이 내용과 관련하여 정말 좋은 브런치 글 공유
JPA를 사용하는 이유
- 객체와 관계형 데이터베이스의 테이블 구조를 매핑할 수 있어 객체지향적인 코딩을 가능하게 함
- "영속성"이라는 개념을 활용한 영속성 컨텍스트를 이용해 객체를 관리
JPA vs. Hibernate vs. DataJPA
JPA는 단순한 명세이며, 구현이 없습니다.
JPA를 정의한 jakarta.persistence 패키지는 각종 annotation, exception, interface 등으로 구성되어 있습니다. 심지어 EntityManager도 jakarta.persistence.EntityManager에 interface로 정의되어 있습니다.
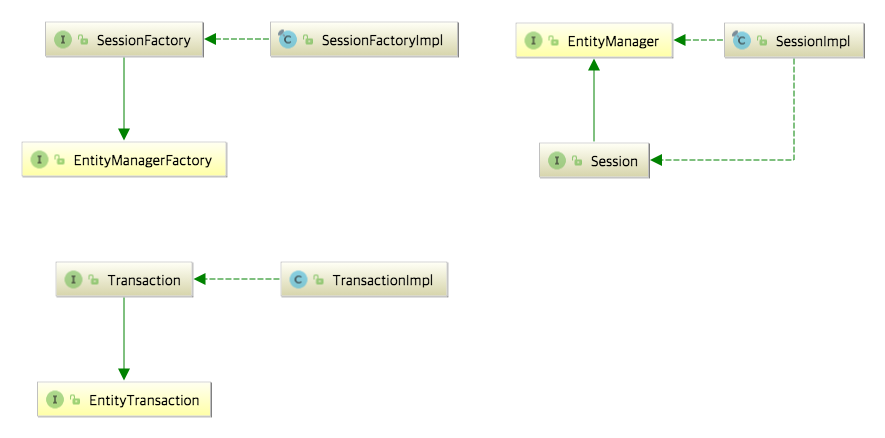
Hibernate는 JPA 명세에 대한 대표적인 구현체입니다.
JPA의 EntityManagerFactory, EntityManager, EntityTransaction을 Hibernate에서 SessionFactory, Session, Transaction으로 상속받고 이를 -Impl로 구현하고 있습니다.
