💡 업로드 모듈을 개발하는 이유
내 머리속에 있는 지우개 어서오고 오랜만

최근 사이드 프로젝트를 소셜 네트워크(SNS) 기반 맛집 소개앱(플램버스)를 진행하고 있다.
현재 디자인 및 기획을 디테일 하고 있는 과정에서 미리 공통적으로 사용할만한 주말마다 짬짬히 비즈니스 로직을 개발하고 있었다.
이미 완성은 했었지만 나중에 다시 보면 분명 왜 이렇게 했는지 기억을 다 지워버릴것이기 때문에 코드를 정리하면서 회고하려고 합니다
업로드 모듈은 리뷰 작성, 피드 작성..등등 많은 곳에서 사용될 예정이므로 결합도와 확장성에 신경을 써서 개발하려고 노력했습니다.(지만 좋은 코드인지는 잘 모르겠음)
혹시 비슷한 로직을 구현하고 계신분중에 성격급하신분들은 그냥 아래 코드를 참고하시면됩니다.
시간이 금이다!
https://github.com/explorer-cat/flambus-v1.0-springboot
WHY S3를 선택했는지?
Amazon Simple Storage Service(Amazon S3)는 업계 최고의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다. 모든 규모와 업종의 고객은 Amazon S3를 사용하여 데이터 레이크, 웹 사이트, 모바일 애플리케이션, 백업 및 복원, 아카이브, 엔터프라이즈 애플리케이션, IoT 디바이스, 빅 데이터 분석 등 다양한 사용 사례에서 원하는 양의 데이터를 저장하고 보호할 수 있습니다. Amazon S3는 특정 비즈니스, 조직 및 규정 준수 요구 사항에 맞게 데이터에 대한 액세스를 최적화, 구조화 및 구성할 수 있는 관리 기능을 제공합니다.
애초 설계할때부터 서버에 직접적으로 업로드 하는 방식은 생각하지 않았다.
일단 AWS 프리티어를 사용중이기도 했고, 내가 알기론 EC2 서버에 네트워크 업로드,다운로드 용량에 따라서 추가 요금이 발생한다. (예전에 무지성 git clone 하다가 요금 폭탄을 맞은적이 있음)
S3는 요금이 아주 착하다. 또한 SDK를 통한 여러 써드파티 기능들도 지원을 하고 있다.
실제 사용하고있는 Ubuntu 서버에서 S3로 바로 접근도 가능함!
SPRING BOOT AWS S3 연결
세팅법은 구글에 검색하면 많이 나와있으니, 아무거나 참고하면된다.
업로드 서비스 구조
UploadController.java
해당 컨트롤러는 업로드 서비스 테스트를 위해 작성했습니다.
@PutMapping(value="/upload",consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResultDTO<Map<String,Object>> saveImage(
@RequestParam(value="image") List<MultipartFile> image,
@RequestParam String userId) throws IOException {
Map<String,Object> sampleArray = new HashMap<>();
uploadService.upload(image,userId ,AttachmentType.REVIEW,2344);
return ResultDTO.of(ApiResponseCode.CREATED.getCode(),ApiResponseCode.CREATED.getMessage(), sampleArray);
}UploadService.java
/**
* @param multipartFile 업로드된 파일 multipartFile 객체
* @param userId 사용자 userId
* @param attachmentType 업로드 타입("REVIEW,FEED")
* @return
* @throws IOException
* @title 파일 업로드
*/
@Transactional
public List<Map<String, Object>> upload(List<MultipartFile> multipartFile, String userId, AttachmentType attachmentType, long mappedId) throws IOException {
List<UploadImage> saveImageDataList = new ArrayList<>();
if(multipartFile.size() <= 0) {
new IllegalArgumentException("업로드될 파일이 없습니다.");
}
//MultipartFile로 받은 객체를 File 객체로 변환
for (MultipartFile file : multipartFile) {
//업로드 시도한 파일 제한 용량 검증
validateFileSize(file);
//MultipartFile -> File 객체로 convert
File convertFile = convert(file).orElseThrow(() -> new IllegalArgumentException("MultipartFile -> File 전환 실패"));
//s3에 적재될 유니크한 파일 이름
String saveFileName = generateUniqueFileName(file.getName());
//실제 파일 이름.
