🥬 상품명은 제각각인데, 어떻게 비교하지?
예를 들어, 하나의 상품이 있다고 해봅시다.
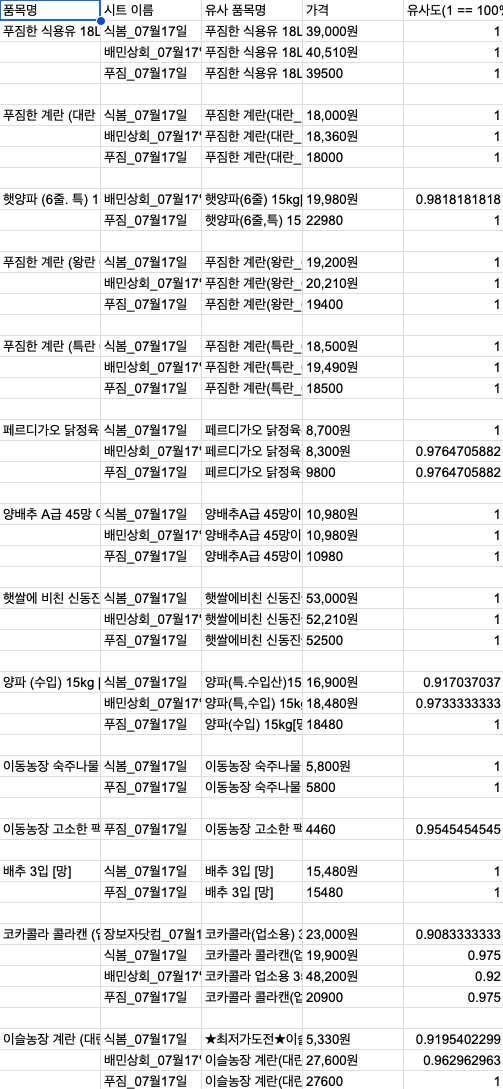
‘표고버섯 (수입산) 4kg [BOX]’ 같은 식자재 상품입니다.
그런데 이 상품을 여러 플랫폼에 등록하다 보면, 각 플랫폼마다 상품명이 조금씩 다르게 표기되는 문제가 생깁니다.
어떤 곳은 브랜드명을 앞에 붙이기도 하고,
어떤 곳은 괄호 대신 대괄호를 쓰거나
_, * 같은 특수문자가 들어가기도 하죠.
이렇다 보니 단순 문자열 비교로는 같은 상품인지 판단하기가 굉장히 어렵습니다.
💡 ‘유사도’라는 개념을 알게 되다
검색을 하다 보니, 두 문자열 간의 유사도를 수치로 표현할 수 있는 방법이 있다는 걸 알게 됐습니다. 바로 문자열 유사도(Similarity Score).
유사도는 0에서 1 사이의 값으로 표시됩니다.
1이라면 완벽하게 일치,
위처럼 유사도 기준을 적용하니,
상품명이 달라도 실질적으로 같은 상품이라는 걸 식별할 수 있었습니다.
🛠️ Python은 많은데 JS는...? → natural 라이브러리 발견
Python에서는 fuzzywuzzy, difflib, Levenshtein 등 유사도 처리에 사용할 수 있는 라이브러리가 꽤 많습니다.
하지만 저는 Node.js 환경에서 작업 중이었기 때문에,
Javascript 쪽에서도 유사도 비교를 할 수 있는 라이브러리를 찾기 시작했습니다.
그러다 발견한 게 바로, natural 이라는 라이브러리입니다.
덕분에 JS에서도 문자열 유사도 비교를 할 수 있게 됐고,
0.9 이상의 유사도를 가진 상품끼리 매칭하는 로직을 구현할 수 있었습니다.
⚙️ 전체 흐름은 이렇게 구성했습니다
플랫폼이 많고, 크롤링도 오래 걸리는 상황이기 때문에
최종적으로 아래와 같은 흐름으로 정리했습니다.
각 플랫폼의 상품 정보를 크롤링
크롤링한 데이터를 Google Sheet에 정리
Google Sheet에서 유사도 기준(0.9 이상)으로 비교
가장 유사도가 높은 상품을 기준으로 자동 매칭
