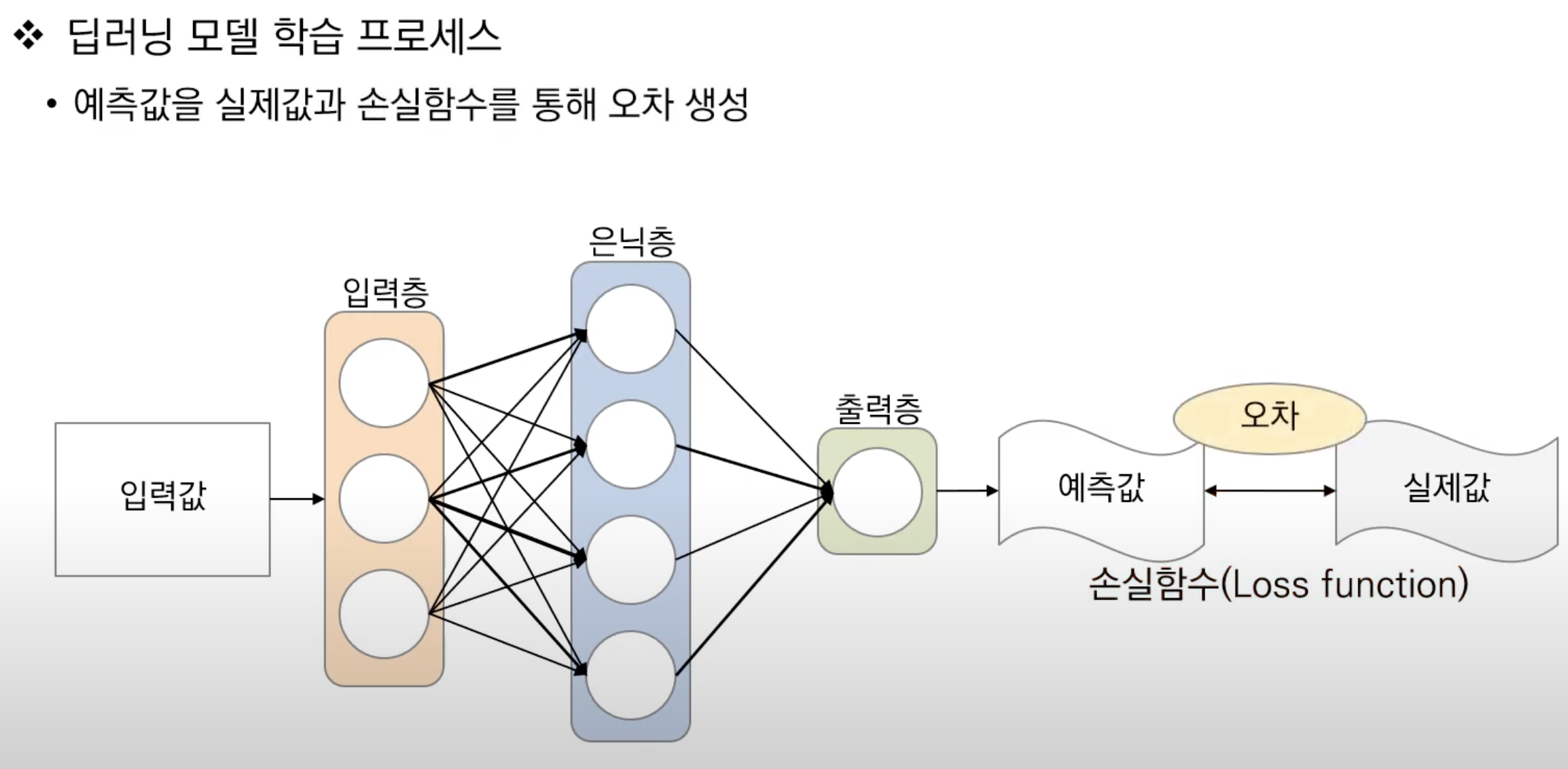
📂 손실함수
- 손실함수(Loss function)는 딥러닝 모델을 학습할 때 정답값과 예측값의 오차를 계산해주는 함수이다.
