-
이전 numble coupon 후기
-
기존 '완성' 시점의 성능은 vues 150 에서 최대 약 142RPS 정도 성능이 측정 되었으며 더이상 vue의 숫자가 올라갈때 마다 RPS가 올라가지 않았다.
-
이전 numble e-commerce coupon 프로젝트 종료 후 피드백을 받은 것 들 중에서 하나씩 개선하고자 하였다.
- 현 UseCase 에서는 충돌이 자주 발생할 것 같습니다.
- Redis에서 count, DB는 write만 하는 것으로 해결 할 수 있을 것으로 보입니다.
요구사항
- 쿠폰의 지급 수량을 초과해서는 안된다.
- 쿠폰은 1인당 1장만 지급한다.
해결 방안
Count는 Redis 에서, DB는 쓰기만 집중
-
기존 coupon_stock 테이블 삭제
- 기존에 '수량'을 확인하던 coupon_stock 테이블을 삭제하고, 수량 count는 전부 redis 의 책임으로 이관하였다.
-
쿠폰 발급 API 쿼리문 삭제
- 쿠폰 발급시 해당 쿠폰이 유효한지 확인 하는 로직(Query) 제거
- Redis 를 통해 해당 쿠폰 정보 확인 및 validation 진행
-
유저의 Request에서 '쿠폰 발급 시' Response Return 제거
- 유저의 요청은 즉시 Response Return
- application단 에서 쿠폰 발급이 가능할 경우 발급
Redis 활용
- SADD 와 SCARD 를 활용하여 요구사항 1, 2번에 대하여 해결하였습니다.
SADD
- 키에 저장된 집합에 지정된 멤버를 추가
- 중복 발급 및 발급 count를 확인하기 위하여 활용
async setGiveUser(setGiveUserOut: IUserCouponCacheSetGiveUserOut) {
// sadd value 가 존재하면 0
return this.client.sadd(this.prefixCouponId + setGiveUserOut.couponId + ':' + this.prefixUserId, setGiveUserOut.userId);
}
- 유저가 '쿠폰 발급' 할 시 2번 요구사항에 의해 1인당 1장 이상 지급 시 error 처리
즉 해당 메소드의 return 값이 0이면 중복 발급 처리
SCARD
- 키에 저장된 개수를 반환
- 해당 coupon 발급 개수가 초과 하지 않았는지 확인하기 위하여 활용
async countStock(couponId: number) {
return this.client.scard(this.prefixCouponId + couponId + ':' + this.prefixUserId);
}
- RDB 상에 존재하는 초기 coupon의 재고 값과 해당 return 값으로 기존 쿠폰 개수를 초과했는지 확인하며 유저에게 쿠폰을 발급시킨다.
결과
Before
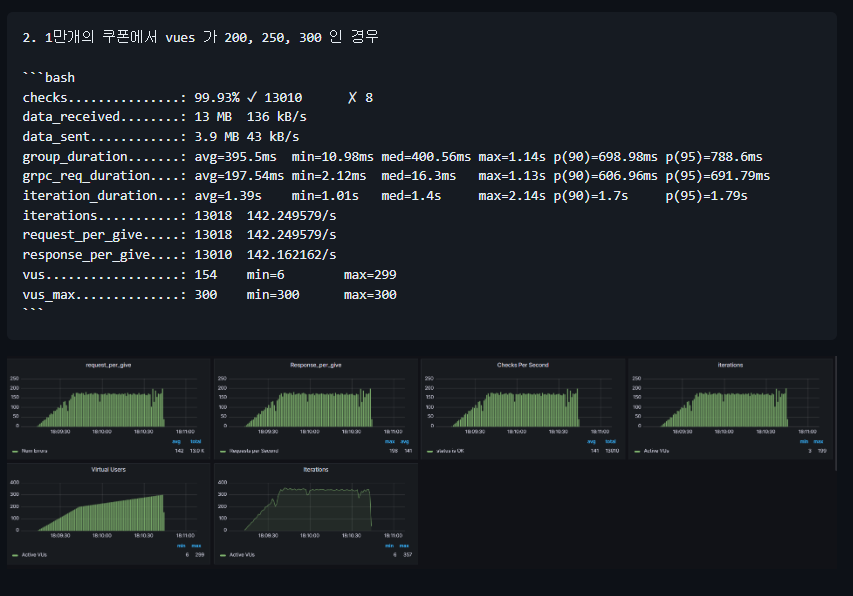
- 150 vues 에서 RPS가 증가하지 않았다.
