📂 컴퓨터 비전 분야 소개
컴퓨터 비전은 주로 이미지나 영상을 다루는 인공지능의 한 분야로서 컴퓨터가 시각적인 세계를 해석하고 이해하는 방법을 학습하는 분야입니다. 컴퓨터 비전은 일반적으로 다음과 같은 작업들이 컴퓨터 비전 비전 분야로 다뤄집니다.
- 이미지 분류(Image Classification)
- 객체 탐지(Object Detection)
- 이미지 분할(Image Segmentation)
- 이미지 생성(Image Generation)
- 자세 추정(Pose Estimation)
큰 맥락에서 이미지의 특성을 파악하고 그 특성을 토대로 각 목적에 맞는 작업이 이루어집니다. 대표적으로 이미지 분류, 객체 탐지, 이미지 생성 모델에 대해 알아보도록 하겠습니다.
🔗 이미지분류 : CNN
컴퓨터 비전은 1960년대부터 컴퓨터 과학의 한 분야로 연구됐는데요. 인공지능의 한 분야로서 성장하게 된 배경에 결정적인 역할을 한 모델이 있습니다. 바로, 이미지 인식(Image Recognition)을 위한 CNN입니다.
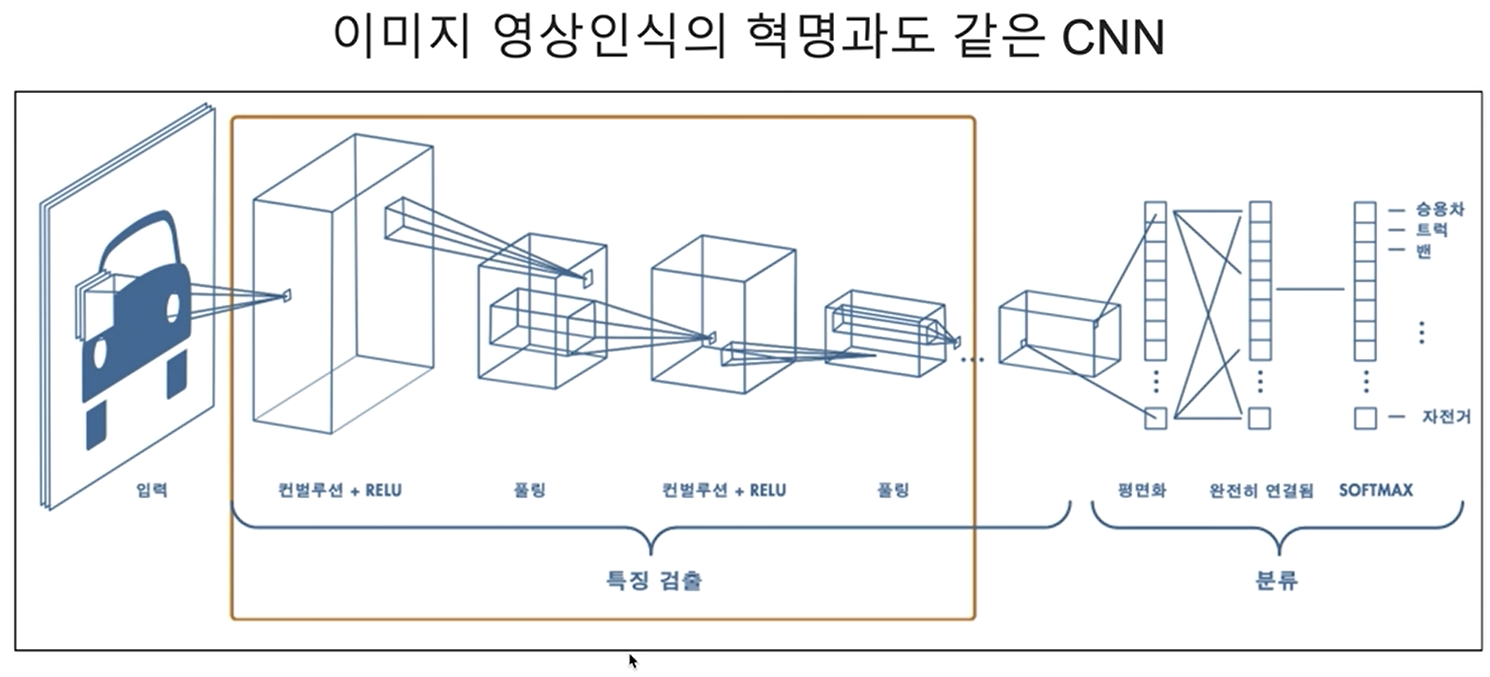
☁️ CNN의 핵심
- 이미지의 공간 구조를 보존하는 능력
- 기존의 다층 퍼셉트론 구조와는 달리 CNN은 이미지의 픽셀 형식을 유지하면서, 다양한 변동 불변성(Translation Invariance)을 가진 패턴을 인식
- 이는 이미지 내 객체의 특징과 위치가 중요한 작업에 특히 효과적
🤔 Translation Invariance
특정 공간 위치와 관계없이 이미지 내의 패턴이나 특징을 인식하는 능력을 의미합니다.CNN은 지역적인 특징(패턴)을 파악해 나가며 전체적으로 일반화합니다.
