- ResNet, ‘Deep Residual Learning for Image Recognition’, 2015
0. Abstract
- 기존 모델의 문제점 [1] 레이어를 깊게 쌓을수록 train/test 에러율이 높아졌습니다. [2] 기존의 매핑인 H(x) 를 그대로 학습시켰을 때 최적화와, 학습의 수렴이 어려운 문제가 존재했습니다.
- ResNet의 핵심 설명 [1] 기존의 매핑인 H(x) 를 F(x) +x 로 식을 변환시켜 잔차 블록인 F(x) 만 학습시키는 방식을 취했습니다. [2] 배치 정규화를 통해 학습 속도 감소, 가중치 초기화에 대한 민감도를 감소 시켰습다. [3] 50 layer 이상의 레이어를 쌓을 경우 Bottleneck 구조를 취해 파라미터 연산을 줄였습니다.
- ResNet의 효과 [1] 잔차 블록을 학습함으로써 신경망이 152 레이어까지 더 깊은 층을 가지면서도, 학습 난이도나 파라미터 연산을 줄이며 오차율을 감소시킬 수 있었습니다. [2] Image classification 문제 뿐만 아니라 Object Dectection, Image Segmentation 문제 등 다양한 비전 문제에서 좋은 성능을 보였습니다.
1. Introduction
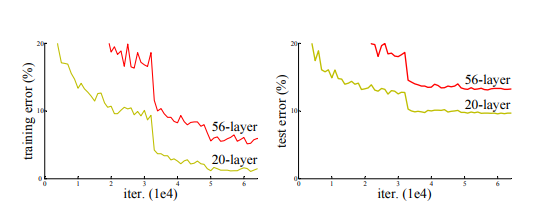
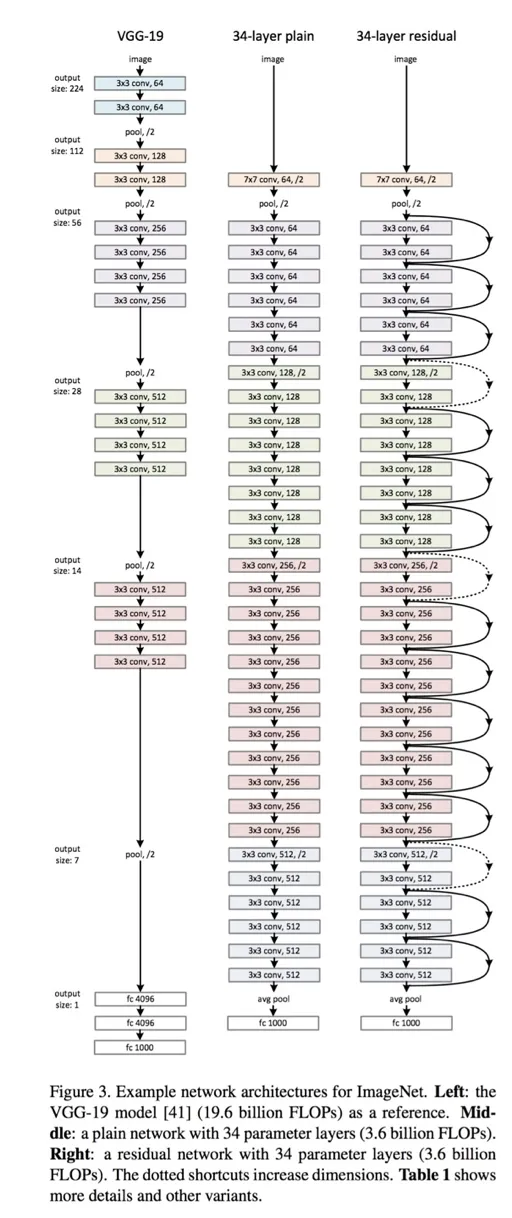
- 기존의 VGGNet 모델의 경우 layer 가 깊어질수록 train, test 셋의 에러율 모두 오히려 높아진다는 문제점이 존재했습니다.
