
운영체제 수업 + Operating System Concepts 10E 정리 내용
Operating System Ch11 : Mass-Storage structure
Mass-Storage
1. Overview
- HDD (Hard Disk Drive)
- SSD (Solid State Disk)
- RAM disk : 전원이 들어와 있을 때 빠르게 저장되는 공간
- Magnetic tape : 단위당 가격이 싼 저장장치
Disk Attachment
1. Overview
- Host attached : 컴퓨터에 직렬로 연결 - SATA, PCI, IDE, SCSI
- Network attached : 네트워크로 연결 - NAS, SAN
2. Network attached Storage (NAS)
- NAS: 원격(소규모) 파일 시스템, firmware, os도 올라가 있음
- 특징
- ip 기반으로 동작
- 네트워크를 통해 컴퓨터와 붙어서 사용되기 때문에 NAS와 컴퓨터는 별개의 시스템.
- 붙어서 사용되는 컴퓨터가 NAS로 정보를 요구하면 NAS에서는 스스로 해당 요구를 수행하고 결과로 ip를 전해준다.
- file level로 접근
- 종류
- NFS(linux), CIFS(windows)
- 용도
- 사설 cloud storage, 데이터 공유, 웹페이지 호스팅, 웹서버 구축, 미디어 파일 저장
3. Storage-Area Network (SAN)
- SAN: 서버의 storage 시스템
- NAS와 차이점: fibre channel로 연결되어있는 파일 시스템 네트워크로 구성되어 파일 시스템을 서버와 연결시킴 -> 컴퓨터에 직렬로 연결한 것 처럼 사용이 가능 (NAS는 통신에서 bottle neck이 발생)
- 특징
- storage array 들과 SAN으로 연결된 것 전체를 파일 시스템으로 묶어서 생각할 수 있다.
- block 단위의 접근 : 서버 시스템으로 구성된 구조이기 때문에 file level로 접근하지 않아도 된다.
4. Storage Architecture
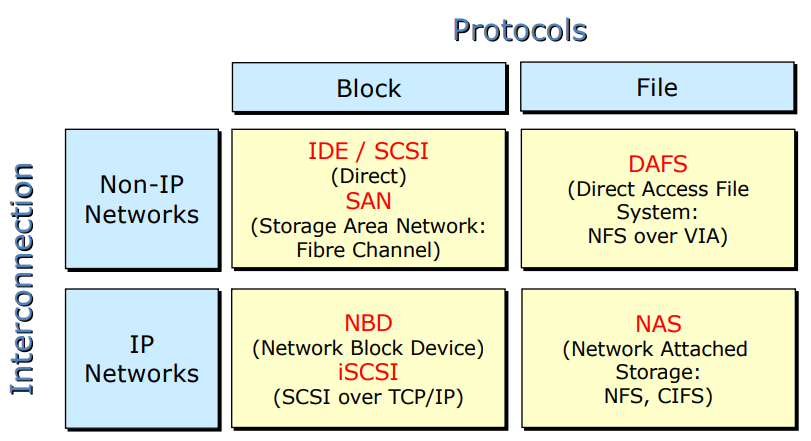
- NBD, DAFS, iSCSI 는 사용하지 않음
HDD
1. Overview
- Disks are messy physical devices
- OS hide mess from higher-level software
- OS provide different levels of disk access
- physical disk block
- disk logical block
- logical file
- 최소 단위는 sector / sector가 모여서 track / 같은 위치의 track을 모은 것이 cylinder
2. Interacting with disks
- 디스크는 cylinder #, surface #, track #, sector # 등 다양한 정보를 요구한다.
- 과거에는 OS가 세부적인 정보를 관리했지만(disk 의 파라메터를 전부 알고 있어야 함) 현재는 하드웨어 디스크 controller가 대신 해준다. -> OS가 가벼워짐
3. Disk Performance
- Disk performance
- transfer: 읽은 데이터를 보내는데 걸리는 시간
- rotation: 원하는 데이터를 찾는데 디스크가 돌아가는 시간
- seek: 원하는 데이터를 찾는데 arm이 움직이는 시간
- seek의 시간이 나머지 두 단계보다 많이 소모된다.
