실제 프로젝트에서 발생한 성능 병목 현상 중 하나인 로그 테이블의 이메일 발송 내역 집계 과정에서의 문제를 집중 분석합니다.
해당서비스에서는 시간이 지남에 따라 로그성 데이터가 대량으로 축적되며, 이로 인해 쿼리 성능 저하가 발생하는 문제가 있었습니다. 특히, Full Table Scan이 주요 원인으로 작용하면서 불필요한 I/O 비용 증가와 임시 테이블 생성으로 인한 성능 저하가 확인되었습니다.
이에 따라, 실제 운영 환경과 유사한 조건에서 테스트를 진행하였고, 적절한 복합 인덱스를 적용함으로써 성능을 획기적으로 개선할 수 있었습니다.
이번 글에서는 실제 사례를 바탕으로, 인덱스 최적화 전후의 차이를 비교하며 성능 개선 과정을 상세히 소개합니다.
문제 예측 및 문제 확인
프로젝트에서 가장 조회 성능을 저해할 것으로 예상했던 부분은 바로 email_send_history 테이블에서 발송된 이메일 수를 집계하는 과정이었습니다.
이 테이블은 관리자 페이지 전반에 걸쳐 모든 이메일 발송 내역을 기록하는 로그 테이블로, 이메일 발송 기능이 주된 서비스인 만큼 데이터가 엄청난 양으로 축적될 것으로 예측됩니다.
데이터 양이 증가하면 당연히 조회 성능 저하가 발생하기 때문에, 성능 최적화가 필수적인 상황이었습니다.
