목표
물리적인 메모리 관리 중 남은 한 방식인 불연속 할당과 관련해 페이징 기법에 대해 알아본다.
Noncontiguous allocation
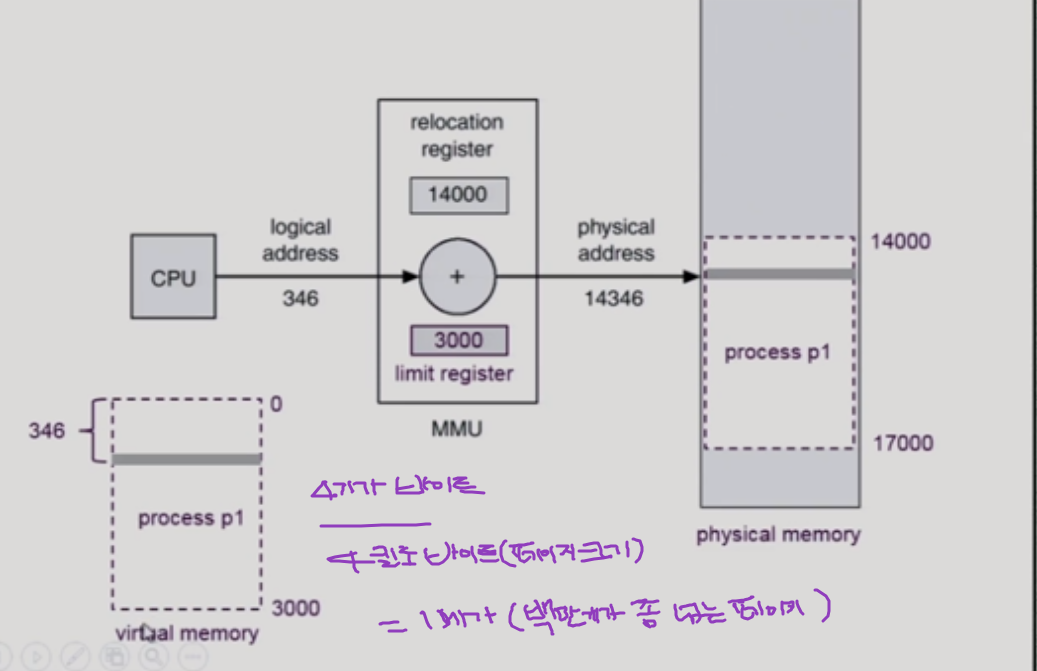
시작 위치를 얻기 위한 레지스터가 많이 필요할 것인데
1) 레지스터 개수는 한정
=> 페이징 기법: 동일 크기의 페이지 단위로 프로그램을 쪼갠다. 보통은 4kb. 당장 필요한 부분은 물리적 메모리에 올라가는데, 올라가는 위치도 각각 다를 수 있다. 각각 페이지마다 주소 변환이 필요하다. 그 페이지 개수가 워낙 많아서 레지스터로는 주소 변환이 감당 안된다. 주소 변환을 위한것이 물리적 메모리에 올라가있다/ : paging
paging

연속 할당 기법: 프로그램 크기가 제각각이기 때문에 메모리 안에 프로그램이 못 들어가는 경우가 생김
paging: 프로그램과 메로리를 동일한 크기로 잘라놨기 때문에, 외부조각이 발생하지 않는다. 내부조각은 생길 수 있다. 프로그램을 구성하는 주소공간을 4kb로 자르다 보면은, 프로그램이 4kb의 배수가 되는 보장이 없다. 마지막에 짜투리 공간이 생길 수 있다 !
