
Operating Systems : Three Easy Pieces를 보고 번역 및 정리한 내용들입니다.
2. The Linux Virtual Memory System
The Linux Address Space
다른 현재 OS들처럼 리눅스 가상 주소 공간도 유저 부분과 커널 부분으로 이루어져있다. 문맥 전환이 일어날 때 현재 실행되고 있는 주소 공간의 유저 부분은 바뀌고, 커널 부분은 프로세스들 사이에서도 동일하게 유지된다. 유저 모드에서 돌아가는 프로그램은 커널의 가상 페이지에 접근할 수 없으며, 커널에 트랩을 발생시켜 특권 모드로 전환해야만 해당 메모리에 접근할 수 있다.
32비트 리눅스에서 주소 공간의 유저/커널 부분의 분리는 주소 0xC0000000, 또는 전체 주소 공간의 3/4 지점에서 일어난다. 즉 0에서 0xBFFFFFFF까지는 유저 가상 주소를 위해 쓰이고, 나머지는 커널의 가상 주소 공간을 위해 쓰인다. 64비트 리눅스도 비슷하기는 하지만, 조금 다른 지점에서 분할된다.
리눅스에서 재밌는 것은 커널 가상 주소에 두 종류가 있다는 점이다.
Kernel Logical Address
하나는 커널 논리 주소(kernel logical address)다. 이 종류의 메모리를 얻을 때에는 kmalloc을 호출한다. 페이지 테이블, 프로세스 별 커널 스택 등 대부분의 커널 자료 구조들은 여기에 있으며, 다른 메모리들과는 달리 디스크로 스왑되지 않는다.
커널 논리 주소와 물리 메모리와의 연결 관계도 눈여겨 볼 만하다. 커널 논리 주소와 물리 메모리의 사이에는 직접 사상이 일어나, 커널의 논리적 주소 0xC0000000는 물리 주소 0x0000000로 변환되고, 0xC0000FFF는 0x00000FFF로 변환된다. 이 직접 사상은 두 가지의 함의를 가진다.
- 커널 논리 주소와 물리 주소 사이의 변환이 간단하다. 이 주소들은 마치 물리 주소인 것처럼 다룰 수 있다.
- 메모리 청크가 커널 논리 주소 공간에서 연속적이면, 물리 공간에서도 마찬가지로 연속적이다. 이는 DMA를 통한 I/O 전속 작업과 같이, 정상 작동을 위해 연속된 물리 메모리를 필요로 하는 연산들을 수행할 수 있도록 한다.
Kernel Virtual Address
커널 주소의 다른 타입은 커널 가상 주소(kernel virtual address)다. 이 타입의 메모리를 얻으려면 vmalloc을 호출해야하는데, 이는 원하는 사이즈의, 가상적으로 연속된 공간을 할당하고 포인터를 반환한다.
커널 논리 메모리와 달리, 커널 가상 메모리는 보통 물리 메모리 상에서는 연속적이지 않다. 각 커널 가상 페이지는 불연속적인 물리 메모리에 매핑되지만, 할당하기는 더 쉽고, 그렇기에 큰 연속 물리 메모리 청크를 찾는 일이 어려운, 큰 버퍼를 위해 사용된다.
커널 가상 주소를 쓰는 가장 큰 이유는, 이를 이용하면 커널이 1GB가 넘는 메모리를 다룰 수 있게 되기 때문이다. 옛날에야 기기 자체가 훨씬 적은 메모리를 가졌기 때문에 고려할 필요가 없었겠지만, 커널이 더 많은 양의 메모리를 필요로 하는 오늘날에는 필수다.
Page Table Structure
x86은 각 프로세스에 하나의, 하드웨어로 관리되는 멀티 레벨 페이지 테이블 구조를 제공한다. OS가 메모리에 매핑을 설정하고 페이지 디렉토리의 시작 부분에 특권 레지스터를 가리키면, 나머지는 하드웨어가 모두 처리한다. OS는 프로세스 생성, 삭제, 문맥 전환 등의 각 경우마다 올바른 페이지 테이블이 MMU의 주소 변환에 쓰이고 있는지 확인한다.
