안녕하세요 이번 시간에는 Spring Boot에서(Spring Boot 외에도 적용될 수 있는 내용입니다!) 캐싱을 진행할 때 주의할 점에 대해서 포스팅하도록 하겠습니다.
우선 용어를 정리해야 합니다. 캐시와 캐시 항목은 다르다는 개념을 알고 계시면 됩니다. 캐시 항목은 하나의 캐시 내에 있는 key-value 쌍으로, 캐시에 저장하는 데이터를 의미합니다. 반면 캐시는 캐시 항목의 집합으로 하나의 캐시 내에 여러 캐시 항목이 존재합니다.
그렇다면 이 개념이 왜 중요할까요? 바로 다음에 알아볼 Spring Boot 캐시 종류를 알아볼 때 필요하기 때문입니다. Spring Boot에서는 여러 캐시를 지원하는데 대표적으로 Caffeine이 있습니다. Caffeine은 고성능 인메모리 캐싱 라이브러리로 빠른 액세스와 비동기 로딩 등을 제공합니다. 이를 이용하여 캐싱 동작을 보다 세밀하게 제어가 가능합니다. Spring Boot에서는 @EnableCaching과 @Cached 어노테이션을 이용하여 쉽게 캐시를 사용할 수 있으며, 별도의 @Bean을 등록하여 Caffeine과 같은 다른 인메모리 저장소를 이용할 수 있습니다.
Spring Boot에서 캐싱을 아래와 같이 사용합니다. 우선 서비스의 main 메서드가 존재하는 클래스에 @EnableCaching을 추가합니다. 이를 추가하면 해당 서비스는 캐싱을 이용할 것이다라는 것을 선언하여 어노테이션을 이용한 캐시 서비스를 이용할 수 있습니다.
@SpringBootApplication
@EnableCaching
public class TodaServerSpringbootApplication {
public static void main(String[] args) {
SpringApplication.run(TodaServerSpringbootApplication.class, args);
}
}이어서 캐싱을 원하는 메서드에 @Cacheable("캐시 이름") 어노테이션을 추가합니다. 이 어노테이션이 추가된 메서드가 실행되면 어노테이션 내의 캐시 이름에 해당하는 캐시가 존재하는지 체크하여 존재한다면 캐싱된 데이터를 리턴하고 없다면 결과값을 메모리에 캐싱하게 됩니다.
@Cacheable("privacy")
public String readTxtFile(String filename) {
try{
ClassPathResource resource = new ClassPathResource(filename);
InputStream inputStream = resource.getInputStream();
byte[] fileData = FileCopyUtils.copyToByteArray(inputStream);
return new String(fileData, StandardCharsets.UTF_8);
}
catch (IOException e){
throw new WrongAccessException(WrongAccessException.of.READ_TXT_EXCEPTION);
}
}자체적으로 제공하는 인메모리 저장소 외에 다른 저장소를 이용하고 싶을 경우 직접 Bean 등록을 하면 됩니다. 아래는 Caffeine을 기본 인메모리 저장소로 등록하는 예시입니다.
여기서 initialCapacity는 캐시 초기 크기를 의미합니다. 캐시 항목 크기가 아니라 캐시 크기라는 점에 유의하셔야 합니다. 따라서 입력값 단위는 캐시 항목의 크기가 아닌 캐시 항목의 수입니다. 캐시 크기가 initialCapacity를 초과하면, 즉 캐시 내부의 캐시 항목 수가 initialCapacity에서 정의한 값보다 많아지면, 자동으로 캐시 크기를 조정하는 작업을 수행합니다. 이 과정에서 항목 재해싱 등 비용이 많이 드는 작업을 수행하여 메모리 소비와 성능 오버헤드가 증가합니다.
maximumSize는 캐시가 보유할 수 있는 최대 캐시 항목 수입니다. 여기도 마찬가지로 입력값 단위는 캐시 항목의 크기가 아닌 캐시 항목의 수입니다. 캐시 크기가 maximumSize를 초과하면, 즉 캐시 내부의 캐시 항목 수가 maximumSize에서 정의한 값보다 많아지면 제거 정책에 따라 기존 항목을 제거합니다. 이 때 자주 액세스하는 데이터가 제거되면 더 많은 캐시 누락이 발생합니다.
@Configuration
public class CaffeineConfig {
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.initialCapacity(10000)
.maximumSize(10000)
.recordStats());
return cacheManager;
}
}이를 통해 사용할 캐시 항목 수에 따라 적절한 initialCapacity과 maximumSize 값을 설정해야 한다는 점을 배웠습니다. 그럼 하나의 캐시 항목의 크기가 큰 경우는 어떻게 해야 할까요?
결론부터 말씀드리자면 크기가 큰 데이터는 캐싱이 오히려 좋지 않습니다. 이를 위해선 캐싱의 프로세스에 대해 알아야 합니다. Spring Boot에서 데이터를 캐싱할 때 크기가 큰 데이터라도 전체 콘텐츠를 있는 그대로 저장합니다. 이 떄 데이터를 직렬화하여 캐시에 저장하게 되며, 데이터를 캐시에서 조회 시 역직렬화하여 값을 조회합니다. 이 과정에서 하나의 캐시 항목이 크다면 전체 데이터를 직렬화 및 역직렬화해야 하므로 더 많은 메모리를 사용하여 오버헤드가 발생할 수 있습니다. 즉 캐싱을 했을 때 오히려 성능이 저하될 수 있습니다.
이는 아래의 실험 데이터를 통해 검증할 수 있습니다. 아래의 표는 Spring Boot 캐시 옵션 별 Latency의 평균 및 표준편차를 구한 값입니다. 각각의 Latency는 Jmeter에서 스레드 100개, loop를 2로 하여 200개의 요청을 처리했을 때의 평균 Latency를 의미합니다.
표를 보시면 캐시를 적용하지 않았을 때와 캐시를 적용했을 때 오히려 캐시 적용 시 Latency가 큰 차이가 없는 것을 알 수 있습니다. 오히려 표준편차, 즉 얼마나 더 고르게 Latency가 발생했냐를 보면 캐시를 적용하지 않았을 때 더 안정적인 Latency가 나타납니다.(상대적으로 덜 들쭉날쭉한) 또한 캐시를 적용 시 가장 초반에 Latency가 크게 측정되는데, 이는 초기 캐싱을 위한 오버헤드로 추측할 수 있습니다.
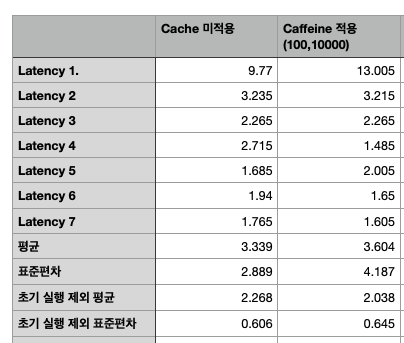
또한 initialCapacity과 maximumSize 값의 차이에 따른 데이터 비교도 가능합니다. 보시면 두 값을 각각 10000으로 설정했을 때와 100으로 설정했을 때 큰 성능 차이가 발생하지 않는 것을 알 수 있습니다. 이는 하나의 캐시 항목만을 사용했기 때문에 initialCapacity나 maximumSize로 인한 오버헤드가 발생하지 않는 상황이기 때문입니다.


감사합니다. 이런 정보를 나눠주셔서 좋아요.