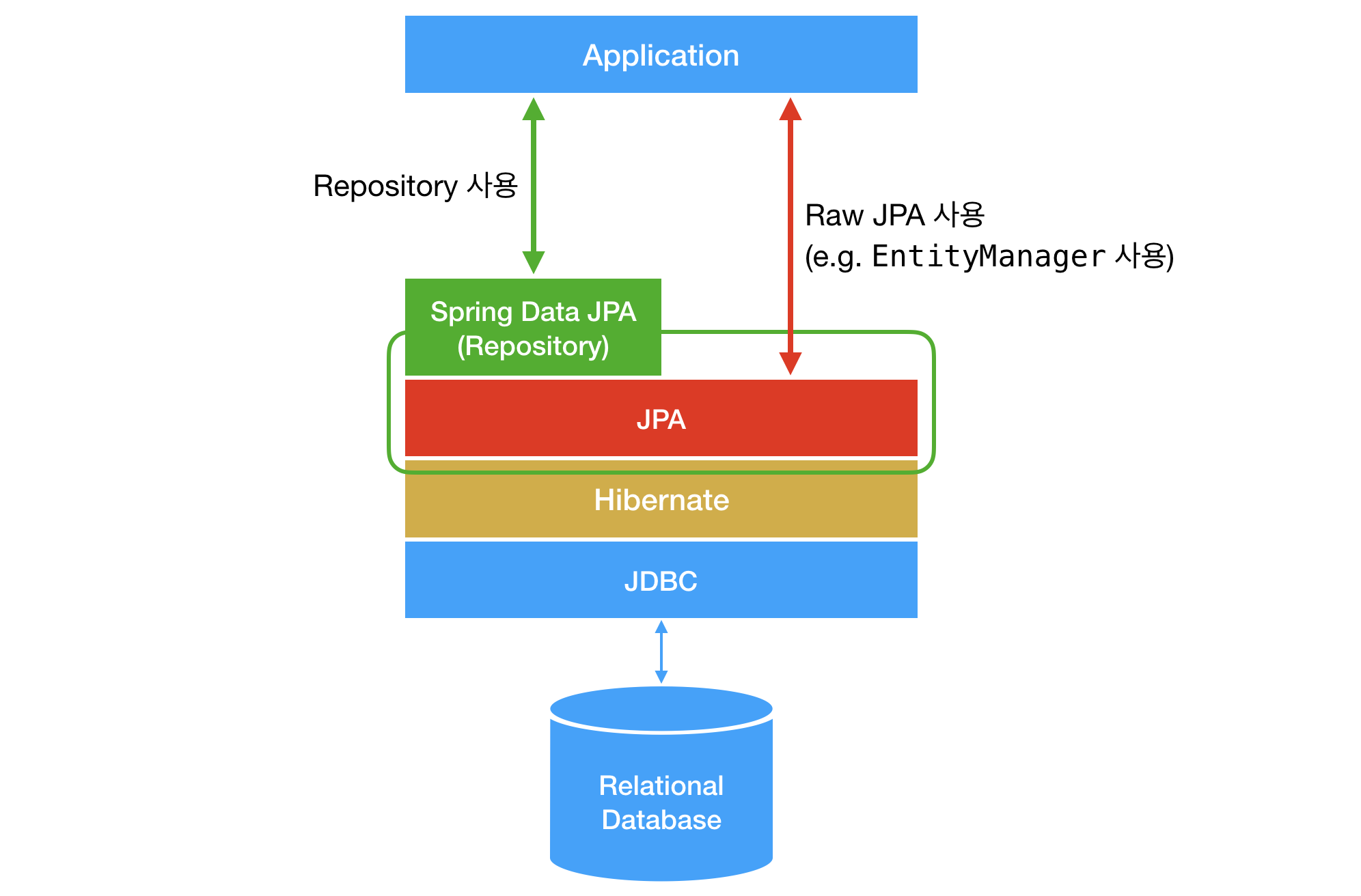
DataJPA는 JPA를 추상화하여 Repository라는 인터페이스를 제공하고, 개발자는 DataJPA에서 제공하는 규칙대로 타입을 지정하고, 메소드 네이밍을 하면 DataJPA가 알아서 해당하는 구현을 해줍니다.
엔티티 매니저와 엔티티 매니저 팩토리
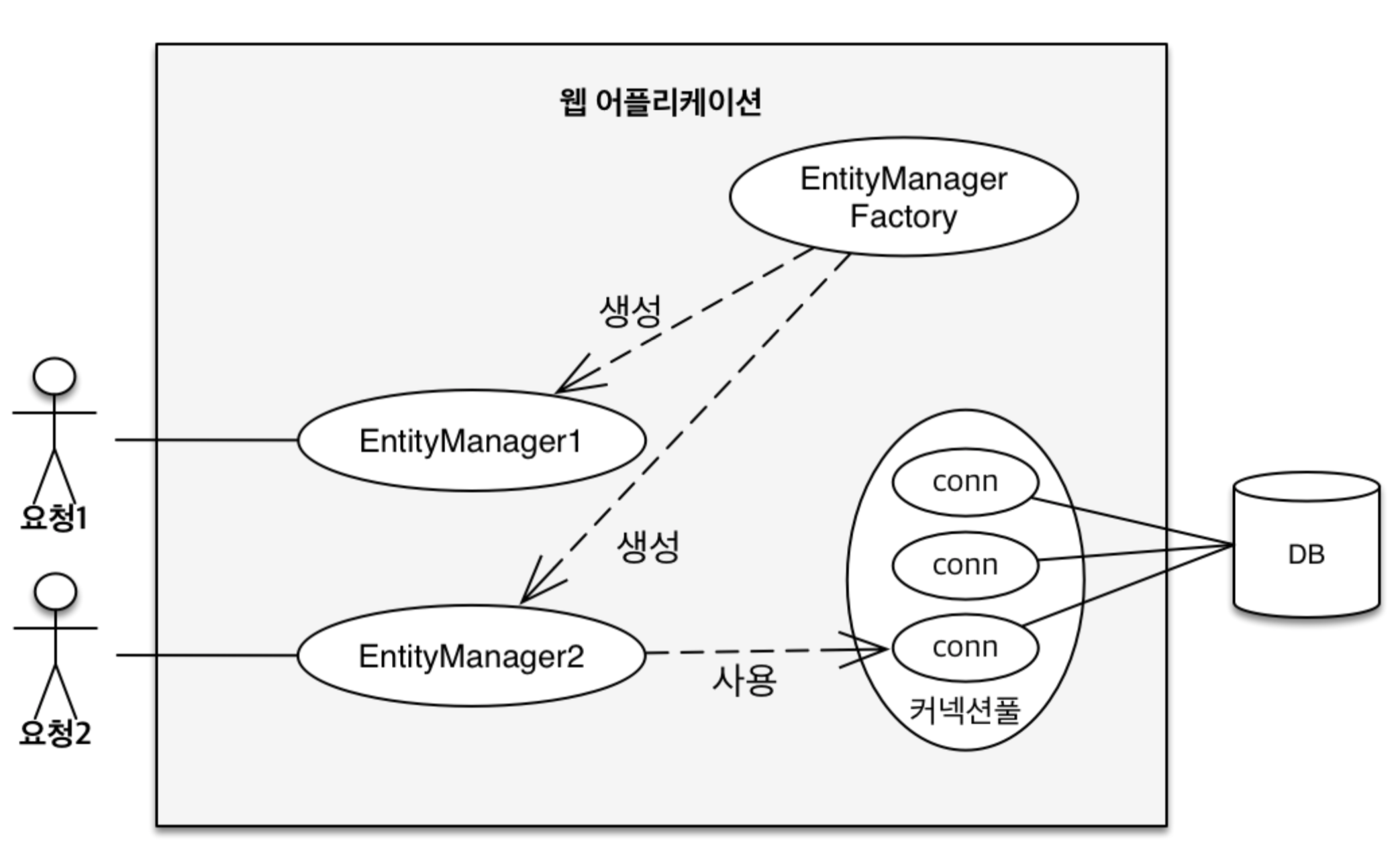
- 엔티티 매니저 : 내부적으로 DB connection을 수립하여 DB에 접근하는 객체
- 엔티티 매니저 팩토리 : 클라이언트의 요청마다 EntityManager를 생성 (Thread 당 하나)
EntityManagerFactory
어플리케이션의 생명 주기동안 딱 1개만 생성됩니다. 즉, 어플리케이션이 실행될 때 하나 생성되었다가, 이를 쓰레드 간 공유하면서 사용하고, 어플리케이션이 종료될 때 EntityManagerFactory 인스턴스는 파괴됩니다.
EntityManager
EntityManagerFacotry에 의해 클라이언트의 요청마다 생성됩니다. 즉, 쓰레드 당 하나가 생성되는데, 쓰레드 간 공유하게 되면 데이터 안정성이 위협되므로 트랜잭션 단위로 작업을 수행할 때 생성하여 쓰레드 간 공유를 방지하게 됩니다. 작업을 수행한 뒤에는 데이터 안정성을 위해 DB connection을 반환해야 하므로 EntityManager.close()하게 됩니다.
위와 같은 이유로 모든 데이터 생성/수정/삭제 등의 변경 작업은 반드시 트랜잭션 단위로 수행되어야 합니다. 이의 경우 단순 조회의 경우 데이터 수정 위험이 없으므로 크게 상관은 없습니다. 따라서
@Transactional(readOnly=true)의 경우 내부적으로 성능을 더욱 최적화하는 로직을 구현해 두었습니다.엔티티 매니저는 아래 메서드들을 이용하여 트랜잭션을 관리합니다.