VAX/VMS 시스템에서와 같이 32비트 주소 공간은 오랫동안 사용되어 왔지만, 이제 더 큰 메모리를 사용하게 되면서 32비트 주소는 충분하지 않게 됐다. 64비트의 주소 공간이 필요해지는 이유다.
64 비트 주소로의 변화는 x86 페이지 테이블 구조에도 영향을 준다. x86이 멀티 레벨 페이지 테이블을 쓰기 때문에 현재의 64비트 시스템은 4레벨 테이블을 사용하는데, 가상 주소 공간을 위해 64비트를 전부 쓰고 있지는 않고 하위 48비트만 쓰인다. 가상 주소의 상위 16 비트는 사용되지 않고 있고, 하위 12비트는 오프셋으로 쓰이며, 중간의 36비트가 변환되는 부분이다.
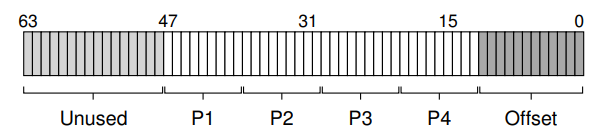
P1 부분은 최상위 페이지 디렉토리의 인덱스로 쓰인다. 주소 변환은 페이지 테이블의 실제 페이지를 P4로 인덱싱할 때까지 일어나고, 그 결과 원하던 PTE를 얻을 수 있게 된다. 시스템 메모리가 더 커지면, 이 주소 공간의 상위 16비트도 사용되어 5 레벨, 6레벨의 페이지 테이블 구조를 사용하게 될 것이다. 특정한 데이터가 메모리의 어디에 위치해있는지를 찾기 위해 여섯 단계의 주소 변환이 필요해지는 것이다.
Large Page Support
인텔 x86에서는 표준적인 4KB의 페이지 사이즈 외에도 여러 페이지 사이즈를 사용할 수 있다. 최근 설계는 2MB에서 1GB 페이지도 지원하는데, 이렇게 큰 페이지를 사용하는 것에는 많은 이점들이 있다.
- 페이지 크기가 커지면 페이지 테이블에서 필요한 매핑의 수는 줄어든다
- TLB의 동작 및 관련 성능의 향상이 일어난다.
- 프로세스가 많은 메모리를 사용하면 TLB는 금방 꽉 차게 된다.
- 만약 각 페이지의 크기가 4KB밖에 되지 않으면, TLB 미스 없이 접근할 수 있는 페이지의 양은 제한적이다. 예를 들어 64개 엔트리의 TLB는 고작 256KB밖에 효율적으로 다룰 수 없다.
- 수GB 메모리를 사용하는 오늘날, 이는 너무 비효율적이다. 모 연구에 따르면 전체 사이클의 10% 정도를 TLB 미스 처리에만 사용할 정도라 한다.
- 큰 페이지를 사용하면 TLB 슬롯을 적게 사용할 수 있고, 프로세스도 TLB 미스 없이 넓은 범위의 메모리에 접근할 수 있게 된다.
- 큰 페이지를 사용하면 TLB 미스를 처리하는 경로가 짧아져 TLB 미스를 더 빠르게 처리할 수 있다. 추가적으로 할당도 더 빨라질 수 있다.
리눅스가 어떻게 큰 페이지를 지원하는지 살펴보는 것도 재밌다. 처음 리눅스 개발자들은 이것이 성능 요구가 엄격한, 큰 데이터베이스와 같은 일부 응용 프로그램에만 필요할 것이라 생각했기에, 해당 응용 프로그램들이 명시적으로 더 큰 페이지의 메모리 할당을 요청하도록 했다. 하지만 이렇게 하려면 각 응용 프로그램들이 큰 페이지 메모리 할당을 인터페이스를 사용하도록 변경해야만 한다.
최근 더 나은 TLB 동작에 대한 수요가 커지면서, 리눅스 개발자들은 투명 거대 페이지(transparent huge page, THP)에 대한 지원을 추가했다. 이 기능이 활성화되면 OS는 어플리케이션의 수정 없이 자동으로 큰 페이지들을 할당할 수 있게 된다.