최적화 방법은 여러 가지가 있지만, 가장 간단하게 적용할 수 있는 것은 인덱스를 활용하는 것입니다.
실제 운영 환경과 유사한 조건을 재현하기 위해, 최소한의 더미 데이터를 삽입한 후 테스트를 진행했습니다.
1,000,000건의 더미데이터 삽입
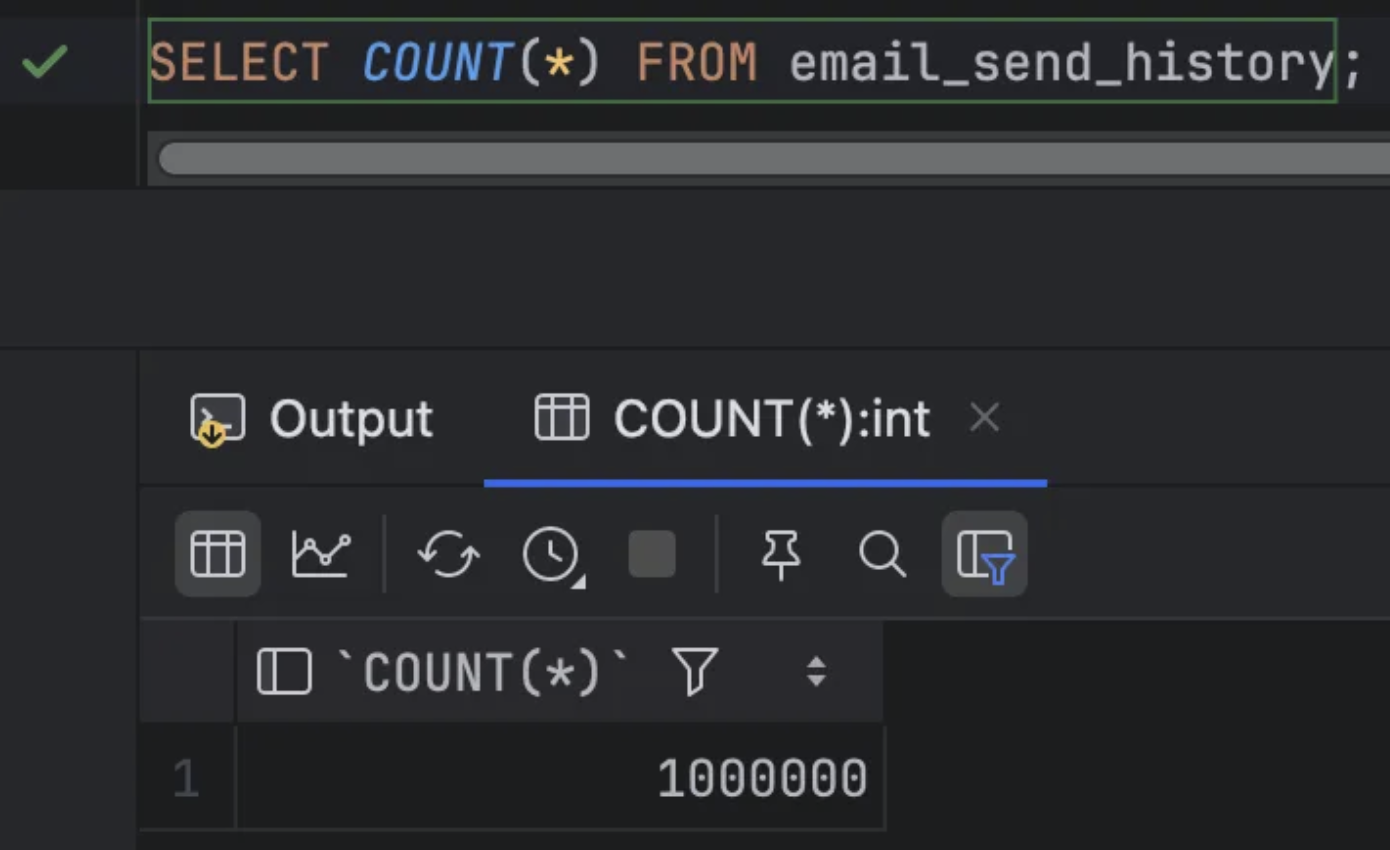
인덱스가 없을 경우 조회
실제 이메일 수 집계 api를 호출할 때 발생하는 쿼리를 확인해 실행 계획을 확인합니다.
실행계획
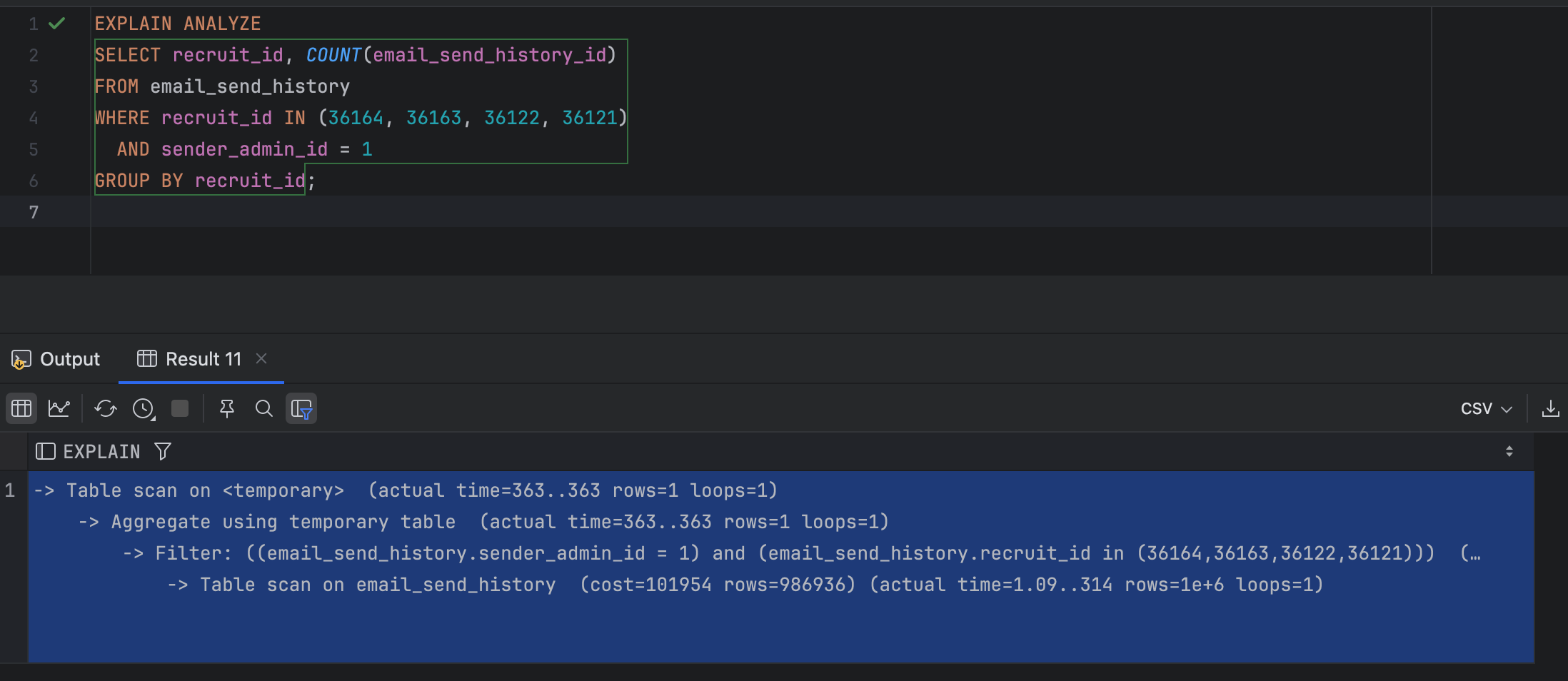
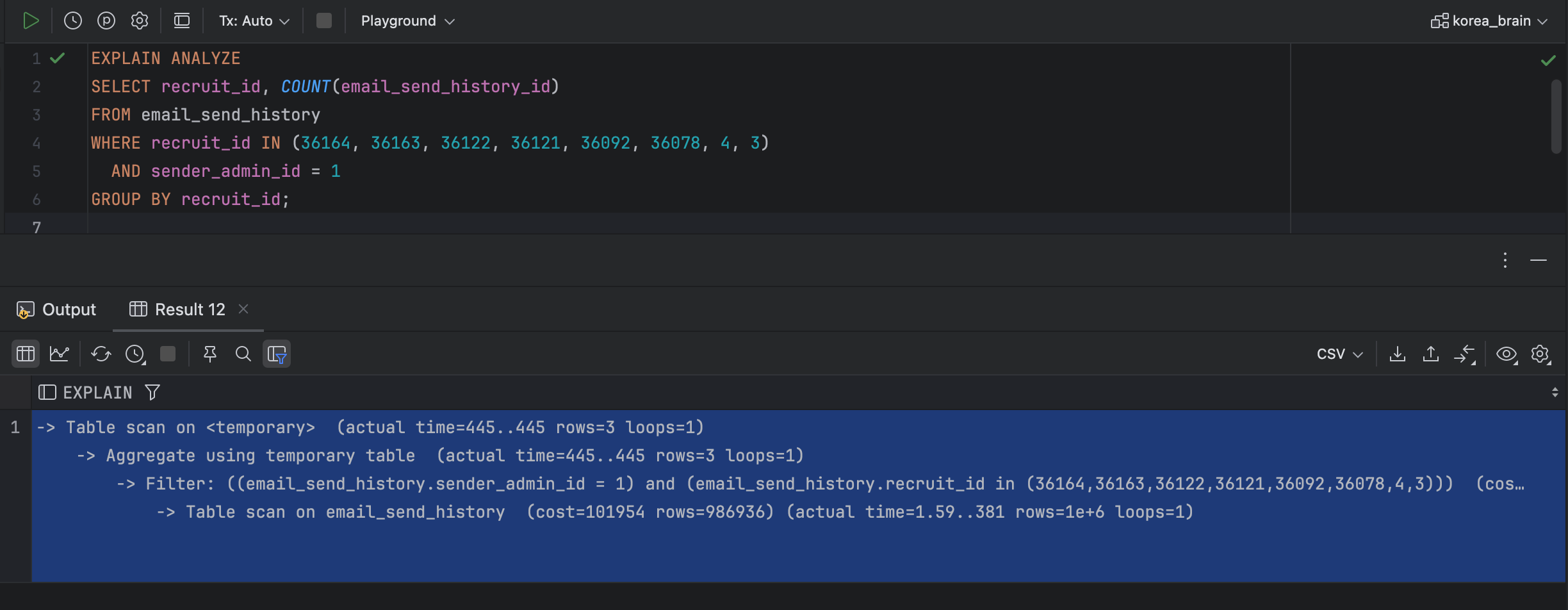
EXPLAIN ANALYZE
SELECT recruit_id, COUNT(email_send_history_id)
FROM email_send_history
WHERE recruit_id IN (36164, 36163, 36122, 36121, 36092, 36078, 4, 3)
AND sender_admin_id = 1
GROUP BY recruit_id;실행계획분석
-> Table scan on <temporary> (actual time=445..445 rows=3 loops=1)