String orginFileName = file.getOriginalFilename();
//업로드될 버킷 PATH
String bucketPath = attachmentType.getType() + "/" + userId + "/" + mappedId + "/" + saveFileName;//적재할 경로 세팅
//업로드 된 이미지 URL
String url = putS3(convertFile, bucketPath); //s3에 적재
// 로컬에 생성된 File 삭제 (MultipartFile -> File 전환 하며 로컬에 파일 생성됨)
removeNewFile(convertFile);
//S3 버킷에 적재된 이미지 파일 정보를 게시글정보와 함께 맵핑해서 디비에 저장함.
saveImageDataList.add(UploadImage.builder()
.fileName(orginFileName)
.uniqueFileName(saveFileName)
.imageUrl(url)
.fileSize(file.getSize())
.attachmentType(attachmentType.getType())
.mappedId(mappedId)
.created(LocalDateTime.now())
.updated(LocalDateTime.now())
.build());
}
return saveDB(saveImageDataList, attachmentType, mappedId);
}
/**
* @title S3 업로드 모듈
* @param uploadFile
* @param fileName
* @return
*/
private String putS3(File uploadFile, String fileName) {
amazonS3Client.putObject(
new PutObjectRequest(bucket, fileName, uploadFile)
.withCannedAcl(CannedAccessControlList.PublicRead) // PublicRead 권한으로 업로드 됨
);
return amazonS3Client.getUrl(bucket, fileName).toString();
}validateFileSize() 함수는 업로드 전 조건을 검사하는 검증 함수입니다.
/**
* @title 파일의 최대 용량을 초과한 경우 예외 처리
* @param file
*/
private void validateFileSize(MultipartFile file) {
String contentType = file.getContentType();
long fileSize = file.getSize();
FileType fileType = FileType.fromContentType(contentType);
if (fileType != null) {
switch (fileType) {
case PNG:
case JPEG:
if (fileSize > fileType.getMaxSize()) {
System.out.println(fileType.getContentType() + " : 업로드 제한된 용량 이상입니다.");
// ZIP 파일의 최대 용량을 초과한 경우 예외 처리
// throw new YourException("ZIP 파일 용량 초과"); // 예외 처리 방식은 상황에 맞게 정의
}
break;
default:
break;
}
}
}
MultipartFile로 받은 데이터를 File객체로 변환해줍니다.
이 과정에서 정상적인 업로드 객체가 아니라면 예외처리 되도록 했습니다.
//MultipartFile -> File 객체로 convert
File convertFile = convert(file).orElseThrow(() -> new IllegalArgumentException("MultipartFile -> File 전환 실패"));/**
* @title multipart 파일 객체를 일반 File 객체로 변환
* @param file
* @author 최성우
* @return
*/
private Optional<File> convert(MultipartFile file) {
try {
File convertFile = new File(file.getOriginalFilename());
if (convertFile.createNewFile()) {
try (FileOutputStream fos = new FileOutputStream(convertFile)) {
fos.write(file.getBytes());
}
return Optional.of(convertFile);
}
return Optional.empty();
} catch (Exception e) {
System.out.println("e : " + e);
}
return Optional.empty();
}다음은 실제로 File 객체로 변환된 데이터를 S3 적재하는 로직입니다.
//s3에 적재될 유니크한 파일 이름
String saveFileName = generateUniqueFileName(file.getName());
//실제 파일 이름.
String orginFileName = file.getOriginalFilename();
//업로드될 버킷 PATH
String bucketPath = attachmentType.getType() + "/" + userId + "/" + mappedId + "/" + saveFileName;//적재할 경로 세팅
어려운 로직은 아니였지만 고민을 오래했던것 같습니다.![]
업로드에서 끝나는것이 아닌 사용자들의 이미 업로드한 피드,리뷰에 대해수 수정,삭제에 대한 예외도 고려했어야 했습니다.
고려했어야할점
- 만약 사용자가 동일한 이름의 파일을 여러개 올린다면 서버에서는 어떻게 구분할까?
- 만약 사용자가 리뷰를 수정할때 업로드한 이미지를 삭제한다면?
- 다른 사용자들이 올린 이미지 이름과 용량마저 다 똑같은 파일이 업로드된다면?
