영화 순위만 보러면 맨 아래 결과로 이동하세요
개요

2023년 3월 31일부로 네이버 영화 서비스가 종료되었습니다. 영화를 보는 것을 좋아하고, 특히 잘 만든 명작 영화들을 거의 존경하는 저로서는 네이버영화 페이지가 사라지기 전에 꼭 해야할 행동이 있었습니다.
그것은 영화 평점 랭킹페이지를 보존하는 것입니다. 단순히 페이지 스크린샷 정도로 끝내려고 했던 저는 페이지를 보고 실망하게 되었습니다. 그곳에는 흔히 말하는 명작 영화들 보다는 그렇지 않은 영화들이 중간중간에 매우 많이 섞여있었기 때문입니다.
저는 크롤링을 이용하여 제 기준에 맞지 않는 영화들을 걸러낼 수 있을거라 생각했고, 제거될 영화들의 몇가지 특징을 조사한 후 저만의 새로운 네이버 랭킹을 저장하기로 마음먹었습니다.
특징1) 연예인 실황영화도 랭킹에 선정되어있다.
현재 네이버 영화 랭킹탭의 1등을 차지하고 있는 영화는 '아임 히어로 더 파이널'이라는 가수 임영웅씨의 다큐멘터리 영화입니다. 이러한 영화들은 제가 찾는 영화도 아닐뿐더러 영화에 대한 평점보다는 팬심이 많이 반영되어 있다고 생각하여 제외하였습니다.

특징2) 적은 평점 수의 영화도 랭킹에 선정되어있다.
네이버는 평점 응답자 300명부터 영화를 랭킹탭에 선정하고 있습니다. 그러나 300이라는 숫자는 일반적으로 좋은 영화를 고르기 위해선 적은 숫자라고 판단했습니다. 그 이유는 매니악한 영화, 특정 종교를 위한 영화, 특정 성향이 강한 영화들도 네이버 랭킹탭에 올라가 있었기 때문입니다.따라서 저는 평점 응답자 수 3000명이라는 기준을 잡고 그 아래 영화들은 제외하였습니다.

만들기
네이버영화 크롤러는 3가지 함수로 구분지어 만들었습니다.
- getStandardDay() : 랭킹 선정 기준일을 반환하는 함수입니다.
- getCodesFromPage(pagenum, standardDay) : 페이지 숫자와 기준날짜를 받아서 목록안의 영화들의 숫자코드를 반환합니다.
- insertMovieFromCodes(codes) : 숫자코드 리스트를 받아서 제가 설정한 기준에 맞는 영화면 데이터베이스에 추가합니다.
1. getStandardDay()
네이버 영화의 랭킹 목록페이지 url은 다음과 같습니다.
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=기준날짜(YYYYMMDD)4&page=페이지 넘버
위에 따르면 페이지에 접근하려면 기준날짜와 페이지 넘버가 필요합니다. 네이버 영화는 자정을 기준으로 정보가 업데이트되므로 가장 최신의 데이터는 어제의 데이터입니다.
datetime 라이브러리를 import하여 어제의 날짜를 YYYYMMDD형식으로 반환하는 함수를 만들었습니다.
def getStandardDay():
#YYYYMMDD형식의 기준일을 문자열로출력한다.
today = date.today()
yesterday = date.today() - timedelta(1)
return(str(yesterday.strftime("%Y%m%d")))2. getCodesFromPage(pagenum, standardDay)
한 랭킹 페이지에는 평점 순서대로 50개의 영화들이 목록되어 있으며, 각 영화들은 모두 해당 영화 상세페이지로의 하이퍼링크입니다.