- 이는 기울기 소실 문제 (vanishing / exploding gradient) 문제나 오버피팅의 문제는 아니였습니다.
- 논문의 저자는 이러한 오차율 증가 문제가 학습 시 그 수렴율이 기하급수적으로 낮아지는 것이 문제로 보았습니다.
- 즉, 기존의 mapping 함수였던 H(x)를 CNN layer에 그대로 넣어 최적화를 시키는 것은 난이도가 높았고 그 마저도 오히려 오차율을 높이는 결과를 가지고 왔습니다.
- ResNet 은 이러한 레이어가 깊어질수록 오차율이 오히려 높아지는 기존이 모델을 개선하고 보다 깊은 레이어가 구축된 모델을 구현하기 위해 개발되었습니다.
2. ResNet Configurations
2-1. Idea
- 기존의 합성곱 레이어에서는 합성 곱 연산인 H(x) 를 직접 layer 에 학습시키는 방식을 사용했고, 우리는 앞서 해당 방식이 최적화(optimization) 난이도가 매우 높다는 것을 파악했습다.
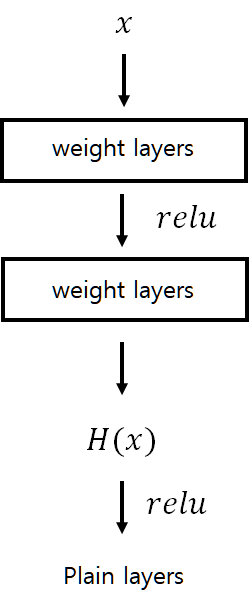
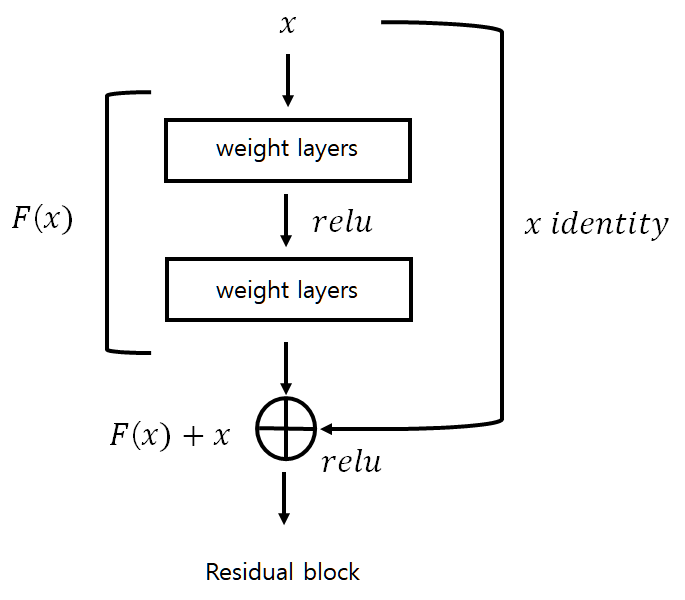
- 따라서 ResNet 에서는 합성곱 연산인 H(x) 를 곧바로 학습하는 것이 아니라, H(x) 를 다시 F(x)+x 연산으로 변환하여 잔차인 F(x) 만을 학습해 기존의 input 인 x 는 그대로 더하는 방식을 취하도록 설계했습니다.
- 기존 VGGNet 과 ResNet 의 layer 학습 과정을 정리하면 다음과 같습니다.