- Disk Scheduling
- 데이터를 읽으려고 할 때 데이터가 쪼개져 있다면, 어떤 순서로 읽는 것이 효율적일지 생각하기
- seek time을 최소화 하기
Disk Scheduling
1. FCFS
- 먼저 들어온 것 부터 차례대로 실행
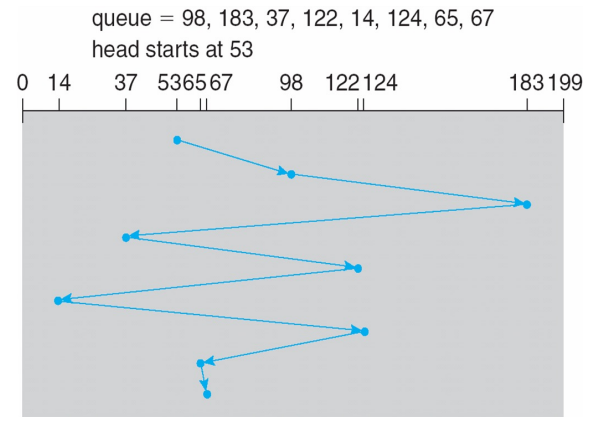
2. SSTF
- Shortest Seek Time First
- 현재 시점 head와 가까이 있는 것 부터 읽기 (SJF와 유사)
- 가장 많이 사용되는 방식
- 문제점 : 현재 읽고 있는 데이터 주변을 위주로 읽게 되므로 starvation이 발생한다. -> 여러 방식으로 해결하여 현재 실제로 사용되는 방식
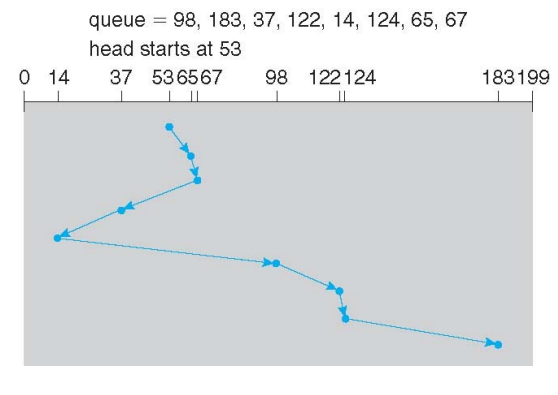
3. SCAN
- 엘레베이터를 타는 것과 유사
- 가는 방향의 끝까지 간 후, 반대 방향의 끝까지 탐색
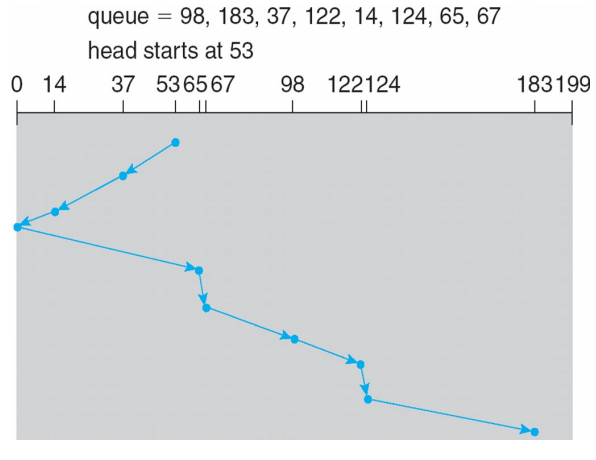
4. C-SCAN
- 읽는 방향을 한쪽으로 정해두기
- 정한 방향의 끝까지 탐색을 하면 반대쪽 끝으로 이동해서 원래 방향으로 다시 탐색
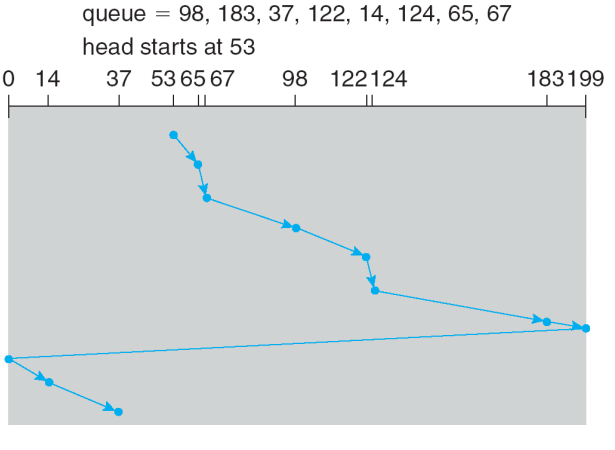
5. C-LOOK
- 현재 가는 방향을 읽으면서 끝에 존재하는 데이터까지만 간 후 반대 방향으로 읽기 시작, 반대방향에서도 마지막 데이터가 존재하는 곳 까지만 간 후 다시 반대 방향으로 읽기
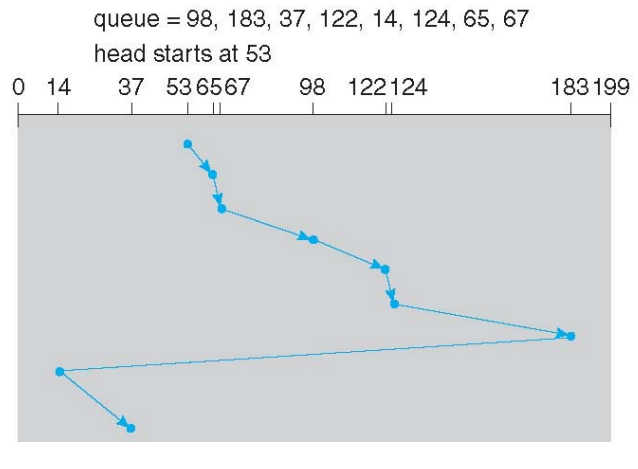
6. Selecting a Disk-Scheduling Algorithms
- 위에서 언급한 방식들의 성능은 거의 다 비슷하다.