고민끝에 버킷에 업로드되는 객체의 파일이름을 UUID를 통해 유니크한 이름으로 변경하고 적재하는 방법을 선택했고 적재 경로를 "업로드타입/유저아이디/리뷰게시글아이디/유니크파일명" 으로 결정을 하게되었습니다.
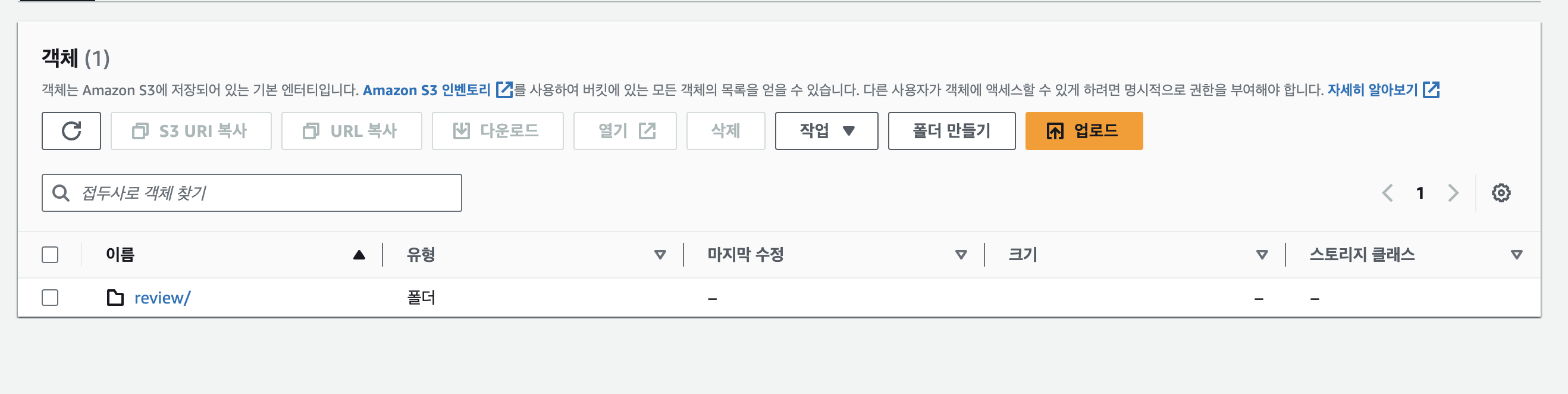
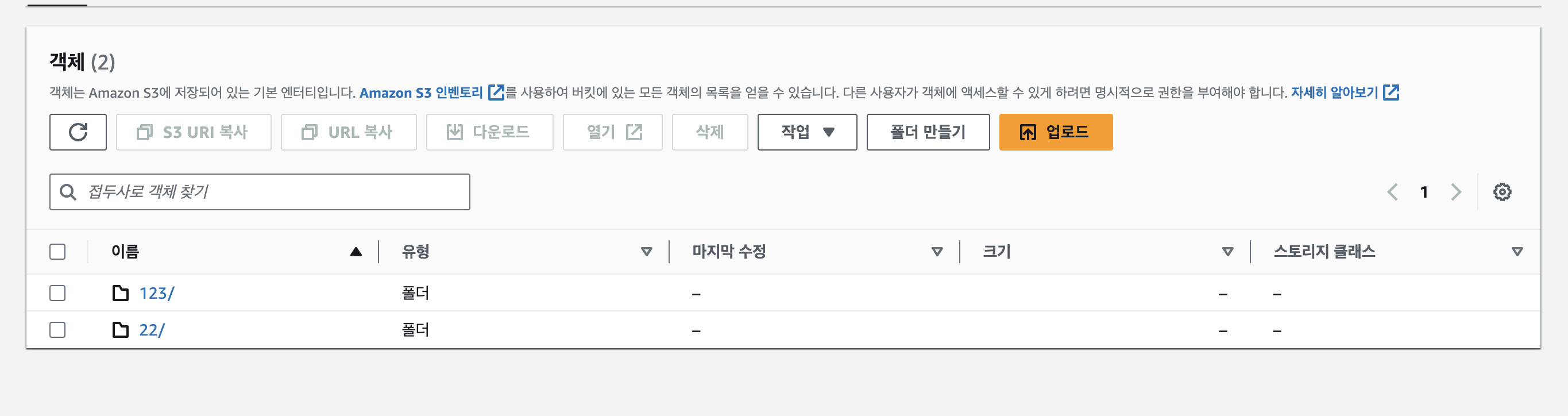