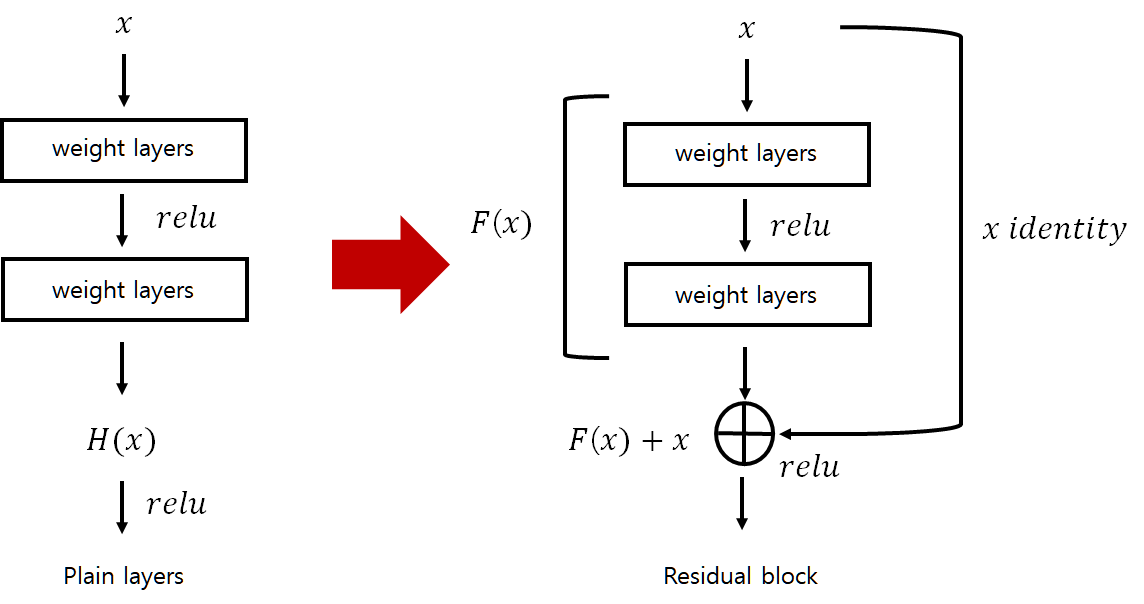
- 여기서 잔여 블록 함수 F(x) 를 수식으로 나타내면 다음과 같습니다.
- W_1은 첫번째 weight layer, W_2 는 두번째 weight layer, \delta 는 relu function 을 의미합니다.
- 이렇게 구현된 F(x) 에 대하여 i개의 weight layer 에 대해 학습시키고 이후 identity x를 추가하는 형식으로 y 값이 최적화 됩니다.
- 여기서 W_s(x)를 shortcut 이라고 부릅니다.
2-2. Configurations

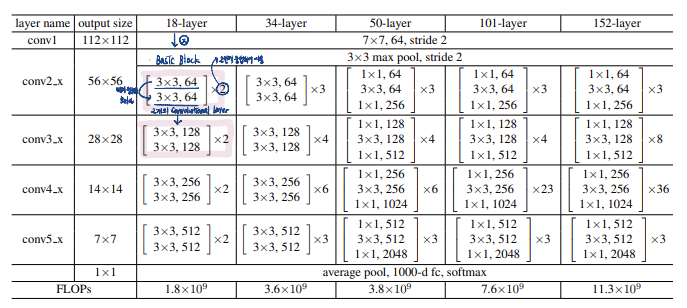
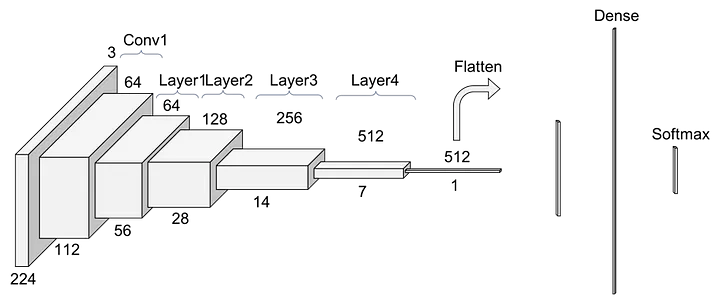
