영상 처리 5주차 - 밝기 개선과 수많은 문제
해당 포스팅은 지식 공유에 목적이 있는 자료가 아닙니다. opencv와 python을 활용한 영상처리 - 얼굴인식의 과정을 공부함에 있어 기록을 하기 위해 작성된 글입니다. 유의 바랍니다.
시작하기에 앞서
지난 포스팅에서 밝기와 명암을 조절하여 어느정도 수준까지 얼굴인식이 가능한가에 대해 알아보면서 히스토그램 스트레칭및 평활화를 이용하여 밝기 개선을 하는 작업을 진행해 보았다.
위의 작업을 수행해보고 밝기 및 명암에 대한 개선이 원활하게 진행되는 줄 알았지만 이번 주에 제대로 검증하는 과정을 수행하던 중 수많은 문제점에 부딪혔다. 가장 많은 시간을 이번 작업에 쏟아부었지만 가장 어려움이 많고 문제점만 발견된 시간이였던 것 같다. 물론 그렇다고 이미지 개선에 성공한 것도 아니다.
그렇지만 수많은 문제점을 알게 되었고 더불어 어떤 식으로 진행해 나가야 하는지에 관한 방향성 또한 찾게 되었다. 그것에 대해 기록해보고자 한다.
수행한 작업과 문제점
간단한 코드 리펙토링
지난 포스팅의 코드를 보면 알겠지만 밝기 조절을 하는 모든 함수를 우린 하나의 메인 파일안에 전부 넣어주었다. 코드가 간결하면 문제가 되지 않지만 수행해야 할 함수가 많아짐에 따라 점점 코드가 지저분해지다는 것을 깨달았다. 메인파일에는 이미지를 불러오는 로직 및 얼굴을 인식하는 코드 만 있어야 한다고 생각했다. 평소에 객체지향 프로그래밍을 하던 나에겐 절차지향적으로 코드를 작성하는 것은 굉장히 지저분한 코드라 느껴졌다. 물론 완벽히 리펙토링을 하진 못하였지만 밝기를 조절하는 함수들은 따로 분리해보고자 하였다.
파이썬도 일단 객체지향 언이인 만큼 모듈화를 시키는 것이 가능하다 생각하였고 이에 따라 파일을 분리하였다. "Class"를 시켜 모듈화한 것이다.
// saturate_control.py
import cv2
import dlib
import sys
import numpy as np
from matplotlib import pyplot as plt
class SaturateControl:
def __init__(self, p, num):
self.p = p
self.num = num
def setdata(self, p, num, dst_img):
self.p
self.num
self.dst_img
def saturate_whole_brightness(self):
pic = self.p.copy()
pic = pic.astype('int64')
pic = np.clip(pic*self.num, 0, 255)
pic = pic.astype('uint8')
return pic
def saturate_contrast(self):
pic = self.p.copy()
pic = pic.astype('int32')
pic = np.clip(pic+(pic-128)*self.num, 0, 255)
pic = pic.astype('uint8')
return pic
def add_brightness(self, dst_img, add_num):
add_dst = cv2.add(dst_img, add_num)
return add_dst
def sub_brightness(self, dst_img, sub_num):
sub_dst = cv2.subtract(dst_img, sub_num)
return sub_dst
def hsv_control(self, img, value):
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
lim = 255 - value
v[v > lim] = 255
v[v <= lim] += value
final_hsv = cv2.merge((h, s, v))
img = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2BGR)
return img
def downgrade_bright(self, x, y, dst):
if (dst[x, y] == [255, 255, 255]).any():
dst[x, y] = [150, 150, 150]밝기 및 명암 조절에 쓰일 만한 다양한 로직을 담은 함수들을 하나의 클래스안에 담아주었다.
메인 파일에 불러올 때는 import를 통해서 파일명을 불러오고 객체지향 언어에서 늘 그랬던 것처럼 인스턴스화 시켜 불러오면 된다. 이것이 나중에 개인 및 팀 협업에 있어서도 꼭 필요한 작업이 아닐까 싶어서 진행해 보았다.
문제점 1 -- 얼굴 감지 인식률을 어떻게?
이미지에서 얼굴을 감지할때 우린 얼굴에 rectangle을 그려서 얼굴 감지를 가능케 하였다. 이 과정에서 얼굴 감지의 정확성을 알아보고 싶었다. 간단히 예로 들자면 깔끔한 이미지의 정확성이 1이라면 밝기와 명암의 가시성이 좋지 않은 이미지에서 얼굴을 인식 할 경우 정확성이 1보다 작은 0.xxxx 이게 될 경우를 말하는 것이다.
