크롤링
- 웹상의 컨텐츠를 수집하고 HTML 을 파싱해 필요한 데이터만 추출함
크롤링 과정 req -> parsing -> select
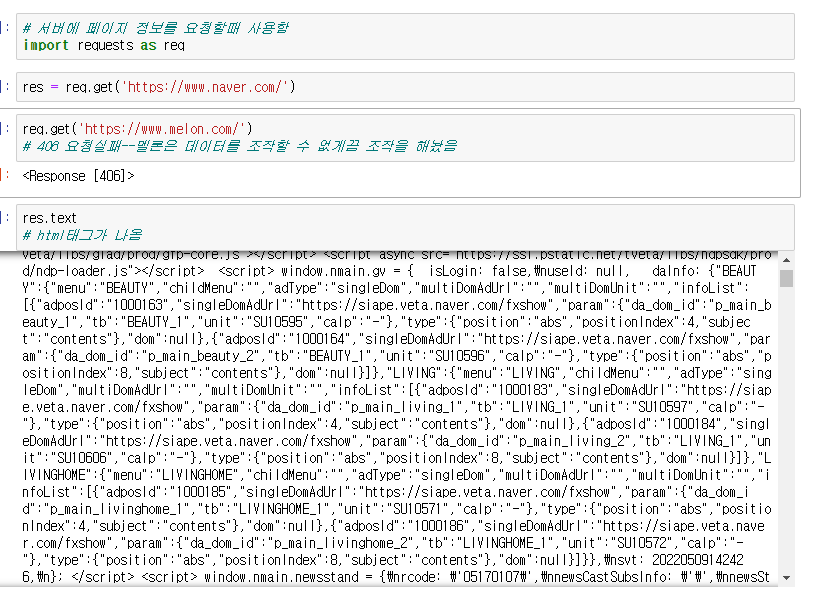
리퀘스트 사용하기
- 서버에 페이지 정보를 요청할때 사용함
import requests as req
BeautifulSoup 사용하기
- 내가 원하는 내용만 추출하겠다
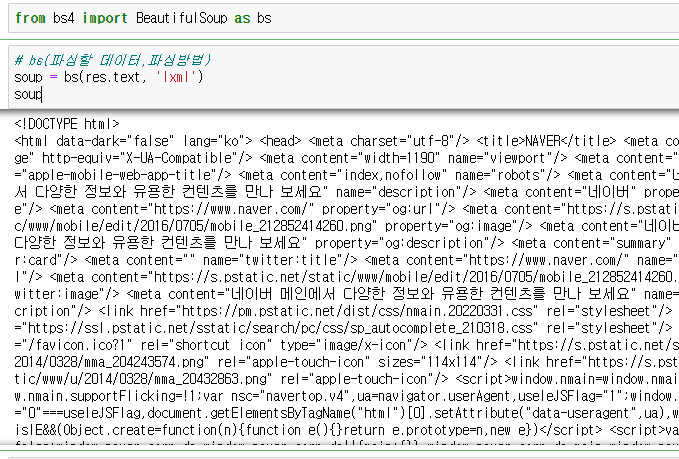
from bs4 import BeautifulSoup as bs - bs(파싱할 데이터,파싱방법)

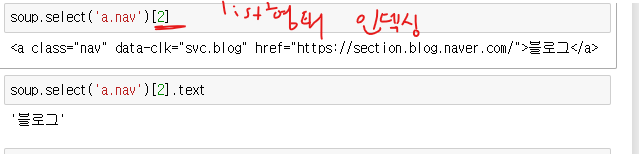
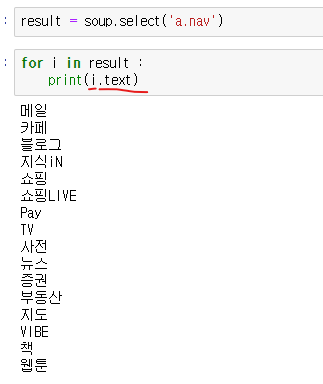
- 가져온 태그를 result 라는 변수에 넣어준다
리스트 형태이기때문에 반복문으로 텍스만 가져올 수 있음
배열을 선언해주고 차례로 넣어줌

네이버 날씨 정보 가져오기
- 네이버에서 현재 날씨를 검색 -> url 이 바뀌었으므로 req.get()안의 url을 변경해준다.
잘들어갔는지 확인까지 함
- html 태그를 파싱하는 작업
bs(req.get담은 변수.text, 'lxml')

