1. 관계형 데이터베이스 개요
DB : 용도 & 목적에 맞는 데이터들끼리 모아서 저장하는 공간
RDB(관계형 데이터베이스) : 관계형 데이터 모델에 기초를 둔 DB
2차원 테이블 간의 관계를 정의함
RDBMS : RDB를 관리, 감독하기 위한 시스템
ex) Oracle, MySQL, MariaDB, PostgreSQL...
TABLE : RDB의 기본 단위
DB는 #개의 테이블로 구성됨
- 컬럼(Column) : 각각의 세로 열
- 로우(Row) : 각각의 가로 열
SQL(Structured Query Language) : RDB에서 데이터를 다루기 위해 사용하는 언어
2. SELECT 문
1) SELECT
- 저장되어 있는 데이터를 조회할 때 사용하는 명령어
SELECT 컬럼1, 컬럼2, ... FROM 테이블 WHERE 컬럼1 = '아무개';
SELECT * FROM 테이블;- 별도의 WHERE 절이 없으면 테이블의 전체 ROW가 조회됨
- 테이블명 / 컬럼명에 별도의 별칠(Alias)을 붙여줄 수 있음 (줄임말 같은 느낌)
SELECT B.BAND_NAME, BM.MEMBER_NAME
FROM BAND B, BAND_MEMBER BM2) 산술 연산자
- NUMBER DATE 유형의 데이터와 같이 사용 가능
| 연산자 | 의미 | 우선순위(= 계산 순서) |
|---|---|---|
| ( ) | 괄호로 우선순위 조정 가능 | 1 |
| * | 곱하기 | 2 |
| / | 나누기 | |
| + | 더하기 | 3 |
| - | 빼기 | |
SELECT COL1+COL2 AS A,
(COL1-COL2)*COL1 AS B
FROM SAMPLE;- 다른 컬럼끼리의 연산에 NULL이 포함돼 있으면 결과값도 NULL이 됨
3) 합성 연산자 (||)
- 문자 & 문자를 연결할 때 사용
// SQL 단어 만들기
SELECT 'S'||'Q'||'L' AS SQL
FROM DUAL;
// COL1과 COL2 띄어쓰기로 연결
SELECT COL1 || ' ' || 'COL2' AS RESULT
FROM SAMPLE;3. 함수
기본 내장 함수를 사용할 땐 FROM DUAL;로 작성 (DUAL 테이블에서 가져옴)
1) 문자 함수
📌 CHR(ASCII 코드) : 아스키 코드를 인수로 입력했을 때 매핑되는 문자가 뭔지 알려주는 함수
ASCII 코드 : 총 128개의 문자를 숫자로 정의함
ex) CHR(65) -> A
📌 LOWER(문자열) : 문자열을 소문자로 변환해줌
ex) LOWER('GAWON') -> gawon
📌 UPPER(문자열) : 문자열을 대문자로 변환해줌
ex) UPPER('gawon') -> GAWON
📌 LTRM(문자열[, 특정문자]) ([] : 옵션)
- 특정문자 명시 X : 문자열의 왼쪽 공백 제거
- 특정문자 명시 O : 문자열을 왼쪽부터 한 글자씩 특정 문자와 비교
- 특정문자에 포함돼 있으면 제거 / 없으면 제거 멈춤
ex) LTRIM(' JENNIE') -> JENNIE
LTRIM('블랙핑크', '블랙') -> 핑크
📌 RTRIM(문자열 [, 특정문자]) ([] : 옵션)
- 특정문자 명시 X : 문자열의 오른쪽 공백 제거
- 특정문자 명시 O : 문자열을 오른쪽부터 한 글자씩 특정 문자와 비교
-- 특정문자에 포함돼 있으면 제거 / 없으면 멈춤
ex) RTRIM('JENNIE ') -> JENNIE
RTRIM('블랙핑크', '핑크') -> 블랙
컴퓨터에서 trim (트림)이라는 것은 "불필요한 부분을 잘라낸다"는 뜻입니다.
프로그래밍 언어 등에서의 trim 은, 주로 "문자열 앞뒤의 공백 문자"를 제거하는 것을 말합니다.
