[Mysql] 시간 함수를 활용한 GPS 변위 그래프 SQL문 리팩토링

📌 개발 동기
최근 입사한 회사내 백오피스 서버에서 사용하는 사내 GPS 모니터링 웹의 날짜별 GPS 신호 로그 파악 그래프를 처음 인계 받아 테스트해보았는데, 하루치도 엄청 버벅거리고, 이틀치부터는 아예 서버가 팅겨서 조회가 되지않는 현상을 발견했다.
그 이유를 찾아보니 . . .
- 그래프에 실제 찍히는 점의 개수는 3000개 남짓이나, 서버에서는 설정한 날짜 조건에 맞는 모든 데이터 개수를 가져오고 있었고, 이를 클라이언트에서 3000개의 데이터로 샘플링하여 출력하는 형태로 사용되고 있었다.
- 테이블에 초당 1개씩 데이터가 쌓이게 설계되어있어, 하루당 약 86400개를 가져오고 있었으며, 약 20일치를 조회하게 된다면 170만개 가량을 가져옴으로써 너무 많은 데이터양을 그래프에 매핑하는 과정에서 서버가 다운되는 현상이 나타났다.
개선 방향에 대한 고민
- 세세한 데이터 하나하나까지 필요한 그래프였다면, 모든 데이터를 전부 출력해주는게 맞지만, 이 그래프의 목적은 GPS 신호의 변위를 대략적으로 확인하는 것이 목적이므로 모든 데이터를 전부 가져오는 것은 비효율적이라고 생각했고, 이 많은 데이터를 애초에 다 가져와서 그래프에 연동한다는 것은 불가능에 가깝지 않을까라는 생각을 했다.
- 따라서 그래프에 나타낼 최소 단위(3000개) 이하의 데이터는 그대로 Select를 해서 가져오고, 그 이상이 되었을 경우 10000개든, 20000개든 데이터가 들어와도 그 중 일정한 간격으로 전체의 3000개만을 Select해서 가져와 전체적인 변위를 파악할 수 있는 대략적인 그래프를 사용자가 볼 수 있게끔 설계하고자 했다.
📌 개발 내용
이전 코드 (getLog.js)
GPS 수신기의 식별자와 시작/종료 날짜 조건을 걸어 가져오는 간단한 Select SQL문이다.
SELECT deviceId, logDate, lat, lon, alt, geoidal, T
FROM log
WHERE logDate > "2023-07-15 00:00"
AND logDate < "2023-07-25 00:00"
AND deviceId = "측정할 수신기 ID"결과
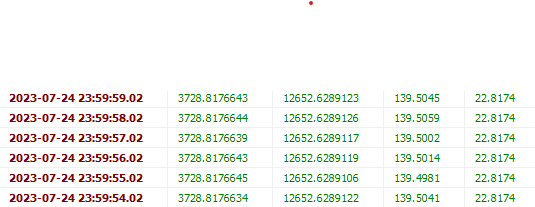
/* 영향 받은 행: 0 찾은 행: 862,557 경고: 0 지속 시간 1 쿼리: 0.015 초 (+ 8.297 초 네트워크) */약 10일치를 조회하는데 86만행, 약 8.3초 가량이 소요되었다.
Query 실행 속도만 본다면 그렇게 느리다고 생각이 들지 않을수 있지만, 클라이언트에서 해당 데이터에 대한 API 요청을 할 때 86만건의 많은 양의 데이터를 다운로드 받고, 그래프에 연동하는 과정에서 실제론 서버가 다운될정도의 딜레이가 발생했다.
수정한 내용
SELECT deviceId, logDate, lat, lon, alt, geoidal, T
FROM gga_log
WHERE logDate > "2023-07-15 00:00"
AND logDate < "2023-07-25 00:00"
AND deviceId = "측정할 수신기 ID"
GROUP BY FLOOR(
TIMESTAMPDIFF(SECOND, "2023-07-15 00:00", logDate) / # (2)
((
SELECT COUNT(*) AS result FROM gga_log
WHERE logDate > "2023-07-15 00:00"
AND logDate < "2023-07-25 00:00"
AND deviceId = "측정할 수신기 ID") / 3000 # (1)
))결과
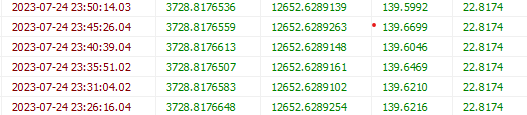
/* 영향 받은 행: 0 찾은 행: 3,006 경고: 0 지속 시간 1 쿼리: 3.203 초 (+ 0.032 초 네트워크) */약 10일치를 조회하는데 2.5배정도 빨라진 3초를 반환하였고, 초의 간격이 완벽하게 떨어지는 경우는 잘 없어, 3000개를 딱 맞출 수 없었지만 대체로 +-10초 정도의 오차로 약 3000개의 데이터를 가져온다.
또한 사진을 보면 logDate의 초 간격도 데이터 개수, 가져올 개수에 의해 계산된 시간초에 따라
일정한 간격으로 가져옴을 확인할 수 있다.
(1) 전체 데이터 개수 / 가져올 행의 개수를 통하여, 몇 초 단위로 데이터를 가져올지 계산
(2) 계산된 데이터를 바탕으로 간격을 초로 계산하고, 그룹을 만들어 Select
📌 마치며 . . .
해당 로직은 데이터가 저장되는 주기가 일정한 시간마다 존재하는 저장소에 쓸 수 있으며, 그래프 혹은 다른 라이브러리에 빅데이터를 설정한 작은 단위로 가져와 대략적으로 표현하고 싶을 때, 사용합니다.
특수한 목적으로 사용했고, 프로젝트의 목적에 맞게 사용한만큼, 특정 상황이 맞지 않는다면, 쓰기 어려운 부분이 많을거라고 생각하지만, 저처럼 수많은 데이터를 전부다 불러오면 과부하를 일으키는 상황에서 대략적으로 그래프에 데이터 값들을 표시하고 싶을때, 사용해보시면 좋을 것 같습니다.
다만 그저 초 간격으로 데이터를 끊어서 가져오는 방식이라, 데이터가 어떤 초 단위 간격으로 저장되어있느냐에 따라 오차라던지 변수가 발생할 수 있으니 유의하시면 좋을 것 같습니다.
📌 추가 개선 방향
앞으로 더 빠르게 하기 위해서, 테이블을 파티셔닝하여 월별로 나눠서 가져온다면 검색 범위가 줄어들어 속도가 조금이나마 더 빨라질것 같습니다.
추후에 파티션을 추가하게 된다면 다음에 이어서 포스팅 해보도록 하겠습니다.
오늘도 좋은 하루되시고, 피드백이나 질문이 있다면 댓글에 남겨주세요!
긴글 읽어주셔서 감사합니다.