EntityTransaction tx = entityManager.getTransaction(); tx.begin(); tx.commit(); tx.rollback();
영속성 컨텍스트
영속성을 직역하자면 영구적인 속성을 지니는 듯한 뉘앙스를 주는데, 이를 저는 "Entity가 휘발되지 않는 상태"로 이해하면 될 것 같습니다.
그렇다면 영속성 컨텍스트는 무엇일까요?
영속성 컨텍스트는 "데이터베이스와 동기화되는 영역"으로 이해할 수 있습니다. 이는 트랜잭션 내에서 엔티티 상태를 담아두는 캐시 레이어와 같은 역할을 수행하기도 하며, tx.commit()을 기점으로 데이터베이스에 엔티티가 테이블로 매핑되어 반영됩니다.
사실 영속성 컨텍스트의 1차 캐시 기능은 한 트랜잭션 내에서만 존재하므로 딱히 유의미한 기능은 아니다.
(참고) 엔티티 매니저는 다음과 같은 과정을 거쳐 엔티티를 조회합니다.
1.em.find(entity.class, "entityName");수행
2. 영속성 컨텍스트 내에 스냅샷 확인
3. 만약 존재하지 않으면 DB 확인
4. DB에서 불러온 엔티티 데이터는 영속성 컨텍스트에 저장
5. 조회한 엔티티 반환
영속성 컨텍스트 내에는 엔티티가 Map<Key, Value>구조로 저장됩니다. 여기서 Key는 @Id 로 선언된 필드 값이, 그리고 Value에는 해당 엔티티 자체가 기록됩니다. 이는 이후에 DB에 반영될 때 PK로 Key의 @Id 필드 값이, 그 외 엔티티의 필드 데이터가 칼럼으로 반영됩니다. (물론, 연관관계를 설정해두면 FK도 자동으로 반영됩니다.)
em.persist(entity)를 통해 특정 엔티티는 영속화됩니다. 이는 영속성 컨텍스트에 저장/반영됨을 의미합니다. 하지만 이는 "영속화"임을 의미할 뿐, DB에 반영되었다는 말과는 구분해야 합니다.
영속성 컨텍스트에서 관리되는 엔티티는 4가지의 라이프사이클을 가집니다.
비영속(transient/new)
말 그대로 '비'영속, 즉 영속성이 아닌 상태입니다. 자바 코드 상에서 인스턴스가 생성'만' 된 상태라고 이해할 수 있습니다. 엔티티 매니저와 전혀 아무런 교류가 없었던 거라고 이해하면 될 것 같습니다. .isTransient()로 확인할 수 있습니다.
영속(managed)
영어를 보면 좀 더 직관적이라고 생각합니다. 엔티티가 영속 상태에 있다는 건 영속성 컨텍스트 내에서 관리를 받고 있는 객체임을 의미합니다. 이는 em.persist(entity)로 시작됩니다.
준영속(detached)
영속성 컨텍스트에 저장되었던 인스턴스를 영속성 컨텍스트에서 분리시킬 때, 해당 인스턴스는 준영속 상태가 되었다고 말합니다. 해당 인스턴스는 이 때부터 영속성 컨텍스트가 제공하는 기능을 사용하지 못합니다.
사실 영속성 컨텍스트는 트랜잭션 단위로 생성되고 삭제되므로 영속성 컨텍스트가 종료되어도 해당 엔티티들은 준영속이 되는 겁니다.
비영속 엔티티는 애초에 영속 상태에 들어온 적도 없는 인스턴스를 말합니다. 즉, 해당 인스턴스의 스냅샷 또는 데이터가 영속성 컨텍스트와 DB 그 어디에도 존재하지 않고, 그저 코드 상에서 메모리만 차지하고 있는 상태입니다.
