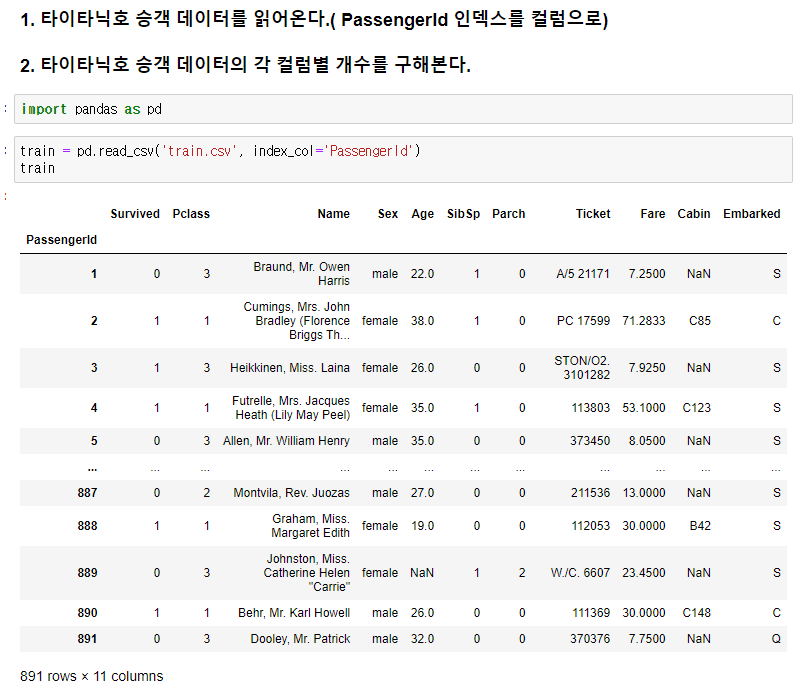
csv 파일 불러오기
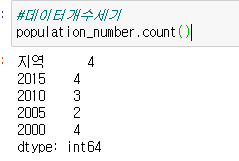
데이터개수세기 - 결측치를 알 수 있다.
열값을 인덱싱해오면 Series클래스(1차원형태)가 된다

정렬

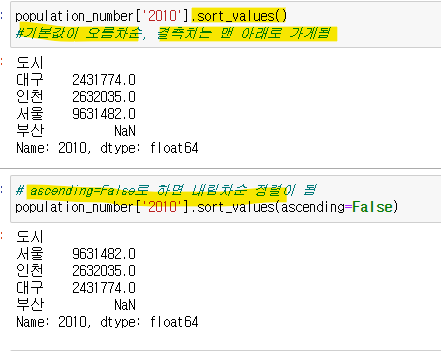
- sort_values()
기본값이 오름차순, 결측치(오름,내림 무관하게) 는 맨 아래로 가게됨
ascending=False로 하면 내림차순 정렬이 됨
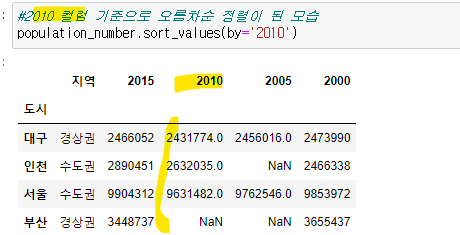
특정 컬럼 기준 : by = ''