이런 작업은 과연 어떻게 수행해야 할까 고민하던 중 cvlib라는 라이브러리를 알게 되었고 해당 라이브러리를 통해 얼굴 인식의 상태를 나타내는 confidence라는 객체를 불러올 수 있다는 것을 알게 되었다. 해당 라이브러리는 tenserflow에 내장되어 있고 그렇게 모듈을 설치하던 중 수많은 문제에 부딪혔다. 해당 cvlib를 설치하기 위해선 하드웨어에 해당하는 GPU까지 건드려야 하는 경우가 생겼고 이 방법은 그다지 좋지 못하다고 느꼈다. 또한 어떠한 과정없이 그대로 얼굴 감지의 정확성을 수치화 시키는 것또한 공부하는 과정에 있어 좋지 못하다고 판단하였다.
문제점 2 -- 이미지 밝기 개선은 과연 완벽하게 되는가?
지난 시간에 히스토그램을 이용해서 이미지 밝기 및 명암 개선을 체험? 해보았다. 그러고 그냥 아, 이렇게 개선할 수 있겠구나 하고 끝내버린 것이 오점이였다.
히스토그램 스트레칭및 평활화를 이용해서 (normalize , equalizeHist 연산) 어느 정도 이미지를 선명하게 보일 수는 있었다.
예를 들어 어두운 이미지를 인풋으로 넣고

해당 연산들을 수행하면
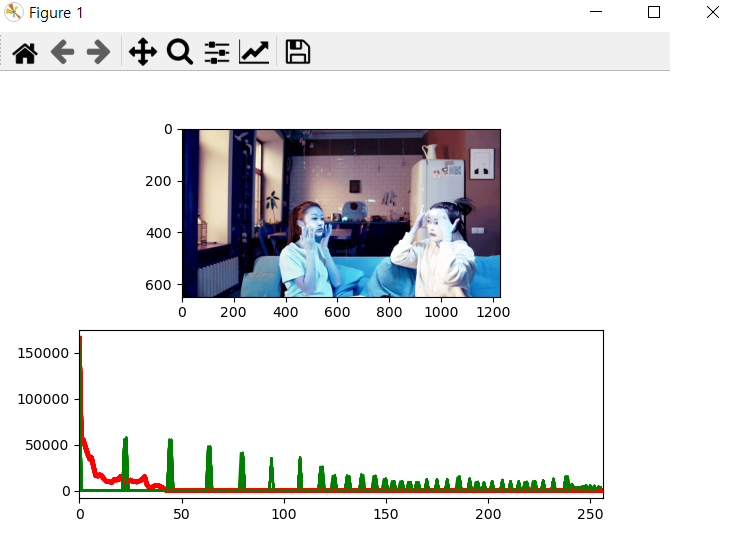
위와 같이 이미지의 픽셀 분포를 넓게 뿌려주고, (참고로 빨간선이 인풋 이미지의 픽셀 분포이고 초록선이 개선된 이미지 (dst)의 픽셀 분포이다.)

이미지 또한 가시성이 좋게 개선시킬 수 있었다.
하지만 !!!!!
밝은 이미지에 대해선 제대로 개선이 되지 않았다. 물론 여기서 밝다는 기준은 일반적 환경보다 어느정도 많이 밝아진 환경을 가정한 것이다.

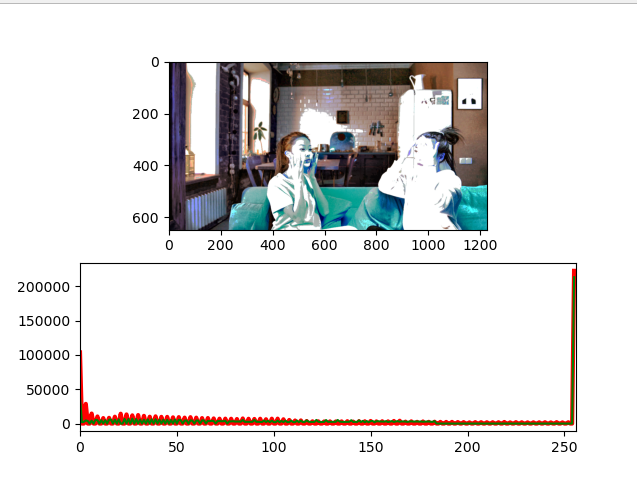
이렇게 극단적으로 밝은 이미지를 동일한 히스토그램 스트레칭 및 평활화 연산으로 개선시켜보자.