준영속 엔티티는 일반적으로 DB에 한번 저장된 이후에, em.detach(entity)를 통해 영속성 컨텍스트로부터 분리된 상태임을 의미합니다. 이후부터는 dirty checking과 같은 기능을 누릴 수 없습니다. 따라서 이를 수정하기 위해서는 em.merge(entity)를 사용하거나 영속 상태로 다시 등록하여 더티체킹을 수행해야 합니다.
삭제(removed)
DB에서 해당 엔티티를 삭제하도록 entity manager에게 요청하는 것을 의미합니다. em.remove(entity)를 통해 수행합니다.
엔티티 매니저의 동작 흐름
EntityManager entityManager = emf.createEntityManager();
EntityTransaction transaction = entityManager.getTransaction();
// EntityManager는 데이터 변경 시 트랜잭션을 시작해야 한다.
transaction.begin(); // Transaction 시작
entityManager.persist(memberA);
entityManager.persist(memberB);
// 이때까지 INSERT SQL을 DB에 보내지 않는다.
// 커밋하는 순간 DB에 INSERT SQL을 보낸다.
transaction.commit(); // Transaction 커밋
https://gmlwjd9405.github.io/2019/08/06/persistence-context.html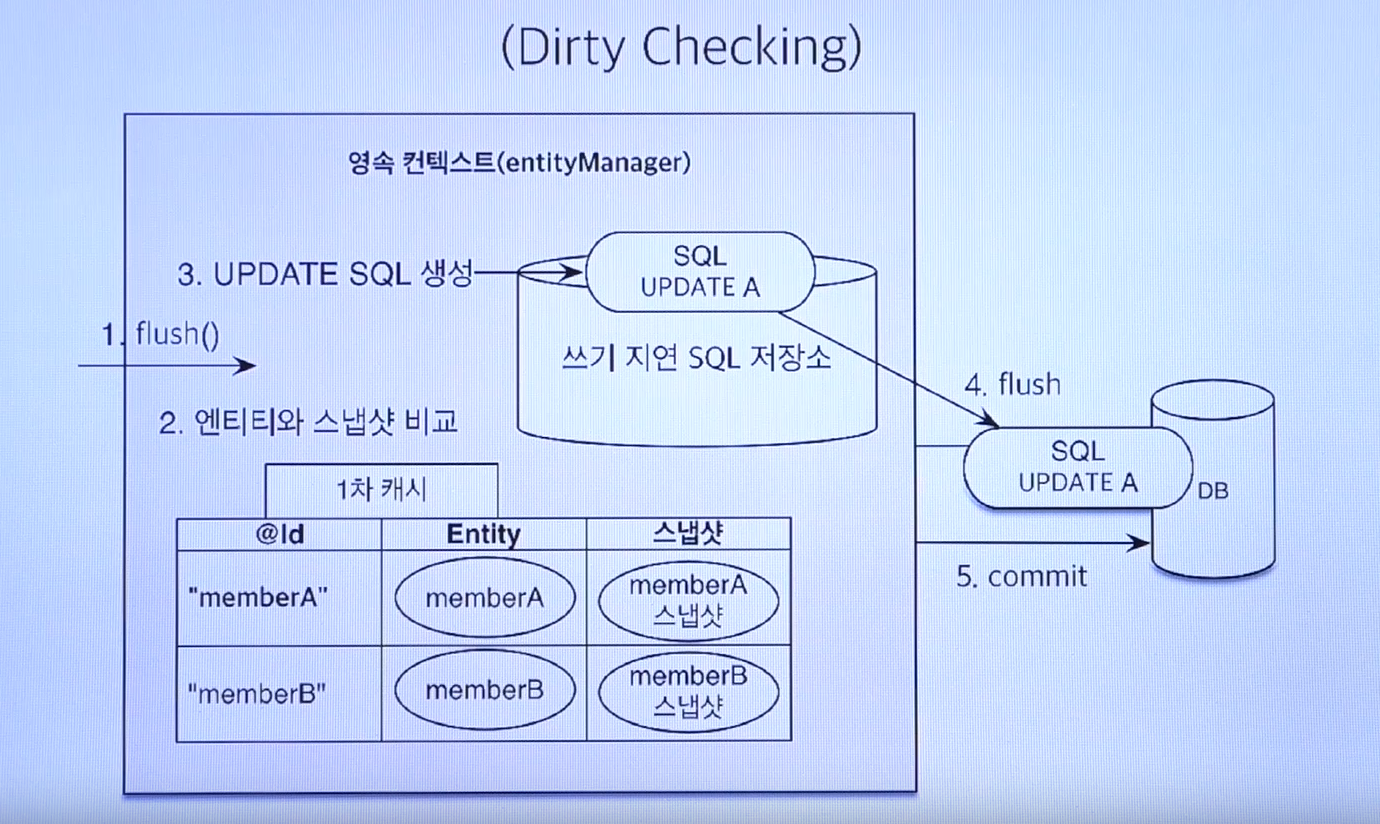
em.persist(entity)- 영속성 컨텍스트에 엔티티를 등록하고 insert SQL을 "쓰기 지연 저장소"에 쌓아갑니다.
