문제 출처: https://www.acmicpc.net/problem/1991
문제
- 이진 트리를 입력받아 전위 순회(preorder traversal), 중위 순회(inorder traversal), 후위 순회(postorder traversal)한 결과를 출력하는 프로그램을 작성하시오.
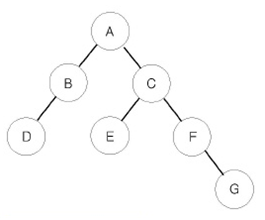
- 예를 들어 위와 같은 이진 트리가 입력되면,
* 전위 순회한 결과 : ABDCEFG // (루트) (왼쪽 자식) (오른쪽 자식)
* 중위 순회한 결과 : DBAECFG // (왼쪽 자식) (루트) (오른쪽 자식)
* 후위 순회한 결과 : DBEGFCA // (왼쪽 자식) (오른쪽 자식) (루트)가 된다.
- 배열을 각각 따로 유지하는 버전
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
private static class Node {
char value;
char left;
char right;
public Node(char value, char left, char right) {
this.value = value;
this.left = left;
this.right = right;
}
}
private static StringBuilder sb = new StringBuilder();
public static void main(String[] args) throws Exception {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(reader.readLine()); // 노드의 개수
Node[] tree = new Node[N]; // 0-base index
for (int i = 0; i < N; i++) {
StringTokenizer tokenizer = new StringTokenizer(reader.readLine());
char value = tokenizer.nextToken().charAt(0);
char left = tokenizer.nextToken().charAt(0);
char right = tokenizer.nextToken().charAt(0);
tree[value - 'A'] = new Node(value, left, right); // 노드 배열
}
dfsPreOrder(tree, 'A');
sb.append("\n");
dfsInOrder(tree, 'A');
sb.append("\n");
dfsPostOrder(tree, 'A');
System.out.println(sb);
}
private static void dfsPreOrder(Node[] tree, char current) {
if (current == '.') return;
sb.append(tree[current - 'A'].value);
dfsPreOrder(tree, tree[current - 'A'].left);
dfsPreOrder(tree, tree[current - 'A'].right);
}
private static void dfsInOrder(Node[] tree, char current) {
if (current == '.') return;
dfsInOrder(tree, tree[current - 'A'].left);
sb.append(tree[current - 'A'].value);
dfsInOrder(tree, tree[current - 'A'].right);
}
private static void dfsPostOrder(Node[] tree, char current) {
if (current == '.') return;
dfsPostOrder(tree, tree[current - 'A'].left);
dfsPostOrder(tree, tree[current - 'A'].right);
sb.append(tree[current - 'A'].value);
}
}
- 각 원소를 연결하는 버전
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
private static class Node {
char value;
Node left;
Node right;
public Node(char value, Node left, Node right) {
this.value = value;
this.left = left;
this.right = right;
}
}
private static StringBuilder sb = new StringBuilder();
public static void main(String[] args) throws Exception {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(reader.readLine()); // 노드의 개수
Node[] tree = new Node[N]; // 0-base index
// 배열 초기화(일단은 value만 채움. value가 곧 인덱스가 된다.)
for (int i = 0; i < N; i++) {
tree[i] = new Node((char) ('A' + i), null, null);
}
// 노드 연결
for (int i = 0; i < N; i++) {
StringTokenizer tokenizer = new StringTokenizer(reader.readLine());
char value = tokenizer.nextToken().charAt(0);
char left = tokenizer.nextToken().charAt(0);
char right = tokenizer.nextToken().charAt(0);
if (left != '.') tree[value - 'A'].left = tree[left - 'A'];
if (right != '.') tree[value - 'A'].right = tree[right - 'A'];
}
// 첫 노드(A)부터 탐색 시작
dfsPreOrder(tree[0]);
sb.append("\n");
dfsInOrder(tree[0]);
sb.append("\n");
dfsPostOrder(tree[0]);
System.out.println(sb);
}
private static void dfsPreOrder(Node node) {
if (node == null) return;
sb.append(node.value);
dfsPreOrder(node.left);
dfsPreOrder(node.right);
}
private static void dfsInOrder(Node node) {
if (node == null) return;
dfsInOrder(node.left);
sb.append(node.value);
dfsInOrder(node.right);
}
private static void dfsPostOrder(Node node) {
if (node == null) return;
dfsPostOrder(node.left);
dfsPostOrder(node.right);
sb.append(node.value);
}
}
- 처음에 char 배열로 트리를 구현하였다가 고전하였다.
- 노드 클래스를 만들고 이를 관리하는 배열을 생성하여 탐색을 수행하였다. 전위, 중위, 후위 탐색 방법은 간단히 재귀를 통해 구현할 수 있었다.
- 처음에는 노드별로 각각 따로 객체를 생성한 뒤, 이들을 배열에 담아 탐색을 수행하는 방식으로 풀었다. 이 방식으로도 풀이가 가능했으나, 트리의 느낌이 없어서 각 원소를 서로 연결하는 방식으로 다시 풀었다.

백엔드 개발자가 되자!