새싹 인공지능 응용sw 개발자 양성 교육 프로그램 김기희 강사님 수업 정리 글입니다.
목차
1. database
2. sql
3. shema
4. mysql
5. table
1. database
명령을 입력하기 위한 프롬포트가 필요하다.
mysql이 database관리시스템을 하여금 명령을 입력하기 위한 프롬포트다.
mysql 에서 명령은 2가지가 있다.
1. mysql client utility 명령
2. SQL = 구조화된 지리 언어
;로 끝나는 것은 DB관련 명령이다
1번 명령을 통해 프롬포트에 접속. 1번 실행되는 명령은 자체 내장 명령이다. 그래서 ; 없어도 실행. 서버쪽에 보내는 명령 = sql명령(문), 여러 라인으로 구성될 수 있으므로 ;으로 마감해야 한다.
메타database
- 메타데이터가 있다만 알아두기
사용자 로그인할 때 사용자가 대상 테이블에 권한이 있는지, 제약사항을 체크해야 한다.
메타데이터를 참조해서 체크한다.
database = 정보의 집합
database는 체계화된 데이터의 집합으로 여러 사람들이 공유하여 사용할 목적으로 통합 관리되는 정보의 집합이다.
데이터의 속성을 부여하고 데이터가 모이면 의미있는 정보가 된다. database는 정보의 집합이다.
하나의 정보는 여러개의 데이터가 모여서 정보가 된다.
column이 모여서 정보가 되고. 이게 모이면 행, 레코드라고 한다. 데이터의 집합이 데이터베이스 = table이라고 한다.
table은 각 column으로 데이터를 분류하고 이 분류한 데이터들이 모이고 정보가 되고 정보가 모여서 table이 된다. 데이터의 집합이 된다. 테이블은 정보의 집합이고 이것을 모아둔 것이 database이다.
데이터베이스의 특징
(읽어만 보기)
- 실시간 접근성 : 언제든지 접근 가능
- 지속적인 변화: 변경된 내용 실시간 적용
- 동시 공유 : 여러사람이 동시에 사용가능
- 내용에 대한 참조 : 하나의 데이터베이스가 있고 그 안에 테이블들이 있다. 이 테이블들 참조, 삭제 가능 등등
- 데이터의 논리적 독립성: 하나의 업무가 하나의 테이블이 된다.
데이터베이스의 장단점
(읽어만 보기)
장점
- 데이터 중복의 최소화
- 데이터 공유
- 일관성, 무결성, 보안성 유지
- 최신 데이터 유지
- 데이터의 표준화
- 데이터의 논리적, 물리적 독립성
- 용이한 데이터 접근
- 데이터 저장 공간의 절약
단점
- 데이터베이스 전문가 필요
- 많은 비용이 소요
- 데이터 백업과 복구의 어려움
- 시스템이 복잡함
- 대용량 디스크로 액세스가 집중되는 경우 과부하가 발생
데이터모델
관계형 데이터베이스 모델(RDBMS)
가. 데이터베이스는 최소한의 의미를 가지는 table로 구성된다. table들은 각각 테이블 내의 column으로 연결된다.
= 같은 뜻
가-1. 데이터베이스는 최소한 의미를가지는 table로 구성된다.
가-2. table은 가각의 table내의 column들로 연결된다.
= 가-2와 같은 뜻
각각의 table들은 상위 정보를 저장하는 table의 primary key와 하위 정보를 저장하는 table의 foreign key를 이용하여 연결함으로써서로 다른 테이블 상에서 연관된 정보를 얻을 수 있도록 해야 함을 말한다.
정확한 업무(table)와 속성(column)을 추출한다.
1. 명사추출 - ex) 업무(table)-제품, 속성(column)-가격추출
요약
table = 업무이다.
업무는 서로 연관있다 = 관계를 형성한다.
