원본 이미지와 배경이 서로 비율이 다른 경우, 둘 중의 한 쪽이 늘어지는 단점이 있는데요. 이를 해결하여 공유드립니다.
bg_img로 배경(background) 불러오기
label의 0~20까지의 값을 입력합니다. (사람==15)
img_orig = cv2.imread(img_path)
bg_img_orig = cv2.imread(bg_img_path) # 배경 이미지를 읽어옵니다
img_resized, seg_map = MODEL.run(img_orig)
seg_map = np.where(seg_map == label, label, 0) # 예측 중 label만 추출
img_mask = seg_map * (255/(seg_map.max() + 1e-10)) # 255 normalization, divisionerror 방지
img_mask = img_mask.astype(np.uint8)배경의 가로에 맞출지, 세로에 맞출지 설정하기
두 이미지의 사이즈가 다르다면,
- 배경에 맞출 것인지 원본에 맞출 것인지
- 가로에 맞출 것인지 세로에 맞출 것인지
를 결정해야 합니다.
저는 원본 이미지를 배경에 맞춰 확대/ 축소하기로 선택했고, 가로에 맞출지 세로에 맞출지는
여러 시도 끝에 (배경_가로/원본_가로) 와 (배경_세로/원본_세로)가 더 작은 쪽에 맞추었습니다.
이는 (배경_가로/배경_세로) 가 (원본_가로/원본_세로)보다 작다면 배경의 가로 사이즈에 맞도록 원본 이미지를 resize하고, 반대의 경우라면 배경의 세로 사이즈에 맞도록 원본 이미지를 resize 한다는 것과 동일합니다
이때, 원본 이미지의 비율에 맞도록
원본 가로, 원본 세로 -> 원본 가로 * (배경 세로 / 원본 세로) , 원본 세로 * (배경 세로 / 원본 세로)
와 같은 처리를 하였습니다.
original_h, original_w = img_orig.shape[:2] # cv2.imread()로 읽어와 height와 width를 저장합니다
bg_h, bg_w = bg_img_orig.shape[:2]
if (bg_h/original_h) >= (bg_w/original_w): # 원본 이미지를 배경 이미지의 height와 width 중 배경/원본이 작은 쪽으로 맞춥니다.
# 원본 이미지: (960, 540), 배경 이미지: (1260, 1080) -> 세로 비: 1260 / 960 = 1.3125, 가로 비: 1080 / 540 = 2 -> 세로 쪽에 맞춥니다.
# 변환 후 이미지 : (1260, 709)
resize_shape = (int(original_h * bg_w / original_w), bg_w)[::-1] # cv2.resize에 인자로 넣을 것이므로
else:
resize_shape = (bg_h, int(original_w * bg_h / original_h))[::-1] # 가로, 세로 순서로 넣어주어야 합니다resize 및 padding 설정
원본과 마스크를 모두 앞에서 결정한 가로/세로에 맞게 resize합니다.
width_diff와 height_diff는 배경의 너비 - 변환된 이미지의 너비, 배경의 높이 - 변환된 이미지의 높이 입니다. 배경의 너비 혹은 높이에 맞춰 resize했으므로, width_diff와 height_diff 둘 중 적어도 하나의 값은 0이 됩니다.
이후 이미지의 위치를 조절할 수 있도록 top_padding과 left_padding을 diff에 ratio를 곱해 설정합니다.
img_mask_up = cv2.resize(img_mask, resize_shape, interpolation=cv2.INTER_LINEAR) # mask와 원본 이미지를 모두 배경에 맞춰 resize합니다
img_orig_up = cv2.resize(img_orig, resize_shape, interpolation=cv2.INTER_LINEAR)
resized_w, resized_h = resize_shape # 가로, 세로 중 한 쪽은 배경 이미지와 동일합니다
width_diff = bg_w - resized_w # 배경 이미지와 변환 후 이미지의 가로 차이입니다
height_diff = bg_h - resized_h # 배경 이미지와 변환 후 이미지의 세로 차이입니다
top_padding = int(height_diff * ratio) # 원본 이미지에서 잘라낸 부분을 정 중앙에 두기 위해 양쪽에 같은 패딩을 줍니다(ratio=0.5)
left_padding = int(width_diff * ratio) # 원본 이미지에서 잘라낸 부분을 정 중앙에 두기 위해 양쪽에 같은 패딩을 줍니다(ratio=0.5)
_, img_mask_up = cv2.threshold(img_mask_up, 128, 255, cv2.THRESH_BINARY)padding 적용 및 이미지 결합
cv2.copyMakeBorder을 사용해 mask와 원본 이미지에 padding을 씌웁니다.