-> Aggregate using temporary table (actual time=445..445 rows=3 loops=1)
-> Filter: ((email_send_history.sender_admin_id = 1) and (email_send_history.recruit_id in (36164,36163,36122,36121,36092,36078,4,3))) (cost=101954 rows=49347) (actual time=1.64..445 rows=30 loops=1)
-> Table scan on email_send_history (cost=101954 rows=986936) (actual time=1.59..381 rows=1e+6 loops=1)결과 분석
Full Table Scan 발생
email_send_history 테이블에 저장된 1,000,000건의 데이터를 모두 읽어야 하므로, 실제 실행 시 381ms 정도의 시간이 소요되었습니다.
옵티마이저 예측 오류
옵티마이저는 49,347건의 결과를 예상했으나 실제 반환된 데이터는 30건에 불과했습니다.
이로 인해 불필요한 임시 테이블 생성과 GROUP BY 연산이 발생했습니다.
임시 테이블 사용
GROUP BY 실행 시 임시 테이블을 사용함으로써 추가적인 디스크 I/O가 발생, 서버 부하가 커질 가능성이 있었습니다.
결과를 요약하자면 이렇습니다.
- 전체 데이터 스캔: 조건에 맞는 소량의 데이터를 찾기 위해 전체 테이블(1,000,000건)을 읽어야 함
- 불필요한 임시 테이블 생성: GROUP BY로 인해 임시 테이블이 생성되어 추가 연산 발생
- 옵티마이저 예측 부정확: 실제 반환 건수와 예상 건수 차이로 인해 최적화되지 않은 실행 계획 선택
총 실행시간 : 381ms
최초 실행 시에는 쿼리 캐시가 비어 있어 디스크에서 데이터를 읽는 비용이 상대적으로 높았습니다.
이후 동일한 실행 계획으로 3회 연속 실행한 결과가 각각 363ms, 363ms, 360ms로 관찰되었습니다.
이는 MySQL이 반복 실행을 통해 캐시를 쌓고, 옵티마이저가 실행 계획을 점진적으로 학습하면서 약간의 성능 개선이 이루어졌음을 보여줍니다.
즉, 동일한 실행 계획이라 하더라도 최초 실행 이후에는 캐시 적중률이 높아지고, 옵티마이저가 실행 패턴에 맞게 미세 조정되므로 실행 시간이 소폭 단축되는 현상이 발생합니다. 다만, 이러한 효과에도 불구하고 전체 실행 시간은 여전히 300ms 중반대로 유지된다는 점을 알 수 있습니다.