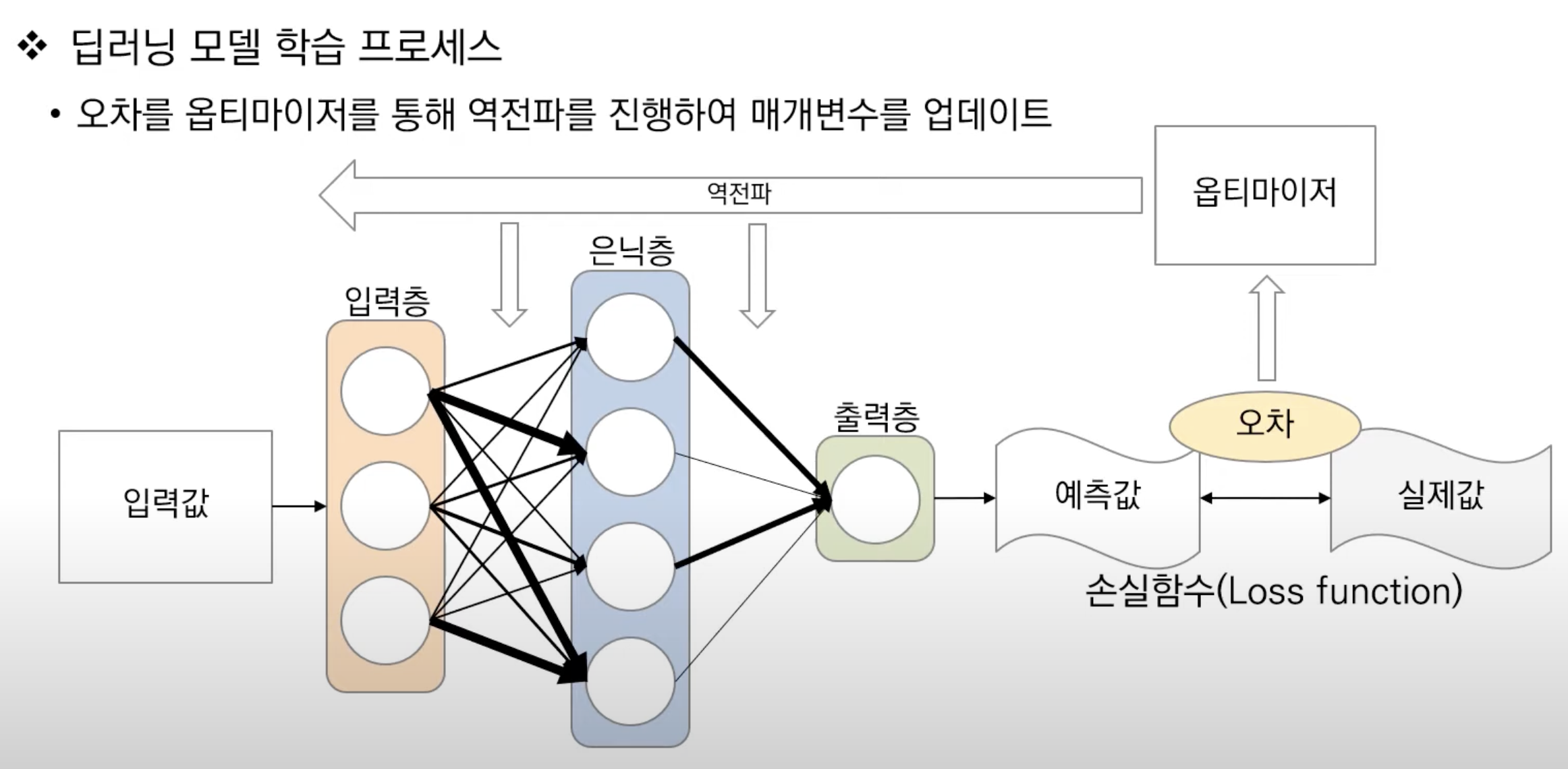
이미지 출처 | 고려대학교 DMQA 연구실
➡️ 신경망 모델을 통과하고, 활성화 함수를 통과해서 최종적인 결과값이 산출되었음.
