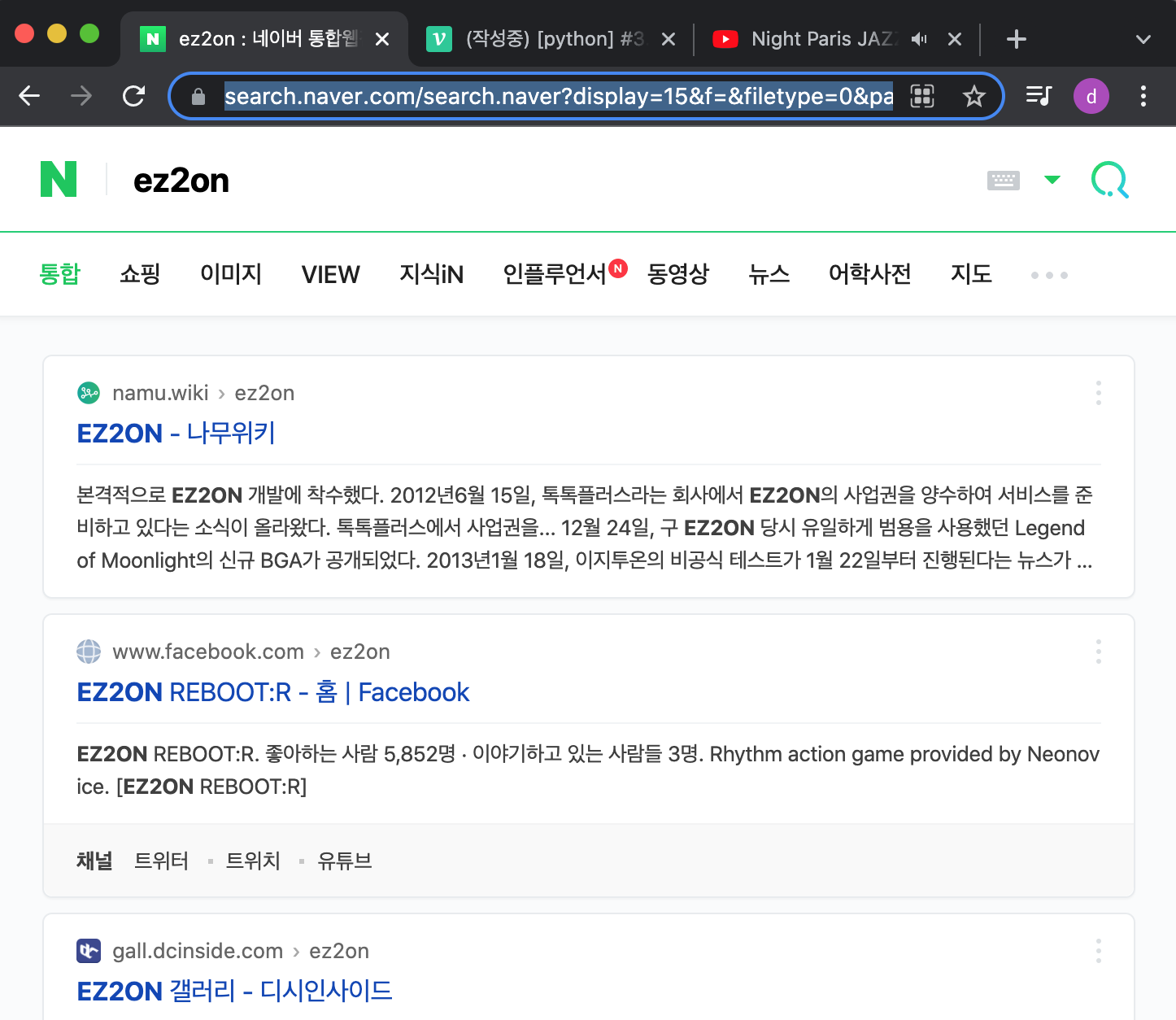
첫 목표는 네이버 검색화면
- 난 리듬게임을 좋아하니 검색어에 이지투온을 검색해 보겠다.
-
여기서 뭘 뽑아낼지를 고민한다. 난 어디까지나 텍스트 자료수집과 웹사이트 정보를 목적으로 하니 제목과 접속 URL을 취득하도록 하겠다.