문제 해결방안 도출
현재 상황에서 가장 문제될 부분은 데이터가 많아질수록 전체 데이터를 읽어야 하는 I/O 부하가 기하급수적으로 증가한다는 점입니다.
만약 이 문제를 방치하면, 이메일 발송 내역을 기록하는 로그 테이블인 email_send_history에서 모든 데이터를 스캔하게 되어, 다수의 사용자가 해당 기능을 호출할 경우 DB 서버에 과부하가 발생할 수 있습니다.
또한, API 응답 시간이 400ms 이상으로 늘어나면 사용자 경험 저하 및 서비스 품질 하락으로 이어질 위험이 있습니다.
📍 이 문제를 해결하기 위해 인덱스를 활용했습니다.📍
인덱스 적용 전 고려사항
로그 테이블 특성:
email_send_history테이블은 주로 삽입만 일어나고, 삭제/변경은 발생하지 않는 로그성 테이블입니다. 수정이나 삭제가 빈번한 테이블에서는 인덱스 추가 시 인덱스 유지 비용이 문제가 될 수 있지만, 로그 테이블의 경우 그러한 부담이 크지 않습니다.쿼리 조건 분석:
실제 실행되는 SQL문을 보면
recruit_id와sender_admin_id를 조건으로 사용합니다. 따라서 두 컬럼에 대해 인덱스를 적용하는 것이 조회 성능에 유리합니다.복합 인덱스 vs. 단일 인덱스:
단일 컬럼 인덱스를 각각 생성할 경우, 복합 인덱스보다 조회 성능이 떨어지고 인덱스 테이블 자체가 불필요하게 커질 수 있습니다. 복합 인덱스를 사용하면 두 컬럼을 동시에 커버할 수 있어 효율적입니다.
인덱스 순서의 중요성 (인덱스 프리픽스 규칙):
인덱스의 순서 또한 매우 중요합니다.
서비스 내에서sender_admin_id만으로도 데이터를 조회하는 경우가 있으므로, 복합 인덱스를 (sender_admin_id,recruit_id) 순서로 생성하면, 인덱스 프리픽스 규칙으로 인해 인덱스의 왼쪽 첫 번째 컬럼인sender_admin_id만을 사용한 조건에서도 효과적으로 활용할 수 있습니다.
최종 인덱스 설계
위의 이유들로 인해 최적의 인덱스는 아래와 같이 결정되었습니다.
CREATE INDEX idx_email_send_history ON email_send_history (sender_admin_id, recruit_id);이 복합 인덱스는sender_admin_id와 recruit_id 조건을 모두 빠르게 조회할 수 있으며, 단일 컬럼 조건 (sender_admin_id)에도 효과적으로 작동하여 별도의 인덱스 추가 없이도 최적의 성능을 기대할 수 있습니다.
인덱스 적용 후 개선 사항
실행계획분석
-> Group aggregate: count(email_send_history.email_send_history_id) (cost=11.6 rows=35) (actual time=0.0632..0.083 rows=3 loops=1)
-> Filter: ((email_send_history.sender_admin_id = 1) and (email_send_history.recruit_id in (36164,36163,36122,36121,36092,36078,4,3))) (cost=8.12 rows=35) (actual time=0.0456..0.0763 rows=30 loops=1)
-> Covering index range scan on email_send_history using idx_email_send_history over (sender_admin_id = 1 AND recruit_id = 3) OR (sender_admin_id = 1 AND recruit_id = 4) OR (6 more) (cost=8.12 rows=35) (actual time=0.0378..0.0653 rows=30 loops=1)복합 인덱스를 적용한 후, 실행 계획을 다시 확인한 결과 다음과 같이 개선됨을 확인했습니다.
Covering Index Range Scan
MySQL이 인덱스만을 이용해 데이터를 조회하므로, email_send_history 테이블의 실제 데이터 페이지를 읽지 않아 I/O 비용이 크게 절감됩니다.