기준이 여러개일 때, 리스트형태로[]대괄호로 묶어줌
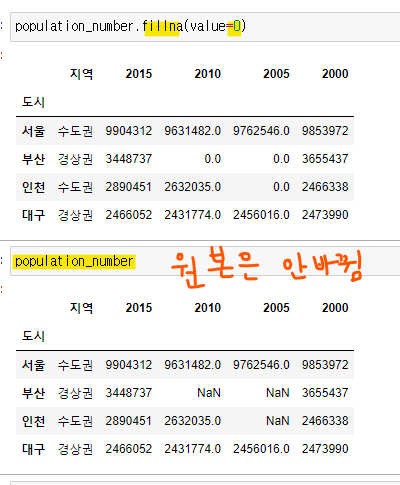
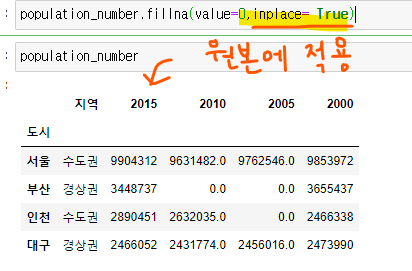
결측치 채우기
- NaN값을 0으로 채워줌 -> 원본데이터가 바뀌진 않음
- inplace = True 일 때 원본에도 적용할 수 있다.
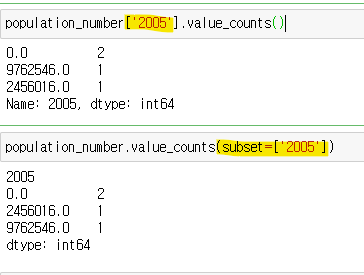
중복데이터
- .value_counts()

csv 파일 불러오기
- 컬럼별 개수 불러오기
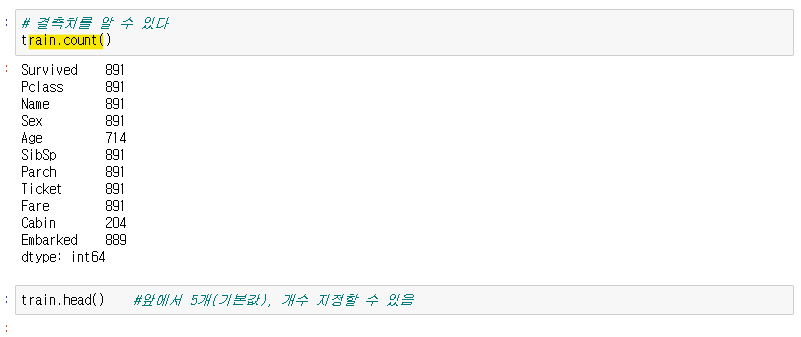
- .head() #앞에서 5개(기본값), 개수 지정할 수 있음
- .tail() #끝에서 5개
- 그룹별 중복제거
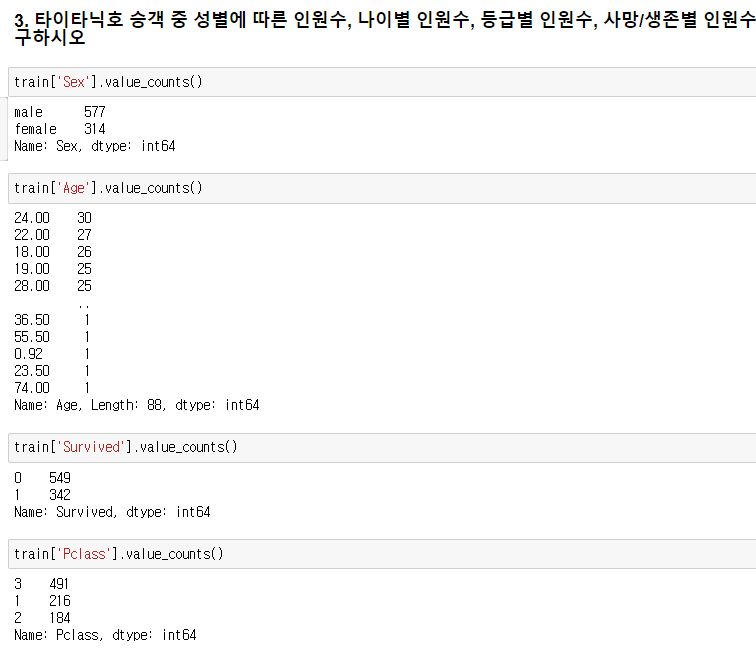
.value_counts()
카테고리 생성
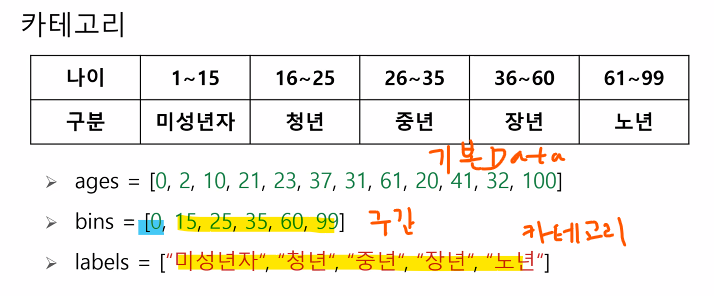