- table(업무) 유형
- 존재의 유형
- 행위의 유형
관계 : 부모와 자식
table과 table이 서로 관계 형성
- 누가 부모가 될 것인가 : 기본키(primary key)
- 누가 자식이 될 것인가 : 외래키(foreign key)
ex)
차량을 소유하는 것은 사원이다. → 사원이 부모, 차량이 자식
모든 table은 primary key(기본키)를 가지고 있다. table 내 레코드 중 대표할 수 있는 것은 primary key(기본키)라고한다.
2. sql
관계형 데이터베이스 관리 시스템 rdbms의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다.
- 데이터 정의 언어
- 데이터 조작 언어
- 데이터 제어 언어
- 트랜젝션 제어 언어
데이터 정의, 조작 언어를 주로 사용할 것이다.
사실은 데이터를 변경하는 것이 아닌 schema 변경한다.
무언가 설계나 사용을 변경한다 = 제어
테이블내의 데이터를 조작 한다 = 조작
데이터(객체)냐 데이터를 가지고 update, drop 차이가 있다.
데이터베이스 안에 객체가 있다.사용자(object), 권한, 규칙, schema(maria bd에서 db를 부르는 말), table, column
-> 데이터가 대상이 될 때는 update, delete
테이블일 때는 drop
사용자 추가하기
추가 CREAT USER kim
삭제 DROP USER kim;
비밀번호 변경 alter user
database관리
mysql에서 작은 의미로서의 데이터베이스는 table의 집합소라고 한다. 그러므로 테이블을 생성하기 위해서는 테이블이 저장될 데이터 베이스가 존재하여야 한다.
3. schema
교재) schema는 데이터베이스의 구조와 제약 조건에 관해 전반적인 명세를 기술한 것이다. 즉 개체의 특성을 나타내는 속성과 속성들의 집합으로 이루어진 개체 그리고 개체와 개체 사이에 존재하는 관계에 대한 정의와 이들이 유지해야 할 제약 조건을 기술한 것이다.