효과적인 조건 처리
조건이 (sender_admin_id = 1 AND recruit_id = 3) OR (sender_admin_id = 1 AND recruit_id = 4) OR ... 형태로 처리되며, IN (36164, 36163, …) 조건에 따라 8개의 recruit_id를 빠르게 조회합니다.
실제 실행 시간은 0.0378..0.0653ms에 30개의 행을 조회하여,
이전의 381ms에 비해 획기적인 개선(약 4,500배 향상)이 달성되었습니다.
필터링 최적화
기존: Filter 단계에서 전체 테이블 스캔을 수행
개선 후: 인덱스를 활용하여 필요한 데이터만 선택적으로 검색 예상 건수는 35건, 실제 조회 건수는 30건이며, 처리 시간은 0.07ms 내에 완료됩니다.
GROUP BY 최적화
count(email_send_history_id) 연산이 인덱스 내에서 직접 수행되어, 임시 테이블 생성 및 추가 정렬(filesort) 없이 최적화된 처리가 가능합니다. 최종 결과는 3개의 그룹(각 recruit_id 별 집계)으로 반환됩니다.
성능 비교 (인덱스 적용 전후)
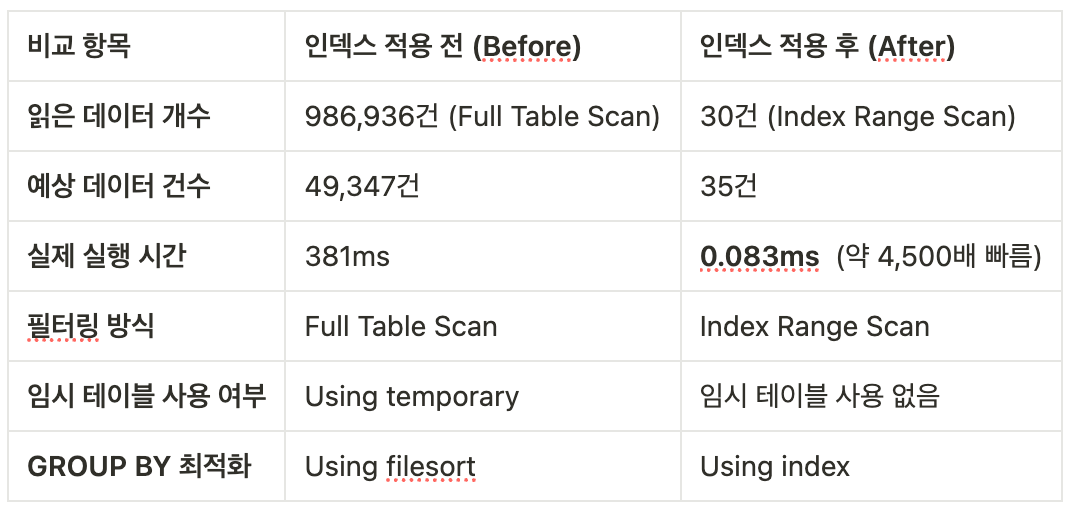
이와 같이 복합 인덱스(sender_admin_id, recruit_id)를 적용함으로써, 필요한 데이터만 빠르게 조회하고, 그룹핑 작업 역시 인덱스 내에서 최적화되어 대량 데이터 환경에서도 안정적이고 효율적인 성능 개선을 이루어냈습니다.
Index Prefix 적용 확인
복합 인덱스의 인덱스 프리픽스 규칙이 제대로 적용되었는지 확인하기 위해, sender_admin_id만을 조건으로 사용하는 실제 쿼리의 실행 계획을 살펴보았습니다.
실행계획
EXPLAIN ANALYZE
SELECT esh1_0.email_send_history_id, esh1_0.application_id,
....