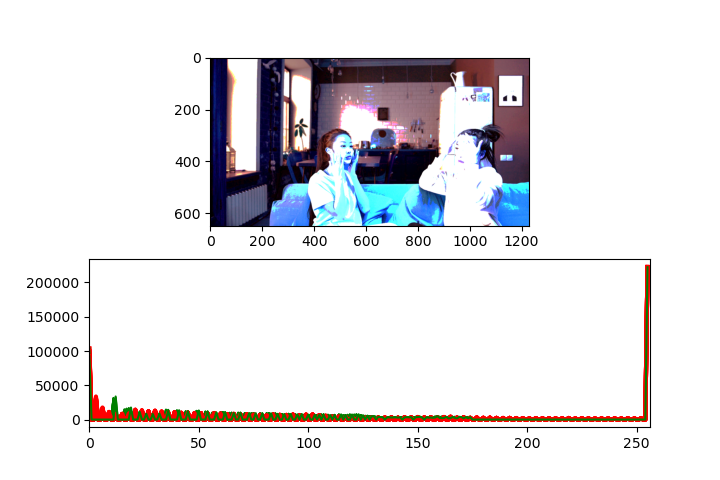
보다시피 인풋 이미지의 픽셀분포와 개선시킨 이미지의 픽셀 분포의 차이가 거의 없다. 그리고 아래 개선 이미지에서 보면 알 수 있겠지만 극단적으로 하얀 부분 (255, 255, 255)의 이미지는 변화가 없다.

개선된 이미지의 가시성이 오히려 더 좋지 않아 보인다.
이유를 알아본 결과 히스토그램 평활화의 한계였다. 여러 색상들이 공존하는 이미지에서 극단적으로 하얀 부분인 경우 개선이 되지 않는 것이다.
이러한 문제를 "CLAHE(Contrast Limited Adaptive Histogram Equalization)"라는 연산으로 해결할 수 있다길래 한 번 알아보았다.
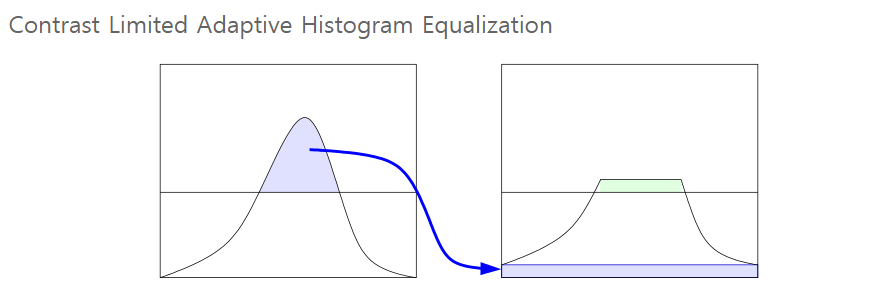
위 그림처럼 계산 전에 히스토그램 높이에 제한을 둬서 특정 높이 이상에 있는 pixel 값들을 재분배하는 방법이다. *clip limit : histogram의 높이를 제한하는 값
우리가 가정한 인풋 이미지를 보면 조명에 의한 빛, 냉장고, 그리고 얼굴에 바른 흰색 크림의 픽셀 분포가 특정 지역에 밀집되어있는 것을 알 수 있다. 그렇게 되면 그 부근에서 histogram의 높이가 매우 커지게 되고 과도하게 픽셀이 증폭되어 버린다.
이러한 문제를 해결해주는 것이 바로 clahe연산인 것이다. 그러면 해당 연산을 수행해보자.
dst_yuv = cv2.cvtColor(dst, cv2.COLOR_BGR2YUV) // BGR to YUV
dst_clahe = dst_yuv.copy()
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8, 8))
dst_clahe[:, :, 0] = clahe.apply(dst_clahe[:, :, 0])
dst_clahe = cv2.cvtColor(dst_clahe, cv2.COLOR_YUV2BGR) // YUV to BGR
dst = dst_clahe처음과 동일하게 어두운 이미지로 적용시켰을때를 알아보자. 즉,normalize + equalizeHist + clahe 연산인 것이다.