- disk scheduling에서 가장 중요한 점은 읽어야 하는 데이터가 어떤 방식으로 디스크에 쓰여있는지를 아는 것이 가장 중요하다.
cf) window 조각모음 - PC 에서는 크게 중요하지 않은 동작이지만, 서버와 같이 데이터가 매우 큰 경우에 중요한 이슈가 된다.
Disk Controllers
1. Overview
- 디스크 컨트롤러가 점점 발전하고 있다.
- CPU와 독립적으로 CPU의 명령을 받아서 처리한다.
- intelligent features
- Read-ahead: the current track
- Caching: frequently-used blocks
- Request reordering: for seek and/or rotational optimality
- Request retry on hardware failure
- Bad block identification
- Bad block remapping: onto spare blocks and/or tracks
2. Swap-Space Management
- Swap space: virtual memory가 disk공간을 메모리 공간처럼 쓰는 것
- Windows: 윈도우가 설치된 디스크(파티션)에 파일 시스템으로 만들어서 사용 -> 늘리고 줄이는 것이 쉽다.
- Linux: 별도의 파티션을 만들어서 제공 -> 늘리고 줄이는 것은 어렵지만, protection 기능은 더 좋다.
RAID (Redundant Array of Inexpensive Disks)
1. Overview
- 하드 디스크를 따로 하나씩 쓰면 여러 단점이 존재
- 디스크는 처음부터 끝까지 연결되어 있어서 중간에 하나라도 문제가 생기면 해당 디스크를 전부 다 사용하지 못한다.
- 성능과 신뢰성을 높이기 위해서 RAID를 사용한다.
- RAID 다수의 디스크를 하나의 디스크처럼 묶어서 사용하는 기술
- 신뢰성
- do nothing
- Mirroring
- A디스크와 B디스크에 똑같은 데이터를 저장해두어서 A디스크에서 문제가 생기면 B디스크를 사용하여 문제를 해결
- 단점: 신뢰성은 향상되지만 효율성이 낮아지게 된다.
- Error correcting
- A디스크의 오류가 생겼을 때 복구할 수 있는 코드를 만들어두기
- A디스크의 문제가 생기면 연산을 통해서 복구시키는 방식 (by error-correcting codes)
- 단점: error correcting code가 공간을 많이 차지한다.
- Error correcting + Mirroring
- error correcting 방식과 mirroring 방식의 장점을 가져와서 사용
- 성능 (by 병렬화)
- do nothing
- bit level
- 다수의 비트로 구성된 block을 비트 단위로 쪼개서 A,B디스크에 번갈아서 조각조각 나눠서 넣는 방식 (데이터를 분산시켜서 저장)
- block level
- OS가 디스크에 저장한 데이터의 최소 단위 그대로 번갈아서 A,B디스크에 넣기
- 성능 향상의 이유
- CPU가 데이터를 요구하면 RAID 방식은 A와 B디스크가 요구한 데이터의 조각을 각각 동시에 읽어올 수 있기 때문에 디스크를 하나 사용할 때 보다 2배 빠른 속도로 읽을 수 있다.
- 디스크가 n개가 되면 n배 빠른 성능을 제공한다.
- cf) locality 특성 때문에 block단위로 쪼개는 방식이 더 효율적이다.
2. RAID Levels
- RAID 0
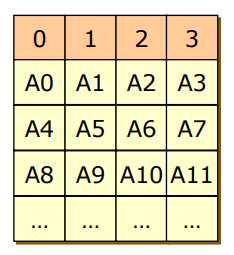
- 신뢰성 0, 성능에 올인한 방식
- block 레벨로 쪼갠 후 병렬화 하기
- 성능은 좋지만 신뢰성은 RAID를 안 쓸때 보다 더 안좋아진다.