📌 TRIM([위치][특정 문자] [FROM] 문자열) ([] : 옵션)
- 옵션 X : 문자열의 왼,오른쪽 공백 제거
- 옵션 O : 문자열을 위치(LEADING / TRAILING / BOTH)로 지정된 곳부터 한 글자씩 특정 문자와 비교 -> 같으면 제거/ 다르면 멈춤
-- LEADING : 선행 / TRAILING : 후행 / BOTH : 동시에
-- 특정 문자 : 한 글자만 지정 가능
ex) TRIM(' JENNIE ') -> JENNIE
TRIM(LEADING '블' FROM '블랙핑크') -> 랙핑크
TRIM(TRAILING '크' FROM '블랙핑크') -> 블랙핑
📌 SUBSTR(문자열, 시작점[, 길이]) ([] : 옵션)
: 문자열의 원하는 부분만 잘라서 반환해주는 함수
- 길이 명시 X : 문자열의 시작점부터 끝까지 반환됨
- 길이가 초과하면 있는데까지만 반환됨
ex) SUBSTR('블랙핑크제니', 3, 2) -> 핑크
ex) SUBSTR('블랙핑크제니', 3) -> 핑크제니
ex) SUBSTR('블랙핑크제니', 6,3) -> 니
📌 LENGTH(문자열) : 문자열의 길이 반환
ex) LENGTH('JENNIE') -> 6
📌 REPLACE(문자열, 변경 전 문자열 [, 변경 후 문자열] ([] : 옵션)
: 문자열에서 변경 전 문자열을 찾아 변경 후 문자열로 바꿔주는 함수
- 변경 후 문자열 명시 X : 문자열에서 변경 전 문자열 제거함
ex) REPLACE('블랙핑크제니', '제니', '지수') -> 블랙핑크지수
REPLACE('블랙핑크제니', '제니') -> 블랙핑크
2) 숫자 함수
📌 ABS(수) : 수의 절대값 반환
📌 SIGN(수) : 수의 부호 반환
- 양수 : 1 / 음수 : -1 / 0이면 0 반환
📌 ROUND(수[, 자릿수]) ([] : 옵션)
: 수를 지정된 소수점 자릿수까지 반올림하여 반환
- 자릿수 명시 X : 기본값은 0 -> 반올림된 정수로 반환
- 자릿수가 음수 : 지정된 정수부를 반올림
-- ex) -1이면 일의 자리, -2이면 십의 자리...
ex) ROUND(163.76, 1) -> 163.8
ROUND(163.76, -2) -> 200
📌 TRUNC(수[, 자릿수]) ([] : 옵션)
: 수를 지정된 소수점 자릿수까지 버림하여 반환
- 자릿수 명시 X : 기본값은 0 -> 버림된 정수로 반환
- 자릿수가 음수 : 지정된 정수부를 버림
-- ex) -1이면 일의 자리, -2이면 십의 자리...
📌 CEIL(수) : 소수점 이하의 수를 올림한 정수 반환
ex) CEIL(72.86) -> 73
CEIL(-72.86) -> -72
📌 FLOOR(수) : 소수점 이하의 수를 버림한 정수 반환
📌 MOD(수1, 수2) : 수1을 수2로 나눈 나머지 반환
- 수2가 0이면 수1가 반환됨
- 수1, 수2 둘다 음수이면 나머지도 음수로 반환됨
ex) MOD(15, 7) -> 1
MOD(15, -4) -> 3
MOD(15, 0) -> 15
MOD(-15, -4) -> -3
3) 날짜 함수
📌 SYSDATE : 현재의 연, 월, 일, 시, 분, 초 반환
SELECT SYSDATE FROM DUAL; // 2022-08-28 22:08:08📌 EXTRACT(특정 단위 FROM 날짜 데이터) : 날짜 데이터에서 특정 단위(YEAR, MONTH, DAY, HOUR, MINUTE,SECOND)만을 출력해서 반환
SELECT EXTRACT(YEAR FROM SYSDATE) AS YEAR,
EXTRACT(MONTH FROM SYSDATE) AS MONTH,
EXTRACT(DAY FROM SYSDATE) AS DAY
FROM DUAL;📌 ADD_MONTHS(날짜 데이터, 특정 개월 수) : 날짜 데이터에서 특정 개월 수를 더한 날짜 반환
- 날짜의 이전 달 / 다음 달에 기준 날짜의 일자가 존재 X -> 해당 월의 마지막 일자 반환됨
SELECT ADD_MONTHS() AS YEAR,
ADD_MONTHS() AS MONTH,
FROM DUAL;4) 변환 함수
(1) 명시적 형변환 & 암시적 형변환
- 명시적 형변환 : 변환 함수를 사용하여 데이터 유형 변환을 명시적으로 나타냄
- 암시적 형변환 : 데이터베이스가 내부적으로 알아서 데이터 유형을 변환함
암시적 형변환의 ex)
조건절에서 VARCHAR 유형의 BIRTHDAY 컬럼을 숫자와 비교할 경우
내부적으로 BIRTHDAY 컬럼을 NUMBER형으로 변환해줌
SELECT*FROM WHERE BIRTHDAY = 20020304;
// 내부적으로 이렇게 동작해줌 ↓
SELECT*FROM WHERE TO_NUMBER(BIRTHDAY) = 20020304;but 암시적 형변환 -> 성능 저하, 에러날 수 있음
되도록 명시적 형변환 사용하는 게 좋음 !
