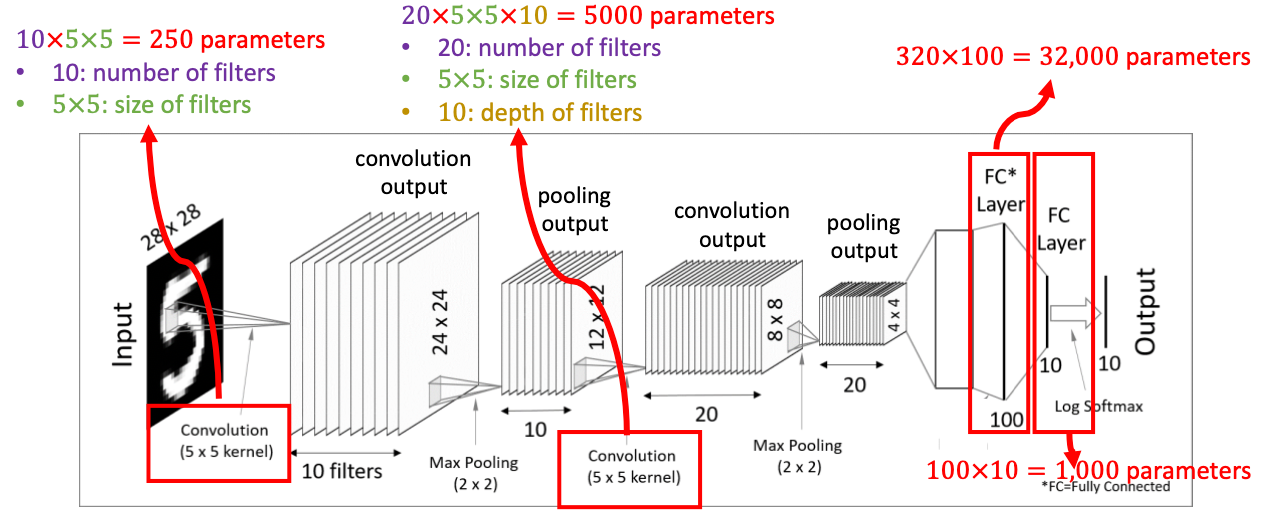
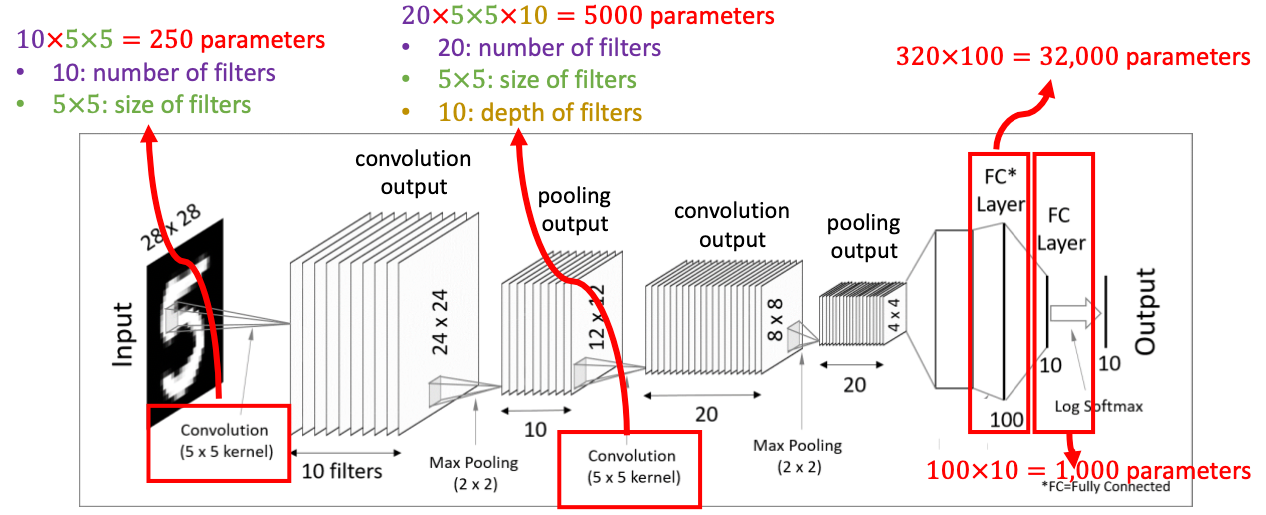
이번에는 MNIST 숫자 손글씨 이미지 분류 실습을 진행해보려고 한다.