이미지 전체 영역을 슬라이딩하며 부분적인 특성을 파악하게 되면, 이미지 내에서 그 특징이 이동하더라도 해당 특징을 동일한 것으로 식별하고 추출할 수 있습니다.
◾️ ResNet
🪻 AlexNet (2012)
2012년에 열린 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)라는 이미지 분류 및 객체 검출 대회에서 Alex Krizhevsky가 설계한 AlexNet이 우승했습니다.
AlexNet은 심층 합성곱 신경망으로 기존의 모든 전통적인 방법보다 뛰어난 성능을 보이며 딥러닝 시대의 시작을 알렸습니다.
🪻 ResNet (2015)
이후 매년 ILSVRC 대회가 열릴 때마다 새로운 CNN 아키텍처가 제시되었는데요. 그중 꼭 기억해야 할 모델 중 하나가 제시된 ResNet(2015)입니다.
이전까지는 합성곱 신경망을 여러 개 쌓아 깊은 신경망을 구성하여 성능을 끌어올렸었는데 어느 순간부터 층을 쌓아도 성능이 감소하기 시작했습니다.
신경망이 깊어지면서 과적합 문제가 발생하며 성능이 하락 한 것입니다. 이 문제를 해결하고자 연구자들은 ResNet 아키텍처를 제안했습니다.
ResNet은 잔차 학습의 개념을 도입하여 수백 개의 층을 구성하여 신경망 훈련을 진행할 수 있었습니다. 아래는 잔차 블록의 식과 구조도입니다.
부분은 아래 구조도에서 더 자세하게 확인해볼 수 있습니다.
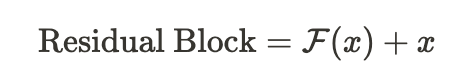

🔗 객체탐지: R-CNN & YOLO
◾️ 객체탐지
- 이미지 내에서 여러 객체를 찾아내고 식별하는 작업