범위 해당이 안되는 데이터는 NaN으로 나옴
범위를 아래처럼 바꿔주자
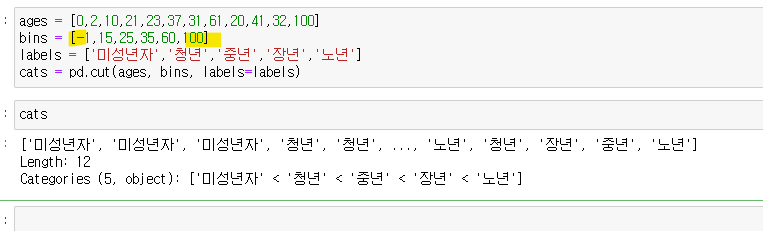

type- 타입확인, categories-인덱스확인할 수 있음
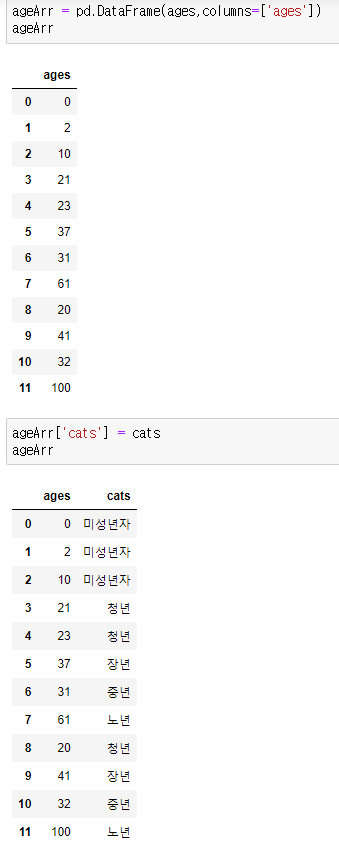
- DataFrame으로 만들어줌
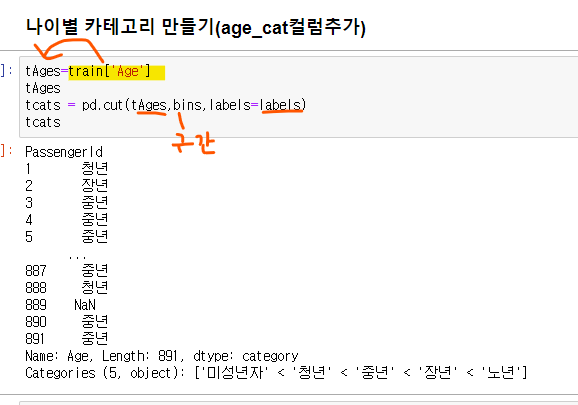
train 데이터에 나이별 카테고리 만들기
- 위의 구간, 라벨을 가져와서 적용하기
- DataFrame에 담아줌