기본이 되는 데이터셋과 분류방법이므로, cnn 과정에 대해서 공부하는 느낌으로 읽으면 될 것 같다.
마지막에는 특성맵을 시각화 하는 과정도 포함한다.
CNN에서 특성 맵은 입력 이미지에 대한 특정한 특징을 감지하기 위해 합성곱 연산을 통과한 결과를 말한다. 각 특성 맵은 하나의 필터(커널)에 해당하며, 이 필터는 입력 데이터의 작은 부분에 대해 합성곱 연산을 수행하여 특징을 추출한다.
📂 CNN 모델 직접 구현하기
📎 임의의 이미지 설정
- 이미지가 어떻게 입력되는지 알기 위해 랜덤한 이미지를 설정함
- 컬러이미지는 3채널로 이루어짐
- 28x28사이즈의 텐서를 만들어 이미지 출력해보기
# PyTorch 불러오기
import torch
# 랜덤 이미지 생성
img_tensor = torch.rand(3, 28, 28)
# 랜덤 이미지에 컬러 입히기
img_tensor = torch.round(img_tensor * 255) # 이미지 값은 0부터 255를 갖습니다.
print(img_tensor)
- 이미지를 출력하기 위해
PIL의Image함수를 불러옴 - 텐서를 이미지로 변환해주는
transform함수도 불러옴 - PIL 객체로 변환하는 객체를 생성하고, 앞서 만든 텐서를 입력하면, 형상을 알기 어려운 노이즈 이미지가 출력됨
- 임의의 값으로 이미지를 생성하게 되면, 당연히 노이즈가 출력됨
from PIL import Image
from torchvision import transforms
tensor_to_image = transforms.ToPILImage()
img = tensor_to_image(img_tensor); img

📎 임의의 가중치 설정
- 마찬가지로 랜덤한 가중치 설정
- 이미 내장된 CNN 레이어와 동일한 값을 가질 수 있도록 우선 통과시켜보기
# PyTorch 내의 nn.Conv2d 레이어에 제작한 이미지 통과 시키기
layer = torch.nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 5, stride = 1, padding = 1)
output = layer(img_tensor)
output.size()
>>> torch.Size([6, 26, 26])- 입력 채널이 3개에서 6개로 늘어남
- 커널 사이즈가 5, 보폭이 1일 때, 28에서 26으로 줄어들었음
📂 CNN 모델
📎 제로 패딩(Zero-Padding)
- 이미지 앞에 하나의 차원을 더 추가하는 것
- 이부분은 배치 사이즈에 해당함
- CNN모델이 이미지를 처리하는 것과 동일한 형태로 맞춰준 것
# 가상의 이미지 데이터 생성
img = torch.round(torch.rand(10,3,28,28) * 255)
- 이미지에 패딩을 더하는 함수 -> Padding 함수 구현
- pytorch의 계산 특징을 이용해 0 값을 갖는 행렬을 하나 생성한 뒤, 입력값을 가운데에 붙여 넣는 방법으로 제로 패딩을 구현
# Padding 함수 구현
def add_padding(inputs):
inputs.to(device)
batch_size, channel, height, width = inputs.size()
zero_padding = torch.zeros(batch_size, channel, height+2, width+2)
zero_padding[:, :, 1:-1, 1:-1] = inputs
return zero_padding
# Padding 적용하기
padded_img = add_padding(img)
print(padded_img[0])
📎 특성맵 사이즈 계산
특성맵의 사이즈를 계산해주는 공식
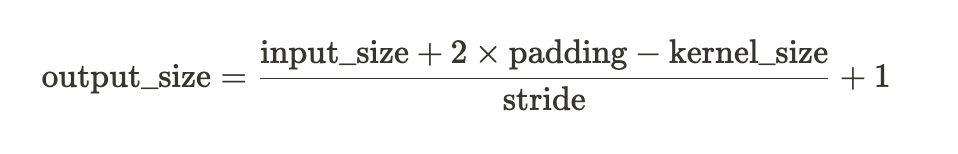
특성맵 = 합성곱층을 입력 이미지와 필터를 연산해서 얻은 결과임
# 특성맵의 사이즈 계산 함수
def cal_output_size(input_size, kernel_size, stride, padding = True):
return (input_size + 2 * padding - kernel_size) // stride + 1
📎 커널 연산
- 앞서 일부 이미지 영역에서만 커널을 구했었음
- 이번에는 반복문을 통해 하나의 특성맵을 모두 구현
# 임의의 커널 생성
out_features = 6
in_features = 3
kernel = torch.rand(out_features, in_features, kernel_size, kernel_size, requires_grad = True)
반복문으로 커널이 이미지를 슬라이딩하도록 만들고, 각각의 값을 특성맵에 저장
# 특성맵에 저장하기
feature_map = torch.Tensor(batch_size, out_features, feature_map_size, feature_map_size)
for i in range(feature_map_size):
for j in range(feature_map_size):
region = padded_img[:,:, i * stride: i * stride + kernel_size, j * stride : j * stride + kernel_size]
region = region.reshape(batch_size, -1)
feature_map[:, :, i, j] = torch.matmul(region, kernel.view(out_features, -1).t())
📎 직접 구현한 CNN 클래스 생성
self.kernel과self.bias를 PyTorch에서 제공하는 파라미터로 변경
class CustomCNN(torch.nn.Module):
