matrix 계산을 쉽게하기 위해서 lower triangle과 upper triangle로 나누는 방식
Transpose
C=⎣⎢⎡135246⎦⎥⎤
CT=[123456]
Partitioned Matrix
matrix의 column이나 row끼리 나누는 것
B=[123456]
column 기준으로 나눈 경우
B=[u1,u2,u3]
u1=[12] u2=[34] u3=[56]
Eigenvalue & Eigenvector
vector u , scalar λ, linear transformation matrix A
λu 는 방향이 같지만, 크기가 다른 벡터
A의 eigen vector는 u (u는 0이 아님)
Au=λu 식에서 λ는 eigen valueu는 eigen vector이다.
eigen vector는 선형변환을 해도 방향이 변하지 않는 벡터를 말한다.
Eigen Decomposition of a Matrix
AP=PD
matrix A : eigen value λ1,λ2,..로 구성
위의 eigen value와 상응되는 eigen vector를 X1,X2,..
P=[X1,X2,...Xk] , D는 성분이 λ의 모음인 diagonal 행렬
그 결과 AP = PD가 된다.
AP의 각 성분은 AX1,AX2, ...이고, PD의 각 성분은 λ1X1,λ2X2,... 이므로
AP=PD -> A=PDP−1
A2=(PDP−1)(PDP−1)
=PD2P−1
=> An=PDnP−1
=> A−1=PD−1P−1
Singular Value
singular value : ATA의 eigen value의 square root
singular value denote : σ1,...σi
i는 matrix A 의 rank를 말한다.
det(ATA−λI)=0이 되는 λ값의 square root가 singular value
Rank
특정 matrix에 있어서 linearly independent 한 column의 수
linearly independent : matrix의 어떤 column성분을 다른 column들로 나타낼 수 없는 경우
row reduction을 통해 rank를 구할 수 있다.
row reduction 이후 non-zero인 row의 수가 rank 이다.
SVD
A=UΣV∗
U : m x m complex unitary matrix
Σ : m x n rectangular diagonal matrix
V : n x n complex unitary matrix
실수 공간에서 A=UΣVT 로 나타낼 수 있다.
AAT의 eigen vector로 U의 columns 구성
-> left singular vectors of A
ATA의 eigen vector로 V의 columns 구성
-> right singular vectors of A
ATA 혹은 AAT의 singular value 로 구성된 diagonal matrix -> Σ
unitary matrix 특성
U∗U=UU∗=UU−1=I
SVD의 기하학적 의미
eigen value는 공간상에서 얼만큼 땡길지에 대한 값
eigen vector는 공간상에서 얼만큼 땡길지에 대한 방향
calculate example
A=[430−5]
일 때
AAT=[430−5][403−5]=[16121234]
det(ATA−λI)=0을 구하면
eigen vector v1=[0.51], v2=[−11]
singular value σ1=210,σ2=10
...
Moore-Penrose inverse
pseudo inverse를 구하는 가장 유명한 방법 : A†
pseudo inverse : for best fit(least squares) solution
Pseudo-Inverse and Least Squares
Least Squares : overdetermined system 을 풀기 위한 방법
-> 관측값이 너무 많은 경우 하나의 식으로 수렴하기 어렵다
선형 방정식
관측된 모션은 실제로는 곡선이지만, dt라는 짧은 시간동안 직선운동을 한다고 가정하여 y=dx+c의 식으로 표현할 수 있다.
세가지 점을 관측했다고 했을 때 -> c+dx1=y1,c+dx2=y2,c+dx3=y3
1) 관측된 세개의 점이 error값이 없다면 그냥 방정식의 값을 풀 수 있다.