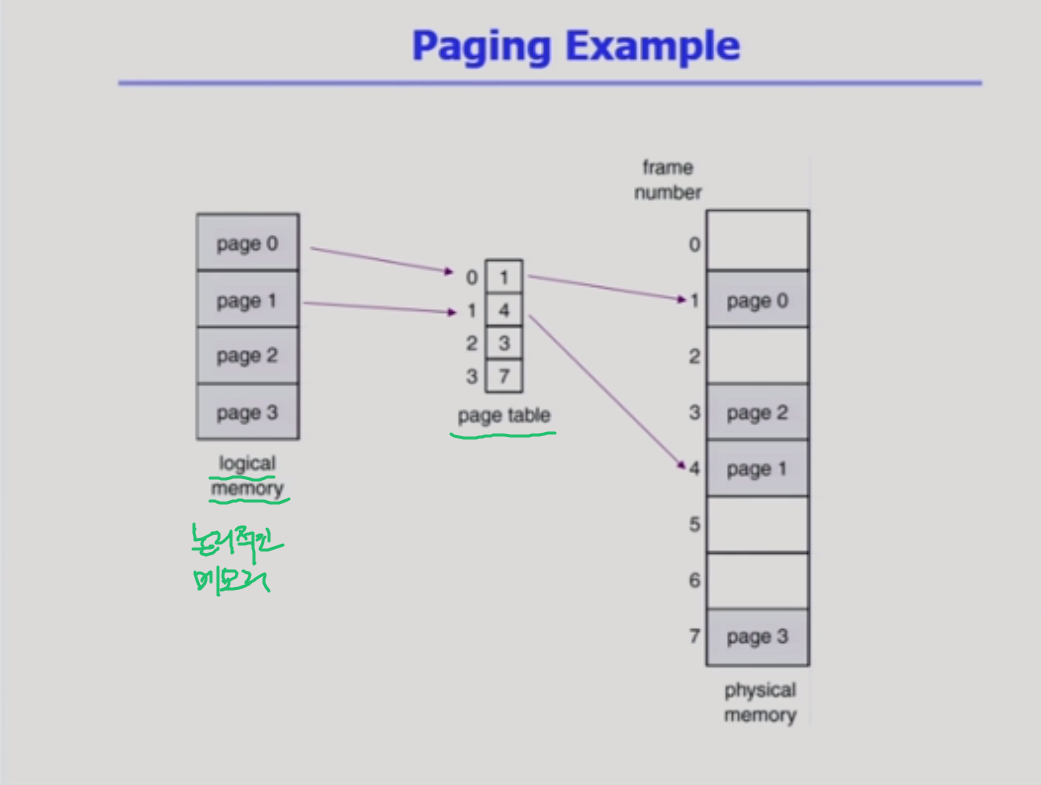
paging example
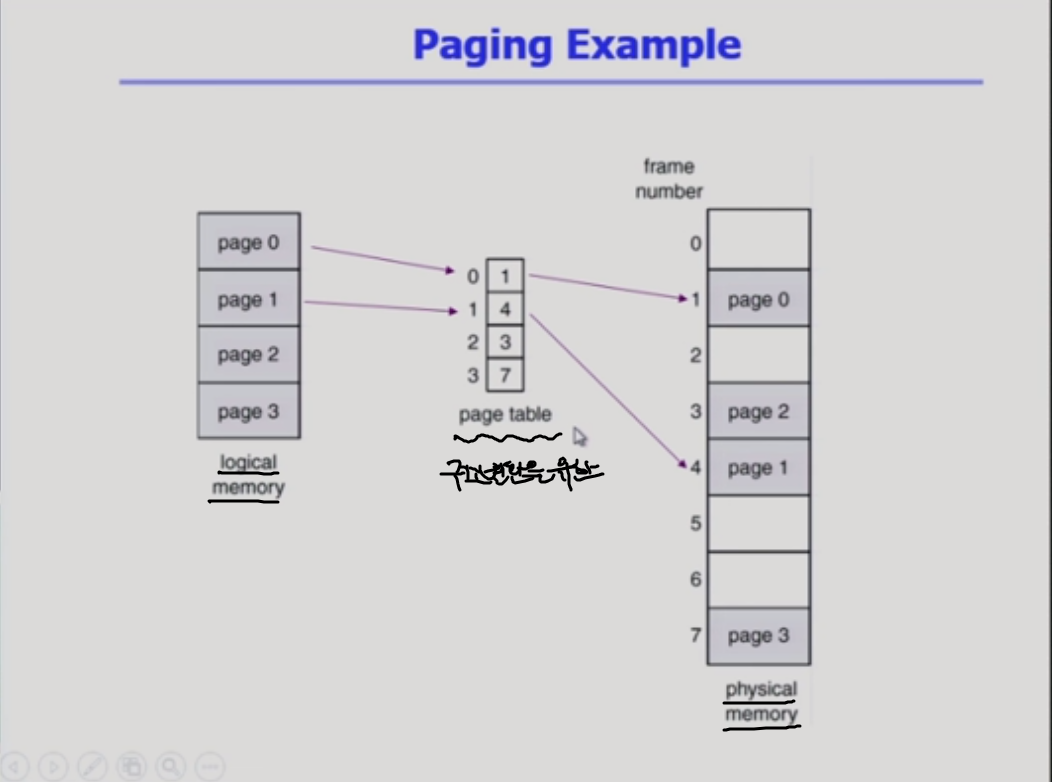
table => 배열이라고 생각하면 된다. 시스템에서 구현하기 위한 것.
