스택
🍀내 풀이🍀
이거 볼 때는 쉬워보였는데 직접 풀어보니깐 어려웠다... 스택 써야하는지 몰랐다. 큐 써야하는줄.. 암튼 스택으로 못 풀겠어서 풀이를 봤는데 어려웠다.. 이것도 이해하는데 한참 걸린거 같다.
- rstrip: 오른쪽 공백을 지우는 것이다.
이 문제는 그냥 문자열을 전체 한 뭉텅이로 봐주고 구분을 해주는 것이다. (나는 하나씩 단어를 뗴서 봐야한다고 생각했는데 생각해보니 그냥 gh<ij>이렇게 쓰이는 경우에는 띄어쓰기가 안되어있기 때문에 다 한 뭉텅이로 보는게 맞다.
이 문제는 예시로 직접해보는게 더 쉬울거 같다.
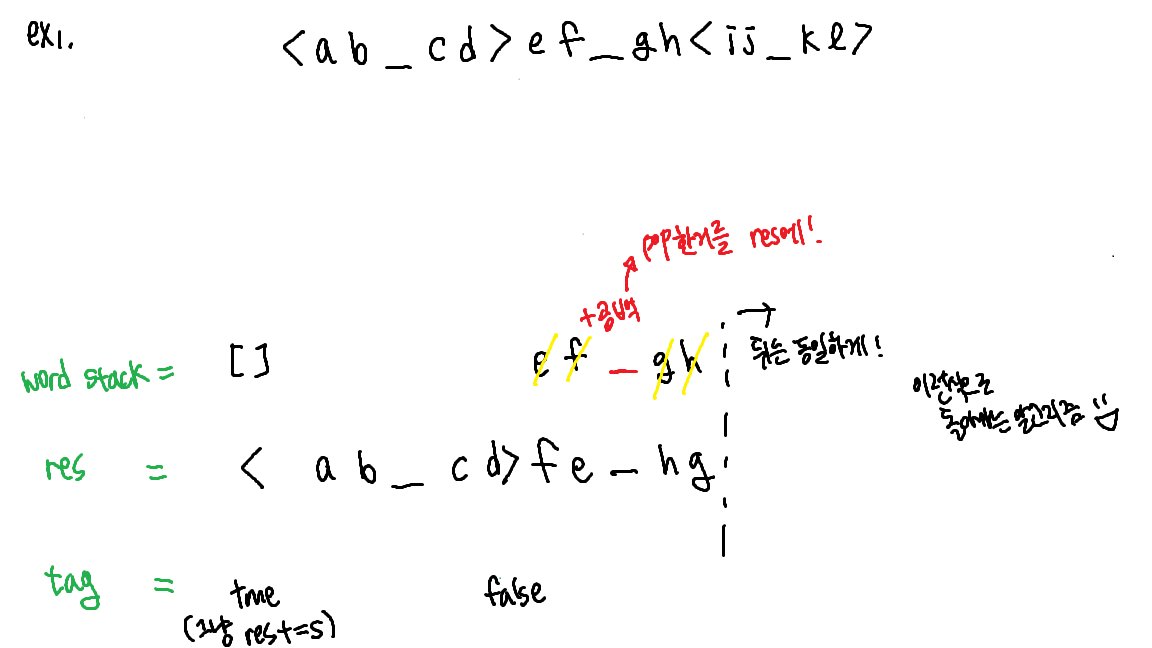
🍀내 코드🍀
방법1 -stack 이용
import sys
input = sys.stdin.readline
string = input().rstrip()#오른쪽 공백 지우기
word_stack = []
tag = False
res = ''
for s in string:
if s == " ":
while word_stack:
res += word_stack.pop()
res += s
elif s == "<":
while word_stack:
res += word_stack.pop()
tag = True
res += s
elif s == ">":
tag = False
res += s
elif tag:
res += s
else:
word_stack.append(s)
while word_stack:
res += word_stack.pop()
print(res)방법2
그냥 문자열로 푸는 방법도 있는데 이 방법으로는 나중에 풀어봐야겠다. 이해가 잘 안된다..
import sys
word = list(sys.stdin.readline().rstrip())
i = 0
start = 0
while i < len(word):
if word[i] == "<":
i += 1
while word[i] != ">":
i += 1
i += 1 # 닫힌 괄호를 만난 후 인덱스를 하나 증가시킨다
elif word[i].isalnum(): # 숫자나 알파벳을 만나면
start = i
while i < len(word) and word[i].isalnum():
i+=1
tmp = word[start:i] # 숫자,알파벳 범위에 있는 것들을
tmp.reverse() # 뒤집는다
word[start:i] = tmp
else: # 괄호도 아니고 알파,숫자도 아닌것 = 공백
i+=1 # 그냥 증가시킨다
print("".join(word))
AI 개발자