def __init__(self, in_features, out_features, kernel_size, stride, padding):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.kernel = torch.nn.Parameter(torch.rand(self.out_features, self.in_features, self.kernel_size, self.kernel_size, requires_grad = True)).to(device)
self.bias = torch.nn.Parameter(torch.rand(self.out_features, requires_grad = True)).to(device)
def forward(self, inputs):
batch_size, in_channels, height, width = inputs.shape
out_channels, in_channels, kernel_height, kernel_width = self.kernel.shape
output_height = cal_output_size(height, kernel_height, self.stride, self.padding)
output_width = cal_output_size(width, kernel_width, self.stride, self.padding)
if self.padding:
inputs = add_padding(inputs)
else:
pass
inputs = inputs.to(device)
self.feature_map = torch.Tensor(batch_size, out_channels, output_height, output_width).to(device)
for i in range(output_height):
for j in range(output_width):
self.region = inputs[:,
:,
i * self.stride : i * self.stride + kernel_height,
j * self.stride : j * self.stride + kernel_width]
self.region = self.region.reshape(batch_size, -1)
self.feature_map[:, :, i, j] = torch.matmul(self.region, self.kernel.reshape(self.out_features, -1).t())
self.feature_map += self.bias.view(1,-1,1,1)
return self.feature_map
📂 MNIST 숫자 손글씨 이미지 분류
📎 데이터셋 불러오기
- 런타임 유형을 GPU로 변경하여 처리 장치를
‘cuda’로 설정함 - 그리고 재생산 가능하도록 만들기 위해 임의값을 갖는 모든 영역의 시드를 고정
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import random
random.seed(319)
torch.manual_seed(319)
if device == 'cuda':
torch.cuda.manual_seed_all(319)
하이퍼파라미터 설정 및 데이터 다운로드
# 하이퍼파라미터 설정
training_epochs = 3
batch_size = 100
learning_rate = 0.001# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
# 데이터 로더
data_loader = DataLoader(dataset=mnist_train,
batch_size= batch_size, # 배치 크기는 100
shuffle=True,
drop_last=True)
📎 모델 설정
- 실제 CNN 모델에는 하나의 합성곱 계층이 아닌, 다양한 계층이 추가됨
- 모델 클래스를 새롭게 만들어 활성화함수
ReLU와MacPooling을 추가함 - MNIST는 흑백이기때문에 입력 채널은 1로 설정함
class CNNwithMaxPooling(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer1 = CustomCNN(1, 32, kernel_size = 3, stride = 1, padding = True).to(device)
self.relu1 = torch.nn.ReLU()
self.maxpooling1 = torch.nn.MaxPool2d(2)
self.dropout1 = torch.nn.Dropout(0.2)
self.layer2 = CustomCNN(32, 64, kernel_size = 3, stride = 1, padding = True).to(device)
self.relu2 = torch.nn.ReLU()
self.maxpooling2 = torch.nn.MaxPool2d(2)
self.dropout2 = torch.nn.Dropout(0.2)
self.fc = torch.nn.Linear(7 * 7 * 64 , 10, bias = True)
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x):
out = self.dropout1(self.maxpooling1(self.relu1(self.layer1(x))))
out = self.dropout2(self.maxpooling2(self.relu2(self.layer2(out))))
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
📎 모델 훈련
- 반복문을 활용하여 역전파 속도가 느리기 때문에 훈련속도가 한번 반복할때 약 3분정도로 느림
model = CNNwithMaxPooling().to(device)
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
from tqdm.auto import tqdm
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in tqdm(data_loader): # 미니 배치 단위로 꺼내옵니다. X는 미니 배치, Y는 레이블.