각 라벨별 개수 구해줌
train에 새로운 컬럼 추가해줌
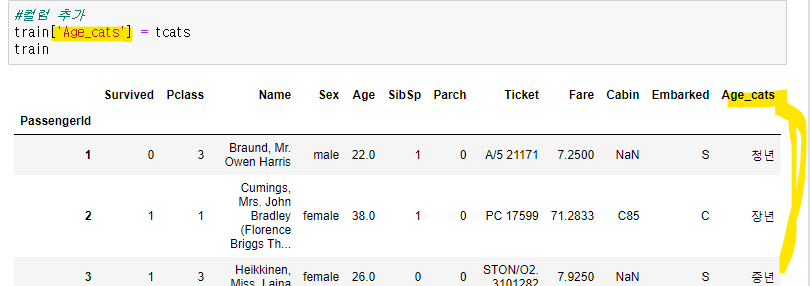
- 컬럼 추가된 모습
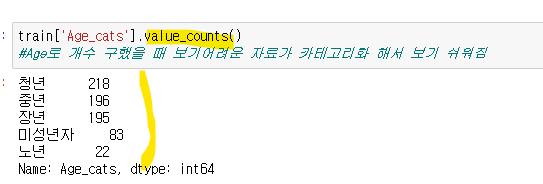
Age로 개수 구했을 때 보기어려운 자료가 카테고리화 해서 보기 쉬워짐
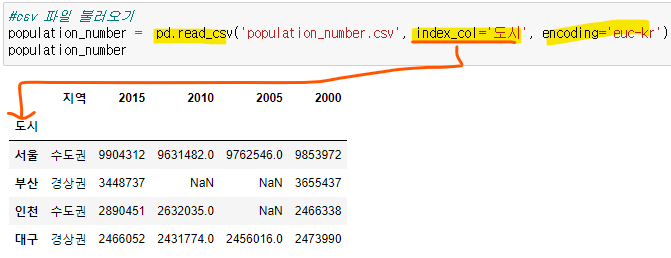
새로운 csv 파일 불러옴
- 인덱스 컬럼, 인코딩 해주기

- 합계구하는 함수 .sum()
기본값 : 컬럼별 합계
순위보는 함수로 학급별 순위 볼 수 있음
반대로 행 별 합계를 보고싶을 때 sum() 안에 axis = 1 로 줌 기본값: axis=0
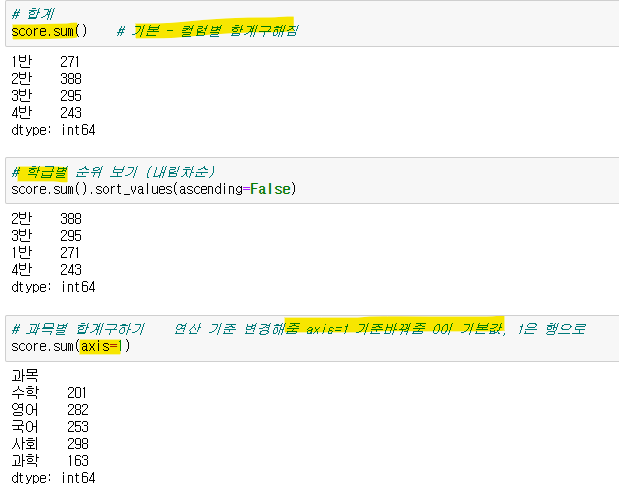
- 합계 열 만들기

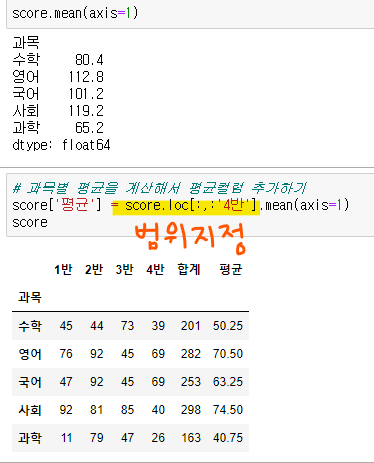
sum함수에 범위 지정없으면 여러번 실행시 누적되어 합계가 들어가기 때문에 범위를 지정해주는 게 좋다
score.loc[:,:'4반']loc 이용해 행,열 - 평균 컬럼 추가
타이타닉호 실습
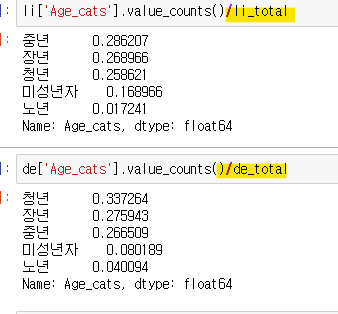
타이타닉호 승객 사망자 중 카테고리별 비율 (미성년자,청년,중년,장년,노년 승객비율)
생존자 중 카테고리별 비율
단, 그룹별 비율의 전체 합은 1이 되어야함)
- 생존자(Survived 컬럼) 의 전체 컬럼 개수 구하기