- Conv1 : convolution + batch normalization + max pooling operation
- kernel size = 7, feature map size = 64
- output size = ((224+2x3-7)/2) +1 = 112
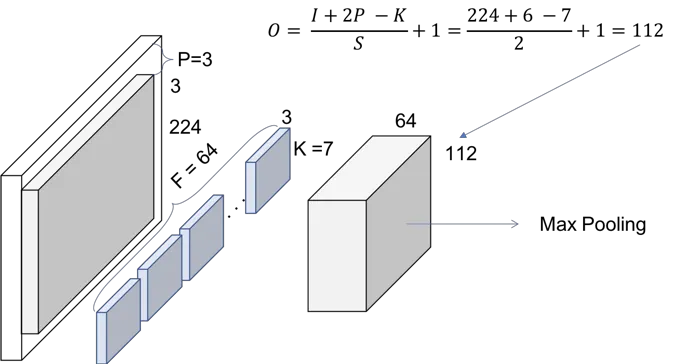
- Batch Nomalization, Max pooling (stride=2)
)
2-3. Bottleneck Block
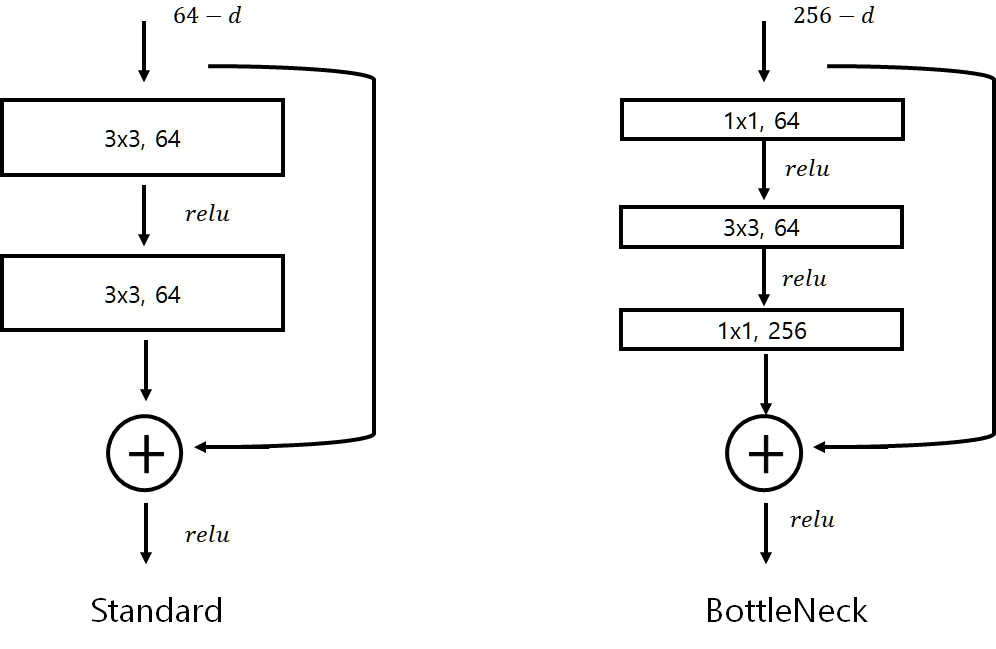
- shortcut 과 더불어 ResNet에서 나온 또다른 혁신적인 방법이 Bottleneck Block 입니다.