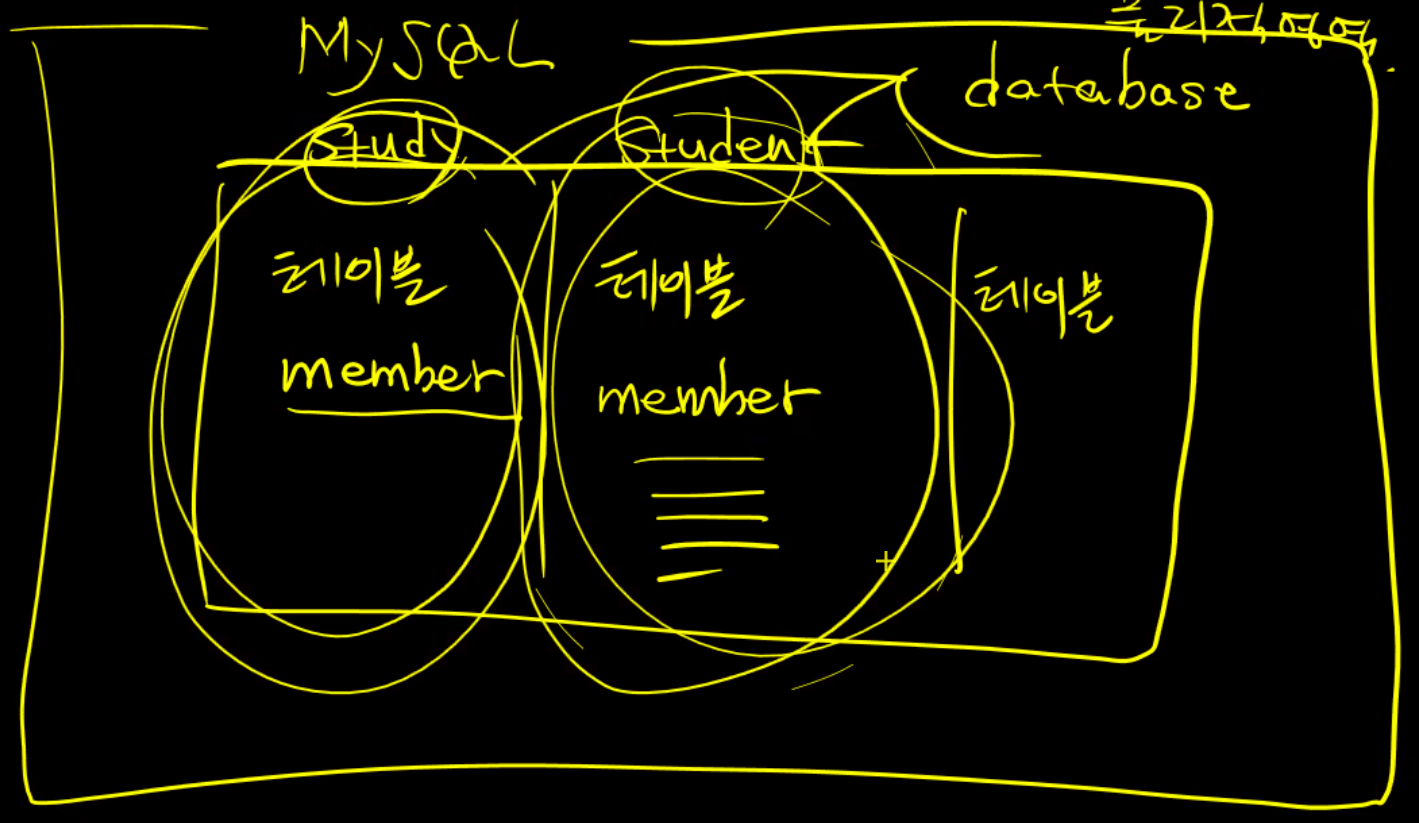
설명) mysql가 하나의 db다. 내부의 database라는 물리적 영역을 만든다.이 물리적 영역안에 table이 있다. 데이터베이스라는 단위가 존재함으로 www.naver.com, db서비스도 제공가능하다.
table space 가 있고 그 안에 member가 여러가지 있을 수 있다. 물리적으로는 하나의 공간인데 여러가지 있을 수 있다. 그래서 그 앞에 소유자(계정)을 붙인다. 한 테이블 안에 www.naver.com, www.daum.net 물리적으로 나눠져 있다. 물리적인 구분으로 본다면 mysql은 db단위로 물리적, 논리적 구분 둘 다 한다.
orcle은 물리적으로 하나이지만. 안에 여러가지 나눌 수 있는 영역을 논리적으로 나눈 것을 schema 라고 한다.
이 영역에 접근할 수 있는 계정, 권한, 테이블, 컬럼, 컬럼에 부여된 제약 모든 것들을 통들어 schema 라고 한다.
4. mysql 자료형
mysql의 자료형은 크게 세 가지로 나눌 수 있다.
- 실수형
- 문자형
- 날짜형
- 문자형
char(m) - char(10) = 10개의 캐릭터형 문자를 저장할 수 있따.
varchar : 가변형, 끝을 나타내는 것이 있다. 10문자 들어가면 10만큼 데이터를 확보한다.
binary
enum(’남자’,’여자’) = ‘남자’ : ‘여자’ = 남자, 여자만 들어갈 수 있다. 저장될 때는 정수값으로 저장된다. 상호배타적, 여러개를 제시하고 하나만 저장될 때
set (’남자’,’여자’) = ‘남자’ : ‘여자’ : ‘남자’ ‘여자’ = 상호배타적이 아니다, 여러개의 기술을 보여주고 여러개 선택가능하도록
mysql 연산자
데이터베이스는 비교연산이다.
