파이썬 가상환경 설정
https://www.youtube.com/watch?v=o_vKT80BBkw&t=521s
selenium example
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element(By.NAME, "q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()시도1
https://www.youtube.com/watch?v=1b7pXC1-IbE&t=1370s
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import urllib.request
driver = webdriver.Chrome()
driver.get("https://www.google.com/imghp?hl=ko")
elem = driver.find_element(By.NAME, "q") #검색창 찾기
elem.send_keys("포테이토 피자") #원하는 값 입력
elem.send_keys(Keys.RETURN) #엔터키
#images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
images = driver.find_element(By.CSS_SELECTOR,".rg_i.Q4LuWd")[0].click()
count = 1
for image in images:
image.click()
time.sleep(3)
imgUrl = driver.find_element_by_css_selector(".n3VNCb.KAlRDb").get_attribute("src")
urllib.request.urlretrieve(imgUrl, str(count) + ".jpg")
count = count + 1
#이미지 다운로드
# opener=urllib.request.build_opener()
# opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
# urllib.request.install_opener(opener)
# urllib.request.urlretrieve(imgUrl, "test.jpg")
# assert "Python" in driver.title
# elem = driver.find_element(By.NAME, "q")
# elem.clear()
# elem.send_keys("pycon")
# elem.send_keys(Keys.RETURN)
# assert "No results found." not in driver.page_source
# driver.close() - 오류: 첫 번째 사진이 계속 연속해서 다운
시도2
https://www.youtube.com/watch?v=Al-S0DQsVsk
# search xpath = /html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input
# image selector = #islrg > div.islrc > div:nth-child(2) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img
#pip install webdriver-manager selenium
from selenium.webdriver.common.keys import Keys
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import urllib.request
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
URL = 'https://www.google.co.kr/imghp'
driver.get(url=URL)
driver.implicitly_wait(time_to_wait=10) #최대 10초까지 기다려줌
keyElement = driver.find_element(By.XPATH,'/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input')
keyElement.send_keys('쉬림프피자')
keyElement.send_keys(Keys.RETRUN)
url = driver.find_element(By.CSS_SELECTOR, '##islrg > div.islrc > div:nth-child(2) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img').get_attribute('src')
urllib.request.urlretrieve(url, 'C:\pizza') #저장 시도3
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import urllib.request
driver = webdriver.Chrome()
driver.get("https://www.google.com/imghp?hl=ko")
elem = driver.find_element(By.NAME, "q") #검색창 찾기
elem.send_keys("쉬림프피자") #원하는 값 입력
elem.send_keys(Keys.RETURN) #엔터키
#images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
images = driver.find_elements(By.CSS_SELECTOR,'.rg_i.Q4LuWd')
count = 1
for image in images:
image.click()
time.sleep(3)
imgUrl = driver.find_element(By.CSS_SELECTOR,'.n3VNCb.KAlRDb').get_attribute("src")
urllib.request.urlretrieve(imgUrl, str(count) + ".jpg")
count = count + 1
시도4
https://www.youtube.com/watch?v=ZTJjW7XuHIY&t=43s
pip install google_images_download
from google_images_download import google_images_download
response = google_images_download.googleimagesdownload()
arguments = {"keywords":"쉬림프피자","limit":100,"print_urls":True,"format":"jpg"}
paths = response.download(arguments)
print(paths)
- 오류
Unfortunately all 100 could not be downloaded because some images were not downloadable. 0 is all we got for this search filter!