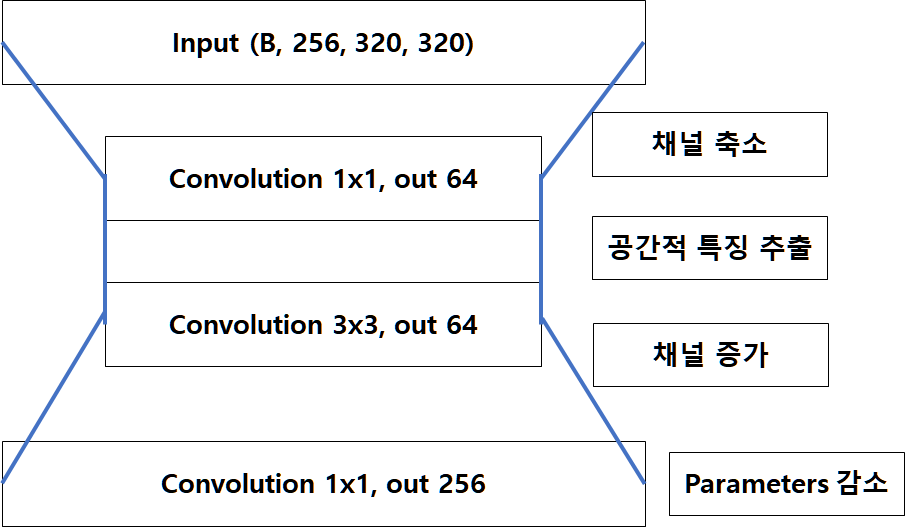
- CNN 은 Feature Map의 특성이 많으면 많을수록 학습이 잘 되기 떄문에, 1x1 Convolution으로 강제적으로 채널을 증가시켜 줍니다.
- BottleNeck 구조는 1x1 Convolution 을 통해 연산량을 최소화하는 것입니다.
- Standard 의 경우 Channel의 수는 적지만, 3x3 Convolution을 두 번 통과하고, BottleNeck의 경우 1x1, 3x3, 1x1 순으로 Convolution을 통과하며 Channel 수는 4배 많지만 Parameter 수가 세 배 적습니다.
2-4. Batch Nomarlization
<추가 해야 한다!!!!>
2-5. Discussion
<1>만약 입력 dimension 과 출력 dimension 이 다르다면?
- 먼저 입력 dim 과 출력 dim 이 동일하다면 지금까지의 수식과 동일하게 identity mapping 을 진행합니다.
- 만약 입력 dim 과 출력 dim 이 다르다면 해결할 수 있는 방안에 대해 논문에서는 두 가지 방안을 설명합니다.
- [1] layer 에 제로 패딩을 붙여 차원을 같게 만들어 준 후 학습을 진행합니다.
- [2] projection 연산을 통해 높은 차원을 낮춰 준 이후 학습을 진행합니다.
[A] 제로 패딩을 통해 차원을 늘리고 identity mappnig 을 진행했습니다.
[B] projection 연산을 진행하고 identity mapping 을 따로 진행했습니다다.
[C] 모든 shortcut x 에 대해서 모두 projection 연산을 수행했습니다.
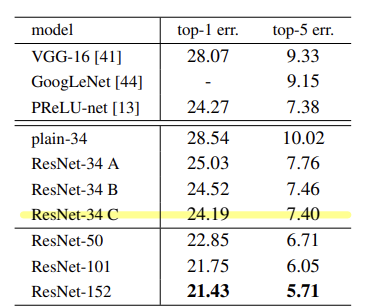
- 결과적으로는 모든 shortcut x 에 대해서 projection 연산을 수행한 결과가 가장 오차가 낮고 성능이 개선되었읆을 확인할 수 있으나, 그 성능 개선 효과가 유의미하다고 판단되지 않아 모든 shortcut x 에 대하여 projection 연산이 필수적이라 보지 않습니다.