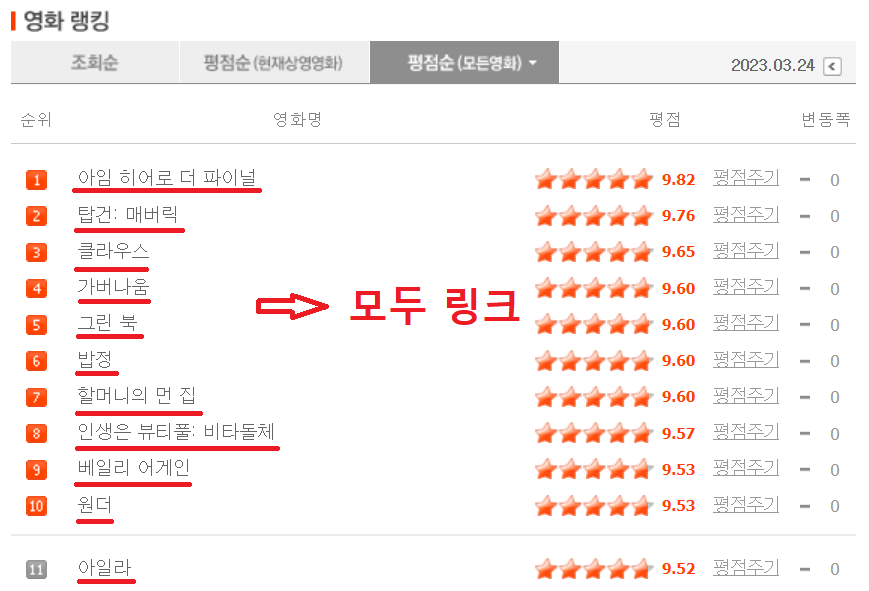
영화 상세페이지의 url은 다음과 같습니다.
getCodesFromPage() 함수는 페이지 넘버와 getStandardDay()에서 구한 기준날짜를 받아서 랭킹페이지를 열고, 페이지 안의 목록들을 반복문으로 돌며 영화 코드들을을 수집합니다. 평점이 9.0아래인경우 반복문을 중지하고 지금까지 모은 코드들을 반환합니다.
def getCodesFromPage(pagenum, standardDay):
html = urlopen('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date='+standardDay+'&page='+str(pagenum))
bs = BeautifulSoup(html, 'html.parser')
codes = []
list = bs.find('tbody').findAll('tr')
for tr in list:
movie=tr.find('a')
if(movie == None):
#목차 앞뒤로 목록 indicator들이 있는데 이들은 tr안에 들어가지만 영화리스트는 아니다. 따라서 넘김
continue
elif(float(tr.find('td',{'class':'point'}).get_text())<9.0):
break
else:
link = movie.attrs['href']
#영화 코드부분만 추출
codes.append(link[30:])
return codes3. insertMovieFromCodes(codes)
이 함수는 getCodesFromPage()에서 구한 코드들을 받아서 영화의 제목, 감독, 그리고 평점을 database에 넣는 함수입니다. db에 넣기 전, 위에서 설정한 몇가지 특징들로 조건문을 만들어 db에 넣을지 말지를 선택합니다.
이렇게 간단히 생각하고 함수를 만들었지만, 계속해서 에러가 발생하였습니다. 에러의 원인에 대해 계속 생각해본 결과, 2가지 문제점을 찾아내었습니다.
첫번째 문제점) 특정 영화 상세페이지에서 조건을 확인하기 위해 사용된 find()함수가 None을 반환함
해결) 에러가 발생하는 지점의 영화코드들을 분석해보니, 모두 19금 영화였습니다. 저는 네이버로그인이 되어 있어서 막힘없이 영화상세페이지에 들어갈 수 있었으나, beatifulsoup는 19금 로그인페이지로 빠지게 된 것으로 확인했습니다.
이 에러를 찾는데 시간이 걸린 이유는 네이버가 모든 19금 영화에 제한을 걸어둔 것이 아니였기 때문이였습니다. '올드보이'같은 유명한 영화는 로그인을 안해도 들어갈 수 있었고, 해외의 덜 유명한 영화들만 로그인이 필요했습니다. 하지만 이는 저에게는 오히려 좋았습니다. 9.0점 이상의 영화들 중에서 제한이 걸리는 영화는 2개뿐이였는데, 이들은 모두 특징2를 만족했기 때문에 database에 넣을 필요가 없었습니다.따라서 try ~ except문을 사용하여 이부분에 에러가 있었다는 메세지를 영화코드와 함께 출력하는 선에서 마무리 하였습니다.