- 이미지 인식은 이미지 전체를 분류하는 작업이지만, 객체 탐지는 한 단계 더 나아간 것
- 객체가 무엇인지, 그리고 이미지에서 어디에 있는지 파악해야 하기 때문에 일반적인 이미지 인식보다 복잡함
- 객체 탐지 모델
→2-Stage 방식: 물체의 위치를 찾은 뒤 분류
→1-Stage 방식: 위치 탐색, 분류를 한번에 해결
◾️ R-CNN (2013)
- 초기 아이디어는
2-Stage 방식 - 이 방식의 효시라고 할 수 있는
R-CNN은 CNN을 기반으로 객체 탐지 - ‘R': 지역(Region) 의미
- 먼저
Selective Search알고리즘을 통해 이미지에서 약 2천 개의 잠재적인Bounding Box(Region Proposal)를 생성함 - 그 후, 해당 지역에 대해
CNN을 통해 내부의 객체를 식별함
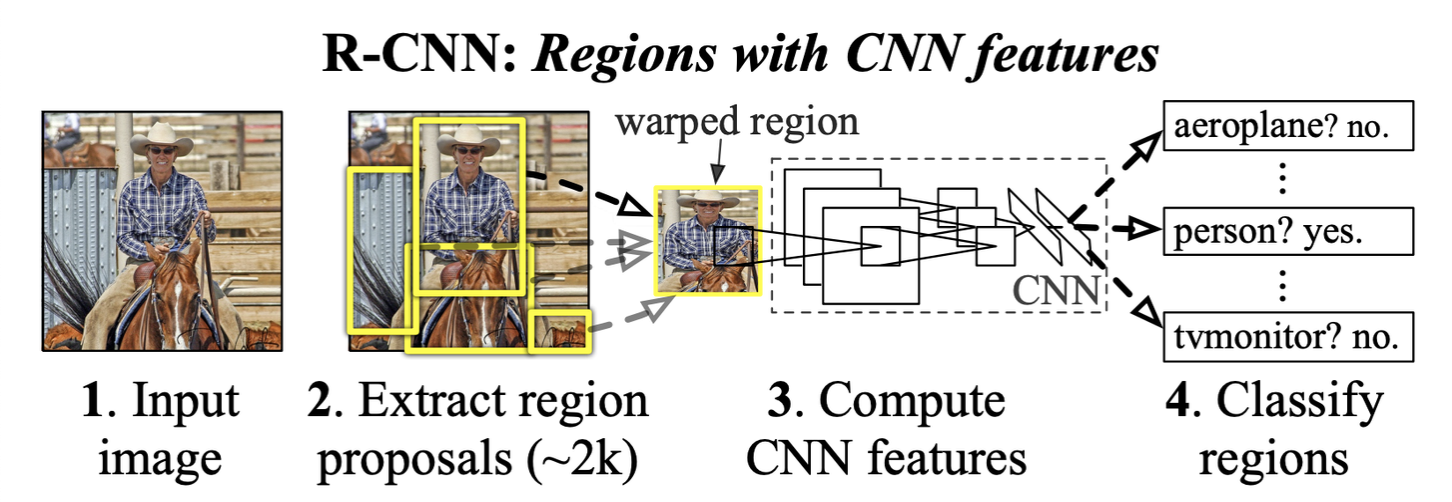
출처: Rich feature hierarchies for accurate object detection and semantic segmentation (Girshick, 2013)
R-CNN은Fast R-CNN과Faster R-CNN으로 진화하면서 모델의 속도와 효율성이 개선되었음- 특히
Faster R-CNN은 전체 이미지 합성곱 특징을 객체 탐지 네트워크와 공유함으로써 거의 비용이 들지 않는 지역 제안을 가능하게 하는Region Proposal Network(RPN)을 도입함.
◾️ YOLO (2015)
- YOLO는
실시간(Real-time)객체 탐지 가능 - 실시간 객체 탐지는 속도와 정확성을 동시에 필요로 함