물론 큰 페이지를 사용하는 데에도 비용은 있다. 가장 큰 잠재적인 비용은 내부 단편화로, 메모리를 크기는 하지만 적게 사용되는 페이지들로 채우는 것이다. 스와핑도 거대 페이지와는 잘 어울리지 않는다. 거대 페이지는 I/O 작업을 증폭시킬 수 있기 때문이다. 할당의 오버헤드도 어떤 경우에는 나빠질 수 있다.
하지만 한 가지는 분명하다. 오랫동안 사용됐던 4KB 페이지 사이즈는 더 이상 예전만큼의 보편적인 해결책이 되지 못한다. 메모리의 사이즈가 커짐에 따라, 큰 페이지와 이를 다루기 위한 솔루션들이 필요해지는 이유다.
The Page Cache
영구 스토리지에 접근하는 비용을 줄이기 위해 대부분의 시스템은 적극적인 캐싱 서브 시스템으로 자주 쓰이는 데이터를 메모리에 보관한다.
리눅스 페이지 캐시는 세 종류의 소스로부터의 페이지들을 메모리에 담는다.
- memory-mapped files
- file data and metadata from devices
- anonymous memory : heap, stack pages that comprise each process
이것들은 해당 데이터가 필요할 때 빠르게 검색될 수 있도록 페이지 캐시 해시 테이블에 담긴다.
페이지 캐시는 엔트리의 수정 여부를 추적한다. 수정된 데이터는 백그라운드 스레드에 의해 주기적으로 배킹 스토어에 쓰여, 수정된 데이터가 결국에는 영구 저장소에 쓰임을 보장한다. 이 백그라운드 동작은 특정 기간을 두고 일어나거나, 너무 많은 페이지들이 수정된 상태로 있는 경우 일어난다.
시스템에 메모리가 부족한 경우, 리눅스는 어떤 페이지를 메모리로부터 쫓아내서 공간을 확보할지를 결정하기 위해 수정된 이중 큐(2Q) 교체를 사용한다.
이전에 표준 LRU 교체가 효과적이기는 하지만, 흔히 쓰이는 특정 접근 패턴의 경우에 대해서는 몹시 떨어지는 성능을 보임을 본 적이 있다. 리눅스 버전 2Q 교체 알고리즘은 두 리스트에 메모리를 나누는 방식으로 이 문제를 해결한다.
처음으로 접근할 때 페이지는 한 큐(A1, 또는 inactive list)에 들어가고, 재참조될 때 이 페이지는 다른 큐(Aq, active list)로 승격된다. 교체가 필요한 경우, 교체 대상 후보는 inactive list에서 뽑힌다. 리눅스는 주기적으로 페이지를 active list에서 inactive list로 옮겨 active list를 전체 페이지 캐시 크기의 2/3 정도로 유지한다.
이 리스트들은 LRU의 순서에 따라 관리되는데, 앞선 장에서 보았던 것처럼 완전히 LRU에 맞도록 사용하는 것은 비용이 너무 많이 들기 때문에, 보통은 근사 LRU를 사용한다.이 2Q 접근법은 LRU와 비슷하게 동작하지만, inactive list에 대한 순환적인 접근을 제한함으로써 순환적인 대용량 접근을 효과적으로 처리한다. 페이지는 메모리에서 쫓겨나기 전에는 절대 재참조되지 않기 때문에, active list에 있는 어떤 다른 유용한 페이지도 플러시되지 않는다.
Security And Buffer Overflows
가장 중대한 위협은 버퍼 오버플로우(buffer overflow) 공격으로, 일반적인 유저 프로그램이나 커널 그 자체에 대한 공격이 될 수 있다.
기본 아이디어는 공격자가 임의의 데이터를 타겟의 주소 공간에 주입시킬 수 있게 하는 시스템의 버그를 찾는 것이다. 보통 그 취약점은 개발자들이 입력이 너무 지나치게 크지는 않을 것이라 가정하고 해당 입력을 버퍼에 복사하는 경우 발생한다. 입력이 생각보다 너무 커서 버퍼를 초과하고 타겟의 메모리를 덮어쓰는 것이다.
오버플로가 큰 문제가 되는 경우는 많지 않지만, 공격자는 버퍼를 넘는 입력으로 대상 시스템에 특정 코드를 주입해, 해당 시스템이 공격자들이 원하는 행동을 할 수 있게 만들 수 있다. 네트워크로 연결된 유저 프로그램에서 이 공격이 성공하면, 공격자는 임의의 연산을 실행하게 만들 수 있고, 특히 OS에 대한 공격은 특권 레벨을 상승시켜 원래는 허용되지 않았을 자원들에 대한 접근을 가능하게 만들 수도 있다.