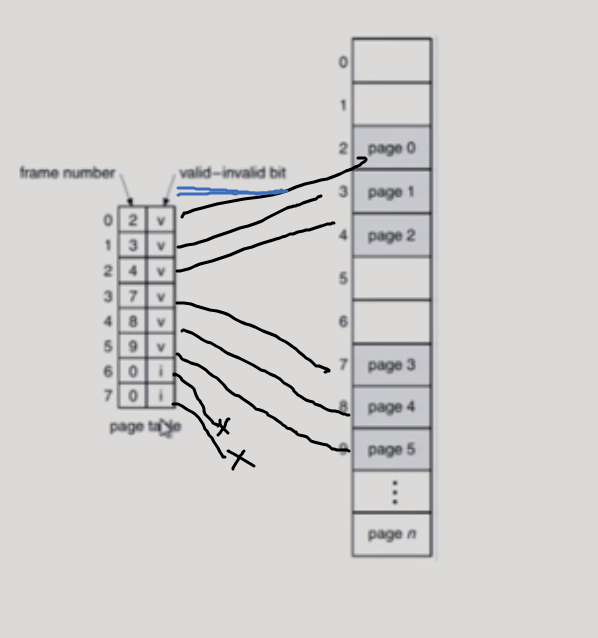
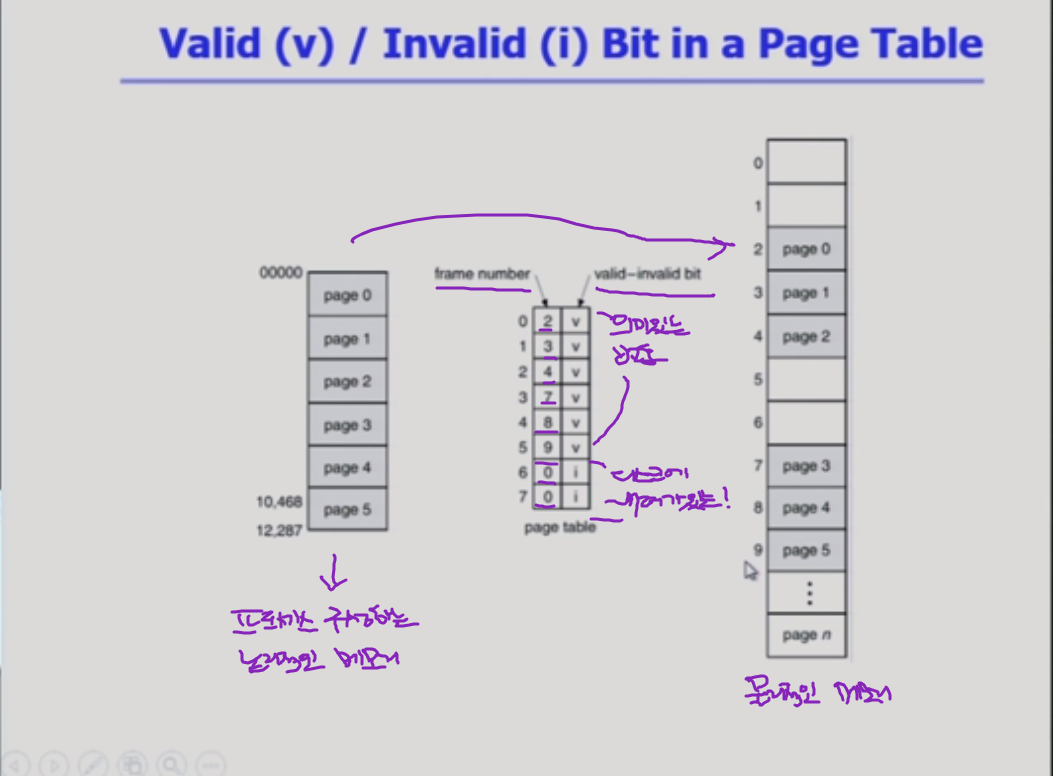
어떤 페이지는 물리적 메모리에 안올라갈 수도 있다. page table에 올라가있는 내용이 의미가 없어진다. 물리적 메모리에 올라가있나, 디스크에 내려가있나/ 비트가 valid 하다 안하다로 체크할 수 있다.
address translation architecture
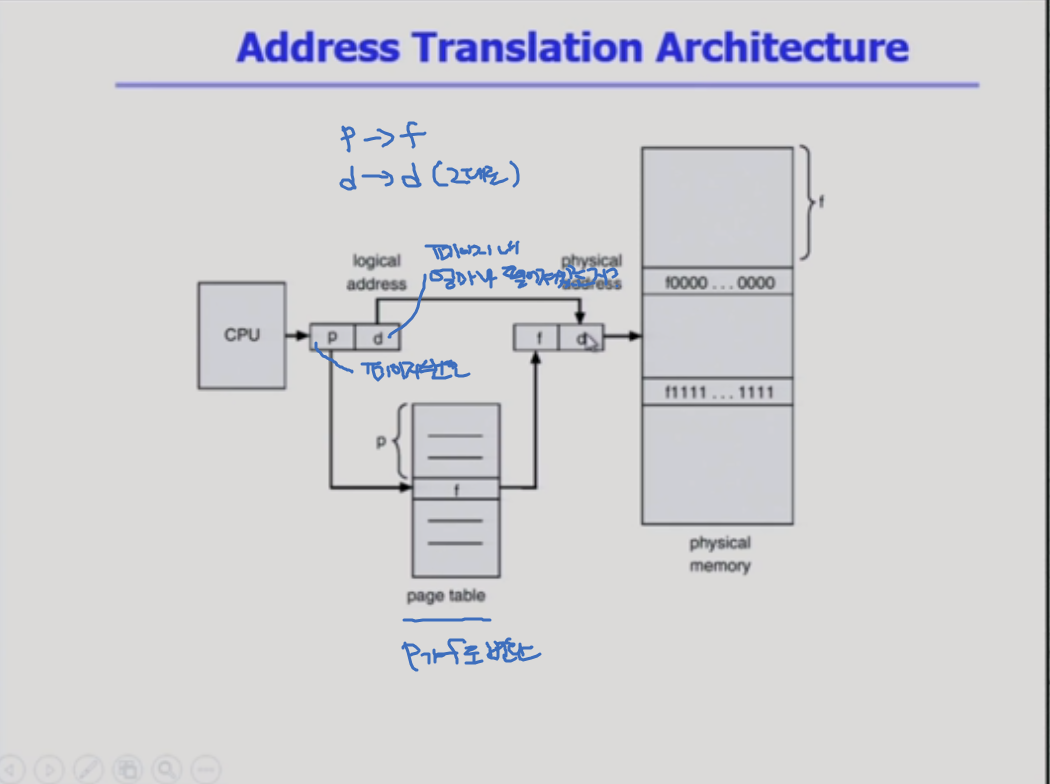
페이지 내 얼마나 떨어져 있는지?