- 속도와 정확성은 Trade-off 관계에 있기 때문에 적절한 균형점을 찾는 것이 중요
- 기존 2-Stage 모델에서 활용하던
RPN없이, 입력 이미지를그리드 셀(Grid Cell)로 나누고 곧바로 Bounding Box와 클래스 확률을 예측함.
- 이 Grid Cell은 다양한 종횡비를 갖는 Anchor Box를 가짐
7 × 7 Grid에서 각각 2개씩 Anchor Box를 사용한다면 총 98개의 Anchor Box가 있는 것임
YOLO의 특징 중 하나는 다양한 크기의 객체를 동시에 탐지할 수 있다는 것
예를 들어, 작은 강아지를 품에 안고 있는 사람 이미지가 있다면 한 Grid Cell에서는 큰 객체인 사람을 탐지하고 다른 Grid Cell에서는 작은 강아지를 탐지하는 식입니다.
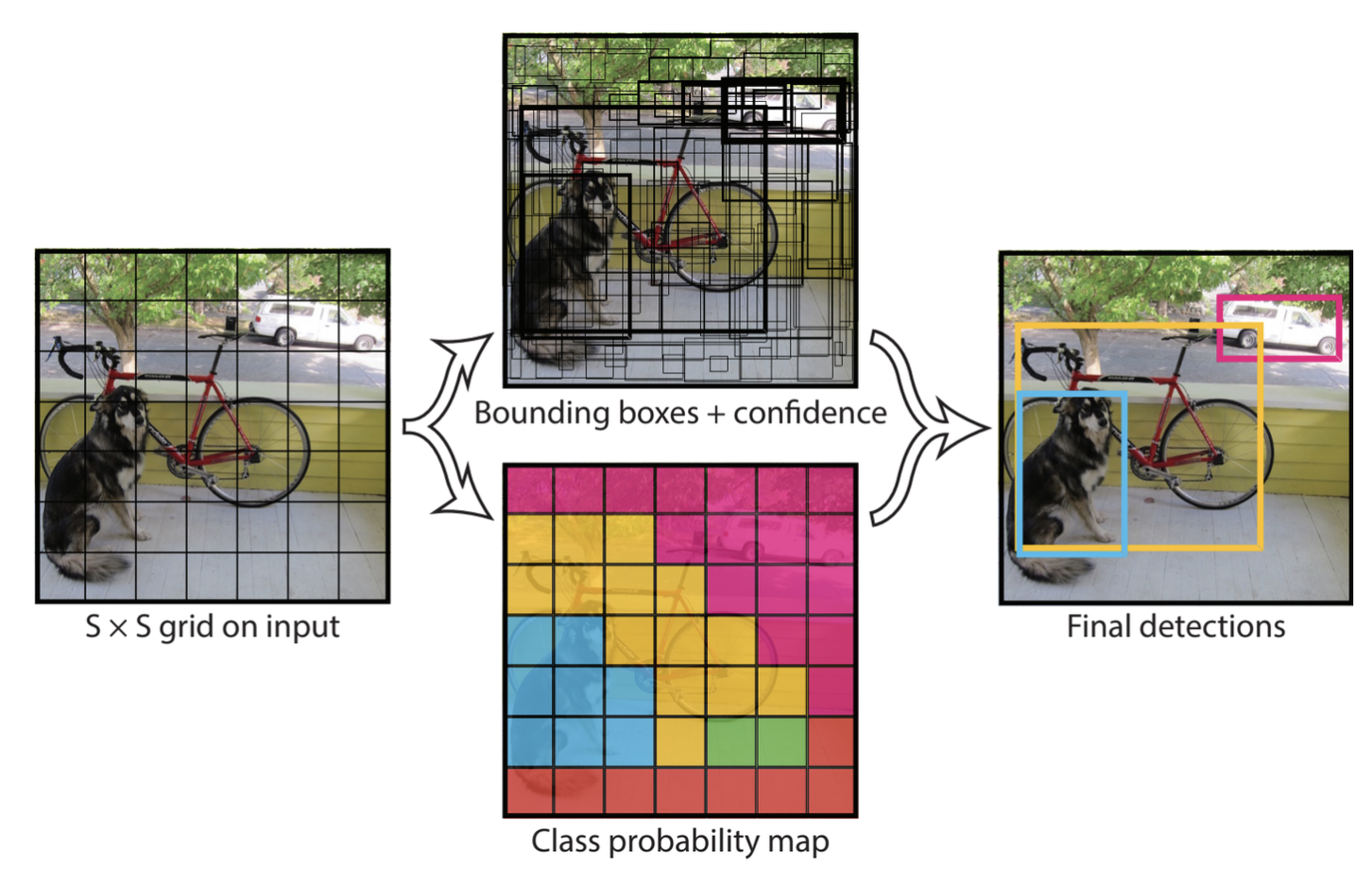
출처: You Only Look Once: Unified, Real-Time Object Detection (Redmon, 2015)
🔗 이미지 생성: GAN & Diffusion
이미지 생성은 최근 Text-to-Image 태스크와 함께 매우 전망 있는 연구 분야로 부상하고 있습니다. 이미지 생성에 대표적인 2가지 모델이 바로 GAN과 Diffusion입니다.
◾️ GAN (2014)
GAN(Generative Adversarial Networks)은 2014년에 등장한 모델로 이미지 생성 분야를 혁신적으로 바꿔놓았습니다. GAN은 주로 두 가지 주요 구성요소인 생성자와 식별자로 구성됩니다.