(2) 명시적 형변환에 쓰이는 함수
📌 TO_NUMBER(문자열)
: 문자열 -> 숫자형으로 변환
ex) TO_NUMBER('1234') -> 1234
TO_NUMBER('abc') -> 에러
📌 TO_CHAR(수 / 날짜 [, 포맷])
: 수 / 날짜형 -> 포맷 형식의 문자형으로 변환
ex) TO_CHAR(1234) -> '1234'
현재 시간 나타낼 때
TO_CHAR(SYSDATE, 'YYYYMMDD HH24MISS')
📌 TO_DATE(문자열, 포맷)
: 포맷 형식의 문자형 -> 날짜형으로 변환
ex) TO_DATE('20210602', 'YYYYMMDD') -> 2021-06-02
| 포맷 표현 | 의미 |
|---|---|
| YYYY | 년 |
| MM | 월 |
| DD | 일 |
| HH | 시(12) |
| HH24 | 시(24) |
| MI | 분 |
| SS | 초 |
5) NULL 관련 함수
📌 NVL(인수1, 인수2)
- 인수1의 값이 NULL일 경우 인수2 반환
- NULL이 아닐 경우 인수1 반환
📌 NULLIF(인수1, 인수2)
- 인수1 = 인수2 -> NULL 반환
- 다르면 -> 인수1 반환
📌 COALESCE(인수1, 인수2, 인수3 ...)
: NULL이 아닌 최초의 인수를 반환
6) CASE
함수와 성격이 같지만 표현 방식이 함수보단 구문에 가까움
'~이면 ~이고, ~이면 ~이다' 식으로 표현
오라클의 DECODE 함수와 같은 기능함
ex) 다음 구문은 모두 같은 결과값 반환함, [ ]는 옵션
CASE WHEN SUBWAY_LINE = '1' THEN 'BLUE'
WHEN SUBWAY_LINE = '2' THEN 'GREEN'
WHEN SUBWAY_LINE = '3' THEN 'ORANGE'
[ELSE 'GRAY']
END
CASE SUBWAY_LINE
WHEN '1' THEN 'BLUE'
WHEN '2' THEN 'GREEN'
WHEN '3' THEN 'ORANGE'
[ELSE 'GRAY']
END
DECODE(SUBWAY_LINE, '1', 'BLUE', '2', 'GREEN', '3', 'ORANGE'[, 'GRAY'])4. WHERE 절
- INSERT를 제외한 DML문 수행 시 원하는 데이터만 골라 수행할 수 있도록 해주는 구문
- UPDATE, DELETE에도 마찬가지
💡 WHERE문의 위치?