FROM email_send_history esh1_0
JOIN recruit r1_0 ON r1_0.id = esh1_0.recruit_id
WHERE esh1_0.sender_admin_id = 1;실행계획분석
-> Nested loop inner join (cost=136497 rows=98694) (actual time=0.19..972 rows=31 loops=1)
-> Filter: ((esh1_0.sender_admin_id = 1) and (esh1_0.recruit_id is not null)) (cost=101954 rows=98694) (actual time=0.153..969 rows=1090 loops=1)
-> Table scan on esh1_0 (cost=101954 rows=986936) (actual time=0.0414..914 rows=1e+6 loops=1)
-> Single-row index lookup on r1_0 using PRIMARY (id=esh1_0.recruit_id) (cost=0.25 rows=1) (actual time=0.00249..0.00249 rows=0.0284 loops=1090)실행 계획 분석 결과는 다음과 같습니다
전체 테이블 스캔:
email_send_history 테이블 전체를 읽으며, 약 1,000,000건의 데이터를 914ms 동안 스캔했습니다.
옵티마이저 예측 오류:
옵티마이저는 sender_admin_id = 1 조건에 대해 98,694건의 결과를 예상했으나, 실제로는 1,090건만 반환되었습니다.
예상과 실제 건수 차이가 클 경우, 잘못된 실행 계획이 선택될 수 있는 위험이 있습니다.
Nested Loop Join 사용:
email_send_history에서 조건에 맞는 데이터를 찾은 후, 각 행의 recruit_id를 기준으로 recruit 테이블과 조인을 수행합니다.
Outer Table이 클 경우 Nested Loop Join은 비효율적입니다.
인덱스 적용 후 개선 사항
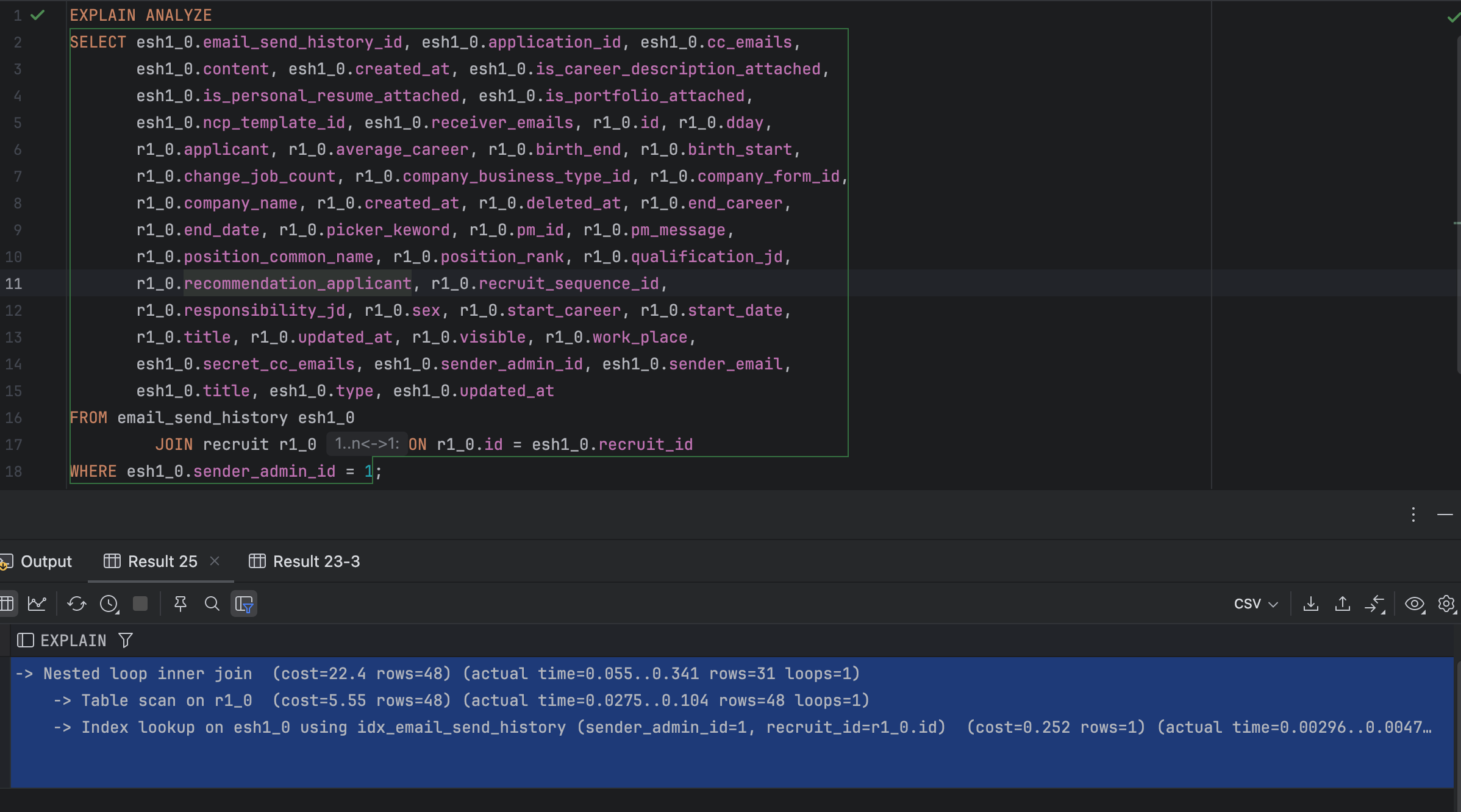