Errors: 0
시도5
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import urllib.request
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("쉬림프피자")
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
# # Get scroll height
# last_height = driver.execute_script("return document.body.scrollHeight")
# while True:
# # Scroll down to bottom
# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# # Wait to load page
# time.sleep(SCROLL_PAUSE_TIME)
# # Calculate new scroll height and compare with last scroll height
# new_height = driver.execute_script("return document.body.scrollHeight")
# if new_height == last_height:
# try:
# driver.find_element_by_css_selector(".mye4qd").click()
# except:
# break
# last_height = new_height
images = driver.find_elements(By.CSS_SELECTOR,'.rg_i.Q4LuWd')
count = 1
for image in images:
try:
image.click()
time.sleep(2)
imgUrl = driver.find_element(By.CSS_SELECTOR,'/html/body/div[2]/c-wiz/div[3]/div[1]/div/div/div/div/div[1]/div[1]/span/div[1]/div[1]/div[1]/a[1]/div[1]/img').get_attribute("src")
# opener=urllib.request.build_opener()
# opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
# urllib.request.install_opener(opener)
urllib.request.urlretrieve(imgUrl, str(count) + ".jpg")
count = count + 1
except:
pass
driver.close()- 오류
[13820:15288:1219/001345.483:ERROR:ssl_client_socket_impl.cc(982)] handshake failed; returned -1, SSL error code 1, net_error -202
시도6(성공)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import urllib.request
driver = webdriver.Chrome()
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys("쉬림프피자")
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
# # Get scroll height
# last_height = driver.execute_script("return document.body.scrollHeight")
# while True:
# # Scroll down to bottom
# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# # Wait to load page
# time.sleep(SCROLL_PAUSE_TIME)
# # Calculate new scroll height and compare with last scroll height
# new_height = driver.execute_script("return document.body.scrollHeight")
# if new_height == last_height:
# try:
# driver.find_element_by_css_selector(".mye4qd").click()
# except:
# break
# last_height = new_height
images = driver.find_elements(By.CSS_SELECTOR,'.rg_i.Q4LuWd')