이미를 결합합니다.
borderType = cv2.BORDER_CONSTANT
# top, bottom, left, right
img_mask_up = cv2.copyMakeBorder(img_mask_up, top_padding, height_diff-top_padding, left_padding, width_diff-left_padding, borderType, value=0)
img_orig_up = cv2.copyMakeBorder(img_orig_up, top_padding, height_diff-top_padding, left_padding, width_diff-left_padding, borderType, value=0)
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
plt.imshow(img_mask_color) # 마스크 시각화
plt.show()
bg_img_orig_blur = cv2.blur(bg_img_orig, (blur_level,blur_level)) # blurring kernel size를 뜻합니다.
img_bg_mask = cv2.bitwise_not(img_mask_color)
bg_img_bg_blur = cv2.bitwise_and(bg_img_orig_blur, img_bg_mask)
img_concat = np.where(img_mask_color==255, img_orig_up, bg_img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()함수로 만들기
LABEL_NAMES = [
"background",
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tv",
]
LABEL_ENCODING = {label: idx for idx, label in enumerate(LABEL_NAMES)}
borderType = cv2.BORDER_CONSTANT
def basic_shallow_focus(img_path, label_str, blur_level=13):
label = LABEL_ENCODING[label_str]
img_orig = cv2.imread(img_path)
img_resized, seg_map = MODEL.run(img_orig)
seg_map = np.where(seg_map == label, label, 0) # 예측 중 label만 추출
img_mask = seg_map * (
255 / (seg_map.max() + 1e-10)
) # 255 normalization, divisionerror 방지
img_mask = img_mask.astype(np.uint8)
img_mask_up = cv2.resize(
img_mask, img_orig.shape[:2][::-1], interpolation=cv2.INTER_LINEAR
)
_, img_mask_up = cv2.threshold(img_mask_up, 128, 255, cv2.THRESH_BINARY)
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
img_orig_blur = cv2.blur(
img_orig, (blur_level, blur_level)
) # blurring kernel size를 뜻합니다.
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg_blur = cv2.bitwise_and(img_orig_blur, img_bg_mask)
img_concat = np.where(img_mask_color == 255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
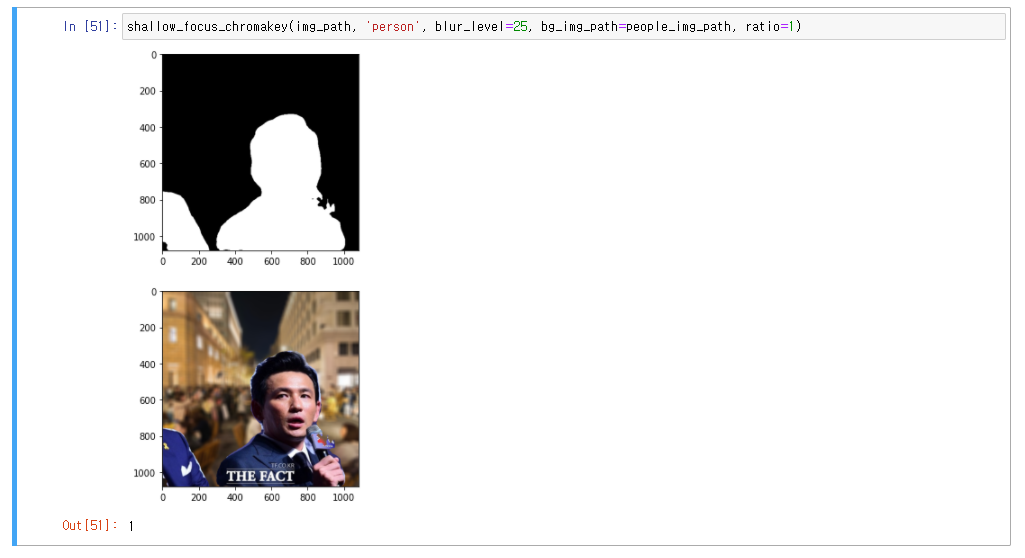
def shallow_focus_chromakey(
img_path, label_str, *, blur_level, bg_img_path=None, ratio=0.5
):
if bg_img_path is None: # 배경 이미지 경로가 주어지지 않으면 원본 이미지 사용
basic_shallow_focus(img_path, label_str, blur_level)
print("shallow focus done on original image")
return 0 # 원본 이미지에 blur 처리를 했으면 0을 반환합니다
label = LABEL_ENCODING[label_str]
img_orig = cv2.imread(img_path)