- boolean 색인 새로운 변수에 담아줌
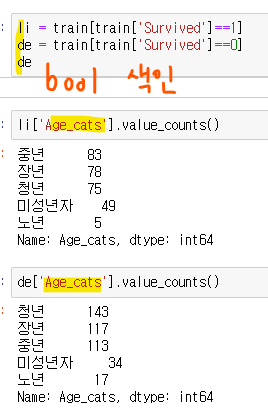
- 생존자 수 shape으로 확인 (행,열)로 나옴

- 총 수를 더해줌 sum이나 count 사용
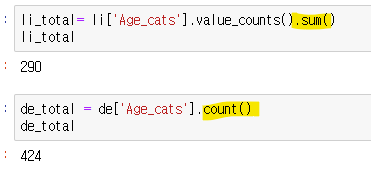
- 전체 수를 나눠줌 요소별
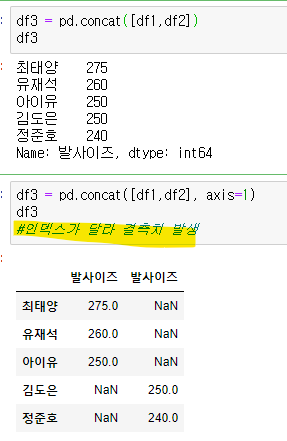
concat([a,b])
- a, b 는 시리즈나 데이터프레임
-concat은 먼저 쓰는 게 왼쪽(행)이 된다

범죄 현황 데이터 실습
-
외부파일 가져옴

-
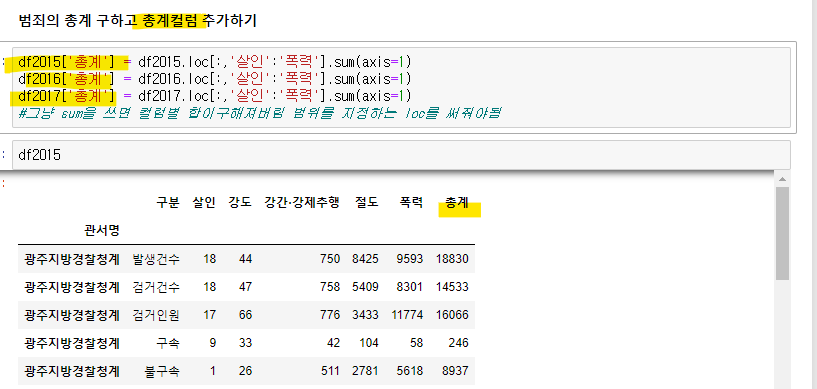
-
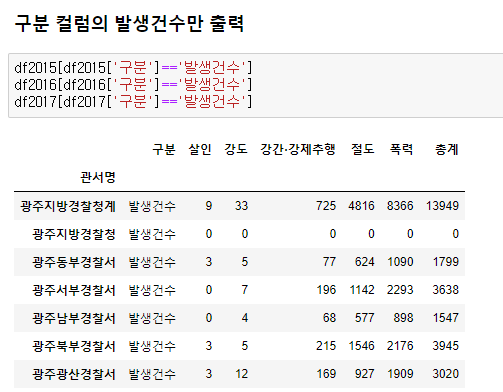
-
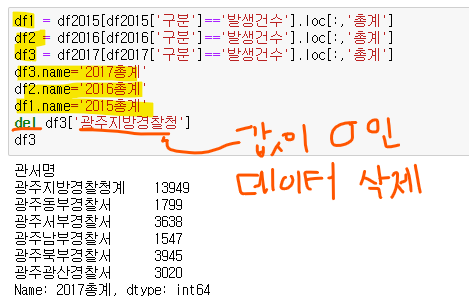
-