=> 이화여대 크기는 변하지 않는다.
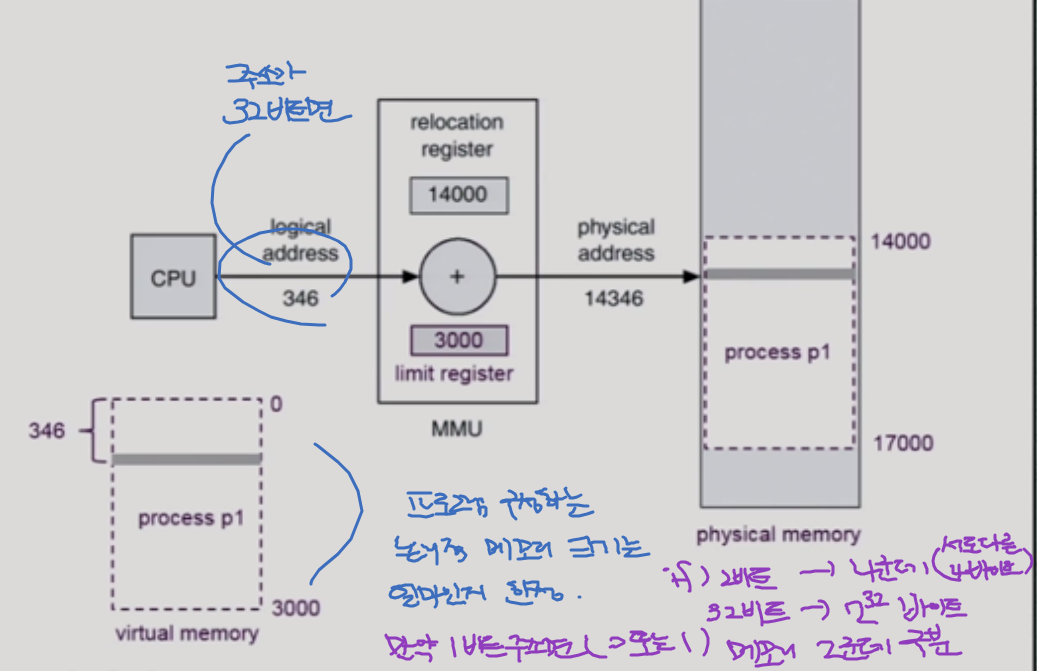
주소체계
보통은 32비트 주소체계를 많이 썼는데 요즘은 64비트 머신을 많이 쓰면서 메모리 크기도 많이 커졌다/
편의상 32비트를 기준으로 설명하겠다.
2의 10승이 킬로고,
2의 20승이 메가고,
2의 30승이 기가입니다. 2의 32승 바이트다 하면 4기가바이트다.
프로그램이 가질 수 있는 최대 메모리 크기는 4기가 바이트다. 32비트 주소체계를 쓸때!
페이지가 100만개가 넘는다. 페이지 테이블이 100만개가 넘는 엔트리가 필요하다는 뜻이 된다.
implementation of page table

page table이 하는 주소 변환의 일불를 TLB(캐시메모리)가 한다 !