오버플로우에 대한 가장 간단한 방어법은 주소 공간의 특정 영역에 있는 코드의 실행을 막는 것이다. AMD가 도입한 NX 비트가 그 예로, 이는 해당 비트가 1인 PTE의 페이지에서 코드 실행을 막는다.
하지만 공격자들은 코드를 직접 주입하지 않고도 임의의 코드 시퀀스가 실행되도록 할 수도 있다. 바로 return-oriented programming(ROP)라 불리는 공격으로, 프로그램들의 주소 공간에 있는 코드 조각(gadgets)들을 재활용해 원하는 동작을 하도록 조작하는 방법이다.
- 버퍼 오버플로우를 통해 스택을 덮어 쓴다.
- 함수 반환 주소를 원하는 코드 조각의 주소로 변경한다.
- 해당 주소의 코드가 실행되고, ... 또 다른 코드 조각을 실행하고,...
- 이렇게 이어붙인 코드 조각이 실제로는 악의 적인 로직을 수행하게 한다.
ROP를 막으려면, 주소 공간 레이아웃 무작위화(address space layout randomization, ALSR) 기법을 사용하면 되는데, 이는 코드, 스택, 힙을 가상 주소 공간의 고정된 위치에 두지 않고 무작위화해, 공격 구현에 필요한 코드 시퀀스를 형성을 어렵게 만드는 방식이다.
ASLR은 유저 레벨 프로그램들을 위한 유용한 방어 수단이어서, 커널 주소 공간 레이아웃 무작위화(kernel address space layout randomization, KASLR)라고 하는 기능으로 커널에 통합되기도 했다.
Other Security Problem: Meltdown And Spectre
커널이 처리해야 할 다른 중대한 문제들에는 다음의 두 가지도 있다. 첫 번째는 멜트다운(meltdown), 다른 하나는 스펙터(spectre)라 불린다. 이 중 더 문제가 되는 것은 스펙터다.
주뒨 취약점은 현대 시스템의 CPU들이 성능 향상을 위해서 온갖 기술들을 다 쓴다는 데에서 시작한다. 이때 쓰이는 최적화 기술 중에는 speculative execution이 있는데, CPU가 어떤 명령이 곧 실행될 것인지를 미리 추측하고 실행하게 하는 것이다. 만약 해당 추측이 맞아 떨어지면 프로그램은 더 빠르게 실행될 것이고, 그렇지 않으면 해당 행동을 취소하고 재실행한다.
이 speculation의 문제는 프로세서 캐시나 분기 예측기 등, 시스템의 여러 곳에 실행 흔적들을 남겨두곤 한다는 것이다. 이러한 상태들은 MMU에 의해 보호될 것이라 생각했던 것들을 포함한 메모리들의 내용까지도 취약하게 만든다.
커널 보호를 향상시키는 한 방법은 각 유저 프로세스에서 커널 주소 공간을 최대한 없애고, 대부분의 데이터를 위해서는 분리된 커널 페이지 테이블을 사용하는 것이다. 이걸 커널 페이지 테이블 고립(kernel page table isolation)이라 부른다. 커널의 코드와 자료 구조들을 각 프로세스에 매핑하지 않고, 최소한만을 거기에 두는 것이다.
커널로의 전환이 일어날 때에는 커널 페이지 테이블의 전환이 일어나며, 이렇게 함으로써 보안이 향상되고 공격 벡터도 피할 수 있다. 다만 비용이 없는 것은 아닌데, 페이지 테이블을 전환하는 작업은 비싸기 때문에, 커널 페이지를 전환하는 것 또한 성능적 비용을 가진다.
KPTI가 모든 보안 문제를 해결하는 것도 아니다. 이는 잘해야 일부를 해결할 뿐이다. 다른 간단한 해결법으로는 speculation 기능을 끄는 것이 있지만, 이는 시스템을 수 천배는 느리게 만들기 때문에 선택할 만한 것이 되지는 못한다.

잘 보고 갑니다~