- 태그 select
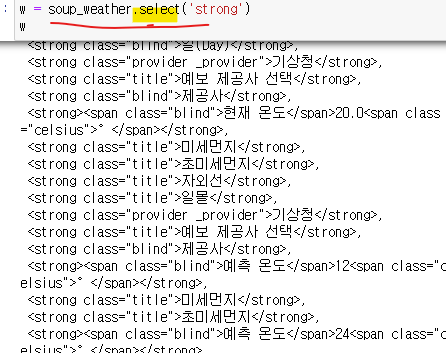
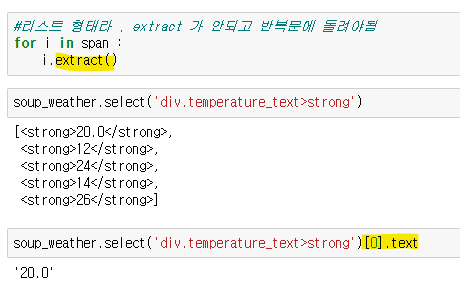
나는 이 예제에서 그냥 strong 태그를 가져와 텍스트를 새로운 배열에 넣어주고나서, 리스트에서 10번째인덱스를 인덱싱해왔는데..
만약 인덱스번호가 10번째가아니라 121번째처럼 세기 어려운 숫자였으면? -->그래서
더 정확한 방법은
가져오려는 strong태그의 부모 관계의 태그를 가져온다.
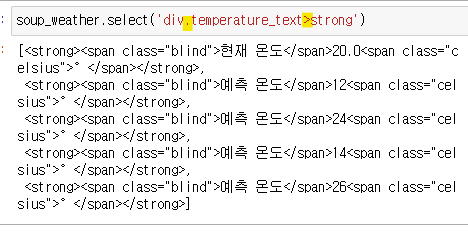
계층 선택자 활용한다 .과 >
가져온 태그에서 span태그를 지워줘야한다
선택자를 다시 지우고자하는 태그인 span으로 가져오고, 변수에 넣어줬다.\
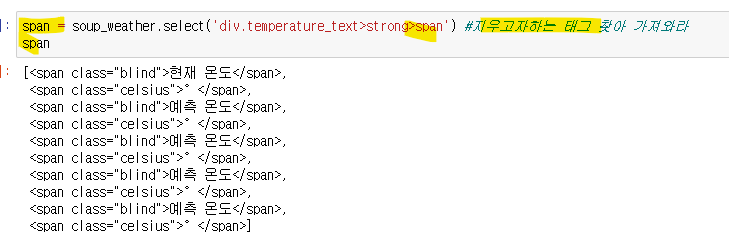
리스트형태라 바로 지울수 없고 반복문으로 돌려서 .extract() 함수 써줌
멜론 차트 가져오기
- url 변경
req.get('https://www.melon.com/')하게되면
Response [406]: 406 요청실패--멜론은 데이터를 조작할 수 없게끔 조작을 해놨음
그래서 header의 User-Agent값을 가져와야한다.
User-Agent는 키 밸류의 딕셔너리형태로 따옴표 주의해서 가져온다.
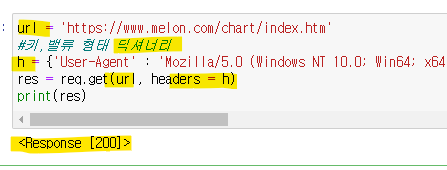
req.get(url, headers = h)
에서 headers=내가 가져온 User-Agent 담아준 변수 - 페이지 파싱
- 노래제목이 들어있는 rank01클래스를 선택해옴 select
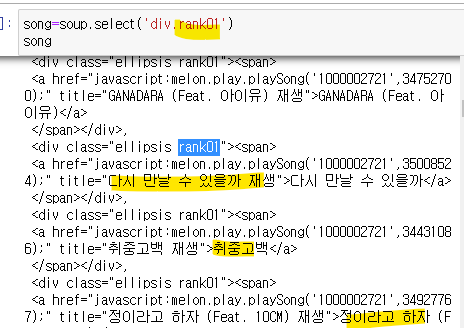
rank01과 ellipsis 클래스를 각 가져왔을 떄 길이를 분석해보자
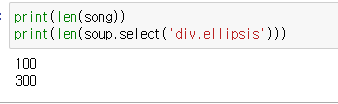
100, 300으로 가져와졌고, 최종으로 가져와야할 데이터는 top 100이므로 원래대로 가져와도 무방할 것으로 판단
하지만 원래는 a태그만 가져와도 됐었는데, top100이라는 지칭할만한 a태그의 특정 클래스가 없어서 rank101을 전부 가져온거였고
궁극적으로 필요한 a 태그를 select 하기 위해 계층선택자를 활용

for문에 넣어 주면 잘 출력된다!!

