 파티션 : 토픽을 구성하는 데이터 저장소, 수평 확장이 가능한 단위
카프카 논리적 구조
-
토픽의 모든 메세지는 바이트의 집합(배열)이다.
-
프로듀서는
카프카 큐에 정보를 저장, 로그 선행 기입 파일 마지막에 메세지를 추가한다. -
컨슈머는
토픽 파티션에 있는 로그 파일에서 메세지를 가져온다. -
카프카 클러스터는 기본적으로 하나이상의 서버 노드(node)로 구성된다.
카프카 물리적 구조
-
위 그림은 노드로 구성된 카프카 클러스터이다.
-
카프카 클러스터는 다중 브로커로 구성된다.
각 브로커는 stateless하지만 주키퍼를 사용해 상태 정보를 유지한다. -
토픽 파티션에는 리더 브로커가 하나씩 있고, 0개 이상의 팔로워가 있다.
리더는 해당하는 파티션의 읽기, 쓰기 요청을 관리한다.
참고 링크