Paging hardware with TLB
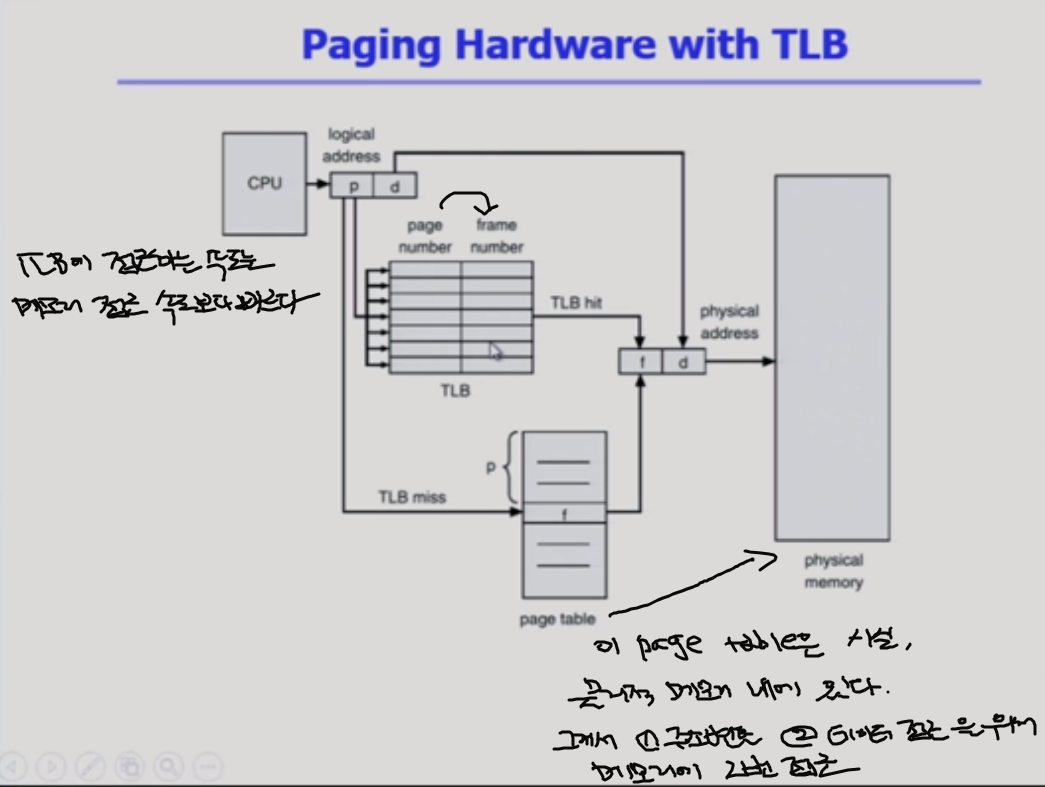
cpu가 물리적 주소를 주면, page table에 가기 전에 tlb를 미리 확인하고, p가 있으면 주소변환을 해서 바로 메모리 접근을 하고 그러면 메모리에 한번만 접근하면 된다. 근데 찾아보니까 tlb는 일부만 담고 있으니, tlb에 없으면 page table을 통해서 주소변환을 해야한다~~!
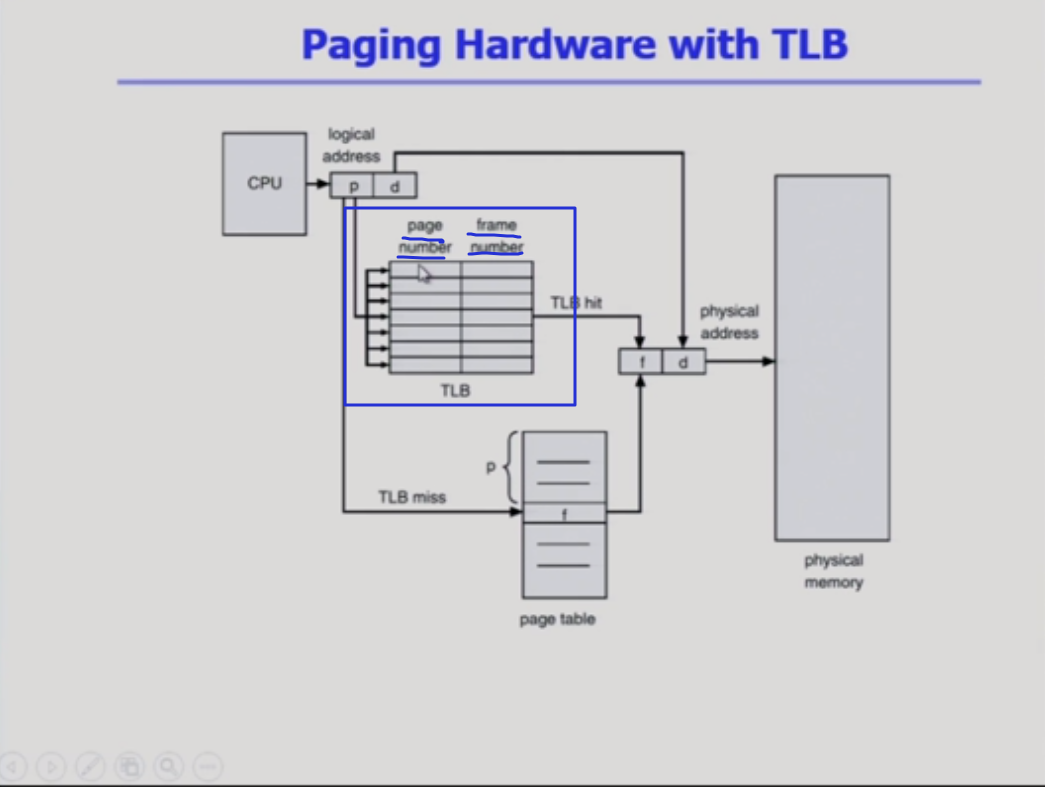

근데, 생각해야할 부분이 있다.
page table은 배열 자료구조다. 0번 엔트리부터 100만번 엔트리까지 다 만들어져 있다. 만약 페이지 번호를 90만 번이면, 위에서부터 다 써치를 하는게 아니다. 바로 90만번 째로 바로 가서, 체크하는데
tlb는 내용의 일부만 담고 있기 때문에 page 번호를 안다고 해서 바로 찾는게 아니다. tlb는 target이 되는 프레임 번호를 갖고 있어서 되는게 아니라, 주소 변환이 어떤 페이지에 대한 건지 논리적 페이지 번호와 논리적 번호를 같이 가지고 있어야 한다.