- SELECT 컬럼명1, 컬럼명2 ... FROM 테이블명 WHERE 조건절;
SELECT *
FROM ENTERTAINER
WHERE NAME = '이지은'- UPDATE 테이블명 SET 칼럼명 = 새로운 데이터 WHERE 조건절;
UPDATE ENTERTAINER SET ACENCY_NAME = '빅히트뮤직' WHERE NAME = '김태형';- DELETE FROM 테이블명 WHERE 조건절;
DELETE FROM ENTERTAINER WHERE NAME = '김태형';1) 비교 연산자
=, <, <=, >, >=
2) 부정 비교 연산자
| 연산자 | 의미 | 예시 |
|---|---|---|
| != | 같지 않음 | |
| ^= | 같지 않음 | |
| <> | 같지 않음 | where col <> 10 |
| not 컬럼명 = | 같지 않음 | where not col = 10 |
| not 컬럼명 > | 크지 않음 | where not col > 10 |
- 논리 연산자 처리 순서 : ( ) -> NOT -> AND -> OR
- NULL과의 연산(+, -, *, /) 결과는 항상 NULL임
- 조건식에서 컬럼명은 일반적으로 좌측에 위치하지만, 우측에 위치해도 동작함
3) SQL 연산자
| 연산자 | 의미 | 예시 |
|---|---|---|
| BETWEEN A AND B | A와 B 사이(A,B 포함) | where col between 1 and 10 |
| LIKE '비교 문자열' | 비교 문자열을 포함 | where col like '방탄%' |
| IN (LIST) | LIST 중 하나와 일치 | where col in (1,3,5) |
| IS NULL | NULL 값 | where col is null |
// 동일한 의미 쿼리
WHERE PLAY_ID BETWEEN 1 AND 5;
WHERE PLAY_ID >= 1 AND PLAY_ID <= 5;
<LIKE>
// NAME이 Classical로 시작되는 행 조회
WHERE NAME LIKE 'Classical%';
// NAME이 M으로 시작하고 S로 끝나는 행 조회
WHERE NAME LIKE 'M%s';
// NAME에 101이 포함된 행 조회
WHERE NAME LIKE %101%;
// TITLE이 IT Staff이거나 IT Manager인 행 조회
WHERE TITLE IN ('IT Staff', 'IT Manager');
WHERE (TITLE = 'IT Staff' OR TITLE = 'IT Manager');4) 부정 SQL 연산자
| 연산자 | 의미 | 예시 |
|---|---|---|
| NOT BETWEEN A AND B | A와 B의 사이가 아님(A, B 미포함) | where col not between 1 and 10 |
| NOT IN (LIST) | LIST 중 일치하는 것이 없음 | where col not in (1,3,5) |
| IS NOT NULL | NULL 값이 아님 | where col is not null |
WHERE PLAY_ID NOT BETWEEN 1 AND 5
WHERE NOT (PLAY_ID BETWEEN 1 AND 5)
WHERE NOT (PLAY_ID >= 1 AND PLAY_ID <= 5)
WHERE PLAY_ID < 1 OR PLAY_ID >55. GROUP BY, HAVING절
1) GROUP BY : 데이터를 그룹 별로 묶을 수 있게함
GROUP BY 뒤에 그룹핑의 기준이 되는 컬럼이 오게 됨
2) 집계 함수 : 데이터를 그룹 별로 나누면 집계 데이터 도출 가능해짐
COUNT(*) : 전체 행을 Count하여 반환
COUNT(컬럼) : 컬럼값이 NULL인 행을 제외하고 카운트
COUNT(DISTINCT 컬럼) : 컬럼값이 NULL이 아닌 행에서 중복을 제거하고 카운트
SUM(컬럼) : 컬럼값들의 합계 반환
AVG(컬럼) : 평균
MIN(컬럼) : 최솟값
MAX(컬럼) : 최댓값
3) HAVING
GROUP BY절 사용할 때 WHERE절처럼 사용하는 조건절
데이터를 그룹핑한 후 특정 그룸을 골라낼 때 사용
< SELECT문의 논리적 수행 순서 >
SELECT - 5
FROM - 1
WHERE - 2
GROUP BY - 3
HAVING - 4
ORDER BY - 6
- HAVING절은 GROUP BY절 이후에 수행됨 -> 그룹핑 후에 가능한 집계 함수로 조건 부여 가능
- SELECT절 전에 수행됨 -> SELECT절에 명시되지 않은 집계 함수로 조건 부여 가능
- WHERE절 써도 되는 걸 굳이 HAVING 절로 쓰면 성능 저하 (에러는 안 남)
- WHERE절에서 필터링 먼저 돼야 GROUP BY할 데이터량이 줄어서
6. ORDER BY 절
SELECT문에서 가장 마지막에 수행됨
SELECT한 데이터를 정렬
ORDER BY 따로 명시 X -> 임의의 순서대로 출력됨
ORDER BY 절 뒤엔 정렬의 기준이 되는 컬럼이 옴 (1개 / #개)
- ASC : 오름차순 (디폴트)
- DESC : 내림차순
7. JOIN
1) JOIN이란?