-
개발자 도구를 연다(맥OS의 경우 Option+command+I)
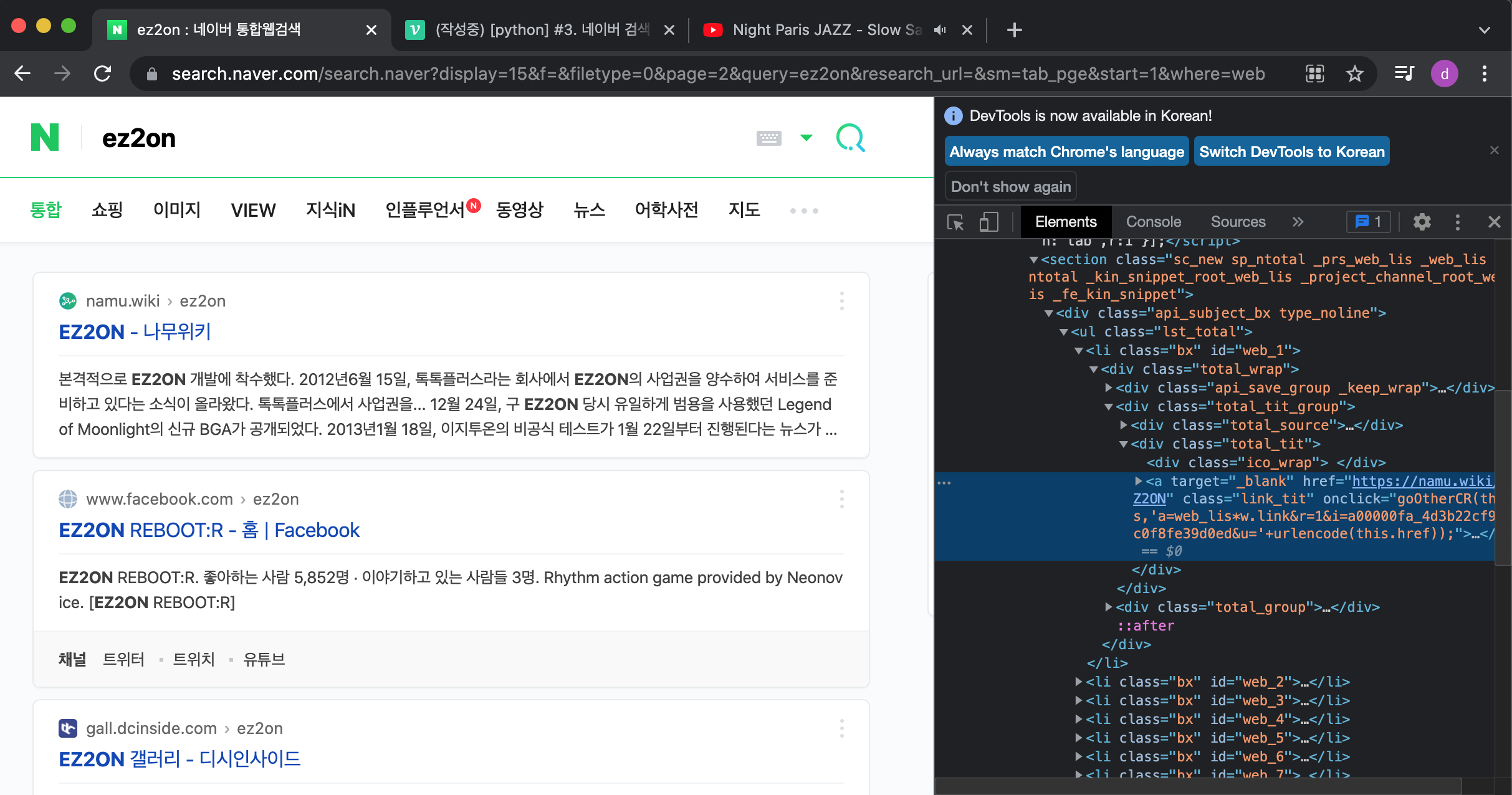
-
내가 원하는 정보가 어디에 있는지 엘리먼트 셀렉터로 찍는다.