➡️ 그러나 여기까지의 과정에서 임의의 가중치를 갖는 신경망 모델이 좋은 값을 낼 수 없음
➡️ 그래서 여기서부터 가중치를 적절하게 조정하기 위한 학습이 필요함
⭐️ 학습의 목표
- ML이 예측을 잘해서, 예측값과 실제값 간의 오차를 최소화하는 것
- 데이터 종류(분류/회귀) 등에 따라, 손실함수를 정의하는 방식에 따라 해결하고자 하는 문제 방식이 달라짐
Loss Function(손실함수)=Objective Function(목적함수)=Cost Function(비용 함수)
📂 MSE
🔗 MSE 개념과 수식
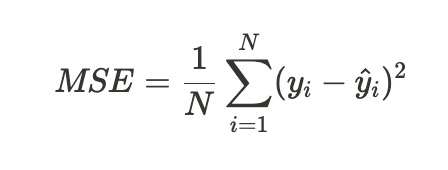
🔗 MSE 코드 예제: 키와 몸무게 회귀 분석
가상의 height와 weight 데이터에 대해 가장 잘 예측할 수 있는 회귀선을 구하기
(1) Dataset 정의
import torch
import matplotlib.pyplot as plt
# 데이터셋 정의
height = torch.tensor([152.4, 157.5, 160.0, 165.1, 172.7, 177.8, 185.4, 190.5, 195.6, 203.2], dtype=torch.float32) # cm 단위
weight = torch.tensor([50.0, 54.4, 56.7, 59.0, 63.5, 68.0, 72.6, 77.1, 81.6, 90.7], dtype=torch.float32) # kg 단위
# 모델 정의
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
#1개의 특성(키)을 입력 받아 1개의 특성(몸무게)을 산출하기 때문에 torch.nn.Linear(1, 1)입니다.
def forward(self, x):
return self.linear(x)
model = LinearModel()(2) 손실함수와 옵티마이저 정의
- MSE 손실함수를 다음과 같이 쉽게 불러오기
# 손실 함수와 옵티마이저
criterion = torch.nn.MSELoss() # 여기가 바로 MSELoss를 정의한 부분입니다.
optimizer = torch.optim.Adam(model.parameters(), lr=0.1) #(3) 모델 학습 코드
# 학습 루프
for epoch in range(10000):
model.train()
optimizer.zero_grad()
# 순전파
weight_pred = model(height.view(-1, 1))
# 손실 계산
loss = criterion(weight_pred, weight.view(-1, 1))
# 역전파
loss.backward()
optimizer.step()
if (epoch+1) % 1000 == 0:
print('Epoch:', epoch+1, 'Loss:', loss.item())