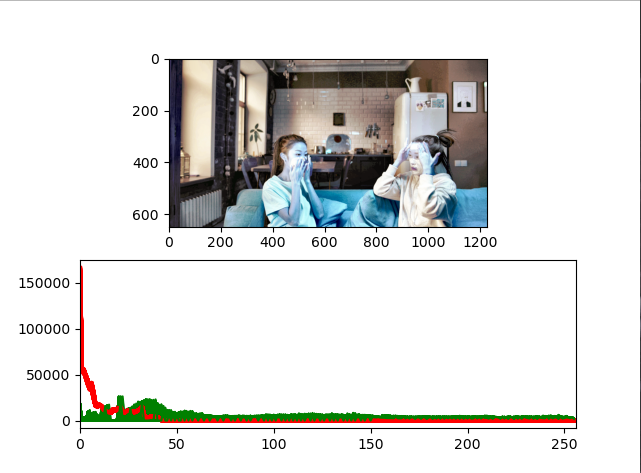
normalize와 equalizeHist만 수행했을때보다 픽셀분포가 어느 한곳에 치우쳐져있는 것을 개선할 수 있었고

이미지 또한 조금 더 가시성이 좋아진 것을 확인할 수 있다.
하지만 !!!!
이 방법또한 극도로 밝은 이미지를 개선하진 못했다.
아까 전과 동일한 극도로 밝은 이미지를 인풋으로 주고 3가지의 연산을 모두 수행해보았다.
그냥 히스토그램 스트레칭과 평활화만 했을때에 비해 그다지 개선된것이 보이지 않는다. 여전히 증폭되어버린 밀집된 픽셀은 제자리에 머물러 있다.
실제로 이미지의 width, height을 구한 뒤 해당 영역 내 좌표의 픽셀 값들을 랜덤으로 불러오는 작업을 수행해 보았는데, [255, 255, 255] 값들이 굉장히 많이 차지하고 있었다.

이미지 내 물체들의 윤곽선이 훨씬 뚜렷해지고, 색 조화가 그나마 원본에 가깝게 변화한 것은 맞지만 clahe 연산 또한 완벽한 개선은 수행하지 못하였다.
사실 물론 우리가 가정한 인풋 이미지와 같은 환경에서 얼굴 인식을 할 경우는 극히 드물것이고 비현실적인것이 당연하다. 하지만, 항상 모든 경우를 가정하고 어떠한 프로그램을 만들어야하는 것이 바람직하기 때문에 난관에 부딪히게 되었다. 아직 정확한 방법을 해결하지 못하였다.
실제로 테스트를 할때 위와 같이 어떠한 밝기의 이미지를 정해놓고 인식하는 경우는 없을테다. 모든 경우, 모든 환경을 가정을 하고 랜덤한 밝기의 이미지에 대해서 모두 개선이되는 연산을 수행해야할 것이다.
그렇다고 if문이나 for문을 통해 어떠한 RGB값에 대해 일일히 대응하는 수많은 로직을 직접 만들기에도 과연 옳은 것인가에 대한 의문도 들었다. if문이나 for문을 일일히 만들어 대응할 경우 연산시간도 늘어나고, 스코프에 대한 문제또한 일어날 것이기 때문에 엄두가 나지 않았다.
그러므로 더욱 더 힘든 작업이 되지 않을까 싶다.
문제 3 -- 길어진 연산 시간
가장 처음 원본 이미지만 출력했을 때에 비해 여러 개선을 수행하는 함수를 수행하고, for문을 통해 루프까지 돌게 되니 연산 시간이 상당히 길어졌다. 거의 0.5초에 한 프레임씩 넘어가는 정도였다. 몇 프레임까지 연산하게 되는지 직접 count += 1의 연산을 수행해 본 결과 조금 더 헤비한 연산일 수록 (예를 들어, 극도로 밝은 이미지를 개선하려는 작업 __위를 참조) count 값이 1000까지 돌파한 것을 알 수 있었다.
아직 고민해 본 적은 없지만 이것 또한 해결해야 할 과제이다.
생각정리
정말 몇일동안 다른 것은 안하고 위의 작업 및 문제 해결에 시간을 다 쓴 것 같아서 기력이 빠졌다. 뭔가 확실히 해결을 못한 점이 아쉽지만 해결해야 할 문제를 명확히 할 수 있던 시간이었다.