-
논리연산
-
비교연산의 특징 (읽어만 보기)
ex) Tera Term
mysql> SELECT 3 <> NULL;
+-----------+
| 3 <> NULL |
+-----------+
| NULL |
+-----------+
1 row in set (0.00 sec)
<>만 쓰면 숫자와 NULL을 비교하면 NULL이 나온다.
mysql> SELECT 3 <=> NULL;
+------------+
| 3 <=> NULL |
+------------+
| 0 |
+------------+
1 row in set (0.00 sec)
5. TABLE
7.2 테이블
관계형 데이터베이스에서 table은 데이터의 집합으로 데이터의 기본 구성요소이며 관계를 형성한다. 테이블은 행과 열로 구성된다.
- 열 : column, field
- 행 : row, record
(record는 파일시스템에서 사용하는 말, 하나의 정보를 구성, 한 라인이 하나의 정보, 하나의 라인은 특정 구분문자를 통해서 저장됨. column의 집합을 field라고 한다. 파일시스템에서는 filed, record라고 하고 데이터베이스에서는 column과 row라고 해야 한다)
테이블을 구성하는 행을 튜플(tuple)이라고도 하며 한 table 내에 포함된 전체 튜플의 수를 카디널리티(cardinality)라고 한다.
전체 행의 수를 더해서 카디널리티(cardinality)
최소한 기본키는 중복이 되지 않기 때문에 레코드 수가 카디널리티(cardinality)가 된다.
column의수를 차수(degree, tree에서 사용)라고 한다.
테이블 생성

→ 명사 추출: 회사, 물류, 제품, 스토리지, 메모리, CPU, AMP, INTEL, DDR4,DDR5
→ 동사 추출: 제품이 있으며
→ 업무추출 : 제품(제품,INTEL, DDR4,DDR5), 분류(스토리지, 메모리, CPU)
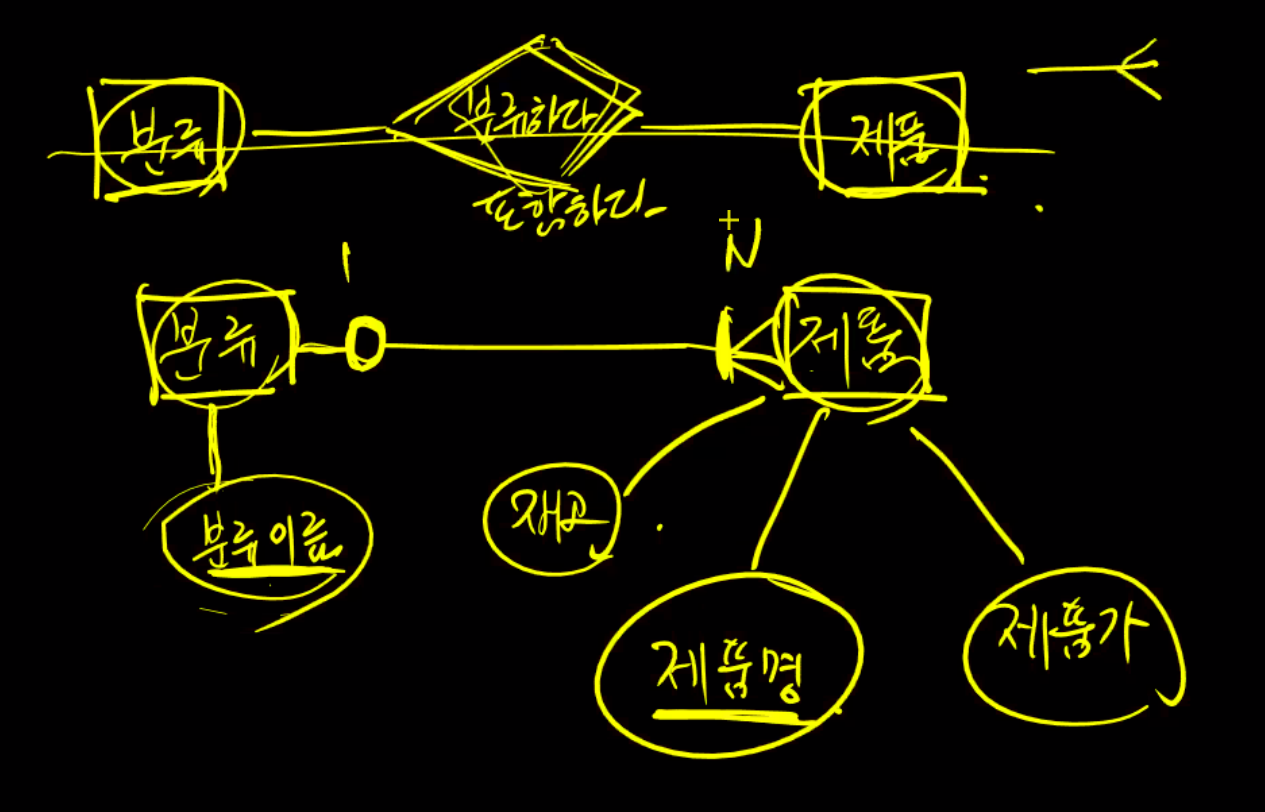
분류 - 제품 관계형성, 관계는 마름모형 , table(업무)는 네모
분류키에서 식별자는 전체분류를 식별가능한 값을 식별자 = 분류이름 = 식별키, 제품에서는 제품명
후보키를 찾아내고 그 안에서 식별키를 찾아낸다. 분류는 제품이 꼭 있어야 하는 것은 아니다(표기: |). 하지만 제품은 분류에 속해야 한다(표기: 0). 선택성 → 차수성
ER다이어그램
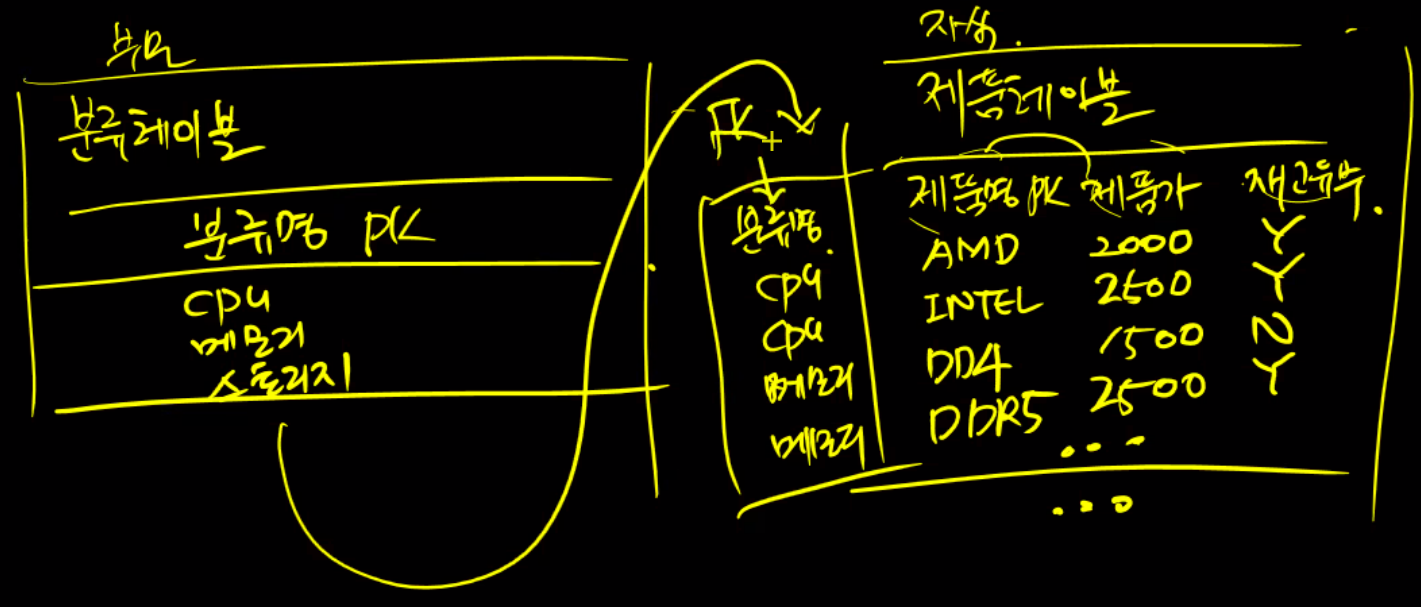
분류테이블 - 분류명 - CPU, 메모리, 스토리지
제품테이블 - 제품명 - 제품명, 제품가, 재고유무
별도의 테이블로 쪼개는 것은 정규화
분류테이블 : 부모 - 제품테이블 : 자식
column이 자식 테이블에 전위가 된다.