두번째 문제점) 랭킹페이지에는 9.0이 넘는 영화였으나, 실제 영화상세페이지에 들어가본 결과 9.0 아래의 영화인경우
해결) 영화랭킹페이지가 모든 영화들의 평점변동사항을 반영하지 못해 생겨난 에러라고 생각했습니다. 결국 영화랭킹페이지의 평점을 따를 것이냐, 영화상세페이지의 평점을 따를 것이냐를 선택해야하는데, 영화상세페이지에선 9.0이상이지만 랭킹페이지에선 9.0이하인경우 멈춰야할 시기를 찾을 수 없게됩니다.
따라서, getCodesFromPage()에서도 평점을 조사하여 랭킹페이지의 평점을 따르되 상세페이지에선 9.0아래인경우는 db에 넣지 않았습니다.
def insertMovieFromCodes(codes):
for code in codes:
html = urlopen('https://movie.naver.com/movie/bi/mi/basic.naver?code='+code)
bs = BeautifulSoup(html, 'html.parser')
validMovie = True
#조건1. 공연실황 영화 제거(ex. 아임 히어로 더 파이널, 장민호 드라마 최종회)
try:
types = bs.find('dt',{'class':'step1'}).next_sibling.next_sibling.findAll('a')
except:
print("error in condition 1, "+code)
continue
for type in types:
if(type.get_text()=='공연실황'):
validMovie = False
break
if(validMovie==False):
continue
#조건2. 네티즌 리뷰 수가 3천 미만이면 제거
try:
numReview = int(bs.find('span', {'class':'user_count'}).get_text()[3:-1].replace(',',''))
except:
print("error in condition 2, "+code)
continue
if(numReview<3000):
validMovie = False
if(validMovie==False):
continue
#rating을 먼저 스크랩 해보고 특정값(9.0) 아래면 포함시키지 않는다
ratingTag = bs.find('div', {'class':'score score_left'}).find('a', {'id':"pointNetizenPersentBasic"}).findAll('em')
rating=''
for r in ratingTag:
rating += r.get_text()
if(float(rating)<9.0):
print("In ranking list. but under 9.0, "+code)
continue
title = bs.find('div',{'id':'content'}).find('div', {'class':'mv_info'}).find('a',{'href':'./basic.naver?code='+code}).get_text()
director = (bs.find('div',{'id':'content'}).find('div', {'class':'mv_info'}).find('dt').next_sibling.next_sibling.get_text()).strip()
cur.execute('INSERT INTO movielist (title, director, rating) VALUES (%s, %s, %s)', (title, director, rating))
conn.commit()
return True4. 실행
페이지는 1부터 시작하고 getCodesFromPage()의 반환값이 빈 리스트가 나올때(랭킹페이지에 9.0이상 영화가 하나도 없을 때)까지 페이지 수를 하나씩 늘려가며 반복합니다.
numPage=1
codes = getCodesFromPage(numPage, getStandardDay())
while(codes):
insertMovieFromCodes(codes)
numPage +=1
codes = getCodesFromPage(numPage, getStandardDay())느낀점 및 결과
깔끔하게 끝날 것이라고 생각했던 것과는 다르게, 여러가지 문제점들을 만나니 코드가 더 길어지고 더러워졌던 것 같습니다.
만드는 것보다 더 어려운 것은 영화를 고르는 기준을 정하는 것이였습니다. 그래서 제 인생 top3 영화(굿 윌 헌팅, 그린북, 여인의 향기)가 모두 들어가는 것을 목표로 하였고, 덕분에 기준을 더 쉽게 잡을 수 있었습니다.
전체 코드 보기 : 전체 코드 링크
결과는 다음과 같습니다. 엑셀 파일을 따로 원하시면 메일로 드리겠습니다.