- 약 150 RPS 정도로 측정
After

- 약 800 vues 정도에서 더이상 RPS 가 오르지 않았다.
- 약 800 RPS 정도로 측정되었다.
다른 방법
- pub/sub 패턴으로 redis에서 read pub/sub 발행, server write DB 에 따른 분리
- server appication 분리에 따른 성능 개선이 얼마나 이루어지는지 확인할 필요가 있었다.
하지만 이 부분도 정확히 어떤곳에서 병목이 발생했는가? 에 따른 판단이 필요할 것으로 보였다.
고민사항
-
DB redis application 등 어느 부분에서 병목 현상이 일어나는가 ?
- 어떤 모니터링 툴써서 정확히 어떤 부분에서 병목이 존재하는지, 어떤 부분을 개선할 수 있는지 판단하는 기준이 명확해지는 방법이 필요해 보인다.
- k6와 grafana만을 활용해서 하다보니, 특정 vue 이상으로 더이상 RPS가 올라가지 않는다. 정도의 정보만 확인 할 수 있었다.
- 정확히 어떤부분에서 병목이 걸리는지, DB 분산, application server 분산, 아니면 해당 로직 및 query등의 문제인지, 병목현상의 정확한 원인파악이 어려웠다.
-
쿠폰을 유저에게 '즉시 지급' 이 아닌 pub/sub 패턴을 통해 지연 지급을 통하여 개선할수도 잇을것이다.
-
'쿠폰 발급 가능' 여부를 판단하는 redis 의 부하는 피할 수 없다.
-
그럼 redis의 부하는 어떻게 개선하는가 ?
- (하단의 링크에서) Kafka 를 사용해서 해결했다고 쓰여있지만, 그것보다는 Redis 를 사용하는 서비스 회사들은 Redis에 대한 부하에 대한 대처법과 어떤식으로 주로 사용하는지에 대해서 궁금증이 생겼다.
회고록
-
redis 와 DB 로 구분했지만 server spec에 따라서 서버 비용(돈)으로 해결 되는 부분인지, scale out 으로 해결 할 수 있는지 판단 기준을 명확하게 세우고 싶었다.
-
하나의 노트북 server로 테스트
- 해당 노트북에 server application, redis, RDS, grafana 등 다 설치 되어있었다.
- aws나 다른 cloud 환경에서 테스트가 필요해 보인다.
기획, 기획에 따른 설계, 기능 요구사항을 위한 개발을 항상 우선시 했다.
-
'동작하는 소프트웨어를 만들어라'
- 가장 우선순위가 높은 부분은 '동작하는 소프트웨어' 이다.
개발을 진행하게 되면 기획, 설계가 이루어지고 해당 기능에 대한 요구사항과 함께 개발을 진행하게 된다.
- 가장 우선순위가 높은 부분은 '동작하는 소프트웨어' 이다.
-
'성능'에 대한 키워드는 우선순위가 낮을때가 많았다.
-
성능 개선이라고 하여도 RDB의 실행계획 및 인덱스를 어떻게 사용하여 Query에 대하여 성능 개선 작업이 주를 이루었다.
-
'성능'을 어떻게 테스트 하는가 에 대해 점점 관심을 기울여야 하지 않을까 란 생각을 했다.
-
아무리 유저가 원하는 서비스라고 해도 '속도'에 따른 서비스 이탈율도 고려해야하며, 속도가 느린 서비스는 아무도 이용하려 하지 않을 것이다.
-
먼저 성능개선을 하기 전에 어떻게 했는지가 제일 중요했다. 상황마다 병목지점이 다 다르기 때문에 실제 내가 직면한 문제에 대해서 먼저 파악이 우선인것 같다.
-
문제 파악을 위해서는 지표를 봐야하고, 테스트를 해봐야하고, 어떤상황인지 인지할 필요가 있어보인다.
-
개선에 대해서 여러 방법, 접근 방식을 배워야할 필요성을 느꼈다.
- 내가 알고 있는 방법이라곤 RDB만 사용, 인덱스를 어떻게 태우는지, 쿼리를 줄여서 사용하는 등의 간단한 방법밖에 생각이 나지 않았다.
- Redis를 활용해서 Read, count 의 책임을 부여하는 등의 아키텍처 적으로 해결 할 수 있는 부분도 존재했다.
- 항상 '스스로' 해결 하고자 할 뿐만 아니라, 이미 상황을 겪고 다르게 해결한 사람들에 이야기를 통해 적용과 응용을 꾸준히 연습해야 겠다.
참고 링크