-> Nested loop inner join (cost=22.4 rows=48) (actual time=0.055..0.341 rows=31 loops=1)
-> Table scan on r1_0 (cost=5.55 rows=48) (actual time=0.0275..0.104 rows=48 loops=1)
-> Index lookup on esh1_0 using idx_email_send_history (sender_admin_id=1, recruit_id=r1_0.id) (cost=0.252 rows=1) (actual time=0.00296..0.00473 rows=0.646 loops=48)인덱스 Lookup 활용:
idx_email_send_history 인덱스를 사용하여 sender_admin_id 조건에 대해 인덱스 조회가 수행됩니다.
이를 통해 전체 테이블 스캔을 제거하고, 필요한 데이터만 빠르게 읽어옵니다.
효율적인 조인 처리:
recruit 테이블의 데이터 건수가 적어 Full Table Scan에도 큰 부담이 없으며, 인덱스 Lookup과 결합하여 Nested Loop Join의 부담을 줄였습니다.
결과적으로 조인에 소요되는 비용이 크게 감소했습니다.
실행 시간 대폭 단축:
기존 실행 계획에서는 972ms 정도 소요되던 쿼리가, 인덱스 적용 후 0.341ms로 단축되어 약 2,850배의 성능 향상을 확인할 수 있었습니다.
복합 인덱스(sender_admin_id, recruit_id)의 적용으로 인덱스 프리픽스 규칙이 제대로 활용되어, sender_admin_id 조건만 사용한 쿼리에서도 인덱스 Lookup이 이루어집니다.
이를 통해 불필요한 전체 테이블 스캔이 제거되고, 전체 실행 시간이 극적으로 단축되는 결과를 가져왔습니다.
대용량 데이터를 다루는 프로젝트에서는 조회 성능 개선이 시스템 전체 효율성에 큰 영향을 미칩니다.
하지만 인덱스를 무작정 추가하면 쓰기 성능 저하와 불필요한 디스크 공간 사용 등의 부작용이 발생할 수 있습니다.
따라서 프로젝트 전반의 데이터 흐름과 쿼리 패턴을 면밀히 분석한 후에 적절한 인덱스 설계로 최적의 효과를 누리는 것이 바람직합니다.