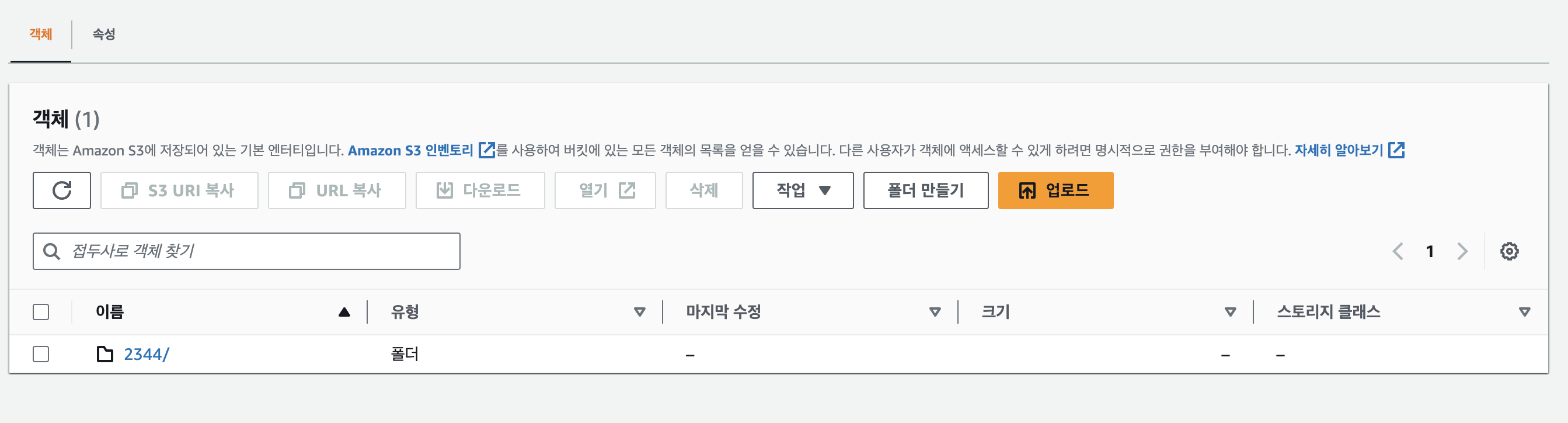
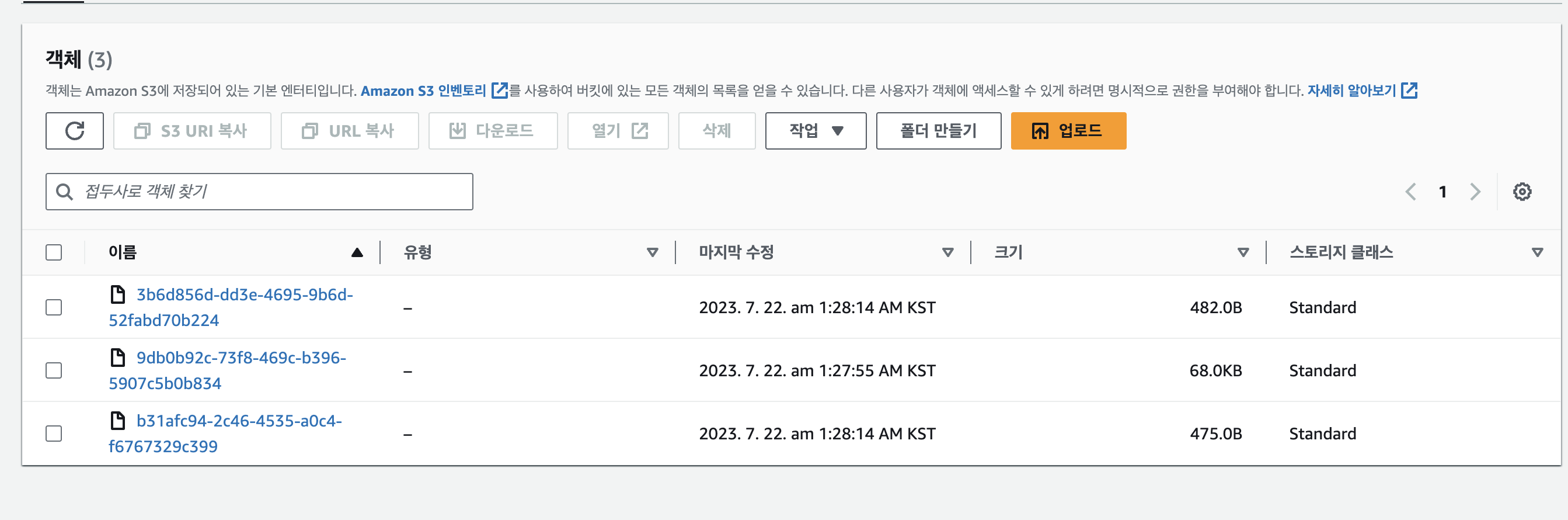
그리고 동시에 데이터베이스에는 해당 리뷰아이디와 파일의 실제 이름, 버킷에 적재된 이름 등을 맵핑시켜 클라이언트 요청에도 문제가 없도록 처리했습니다.