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
>>>
[Epoch: 1] cost = 114.13855
[Epoch: 2] cost = 67.8441467
[Epoch: 3] cost = 64.6813049
📎 모델 평가
- 정확도가 다음과 같이 77퍼센트가 나오는 것으로 보임
- 층을 더 깊이 구성하거나, 다른 활성화 함수를 사용하는 등의 조치가 필요해보임
with torch.no_grad():
X_test = mnist_test.data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.targets.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
>>> Accuracy: 0.7749999761581421
📂 특성맵 시각화
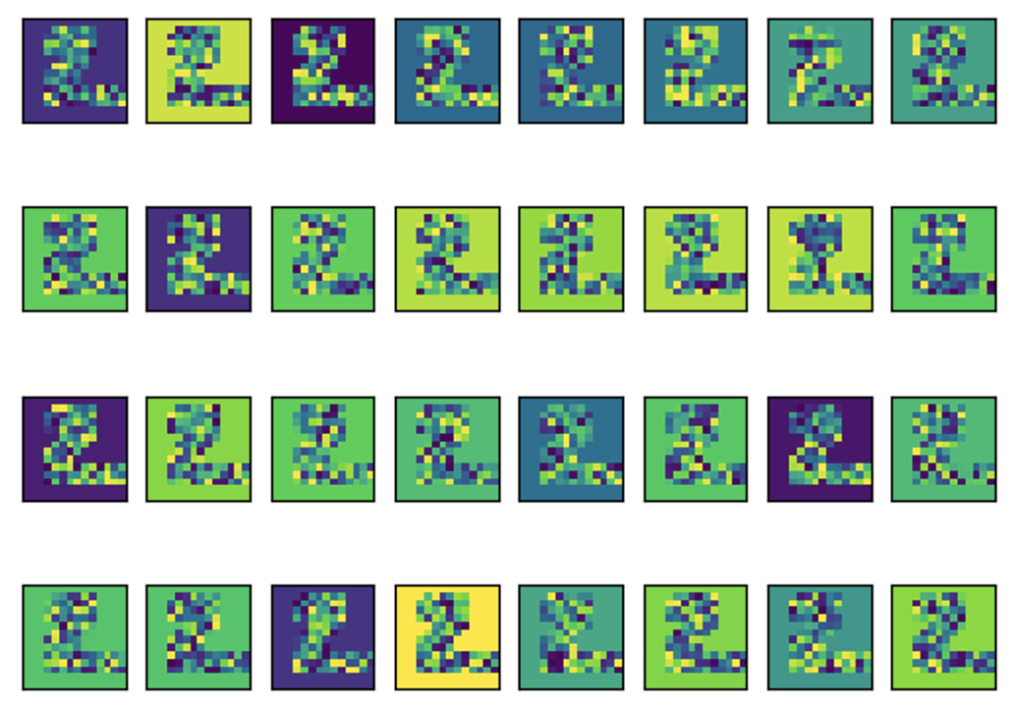
숫자 2에 대한 특성맵을 시각화한 결과
- 한 개의 이미지에 대해 1개의 레이어층을 통과한 경우, 다음처럼 32개의 특성맵이 그려짐을 알 수 있음
- 모든 이미지가 2의 모습을 띄지만 각각의 값은 차이가 많이 나는 것처럼 보임
image_set = model.layer1(X_test[:5])
image_set = model.relu1(image_set)
image_set = model.maxpooling1(image_set)
import matplotlib.pyplot as plt
fig = plt.figure()
rows = 4
cols = 8
for n in range(rows * cols):
img = image_set[1][n].cpu().detach()
img = tensor_to_image(img)
ax = fig.add_subplot(rows, cols, n + 1)
ax.grid(False)
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(img)
n += 1
특성맵은 결국 이미지의 특성을 포착한 집합체입니다. 그래서 이 결괏값으로 XAI를 구현하기도 하고 다시 다른 모델의 입력값으로 넣어 다른 목적(생성, 탐지 등)으로 활용하기도 합니다. 단순히 모델을 구현하고 훈련시키고 테스트하는 것이 아니라 어떤 과정을 통해 구현됐는지 살펴보고 각각의 결괏값에 대한 이해와 활용 방법을 익혀 나가면서 컴퓨터 비전에 한 발 더 다가갈 수 있습니다.
[출처 | 딥다이브 Code.zip 매거진]

@fragrance_0의 개발로그