2) 주소변환이 바로 되는게 아니라, p에 대한 주소변환 정보가 tlb에 있는지 없는지 전부다 써치를 해야 한다. 그럼 이게 오버헤드가 대단히 크다. 그래서 보통 tlb는 한꺼번에 병렬적으로 찾으려는 하드웨어가 있어야 하는데 그런 하드웨어를 associative 레지스터라고 부른다.

effective access time
메모리 접근하는 시간이 어떻게 되는지 알아보자 !

tlb miss ! = 1-a
tlb hit ! = a
tlb에 접근하는 시간을 입실론?
메모리에 접근하는 시간 1
전제: 메모리에 접근하는 시간보다 tlb에 접근하는 시간 입실론이 더 작겠지/
two-level page table

페이지 테이블을 사용하면 좋은 점은 프로그램을 동일 크기로 잘라서 메모리 빈 위체 아무데낭 올릴 수 있고, 당장 필요한 페이지만 올릴 수 있고 효율적으로 사용이 된다. 근데 페이지 개수가 프로세스마다 백만개가 넘으니까, 페이지 테이블 수도 백만개가 넘고, 4바이트 엔트리 하나하나가 백만개 정도 넘는다. 페이지 테이블은 프로세스마다 각각 존재한다. 그러니까 우리가 32 비트 주소체계에서 사용하는 현대 운영체제에서는 페이지 테이블을 통해서 공간낭비가 된다.
=> 그래서 2단계 페이지 테이블이란 걸 사용하게 된다.
two-level page table
주소 변환을 위해서 메모리를 두번 접근하고 실제 데이터를 변환하기 위해 한 번 접근한다. 시간상으로는 손해지만 공간상으로는 이득이다.
원래는 엔트리 1m개가 연결 . 시간도 공간도 손해인거라고 생각이 드나? => 프로세스의 주소공간 4기가 바이트를 1메가 개로 . 실제 프로세스 주소공간을 구성하는 백만개 페이지 중에서 정말 사용하는 페이지는 몇개 안된다.