사용자는 서버로 리뷰 아이디만 요청하면 업로드된 URL 주소를 알 수 있습니다.
https://flambus-bucket-korea.s3.ap-northeast-2.amazonaws.com/review/22/2344/1f72e22b-2c16-426b-a0ce-facbba58d2a1

SaveDB 함수
'이미 해당 리뷰 또는 피드에 업로드된 이미지가 있는 경우, 모두 삭제'를 진행하는 이유는
사용자가 리뷰나 피드를 수정했을때 새로운 이미지를 추가했는지 삭제했는지 구분하기 번거롭기때문에 수정될경우 해당 폴더 자체를 지우고 새로 업로드 하는 로직으로 구현했습니다.
구현속도나 따로 처리해야될 부분은 많이 줄었으나, 단점은 피드나 리뷰의 글만 수정해도 첨부파일이 있다면 해당 이미지는 삭제되고 서버쪽에 재업로드된다는 단점이 있겠습니다.
개선해야지..
/**
* @title S3에 적재된 파일과 맵핑 정보를 데이터베이스에 저장합니다.
* @param saveImageData 맵핑된 이미지 정보.
* @param attachmentType
* @param mappedId
* @return List<Map<String, Object>>
*/
private List<Map<String, Object>> saveDB(List<UploadImage> saveImageData, AttachmentType attachmentType, long mappedId) {
List<UploadImage> existingImages = uploadRepository.findByAttachmentTypeAndMappedId(attachmentType.getType(), mappedId);
// 이미 해당 리뷰 또는 피드에 업로드된 이미지가 있는 경우, 모두 삭제
if (!existingImages.isEmpty()) {
uploadRepository.deleteAll(existingImages);
}
// 새로운 이미지들을 저장
List<UploadImage> savedImages = uploadRepository.saveAll(saveImageData);
// 저장된 이미지들의 정보를 결과 리스트에 추가
List<Map<String, Object>> results = new ArrayList<>();
for (UploadImage savedImage : savedImages) {
Map<String, Object> image = new HashMap<>();
image.put("fileName", savedImage.getFileName());
image.put("imageUrl", savedImage.getImageUrl());
results.add(image);
}
return results;
}uuid를 활용해 유니크 파일명을 생성하는 함수
/**
* @title 파일이름이 겹치지 않기 위한 유니크한 파일 이름을 만들어주는 함수.
* @param originalFileName 업로드하는 파일의 원본 이름
* @return uuid
*/
private String generateUniqueFileName(String originalFileName) {
String extension = "";
int lastDotIndex = originalFileName.lastIndexOf(".");
if (lastDotIndex >= 0) {
extension = originalFileName.substring(lastDotIndex);
}
// UUID를 사용하여 랜덤값을 생성하고, 확장자와 합쳐서 고유한 파일 이름을 생성
String uniqueID = UUID.randomUUID().toString();
return uniqueID + extension;
}파일의 타입과 업로드 타입등을 Enum으로 관리해보자
관리를 용이하게 하기위해 2가지의 Enum Class를 생성해서 관리했습니다.