정규화가 끝나면 schema를 만들어야 한다.
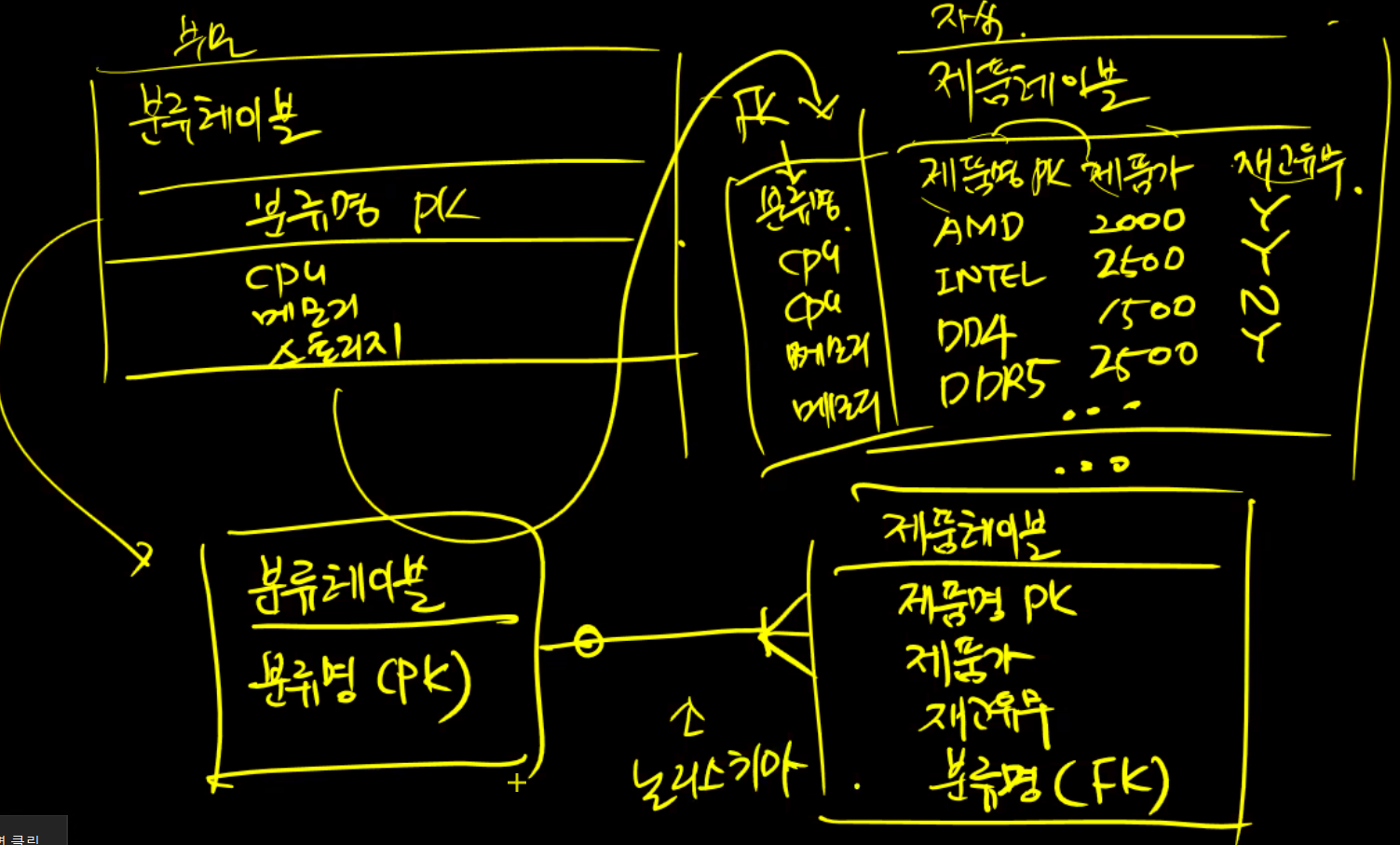
→ 논리schema
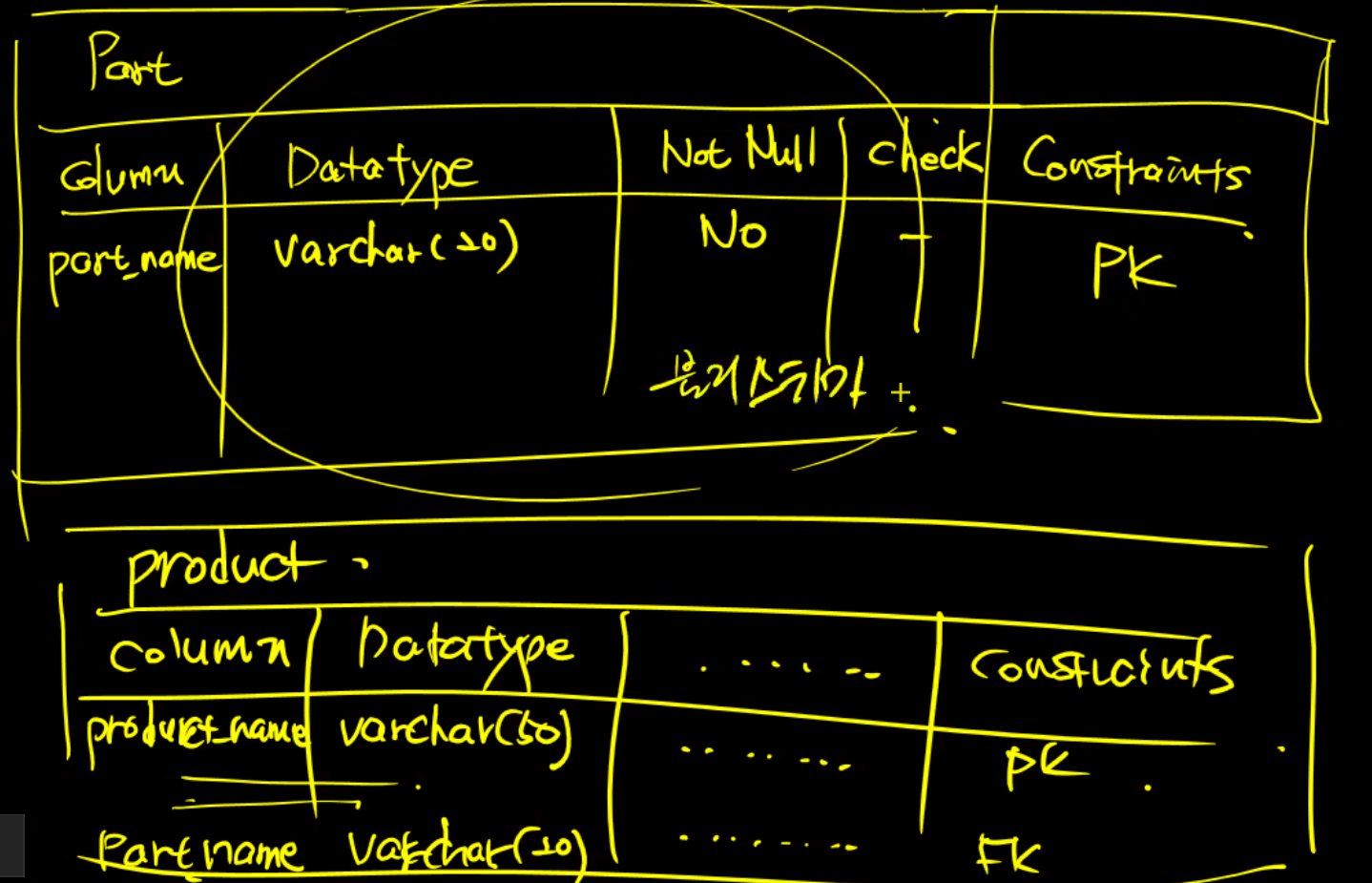
→ 물리schema
→ 이것을 바탕으로 테이블을 생성한다. 어떤 과정에 의해서 만들어지는 가만 알아두기
참조무결성
부모자식간 형성이 되면 부모는 아무런 제약이 없다. 자식테이블은 제약을 받는다. 부모한테 없는 키로는 제약을 못 받는다.
두 테이블 간에 관계까 형성되었을 경우에는 데이터의 입력, 편집 및 삭제에 제한을 받게 된다.
예를 들어 두 테이블이 아래와 같은 소유 관계를 가질 때 자식 테이블에는 자식 테이블의 외래키에서 참조하는 부모 테이블의 primary key column에 등록되지 않은 값은 입력이 불가하다.
select 문, 자료의 검색
기본은 select from
별명 = alias
예약어는 컬럼명으로 못 씀 → ` 을 이용하면 사용 가능
알리아스는 SELECT문 과 FROM문에서도 사용 가능하다
131P 그룹함수를 잘 써야 한다.