프로세스의 주소공간을 구성하는 코드 데이터 스택이 있는데, 이게 메모리 공간이 워낙 넓다니까 저위에 코드 데이터가 있고 밑에 스택이 있고, 중간에 메모리 공간이 있다. 뭐 둬도 상관이 없다. 페이지 중에서 필요한 것만 물리적 메모리에 올려놓기 때문에, 크게 메모리 낭비가 될 게 없다. 다만, 페이지 테이블은 낭비가 된다. 사용안되는 메모리에 대해서 페이지 테이블 엔트리가 없애버리면, 페이지 번호로 바로 접근을 못한다. 없애지는 못한다.
결론을 내릴게. 즉 사용하지 않는 페이지가 논리적 메모리에 올라가있는데 그게 논리적 메모리에서는 문제가 되지 않지만 페이지 테이블에서는 사용하지 않는 페이지까지 다 주소변환을 하기 때문에 메모리 낭비가 심해진다. => two-level page table
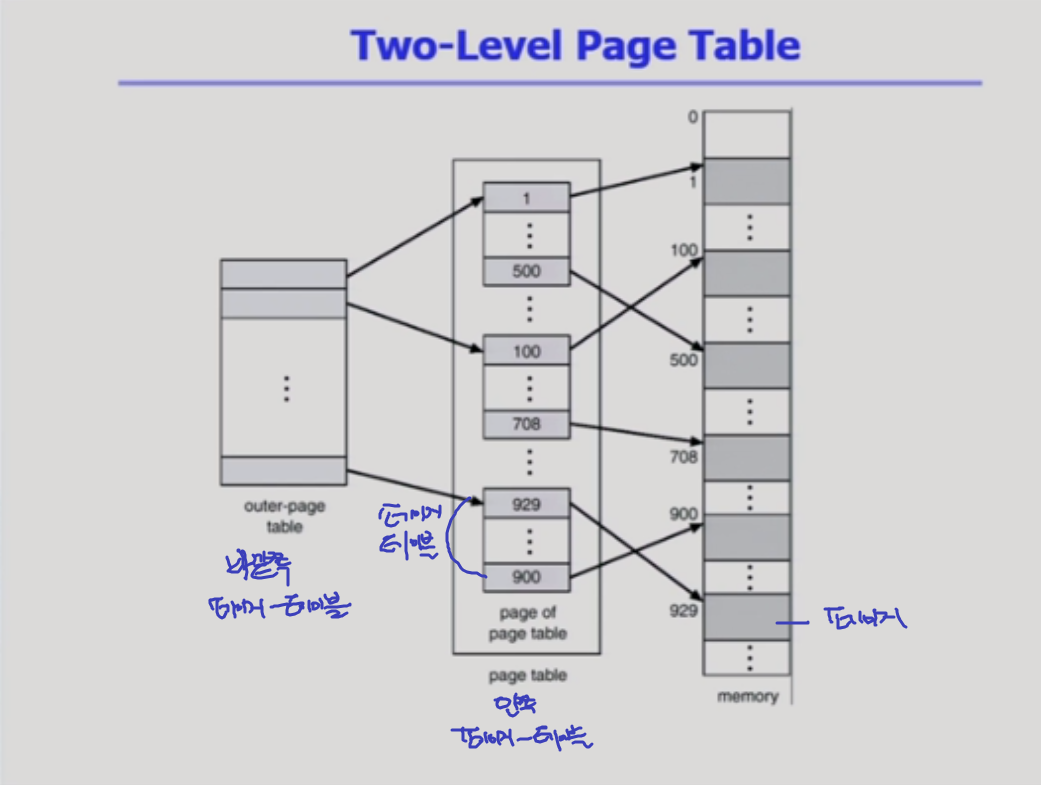
사용이 안되는 영역에 대해서는 안쪽 페이지가 만들어지지 않고, 바깥쪽 페이지 포인터가 그냥 NULL로 표시되어 있다. (안쪽 페이지 엔트리 하나하나는 4키로 바이트. 즉 페이지 하나를 가리키게 되고 / 바깥쪽 페이지 테이블의 엔트리 하나는 4키로 바이트가 아니라 그것보다 훨씬 큰 하나의 페이지 테이블을 가리키는 것. )
안쪽 페이지 테이블 하나가 4키로 바이트면 안쪽에 엔트리는 몇개 잇을까요? 안쪽 페이지 테이블 중 하나하나 페이지가 4바이트씩이다. 그럼 개수는 1K개가 나온다.
Address-translation scheme
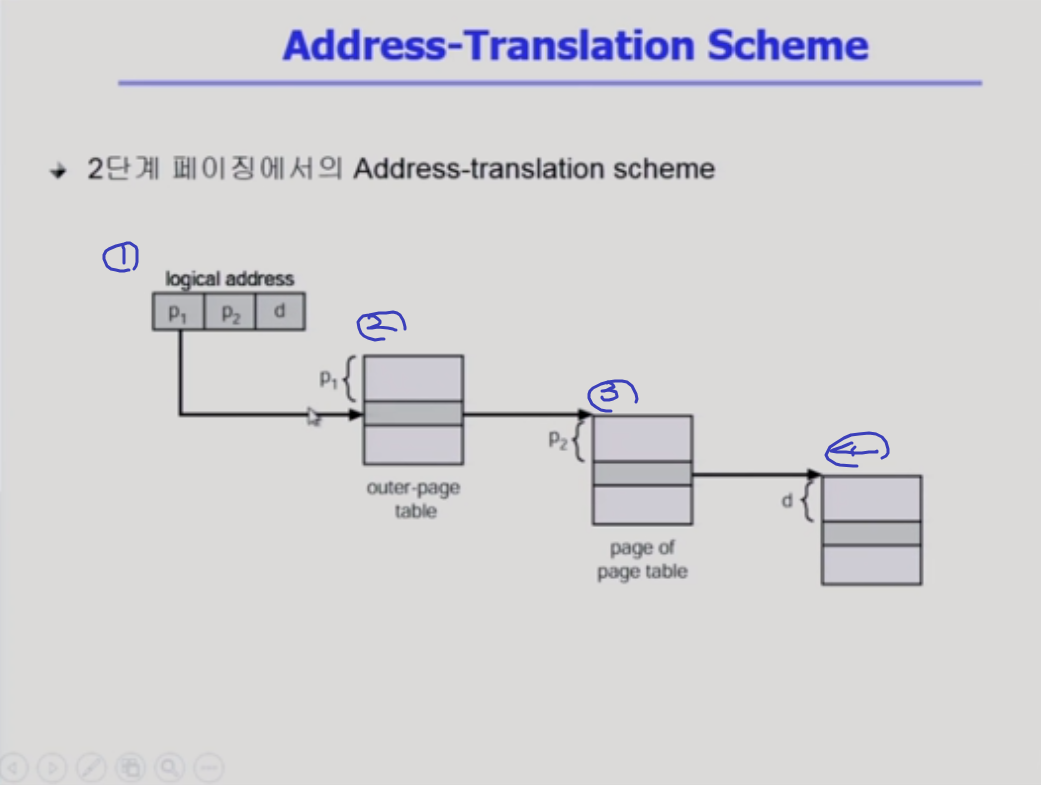
- 32비트의 주소가 이제 3부분으로 나눠진다. 맨 뒤쪽에 있는게 페이지 오프셋이다. 페이지 내에서 얼마나 떨어져있는가. 이거는 몇 비트인가요? 페이지 하나의 크기가 4키로 바이트고, 그내에서 몇번째냐를 가리키는 거기 때문에 4k개의 위치 부분이 필요하기 때문에 4k를 구분하려면 ? 4k는 2의 12승이다. 그래서 12비트가 있으면 된다 ~~
- p1은 바깥쪽 테이블에서 p1번째를 뜻하고
- p2는 아쪽 페이지 테이블 쪽에서 위에서 p2번째를 나타내는 페이지 테이블의 페이저 번호다.