bg_img_orig = cv2.imread(bg_img_path) # 배경 이미지를 읽어옵니다
img_resized, seg_map = MODEL.run(img_orig)
seg_map = np.where(seg_map == label, label, 0) # 예측 중 label만 추출
img_mask = seg_map * (
255 / (seg_map.max() + 1e-10)
) # 255 normalization, divisionerror 방지
img_mask = img_mask.astype(np.uint8)
####
original_h, original_w = img_orig.shape[
:2
] # cv2.imread()로 읽어와 height와 width를 저장합니다
bg_h, bg_w = bg_img_orig.shape[:2]
if (bg_h / original_h) >= (
bg_w / original_w
): # 원본 이미지를 배경 이미지의 height와 width 중 배경/원본이 작은 쪽으로 맞춥니다.
# 원본 이미지: (960, 540), 배경 이미지: (1260, 1080) -> 세로 비: 1260 / 960 = 1.3125, 가로 비: 1080 / 540 = 2 -> 세로 쪽에 맞춥니다.
# 변환 후 이미지 : (1260, 709)
resize_shape = (int(original_h * bg_w / original_w), bg_w)[
::-1
] # cv2.resize에 인자로 넣을 것이므로
else:
resize_shape = (bg_h, int(original_w * bg_h / original_h))[
::-1
] # 가로, 세로 순서로 넣어주어야 합니다
####
img_mask_up = cv2.resize(
img_mask, resize_shape, interpolation=cv2.INTER_LINEAR
) # mask와 원본 이미지를 모두 배경에 맞춰 resize합니다
img_orig_up = cv2.resize(img_orig, resize_shape, interpolation=cv2.INTER_LINEAR)
resized_w, resized_h = resize_shape # 가로, 세로 중 한 쪽은 배경 이미지와 동일합니다
width_diff = bg_w - resized_w # 배경 이미지와 변환 후 이미지의 가로 차이입니다
height_diff = bg_h - resized_h # 배경 이미지와 변환 후 이미지의 세로 차이입니다
top_padding = int(
height_diff * ratio
) # 원본 이미지에서 잘라낸 부분을 정 중앙에 두기 위해 양쪽에 같은 패딩을 줍니다
left_padding = int(
width_diff * ratio
) # 원본 이미지에서 잘라낸 부분을 정 중앙에 두기 위해 양쪽에 같은 패딩을 줍니다
_, img_mask_up = cv2.threshold(img_mask_up, 128, 255, cv2.THRESH_BINARY)
# top, bottom, left, right
img_mask_up = cv2.copyMakeBorder(
img_mask_up,
top_padding,
height_diff - top_padding,
left_padding,
width_diff - left_padding,
borderType,
value=0,
)
img_orig_up = cv2.copyMakeBorder(
img_orig_up,
top_padding,
height_diff - top_padding,
left_padding,
width_diff - left_padding,
borderType,
value=0,
)
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
plt.imshow(img_mask_color)
plt.show()
bg_img_orig_blur = cv2.blur(
bg_img_orig, (blur_level, blur_level)
) # blurring kernel size를 뜻합니다.
img_bg_mask = cv2.bitwise_not(img_mask_color)
bg_img_bg_blur = cv2.bitwise_and(bg_img_orig_blur, img_bg_mask)
img_concat = np.where(img_mask_color == 255, img_orig_up, bg_img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
return 1결과