tx.commit()- 커밋하는 시점에 insert SQL을 한번에 보냅니다.
em.flush()와 tx.commit()의 차이
em.flush()는 영속성 컨텍스트가 가진 변경사항을 확인(더티체킹)하여 DB에 즉각 반영합니다. 하지만 트랜잭션을 종료하진 않습니다. 따라서 롤백의 여지를 우선 남겨둡니다.
tx.commit()은 영속성 컨텍스트가 가진 변경 사항을 확인(더티체킹)하여 DB에 즉각 반영(==플러시 자동 호출)하고 트랜잭션을 종료합니다. 이 때문에 commit은 변경 사항을 DB에 영구적으로 반영한다고 말하기도 합니다. 당연히 트랜잭션이 종료되므로 롤백이 불가능합니다.
더티 체킹 방식으로 구현된 이유
학습 단계의 우리는 대부분 수정을 하기 위해서 별도의 .update()메서드를 본능적으로 찾았을 것입니다. 하지만 JpaRepository 인터페이스의 상속 트리를 아무리 타고 올라가봐도 .update() 관련 메서드는 찾아볼 수 없습니다.
JPA는 더티 체킹이라는 기능을 명시하고 있습니다. 이는, 영속성 컨텍스트에서 관리되는 엔티티의 변경 사항을 감지하고 그에 맞는 업데이트 쿼리를 생성하는 기능입니다.
따라서 우리는 자연스럽게 어떤 엔티티를 조회하고(1차 캐시에 있으면 이미 영속 상태, 없으면 DB에서 조회해서 영속화 거침), 이의 필드값을 수정하면 tx.flush() 또는 tx.commit()타이밍에 영속성 컨텍스트에 저장된 엔티티의 스냅샷과 코드 상의 엔티티 필드 데이터를 비교하여 변경 사항에 대한 쿼리문을 작성하여 DB에 날리게 됩니다.
이는 마치 우리가 리스트를 어떤 참조변수에 할당하고 이 변수에 업데이트 메소드를 사용하는 게 아니라 그냥 그 리스트의 인덱스에 수정 값을 그대로 때려박으며 사용하는 매커니즘을 그대로 구현한 것과 같습니다.
물론 이 때, setter를 사용하기보단 구체적인 메서드 등을 이용하는 것이 바람직하고, 그 외에 빌더 패턴도 고려해볼 수 있다.
@Transactional(readOnly=true)가 빠른 이유
위 어노테이션을 메소드 레벨에서 정의하게 되면, 해당 메서드 내에서 트랜잭션을 돌릴 때 영속성 컨텍스트 내에 조회 엔티티에 대한 스냅샷을 저장하지 않습니다.
그러므로 당연히 더티 체킹도 수행되지 않고, 데이터 변경을 위한 쿼리문도 쌓이지 않습니다. 동일한 맥락에서 .flush()나 .commit()또한 수행되지 않기 때문에 더욱 조회에 최적화된 성능으로 작업을 수행할 수 있는 것입니다.