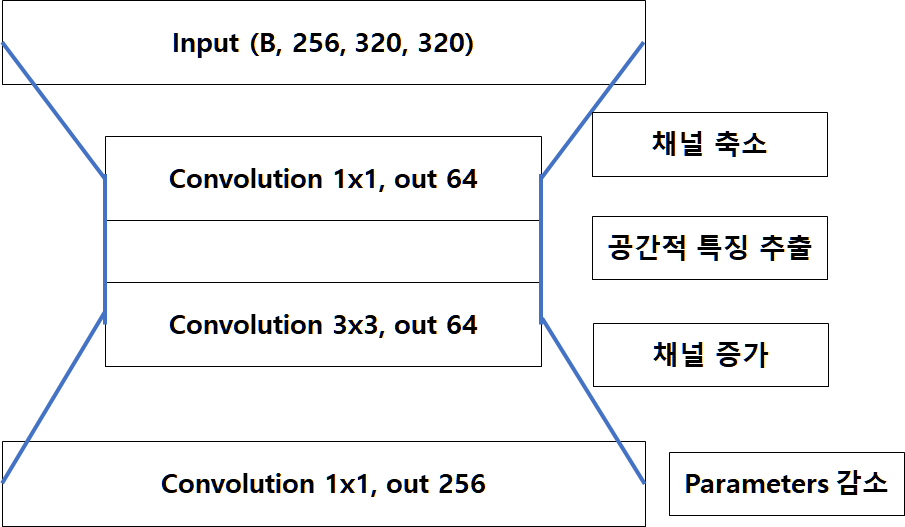
<BottleNeck 구조>
3. Classification Experiments
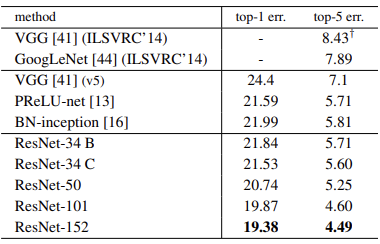
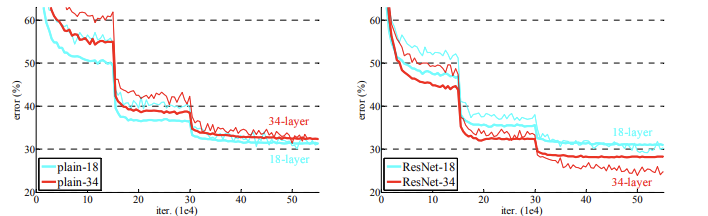
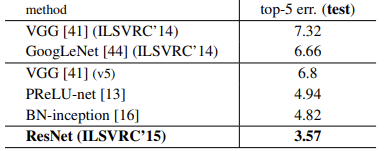
- 실제로 ResNet은 레이어를 쌓을수록 더 좋은 성능이 보임을 확인했고, 특히 앙상블 시 그 성능이 크게 상승함을 확인할 수 있었습니다
- 하지만 1000 개 이상의 layer 를 쌓을 시 다시 오차율이 상승함을 확인할 수 있었습니다.
- ResNet의 경우 객체 탐지 (Object Detection) 이나 Image Segmentation 문제에서도 유의미한 성능을 도출함을 확인할 수 있었습니다.
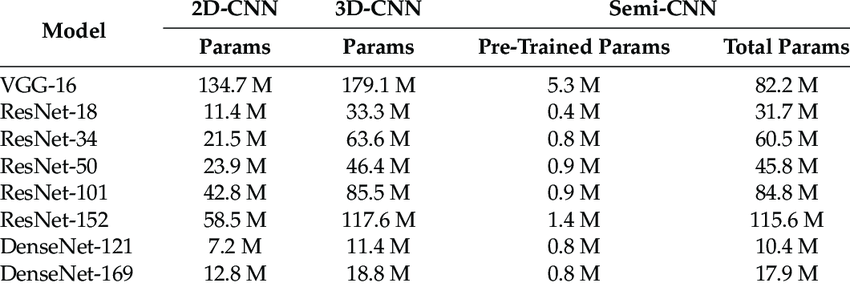
- 실제로 ResNet이 VGG 와 비교해 파라미터의 수가 확연히 줄어든 것을 확인할 수 있었습니다.
4. Reference
- ResNet, ‘Deep Residual Learning for Image Recognition’, 2015
- https://youtu.be/DAOcjicFr1Y
- https://towardsdatascience.com/understanding-and-visualizing-resnets-442284831be8

ML/DL/NLP