count = 1
for image in images:
try:
image.click()
time.sleep(3)
imgUrl = driver.find_element(By.XPATH,'//*[@id="Sva75c"]/div[2]/div/div[2]/div[2]/div[2]/c-wiz/div[2]/div[1]/div[1]/div[2]/div/a/img').get_attribute("src")
# opener=urllib.request.build_opener()
# opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
# urllib.request.install_opener(opener)
urllib.request.urlretrieve(imgUrl, str(count) + ".jpg")
count = count + 1
except:
pass
- 똑같은 사진 100장 다운로드 오류
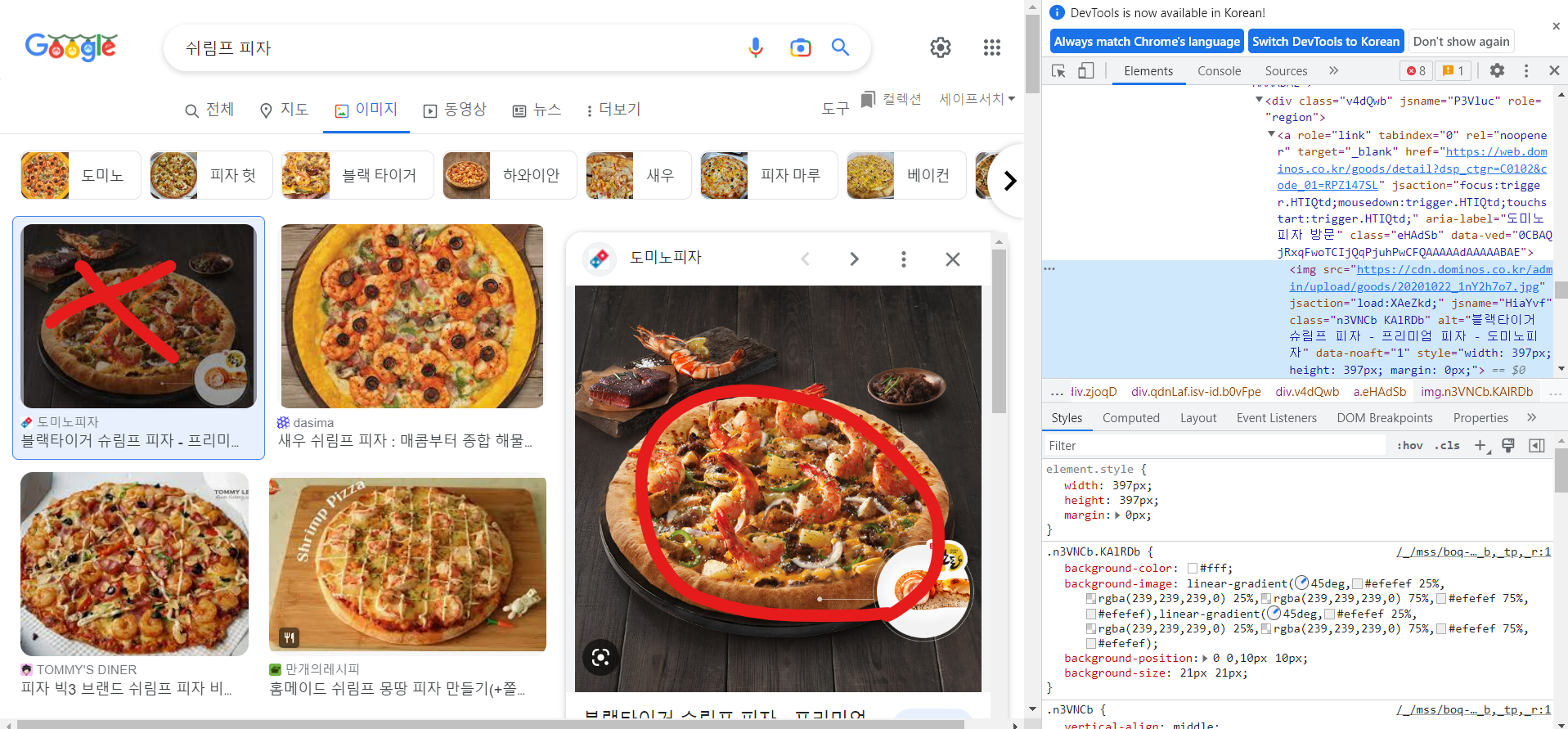
작은 이미지에서 경로복사가 아닌 큰 이미지에서 경로복사해야 한다.
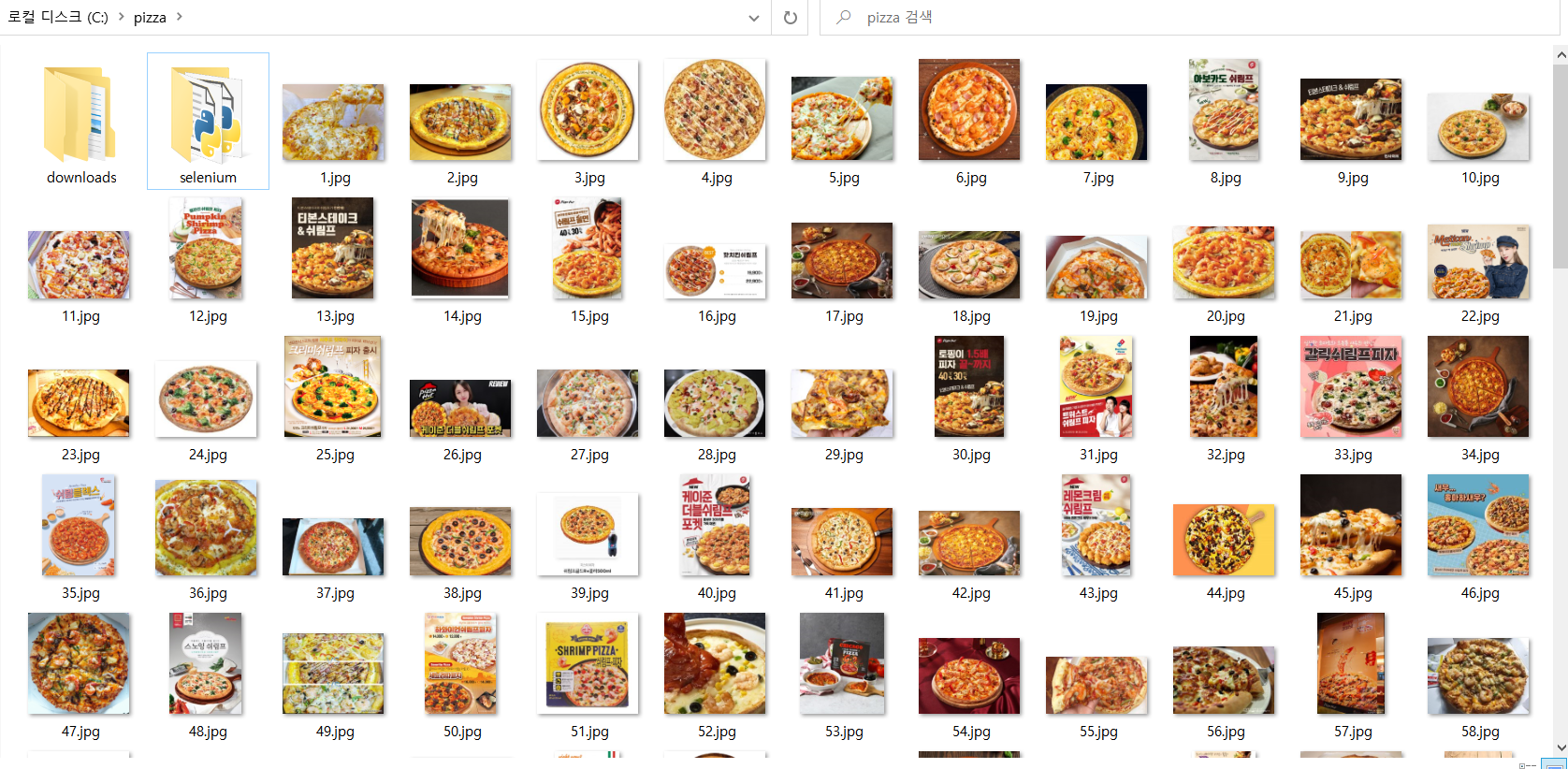
시도7(성공) - AutoCrawler
https://keep-steady.tistory.com/29
제일 빠르고 간편
- Terminal에서 (vs code사용)
git clone https://github.com/YoongiKim/AutoCrawler
cd AutoCrawler
pip install -r requirements.txt
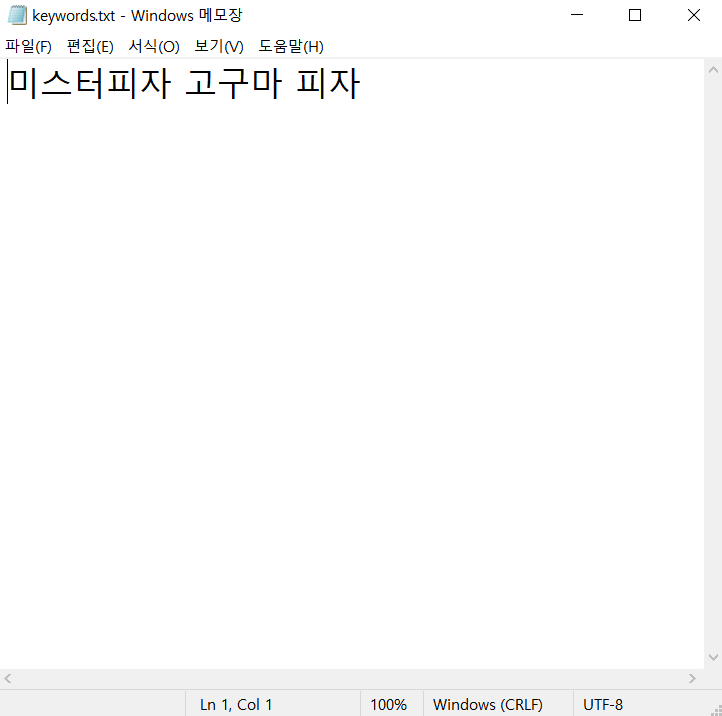
#keywirds.txt 키워드 적기
python main.py --limit 100AutoCrawler폴더 안의 keywords.txt에 검색하는 키워드를 한 줄에 한 개씩 적기

DL 공부중