떨어졌으면 안 썼을 빅분기 4회 필기, 실기 후기
카드형 자격증이 새로 나왔길래 궁금할 사람들이 있을 것 같아서 올립니다.

이렇게 생김
필기
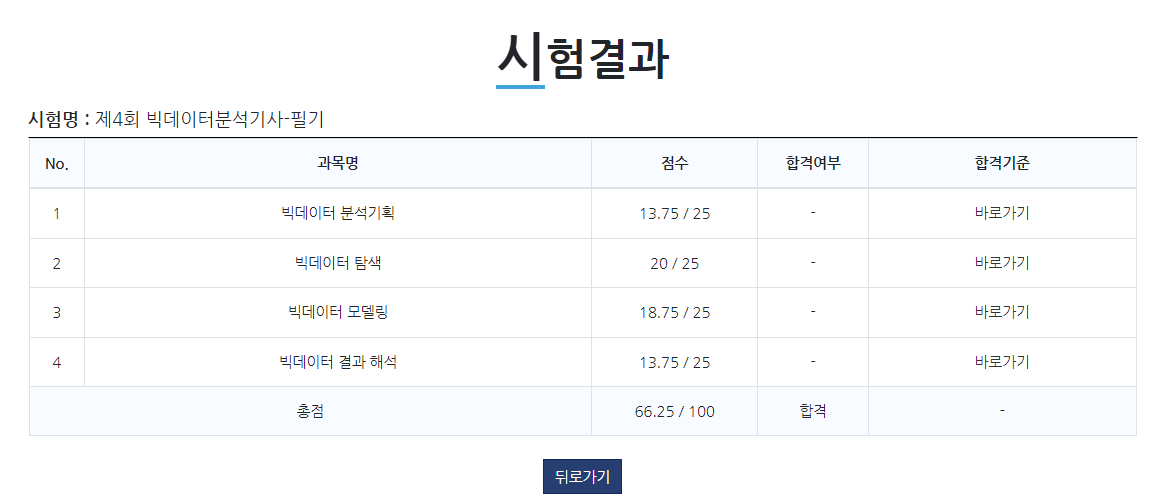
필기는 별로 말할 게 없다..
학기초에 근로하면서 깔짝깔짝 하다가 시험보러 갔는데 턱걸이로 붙었다.
ADsP 공부한 거랑 겹친 게 많았고, 학교 수업에서 배운 거로 어떻게 합격한 것 같음
이제 총 3회 실시된 시험이라 (제1회 시험이 코로나로 실시되지 않음) 기출도 별로 없고, 출제경향도 들쑥날쑥하다.
그래서 어떤 책을 사도 완벽하게 커버되지 않는 것 같다.
나는 예문사 책을 봤는데 막상 시험에서 처음 보는 용어들도 좀 나와서 당황했음
(제대로 공부를 안 해서 그럴 수도)
근데 어차피 60점 넘으면 합격이니까, 합격하기 쉽냐 어렵냐로 보면 그렇게 어렵진 않은 것 같다.
실기
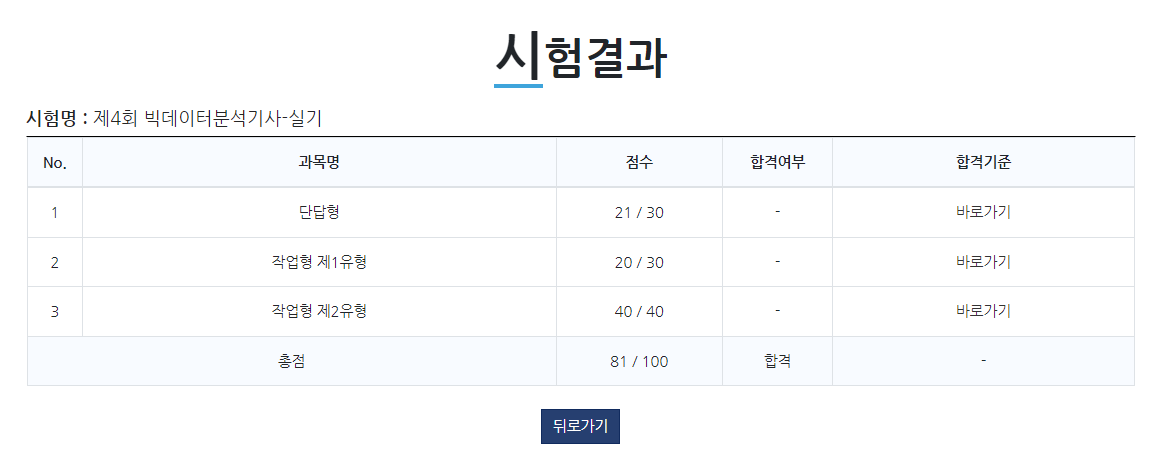
종강하니까 1주일 뒤가 빅분기 실기 시험이었다. 그래서 거의 1주 동안 준비했다.
실기는 할말이 많아서 파트별로 나눠보겠음
단답형
총 10문제로 개당 3점으로 어떤 개념에 대한 설명이 주어지고 그게 무엇인지 쓰는 것이다.
4회 문제 정답이 아래와 같다. (순서 랜덤)
JSON
최소제곱법
차원 축소
Box-Cox
드롭아웃
SOM
SVM
Sqoop
정규성
0.686 (Precision과 Recall 값을 주고 F1-score 구하기)
대부분 굵직한 개념에서 나오는 것 같다.