그룹이라는 이름이 붙은 이유
일반적으로 함수를 실행하기 위해 인수가 필요하다.
그룹함수는 인수의 값이 하나가 아니라 column 전체가 인수가 될 수 있다. 레크도 전체가 인수가 될 수 있다. 그룹함수는 개별적 컬럼함수와 쓰면 안된다.
- COUNT
- SUNT
- AVG
- MAX
- MIN
ex)
주로 통계를 구한다. 개별 컬럼과 사용하면 안된다.
→ select b_name, AVG(b_price) FROM book;
→ 이럴 때 사용하는 게 group by 예시) SELECT c_code, AVG(b_price) FROM book GROUP BY c_code;
select - where - 필러팅하고 그룹핑
SELECT c_code, AVG(b_price) FROM book
WHERE c_code LIKE '%F%' GROUP BY c_code
group - having - 그룹핑먼저 하고 필터링
SELECT c_code, AVG(b_price) FROM book GROUP BY c_code
HAVING c_code LIKE '%F%'
SELECT c_code, AVG(b_price) FORM book WHERE b_price >20000 GROUP BY c_code;
SELECT c_code, AVG(b_price) FORM book WHERE b_price >20000 GROUP BY c_code having c_code LIKE '%F%';
JOIN
-
THETA JOIN - where절로 조건을 지정한 경우
SELECT *
FROM category C, book B
WHERE C.c_code = B.c_code; -
inner join
SELECT *
FROM category C INNER join book B
USING (c_code)
카테고리 c테이블과 book b가 동일한 이름의 컬럼값을 가져와라
SELECT *
FROM category C INNER join book B
ON (C.c_code = B.c_code)
→ 이것도 가능
SELECT *
FROM category C NATURAL join book B
→ 이것도 가능, 값이 같은 것을 추출한다.