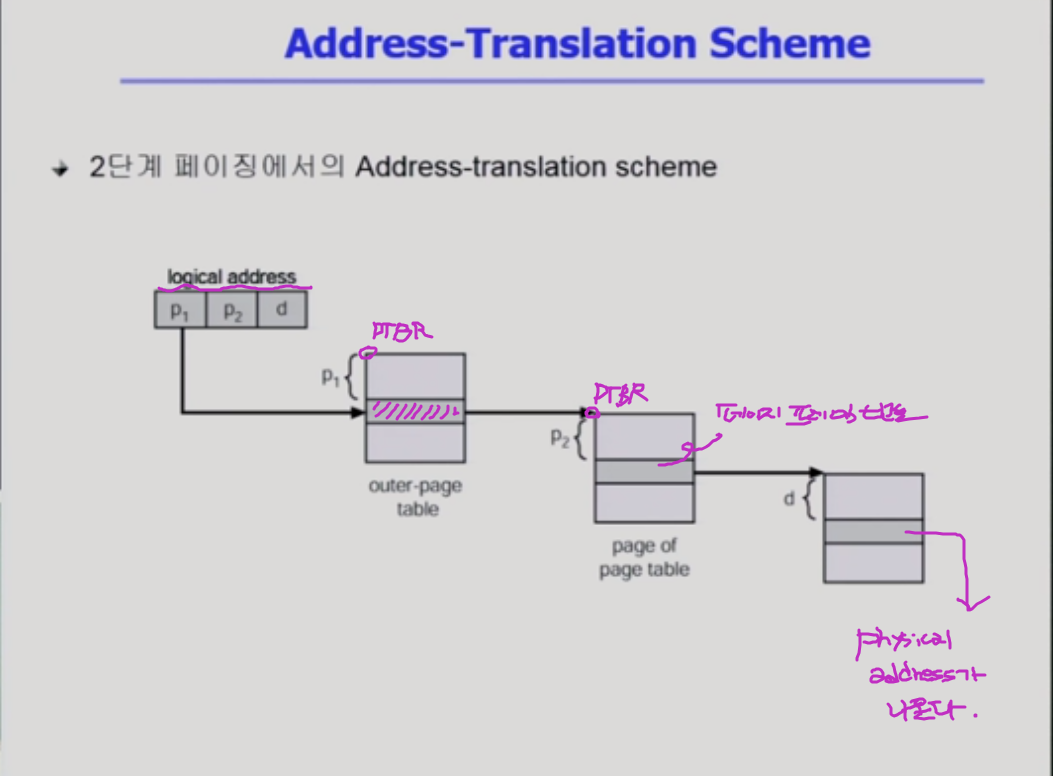
위에서부터 p1번째 떨어진 위치로 가
null 이면 사용되지 않는 주소다.
뭔가를 가리키고 있으면 안쪽 페이지 테이블 위치의 시작위치를 가지고 있을 거고 거기서부터 p2를 통해서 페이지 프레임 번호가 나오고, 거기서부터 d 번째 바이트 위치를 가면 logical address에 대응하는 phusical address가 나온다.
정리
- 서로 다른 2의 n승 군데를 구분하기 위해선 몇 비트가 필요하냐?
=> n비트가 필요하다. - n비트로 구분 가능한 서로 다른 위치는?
=> 2의 n승가지 - 우리가 서로 다른 위치를 n군데 구분하고 싶을 때 몇 비트 필요하냐?
- n비트로 구분 가능한 몇 군데냐?
multilevel paging and performance

지금까지 2단계 페이지를 설명했는데,
멀티 레벨 즉, 다단계 페이지를 사용할 수 있다. 3단계, 4단계,,,
공간을 크게 줄일 수 있다. 프로세스의 주소공간 중에 상당 부분이 사용이 안되기 때문에 다단계 페이지 테이블을 사용하면 최외각 페이지만 만들어지고 사용 안되는 위치는 다 null로 되어있다. 안쪽 페이지 안만들어진다.
근데 문제는 시간이 오래 걸린다. 주소 변환을 위해서 메모리 접근 여러번 실제 데이터 접근 한번 하면서 시간 오래 걸림
그런데도 왜 멀티레벨을 하는 지 위 그림에서 설명
valid / invalid bit in a page table

잘 봤습니다. 좋은 글 감사합니다.