AttachmentType 은 사용자가 업로드하는 이미지가 "리뷰" 인지 "피드" 인지 아니면 추후 추가될 어떤 것 인지에 따라 DB에 AttachmentType별로 다르게 적재합니다.
AttachmentType.java
public enum AttachmentType {
REVIEW("review"),
FEED("feed");
// 추후에 추가될 다른 업로드 타입들
private final String type;
AttachmentType(String type) {
this.type = type;
}
public String getType() {
return type;
}
public static AttachmentType fromString(String text) {
for (AttachmentType uploadType : AttachmentType.values()) {
if (uploadType.type.equalsIgnoreCase(text)) {
return uploadType;
}
}
throw new IllegalArgumentException("Invalid uploadType: " + text);
}
}
FileType.java
FileType.java 는 사용자가 업로드하는 파일객체의 확장자의 따라 용량과 타입을 반환합니다.
또한 파일 타입을 체크하는 요소들이 업로드,다운로드 간 여러곳에서 사용되고 있었습니다.
public enum FileType {
ZIP("application/zip", 100 * 1024 * 1024), // 100MB
PNG("image/png", 10 * 1024 * 1024), // 10MB
JPEG("image/jpeg", 20 * 1024 * 1024), // 20MB
PDF("application/pdf", 50 * 1024 * 1024); // 50MB
private final String contentType;
private final long maxSize;
FileType(String contentType, long maxSize) {
this.contentType = contentType;
this.maxSize = maxSize;
}
public String getContentType() {
return contentType;
}
public long getMaxSize() {
return maxSize;
}
public static FileType fromContentType(String contentType) {
for (FileType type : FileType.values()) {
if (type.getContentType().equals(contentType)) {
return type;
}
}
return null; // 해당 contentType이 없으면 null 반환 or 예외 처리
}
}
두가지를 분리한 이유는 지속적으로 추가,삭제,변경이 될 수 있는 부분인거같아서 관리를 용이하게 하기 위해 Enum을 사용했습니다.
참고 문서는 동욱님이 배민시절 올리신 우테크 블로그 글을 참고했습니다.
https://techblog.woowahan.com/2527/
테스트 요청
테스트를 위해 두가지 컨트롤러를 미리 작성했습니다.
첫번째는 디비에 맵핑된 ID로 이미지를 요청
두번째는 업로드 타입과 타입의 ID로 요청(4번 리뷰의 데이터를 불러오겠음 등)
@GetMapping("/image/{id}")
public ResultDTO<UploadImage> getImageById(@PathVariable Long id) {
try{
Optional<UploadImage> image = uploadService.getImageById(id);
if (!image.isPresent()) {
return ResultDTO.of(ApiResponseCode.SUCCESS.getCode(), ApiResponseCode.SUCCESS.getMessage(), null);
} else {
return ResultDTO.of(ApiResponseCode.SUCCESS.getCode(), ApiResponseCode.SUCCESS.getMessage(), image.get());
}
} catch(NullPointerException error) {
Optional<UploadImage> image = uploadService.getImageById(id);
return ResultDTO.of(200,"success",image.get());
}
}
@GetMapping("/image/{attachment}/{mappedId}")
public ResultDTO<List<UploadImage>> getImageByAttachmentType(
@PathVariable String attachment,
@PathVariable long mappedId) {
List<UploadImage> results = uploadService.getImageByAttachmentType(AttachmentType.fromString(attachment),mappedId);
return ResultDTO.of(ApiResponseCode.SUCCESS.getCode(), ApiResponseCode.SUCCESS.getMessage(), results);
}UploadService.java
해당 요청의 대한 로직은 JPA로 간단하게 구현했습니다.
/**
* @title AttachmentType에 맞는 이미지 데이터를 반환합니다.