단답형이라고 해서 필기시험 내용 전체를 공부하려 하면 안 된다.
데이터자격검정 홈페이지에 출제 범위가 나와있으니까 확인하고,
기출을 한 번 분석 후에 공부 방향을 정하는 게 좋은 것 같다.
나는 JSON, Box-Cox, SOM 세 개 틀린 것 같다.
답만 딱 봐도 그렇게 지엽적인 내용은 출제하지 않는게 보인다.
그런데 여기서 하나 알아둬야 할 게, 작업형이 10점 단위로 채점이 된다.
그래서 단답형 점수의 일의 자리는 의미가 없다. ( 21점이나 27점이나 똑같음)
그래서 4개, 7개, 10개 정답을 목표로 해야 함
나는 7개 맞은 거 같은데, 혹시 더 실수했을까봐 불안했다.
작업형 제1유형
작업형은 R과 Python 중에 골라서 할 수 있는데, 난 Python을 사용함
제1유형은 총 3문제로 각 10점, 부분점수 없다.
다른 거 다 필요없고 Pandas 잘하면 되는 것 같다.
1주일 동안 이거 준비하면서 Pandas 실력이 많이 늘었다.
근데 평소에 datetime 다루는 게 헷갈려서 맨날 미뤄뒀는데 이게 한 문제가 나와서 틀려버렸다.
문자열로 되어있는 한 칼럼을 datetime으로 바꿔서 갯수를 세야 됐었는데,
바꾸는 법을 몰라서 'January 1, 2018', 'January 2, 2018', 'January 3, 2018', 'January 4, 2018', ...
이런 식으로 하드코딩해서 결국엔 답을 맞춘 줄 알았는데, 문자열 중간중간에 공백이 포함된 것들이 있었다.
https://www.kaggle.com/datasets/shivamb/netflix-shows
위 링크 데이터였는데, 아마 출제할 때 하드코딩 방지로 의도한 것 같다.
다음 시험을 준비하는 사람들은 이런 데이터도 나온다는 사실을 숙지하고 EDA를 충분히 해봐야 할 것 같다.
작업형 제2유형
시험이 총 3시간인데, 2시간쯤 흘렀을 때 다 풀고 조기퇴실 했다.
근데 엘리베이터에서 어떤 아저씨가 말 걸더니 답을 맞춰보자 하셨다.
나는 쫄려서 답 맞춰보는 스타일 아닌데.. 아무튼 맞춰보는데 나는 제2유형을 분류 문제로 이해하고 풀었는데 이 아저씨가 회귀문제라고 하는 거다.
순간 머리가 하얘졌는데 아저씨랑 토론을 좀 해보니까 분류가 맞았다.
단답형에서도 좀 틀리신 거 같아서 아마 다음 회차 시험 치실 거 같다.
주어진 데이터로 EDA부터 머신러닝 모델링, test 예측 csv 생성까지 쭉 짜는 거다.
파이썬을 사용한다면 아마 scikit-learn을 사용할 건데,
중요한 건 깔끔한 전처리, 파생변수 생성, 파라미터 튜닝 같은 것이 아니라!
예측력이 조금 떨어지더라도 최종 제출 파일을 제대로 만드는 것이다.
최종 제출 파일을 만들었을 때 만약 확률을 구하라 했는데 1이냐 0이냐 예측을 했다던지, test 데이터와 행 수가 다르다던지 그러면 안 된다. (이건 무조건 0점 처리될 것임)
나는
원핫인코딩 -> XGBoost, RandomForest 피팅 -> 검증 데이터 F1-score 비교 -> 더 높은 걸로 test predict -> 예측 파일 생성
이정도만 해줬는데 만점 받았다.
기존 기출이나 예시 문제에서는 이진 분류로 평가 지표로 ROC-AUC를 사용하는 문제만 나와서 이번엔 회귀 문제가 나올줄 알았는데, 예상 밖으로 다항 분류에 평가지표 macro F1 score를 사용하는 문제가 나왔다.
연습하던 거랑 살짝 다르기도 하고 저때 macro F1 score가 뭘 의미하는지도 몰라서 좀 당황하긴 했는데 help() 까지 써가면서 평가 지표 출력까지 어떻게 잘해서 제출한 것 같다.
작업형 제2유형은 무려 40점짜리인데 주어진 양식을 제대로 지키지 못해서 0점 처리되는 사람이 많다.
칼럼명 불일치, 행 수 불일치가 가장 많을 것 같다.
나도 여기서 실수했을까봐 계속 쫄렸는데, 다행히 제대로 한 거 같다.
제5회에서는 아마 회귀 문제가 나오지 않을까?
주저리
데이터 전문가 포럼 네이버 카페 가보면 이 자격증의 효용성에 대해 의구심을 갖는 사람들도 있다.
근데 나는 이거 준비하면서 짧은 기간에 Pandas 정리도 하고,
사이킷런을 이용한 파이썬 머신러닝의 큰 틀도 잡을 수 있어서 꽤 만족스러웠다.
최종적으로 한번에 합격을 해서 속 편하게 후기도 쓸 수 있는 것 같다.
사조사 공부하기 싫어서 후기 쓰고 있다.
끝