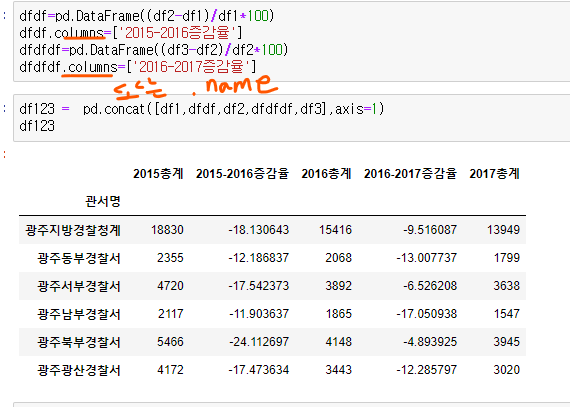
-
del 로 NaN이 나오는 컬럼을 삭제하거나
(del df3['컬럼명'] ) -
총 결과인 df123에서 drop 함수 :
df123.drop('광주지방경찰청')
drop은 일종의 뷰, 변화없음
---> 새롭게 대입하거나, inplace = True 를 넣어야 값이 변하게됨! -
또는 슬라이싱 :
df123.iloc[:-1]
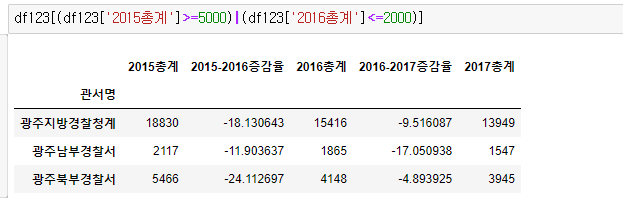
조건 여러개인 bool 색인
or | 한개
and & 한개
groupby
- 임의 데이터
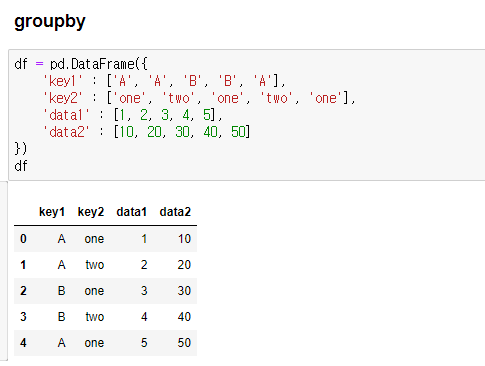
- 그룹별 데이터 확인 할 수 있음
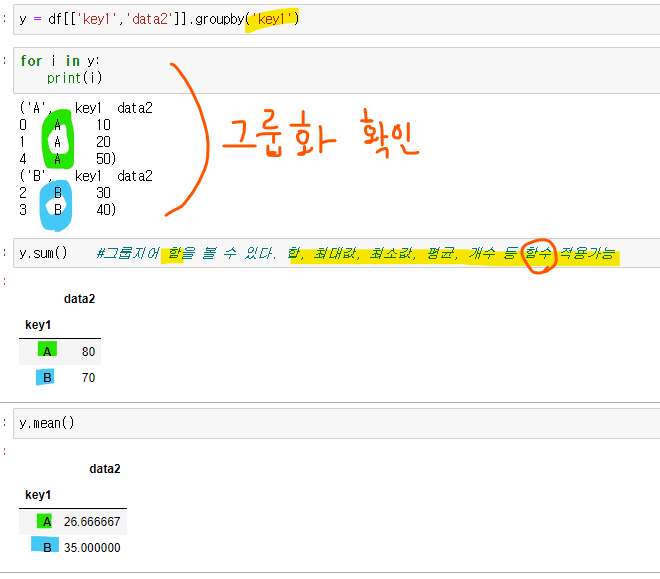
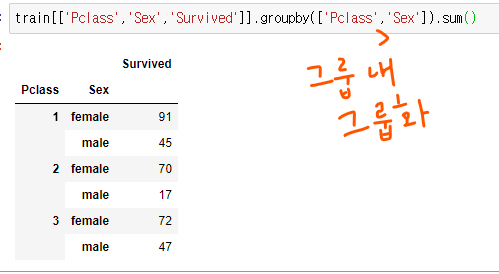
- 타이타닉 데이터에서
클래스, 성별,생존 컬럼 가져와서, 클래스, 성별 그룹화 한 후 생존의 합을 보여주는 데이터