reinforce learning
1.강화학습 기본 용어

강화학습 에이전트를 학습시키기 위한 도구코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 연구분야. ex) Decision Tree, SVM, Random Forest, ...1\. 지도학습 (Supervised Learning) : Regres
2.강화학습 기초 이론
현재 상태의 가치 함수와 다음 상태의 가치 함수 사이의 관계를 나타낸 식$V\\pi(S_t) = E\\pi R{t+1} + \\gamma V\\pi(s\_{t+1})|S_t = s$$Q\\pi(s,a)=E\\piR{t+1} + \\gamma Q\\pi(S{t+1},A{
3.Unity ML-Agent
강화학습과 시뮬레이션 강화학습의 경우, 에이전트가 다양한 경험을 수행하며 학습 강화학습은 1. 다양한 경험을 수행해야 하므로 학습 시간이 오래 걸리고, 2. 실패가 발생하면 안되는 환경에는 적용하기 어렵기 때문에, 강화학습의 경우 주로 시뮬레이션을 통해 학습 및 성능을
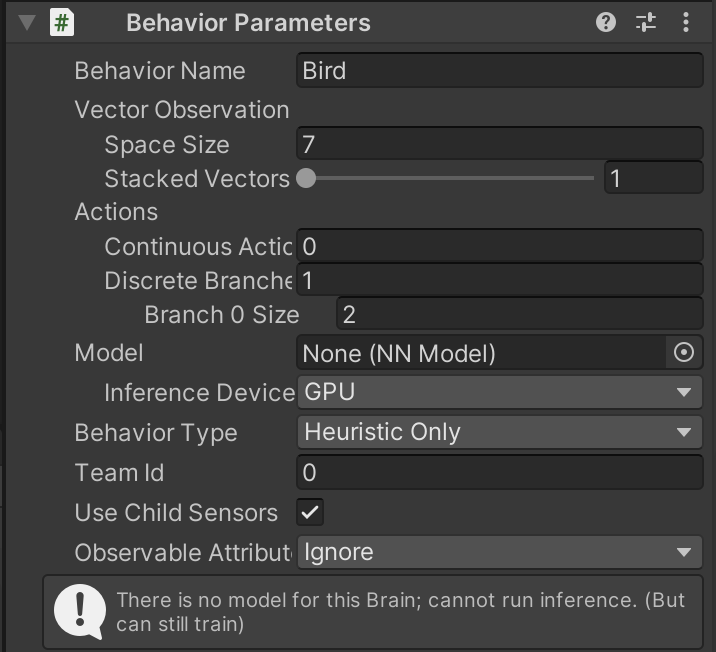
4.Unity ML-Agent 내부 요소 및 함수
에이전트의 학습에 관련된 파라미터학습의 결과로 나올 모델의 이름환경의 수치적 관측 관련 설정Space size를 통해 관측의 크기 설정 (ex. x, y, z좌표라면 3)Stacked Vector를 통해 관측의 누적 횟수 결정 (ex. 바로 이전 스텝의 위치와 현재의
5.ML-Agents
Proximal Policy Optimization (PPO)Soft Actor Critic (SAC)Curiosity based Exploration (ICM, RND)Multi-Agent POsthumous Credit Assignment (MA-POCA)PPO와
6.DQN (Deep Q Network)
가치 기반 강화학습 (Value-based Reinforcement Learning)정책 기반 강화학습 (Policy-Based Reinforcement Learning)DQN은 대표적인 가치 기반 강화학습의 알고리즘이다.큐 함수를 학습하여 최적의 큐 함수를 얻고 이를
7.ml-agent 활용 예제 - 01. Unity 환경 제작하기
01. 게임 환경 제작하기 > 참고) https://www.youtube.com/watch?v=EqoU1PodQQ4&t=8297s 위 유투브를 따라서 제작하면 아래 사진과 같은 게임 환경을 손쉽게 제작할 수 있다. 여기서 우리가 원하는 바는 게임 환경 제작이 아닌
8.강화학습 개념
상태, 상태 천이 확률 밀도 함수, 행동, 보상함수로 이루어진 stochastic process.$p(x{t+1}|x_t, x{t-1}, ..., x0, u_t, u{t-1} ..., u0)=p(x{t+1}|x_t, u_t)$ 이면 마르코프 시퀀스라고 부른다.즉, $t
9.벨만방정식 유도하기
상태가치함수는 다음과 같다.$$\\begin{aligned}V^\\pi(xt)&={\\mathbb E}{\\tau{u_t:u_T}\\sim p(\\tau{ut:u_T}|x_t)}\\left\[ \\sum\\limits{k=t}^T \\gamma^{k-t} r(xk, u
10.ml-agent 활용 예제 - 02. python DQN
완성 히히히
11.정책 그래디언트
환경으로부터 받는 누적 보상을 최대화하는 최적 정책을 구하는 것.목적함수는 다음과 같이 표현 가능하다.$$\\begin{aligned}J(\\theta) = {\\mathbb E}{\\tau \\sim p\\theta(\\tau)} \\left \\sum\\limits
12.A2C
한 에피소드가 끝나야 정책을 업데이트할 수 있다.그래디언트 분산이 매우 크다.온-폴리시 방법이다.여기서는 1번과 2번에 대한 단점을 개선한 A2C(advanced actor-critic) 알고리즘을 공부할 예정이다.REINFORCE 알고리즘의 목적함수와 그래디언트는 다
13.A2C 알고리즘
A2C 알고리즘의 목적함수 그래디언트는 다음과 같다.$$\\begin{aligned}\\nabla\\theta J(\\theta) = \\sum\\limits{t=0}^T ({\\mathbb E}\\nabla\\theta \\log \\pi\\theta(ut|x_t)
14.A3C (Asynchronous Advantage Actor-Critic)
에피소드가 끝날 때까지 기다리지 않아도 된다.Advantage 함수를 도입해 그래디언트 분산을 줄였다.정책과 가치함수를 학습시킬 때 사용되는 샘플(batch)가 시간적으로 상관되어 있다.샘플간의 높의 상관관계는 그래디언트를 편향시키고 학습을 불안정하게 만들 수 있다.A