2) 관측된 점 중 error값이 있다면, 방정식을 못풀게 된다. -> SSE로 풀기
SSE : 각 방정식에 error 값을 더해주고 error 값을 최소화 하는 방식
-> c+dx1+e1=y1,c+dx2+e2=y2,c+dx3+e3=y3
-> SSE=(c+dx1−y1)2+(c+dx2−y2)2+(c+dx3−y3)2
-> SSE를 0에 가깝도록 만드는 방식으로 풀기
matrix
위에서 언급한 내용을 matrix 형태로 바꾸면 y=Ax+e 형태로 바꿀 수 있고, 목표는 eTe를 최소화 (0에 가깝게) 하는 것이다.
minxeTe=(y−Ax)T(y−Ax)
-> minxeTe=yTy−2xTATy−xTATAx
-> ∂x∂eTe=−2ATy+2ATAx=0 로 표현된다. (∂b∂bTXTXb=2XTXb 에 의해서)
=> 결론적으로 ATAx=ATy -> x=(ATA)−1ATy -> x=A−1y
결론
A의 pseudoinverse 를 A†=(ATA)−1AT 로 표현할 수 있다
Pseudo-Inverse and SVD
쉬운 상황 : Σ 가 m x m diagonal matrix 인 경우
A=UΣVT -> A−1=VΣ−1UT
Σ의 inverse는 각 singular value로 이루어진 값들을 역수를 취해주면 되기 때문에 계산하기 쉽다.
어려운 상황 -> Pseudo-Inverse 사용 : Σ가 m x n 인 경우
이 경우 Σ의 inverse에서 분모에 0이 들어가버린다.
-> Destroy (차원 이동에 있어서 손실이 생긴다)
-> 0이 곱해지기 때문에
-> inverse를 구할 수 없다
그럼 손실이 되지 않게 할 수 있지 않을까? -> pseudo inverse!!
-> A†=VΣ†UT
Jacobian Pseudo-inverse
이 방식을 사용할 때는 matrix가 square가 아니거나 invertible 한 경우
JΔθ=e 의 least square의 값을 구할 때 가장 좋은 해결책이다.
J−1e=Δθ 의 J−1를 구하는 것이 목표!
하지만 J−1은 없는 경우도 있다. 그 경우 J†로 계산하기!!
Jacobian 을 푸는 여러가지 경우..
1) m≥n이고, J가 full column rank인 경우 JTJ 계산 => moore-penrose
ex) JΔθ=e -> JTJΔ=JTe -> Δθ=(JTJ)−1JTe
-> (JTJ)−1JT 는 J†
2) m<n이고 J가 full row rank인 경우 JJT 계산 => moore-penrose
3) J가 full rank가 아닌 경우 SVD를 통해 J† 계산
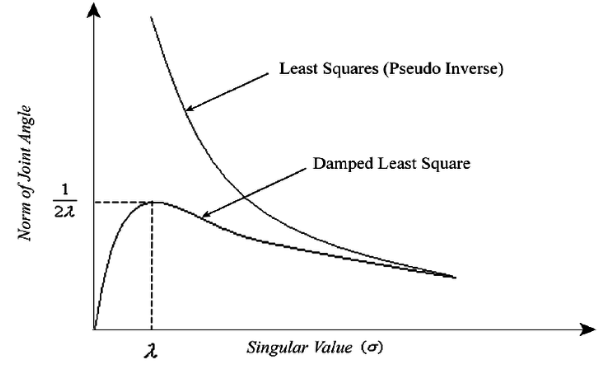
Damped Least Squares (DLS)
least square의 경우 singularity가 0에 가까이 가게 되면 오류가 생긴다는 문제가 생긴다!!
이 문제를 해결하기 위해서 σ1 대신에 σ+λ1로 계산해준다. 이 λ 는 사람이 정해주어야 하는 값이다.
∥JΔθ−e∥2+λ2∥Δθ∥2 -> damping을 적용한 식
Pseudo-Inverse Damped Least Squares
JT(JJT+λ2I)−1=∑i=1rσi2+λ2σiviuiT
-> J†=∑i=1rσi−1viuiT
-> 원래 pseudo inverse 식에서 λ2I를 damping하는 값으로 억지로 끼워넣어서 구한 식
그림에서 보는 것 처럼 least square는 0에 가까워질수록 해가 발산해버리기 때문에 문제가 발생한다.
damped least square는 λ라는 값을 통해 0에 가까운 값들을 억지로 변형시켜서 안정된 해를 구하는 것