: 다른 테이블을 한 번에 보여줄 때 쓰는 쿼리
2) EQUI JOIN
: Equal(=) 조건으로 JOIN
ex) 특정 리뷰 1개만 출력하고 싶을 때
: 마우스 - 상품 테이블의 데이터임, 리뷰 - 리뷰 테이블의 데이터임 => 두 테이블을 조인
SELECT A.PRODUCT_CODE,//(겹치는 컬럼은 한 번만 SELECT하면 됨)
A.PRODUCT_NAME,
B.MEMBER_ID,
B.CONTENT,
B.REG_DATE
FROM PRODUCT A,//PRODUCT테이블을 A로 별칭 지정
PRODUCT_REVIEW B
WHERE A.PRODUCT_CODE = B.PRODUCT_CODE
AND A.PRODUCT_CODE = '10001';3) Non EQUI JOIN
: Equal(=) 조건이 아닌 다른 조건(BETWEEN, >, >=, <, <=)으로 JOIN
ex) 이벤트 기간 동안 리뷰 작성한 고객에게 사은품 주는 행사
: 리뷰 테이블 & 이벤트 테이블 join해야함
SELECT A.EVENT_NAME,
B.MEMBER_ID,
B.CONTENT,
B.REGDATE
FROM EVENT A,
PRODUCT_REVIEW B
WHERE B.REGDATE BETWEEN A.START_DATE AND A.END_DATE;4) 3개 이상 TABLE JOIN
8. STANDARD JOIN (= ANSI JOIN, 표준 조인)
1) INNER JOIN
: JOIN 조건에 충족하는 데이터만 출력됨
- JOIN 조건을 ON 절을 사용하여 작성해야 함
SELECT A.PRODUCT_CODE,
A.PRODUCT_NAME,
B.MEMBER_ID,
B.CONTENT,
B.REG_DATE
FROM PRODUCT A INNER JOIN PRODUCT_REVIEW B
ON A.PRODUCT_CODE = B.PRODUCT_CODE;2) OUTER JOIN
: JOIN 조건에 만족하지 않는 행들도 출력됨

-
LEFT OUTER JOIN
- LEFT 테이블 & RIGHT 테이블 중 JOIN에 성공한 데이터
- JOIN에 성공 못한 나머지 LEFT 테이블 데이터가 함께 출력- RIGHT 테이블에 조인되는 데이터가 없는 Row들은 RIGHT 테이블의 컬럼 값이 Null로 출력됨
-
RIGHT OUTER JOIN : LEFT와 반대
-
모든 행이 출력되는 테이블의 반대편 테이블 옆에 (+) 붙여서 작성
-
FULL OUTER JOIN : 왼, 오 테이블의 데이터의 합집합, 중복값은 제거됨
3) NATURAL JOIN
: A테이블 & B테이블에서 같은 이름 가진 컬럼들이 모두 동일한 데이터를 갖고 있으면 JOIN됨
💡 두 테이블에서 컬럼명은 같지만 데이터가 모두 동일하진 않은 컬럼이 존재하면?
- USING 조건절로 같은 이름 가진 컬럼 중 원하는 컬럼만 JOIN에 이용 가능 (원래 기본은 모든 컬럼을 합치는 거임)
- 단 SELECT절에서 USING 절로 정의된 컬럼 앞에는 별도의 별칭 / 테이블명 붙이면 X
SELECT CAST,
GENDER,
A.JOB AS R_JOB
B.JOB AS I_JOB
FROM RUNNING_MAIN A JOIN INFINITE_CHALLENGE B
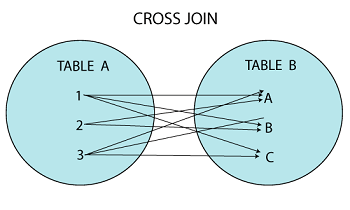
USING (CAST, GENDER); // 컬럼명 그대로 사용4) CROSS JOIN
: 경우의 수 느낌
A 테이블 & B 테이블 사이에 JOIN 조건이 없는 경우, 조합할 수 있는 모든 경우를 출력