enum
- 열거형 데이터 타입.
- 상수의 그룹화를 위해선 enum이 아주 좋은 타입이 될 수 있다
- 코드의 가독성을 높이고 명확한 상수 값을 정의할 수 있다.
- 컴파일 시에 자동으로 숫자 값으로 매핑되므로 따로 값을 할당할 필요가 없다.
object.literal
const obj = {
a: [1, 2, 3],
b: "b",
c: 4,
};- 객체 리터럴은 키 + 값의 쌍으로 구성된 객체를 정의하는 방식
- enum은 number, string 타입의 값만 대입할 수 있다.
- 객체 리털러은 어떤 타입의 값도 대입할 수 있다.
- 다양한 데이터 타입을 지원해서 유연한 구조를 가질수 있다.
- 사용하기 전에 값이 할당되어야 하므로, 런타임 에러를 방지할 수 있다.
as const
하지만 원시 타입이 아닌 object나 array 타입의 경우라면 얘기가 달라집니다. object나 array는 참조 타입이기 때문에 const로 선언하더라도, 내부 프로퍼티의 추론 범위가 한정되지도 않고, 값을 변경할 수도 있습니다.
객체의 모든 프로퍼티들이 readonly로 변경되고, 각 프로퍼티의 타입이 할당된 리터럴 값으로 추론됩니다.
심지어 다음과 같이 중첩된 객체나 배열의 프로퍼티들도readonly로 변경되고 리터럴 값으로 추론됩니다.
이렇듯, as const를 사용하면 원시 타입이든 참조 타입이든 값의 재할당을 막아버리기 때문에 의도치 않은 변경으로 인한 오류를 없앨 수 있습니다. 또한, 리터럴 타입의 추론 범위가 리터럴 값 자체로 한정되면서 좀 더 안전하게 코드를 작성할 수 있습니다.
const enum
사실 enum은 as const가 아닌 const enum와 비교해야 합니다. 둘 다 상수의 추상화라는 목적은 같지만, 트랜스파일된 결과는 아예 다르기 때문에 상황에 따라 어떤 것을 사용할 지 판단할 필요가 있습니다.
이 말은 즉슨, 트랜스파일의 결과로 생성된 코드에 불필요한 코드가 추가된다는 뜻입니다. 그에 반해 const enum는 객체 리터럴 조차 결과에 남지 않기 때문에 훨씬 더 적은 코드를 만듭니다. 실제 배포되는 코드의 크기는 티끌만큼이라도 줄이는 것이 도움되기 때문에 reverse mapping이 필요한 경우가 아니라면 const enum을 사용하는 것이 좋습니다.
참조 : (https://velog.io/@logqwerty/Enum-vs-as-const)
유틸리티 타입
기본 타입을 변형하거나 조작하기 위한 몇 가지 유틸리티 타입을 제공한다.
Partial < T >
- T의 모든 속성을 선택적으로 만든다.
- 단, T 안에 있는 프로퍼티들만 정의해야 한다. 정의되어 있지 않은 프로퍼티들은 쓸 수 없다.
Required < T >
- T의 모든 속성이 반드시 제공되어야 한다.
interface Props {
name: string;
age: number;
address?: string;
}어떤 데이터가 들어올 때 무조건 address가 들어와야 하면 Required를 쓸 수 있다. 그 데이터 하나때문에 옵셔널 체이닝을 변경하는 것이 더 비효율적이기 때문에
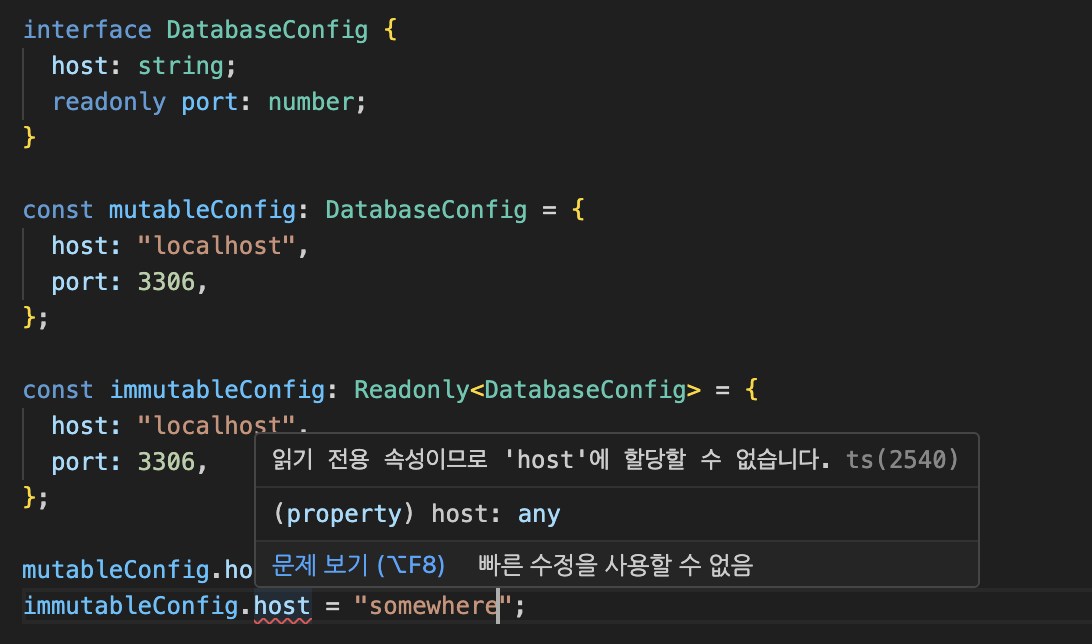
Readonly < T >
- 모든 속성을 읽기 전용으로 만든다.
- readonly 타입들로 구성된 객체가 아니어도 불변 객체로 취급할 수 있다.
Pick < T, K >
- 타입 T에서 K 속성들만 선택하여 새로운 타입을 만든다.
- 이를 통해 타입의 일부 속성만을 포함하는 객체를 쉽게 생성할 수 있다.
interface PersonePick {
name: string;
age: number;
address: string;
}
type SubsetPerson = Pick<PersonePick, "name" | "age">;
const person: SubsetPerson = { name: "Spartan", age: 30 };Omit < T, K>
- 타입 T에서 K 속성들만 제외한 새로운 타입을 만든다
어떤 상황에서??
타입이 30개가 넘는 T가 있다고 해보자. 나는 27개만 써야 하는데 27를 다시 선택하는 것보다 30개중에서 3개만 제외하고 만드는게 효율적이지 않을까??
interface PersonePick {
name: string;
age: number;
address: string;
}
type SubsetPerson = Omit<PersonePick, "address">;
const person: SubsetPerson = { adress : suwon };