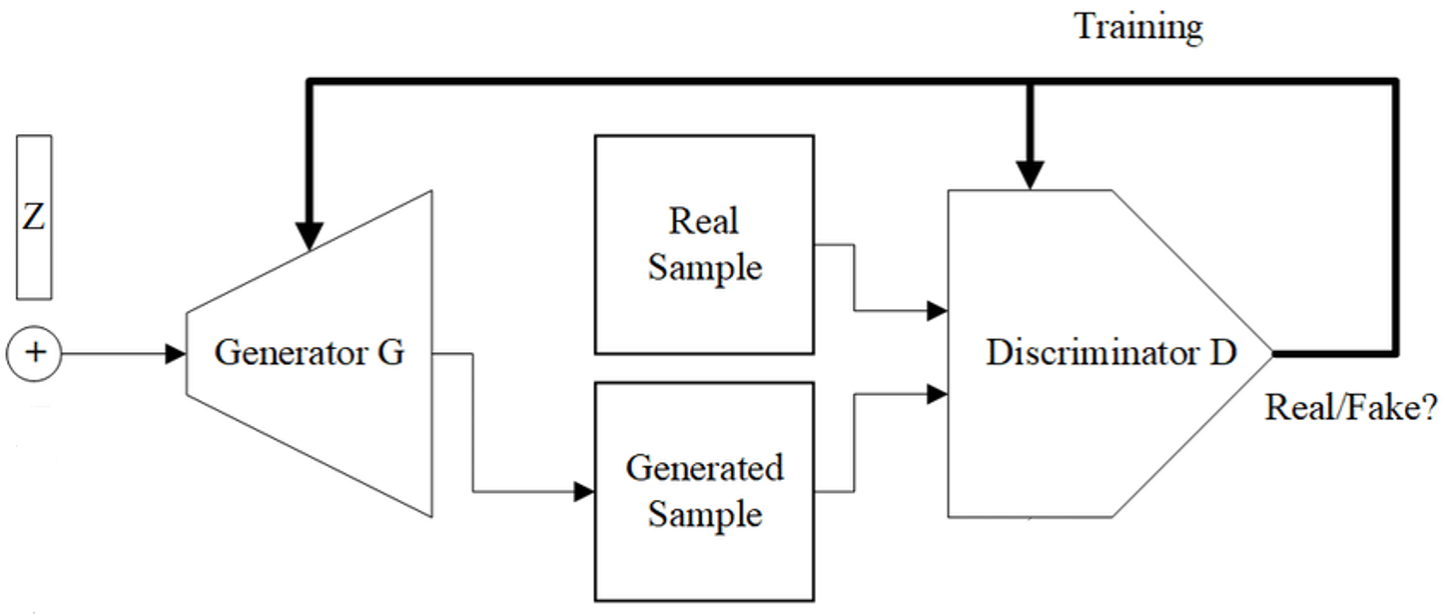
출처: 위키피디아 커먼즈
-
생성자(Generator)
- 생성자는 훈련 데이터셋에서 실제 이미지와 유사한 새로운 이미지를 생성
- 일반적으로
가우시안 분포(Gaussian Distribution)와 같은 일반적인 분포에서 임의의 노이즈를 입력받음 - 이 임의의 노이즈에서부터 새로운 이미지를 생성해 감
-
식별자(Discriminator)
- 식별자는 훈련 데이터셋에서 입력 받은 실제 이미지와 생성자가 생성한 가짜 이미지를 구별하는 역할을 함
- 식별자는 사실과 가짜를 구분하는
이진 분류(Binary Classification)문제를 해결해가는 것
생성자와 식별자는 생성자가 식별자를 속이려고 하고, 식별자가 실제와 가짜를 정확하게 분류하려고 하는 적대적인(Adversarial) 프레임워크에서 함께 훈련됩니다.
시간이 지남에 따라 생성자는 더 실제같은 이미지를 생성할 수 있게 됩니다.
- 2014년 DCGAN(Deep Convolutional GAN): 학습 과정의 안정성이 크게 개선
- 이후 CycleGAN, StarGAN, StyleGAN 등장
그중에서도 지금까지도 중요하게 활용되고 있는 모델이 바로 StyleGAN입니다. StyleGAN은 하나의 이미지에 특정 스타일의 이미지를 더욱 세밀하게 생성하는 Style Transfer 분야에 자주 활용됩니다.
◾️ Diffusion

- Diffusion 모델은 이미지 생성을 위한 새로운 접근법으로, 유망한 결과를 보임
- Diffusion 모델 또한 임의 노이즈로부터 출발하여 점진적으로 이미지 특성을 나타내는 데이터 분포로 변환됨
- 이 과정은
순방향 전파(Forward Process)과정과역방향 전파(Inverse Process)로 이루어짐
1. 순방향 전파
❐ 원본 이미지 데이터에 점진적으로 노이즈가 추가하는 과정
❐ 순방향 전파는 여러 단계로 나뉘는데 직전에 입력된 데이터에 의존하는 마르코프 체인(Markov Chain)을 방식으로 연산2. 역방향 전파
❐ 노이즈를 점진적으로 제거하고 원래 데이터를 재구성하는 방법을 학습 (앞서 노이즈를 추가하는 과정과 반대로) -> 이미지 생성 능력 학습
❐ 간단한 사전 확률 분포에서 시작하여 역방향 전파 과정을 실행하면 새로운 이미지 생성 가능Diffusion 모델의 초기 버전은 생성 시간이 오래 걸리는 문제가 있었지만, 2020년 이후 Denoising Diffusion Probabilistic Models(DDPM) 모델이 이 문제를 개선했습니다.
최근에는 정교한 생성 능력으로 지금까지도 활발하게 활용되고 있습니다.
[출처 | 딥다이브 Code.zip 매거진]