>>> ...
>>> Epoch: 10000 Loss: 1.8617804050445557(4) 데이터 포인트와 회귀선 표시
# 그래프 표시
plt.scatter(height.numpy(), weight.numpy(), color='blue', label='Original Data')
plt.plot(height.numpy(), model(height.view(-1, 1)).detach().numpy(), color='red', label='Fitted Line')
plt.title('Linear Regression with MSELoss')
plt.xlabel('Height (cm)')
plt.ylabel('Weight (kg)')
plt.legend()
plt.show()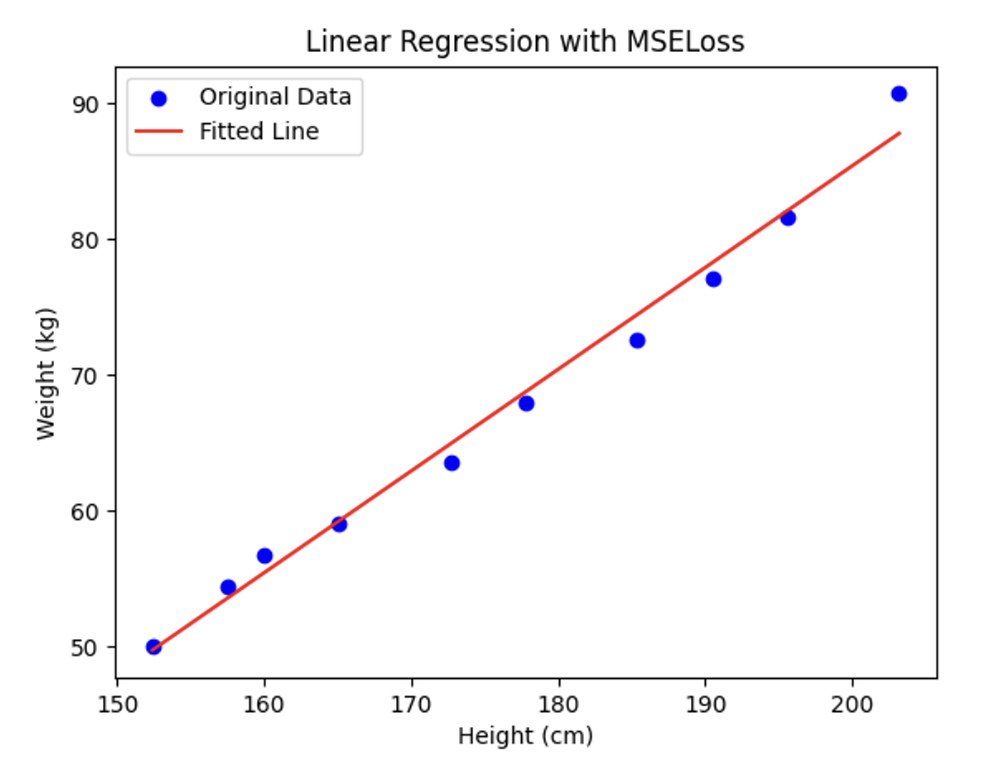
📂 Cross Entropy
- Cross Entropy는 범주형 데이터의 다중 클래스 분류 문제에 주로 활용됨
- 예측값은 일반적으로 확률값으로 나타내고, 실제값은 주로 One-hot 인코딩된 형태로 나타냄
크로스 엔트로피는 한마디로 하면 ‘예측과 달라서 생기는 깜놀도(즉 정보량)’라고 할 수 있다.
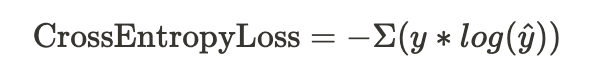
⤬ 크로스 엔트로피: 모델에서 예측한 확률값이 실제값과 비교했을 때 틀릴 수 있는 정보량
➡️ 값이 작을수록 예측 잘함
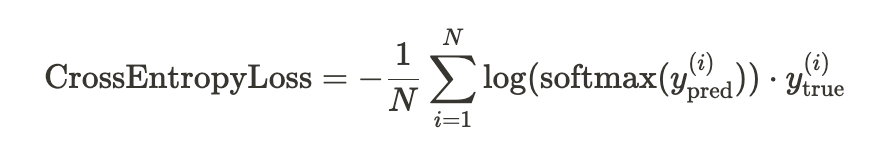
import torch
import torch.nn.functional as F
# 크로스 엔트로피 손실함수 정의
def cross_entropy_loss(y_pred, y_true):
# y_pred에 log softmax를 적용하여 log 확률을 얻습니다.
log_probs = F.log_softmax(y_pred, dim=1)
# true 레이블에 해당하는 log 확률을 수집합니다.
true_log_probs = torch.gather(log_probs, 1, y_true.unsqueeze(1))
# true log 확률의 음의 평균을 계산합니다.
loss = -torch.mean(true_log_probs)
return loss🔗 Cross Entropy 코드 예제: MNIST 데이터
(1) 모델 정의
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 장치 설정 (CPU 또는 GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 모델 정의
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc = nn.Linear(784, 10) # 28 * 28
def forward(self, x):