* @param attachmentType {"reivew","feed"}
* @param mappedId {"reviewId","feedId"}
* @return [data]
*/
public List<UploadImage> getImageByAttachmentType(AttachmentType attachmentType, long mappedId) {
List<UploadImage> byAttachmentTypeAndMappedId = uploadRepository.findByAttachmentTypeAndMappedId(attachmentType.getType(), mappedId);
return byAttachmentTypeAndMappedId;
}
/**
* @title Image pk를 통한 이미지 데이터 반환
* @param id : db pk
* @return
*/
public Optional<UploadImage> getImageById(Long id) {
return uploadRepository.findById(id);
}
결과
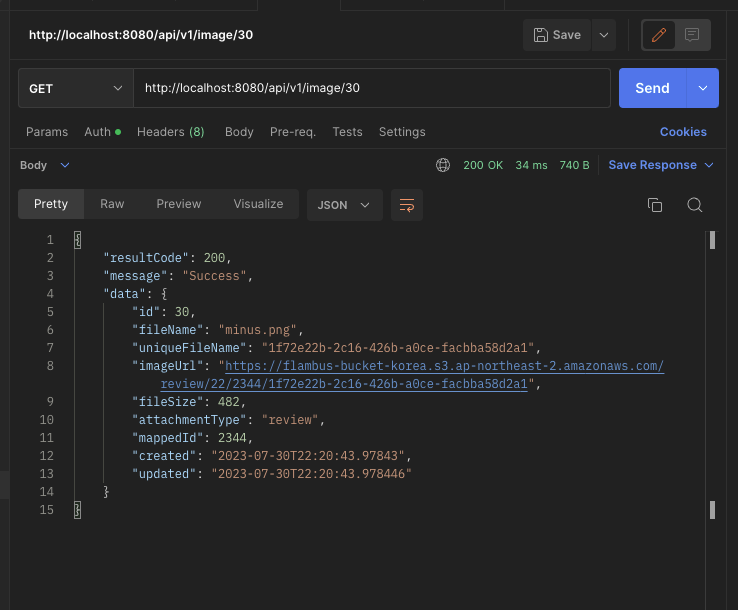
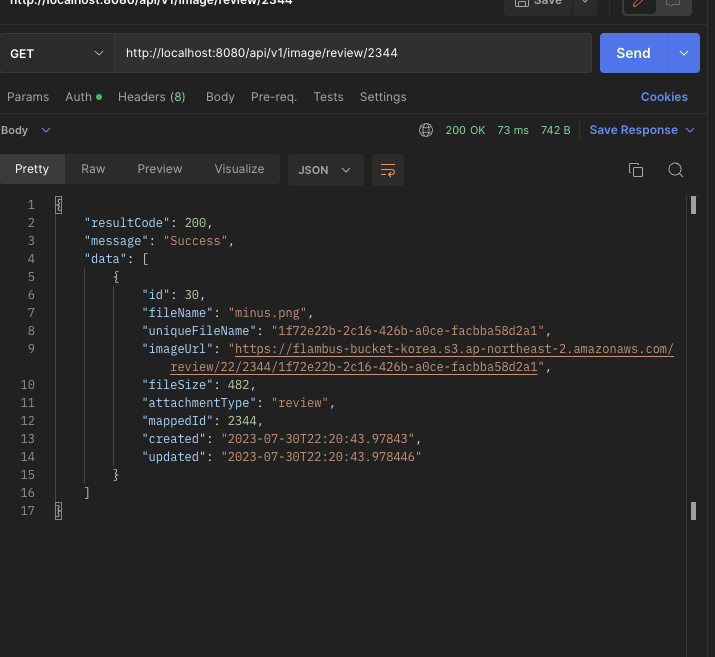
리뷰나 피드관련 API가 개발되야지 사용을 해볼 수 있겠지만, 현재까지는 만족스러운것 같습니다.
하지만 개발하면서 보안이나 구조적으로 문제가 없을까 하는 고민은 계속 했던것 같습니다.
실제 실무에서 30GB 이상의 파일을 업로드도 가능했고, 실시간 업로드 상황도 알아야했기때문에 버킷과 서버간의 중간에서 유효성을 검증해주는 소켓 파일서버가 있었지만, 이번에 사용하는 업로드는 간단한 이미지 정도로 따로 중계 소켓파일서버를 개발하지는 않았습니다.
서비스 로직이 수정되거나 개발중에 아키텍쳐가 바뀌면 왜 바뀌었는지를 비롯해서 어떤 부분이 문제 였는지 또 남겨보면 좋은 경험이 될 것 같습니다.
일부 핵심 코드만 올렸지만 사용한 전체 코드를 확인하여 사용하실 분들은 아래 링크를 참고해주세요
https://github.com/explorer-cat/flambus-v1.0-springboot