- RAID 1
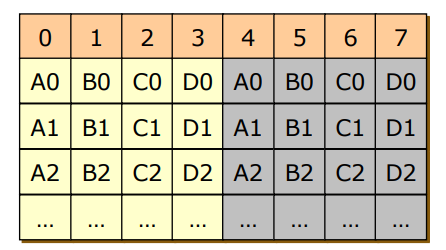
- RAID 0 방식에 신뢰성을 추가, 원래 쓰던 데이터를 복사해서 Mirroring 한 방식
- Mirroring 방식만으로 신뢰성을 확보 -> 용량을 많이 차지하는 단점 존재
- RAID 2
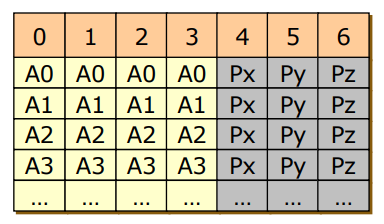
- bit 레벨로 쪼개기 -> 성능
- error correcting code -> 신뢰성
- 다른 방식보다 큰 장점은 없다.
- RAID 3
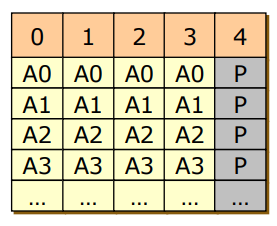
- bit 레벨로 쪼개기
- 간소화 시킨 error correcting 사용 (Parity)
- cf) bit 레벨로 쪼개는 방식은 실제로 사용하는 방식은 아니다.
- RAID 4
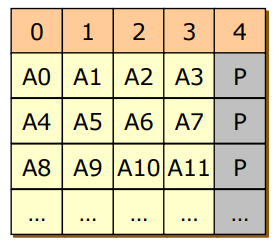
- RAID 3방식을 block 레벨로 쪼개는 방식으로 바꾼 것
- 성능이 별로 좋지 않다.
- parity 가 하나의 디스크에 모두 존재하기 때문에 block이 수정되면 parity가 계속해서 수정되므로 4번 디스크의 접근이 많아져 bottle neck이 발생한다.
- RAID 5
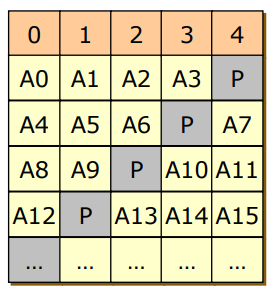
- RAID 4의 문제를 해결한 방식
- parity를 분산시킨 것 -> 각 디스크 마다 하나씩 존재하도록 분산
- 실제로 사용함
- RAID 6
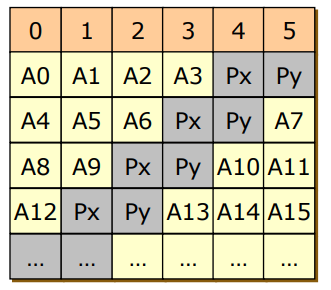
- RAID 5의 parity를 error correcting 방식으로 바꾼 것
- RAID 0+1
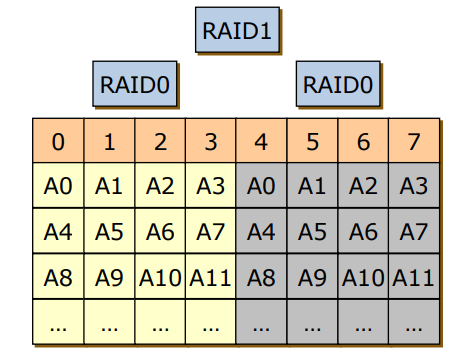
- RAID 0와 RAID 1을 실행하여 구성
- 성능면에서 최고와 신뢰성에서 최고의 방식을 합쳐서 사용
- 단점: 1번 디스크에서 오류가 나면 0,2,3번 디스크를 사용하지 못함
- RAID 10
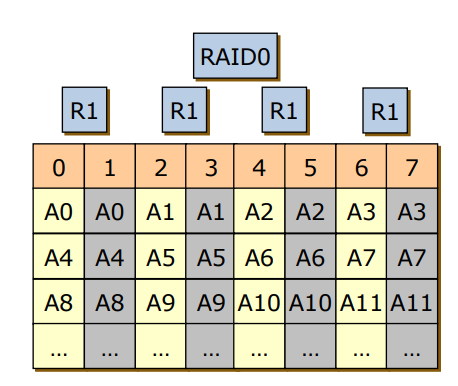
- RAID 0+1을 개선한 방식
- RAID 1을 먼저 수행 (RAID 0+1의 수행 순서의 반대)
- 2번 디스크가 고장나게 되면 나머지 디스크를 다 사용할 수 있으며 고장난 2번 디스크는 3번 디스크로 대체해서 사용한다.
- 가장 좋은 방식