x = x.view(x.size(0), -1) # 입력 이미지 펼치기
# x.size(0)은 배치 사이즈를 의미합니다. 그외의 차원은 1차원으로 평탄화한다는 의미입니다.
x = self.fc(x)
return x(2) MNIST Dataset 로드
- 효율적인 계산을 위해 텐서로 변환한 뒤 정규화 작업을 거침
# MNIST 데이터셋 로드
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root="./data", train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root="./data", train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)(3) MNIST 데이터 원본 확인
import matplotlib.pyplot as plt
# MNIST 훈련 데이터에서 배치 이미지 가지고 오기
images, labels = next(iter(train_loader))
# 원본 이미지 출력하기
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(8, 8))
for i, ax in enumerate(axes.flatten()):
ax.imshow(images[i].squeeze(), cmap='gray')
ax.axis('off')
ax.set_title(f"Label: {labels[i]}")
plt.tight_layout()
plt.show()(4) 모델 인스턴스 생성 | 손실 함수 정의 | 옵티마이저 정의
- 다중분류문제 ->
nn.CrossEntropyLoss() - 확률적 경사하강법 ->
SGD활용
# 모델 인스턴스 생성
model = MyModel().to(device)
# 손실 함수 정의
criterion = nn.CrossEntropyLoss()
# 손글씨 이미지에 쓰인 10개의 숫자를 예측하는 문제이므로 '다중 분류 문제'입니다.
# 옵티마이저 정의
optimizer = optim.SGD(model.parameters(), lr=0.01)(5) 모델 훈련
# 훈련 반복
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 순방향 전파
outputs = model(inputs)
loss = criterion(outputs, labels)
# 역방향 전파 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
# 에폭의 평균 손실 계산
epoch_loss = running_loss / len(train_loader)
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}")(6) 모델 평가
# 평가
model.eval()
total_correct = 0
total_samples = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total_samples += labels.size(0)
total_correct += (predicted == labels).sum().item()
accuracy = total_correct / total_samples
print(f"테스트 정확도: {accuracy:.2%}")
>>> 테스트 정확도: 91.80%🔗 Binary Cross Entropy
🪻 바이너리 크로스 엔트로피: 이진 분류 문제에 활용되는 엔트로피
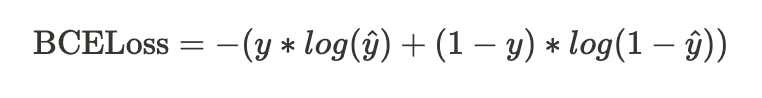
🪻 실제 손실함수로 쓰이는 공식과 코드
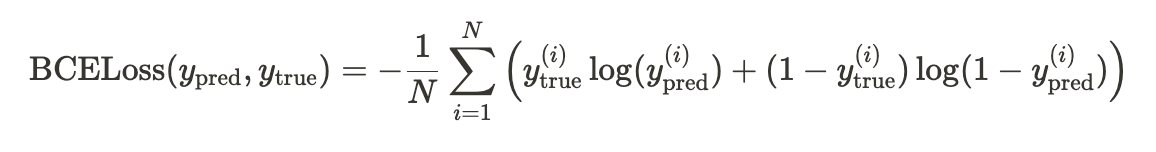
import torch
import torch.nn.functional as F
def binary_cross_entropy_loss(y_pred, y_true):
loss = -torch.mean(y_true * torch.log(y_pred) + (1 - y_true) * torch.log(1 - y_pred))
return loss
🔗 KL-Divergence
- 쿨백-라이블러(Kullback-Leibler) 발산을 줄여서 쓴 말인데, 쿨백과 라이블러 모두 사람이름인 것으로 확인
- divergence ->
차이라는 뜻으로 해석 ='두 확률 분포를 비교'
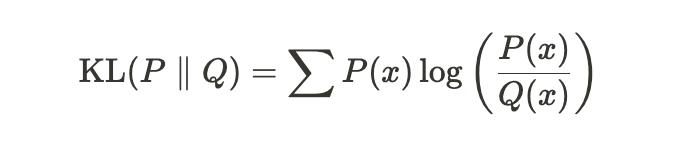
import torch
import torch.nn.functional as F
def kl_divergence_loss(P, Q):
return torch.sum(P * torch.log(P / Q))[출처 | 딥다이브 Code.zip 매거진]

@fragrance_0의 개발로그