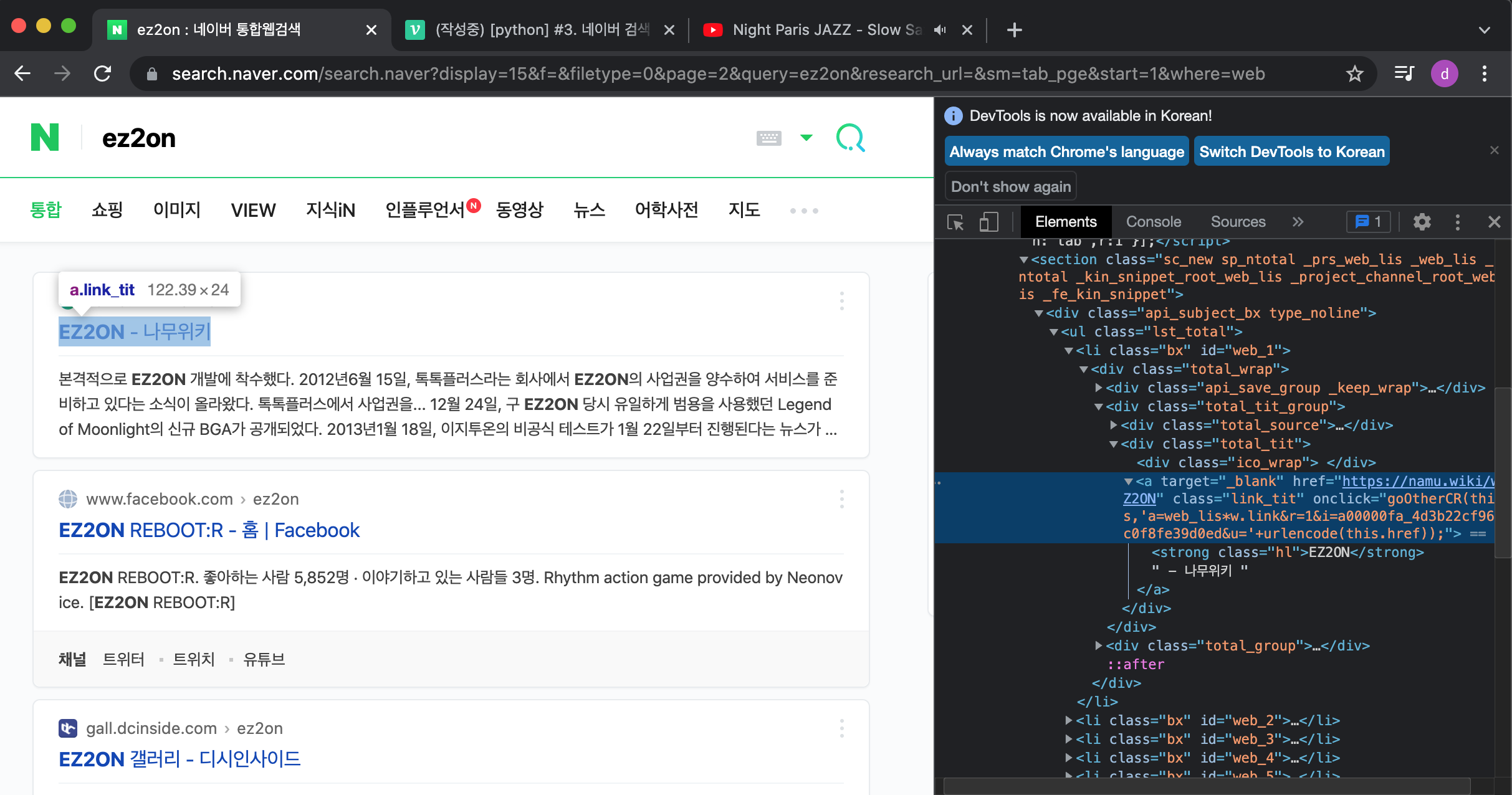
여기부터는 웹 기본 지식이 필요
- 문제는 이렇게 생겨먹은 제목이 여러개가 있다는 점이다. Jquery("셀렉터").each() 와 아주 유사하게 이것도 엘리먼트 셀렉터를 이용한다.
req = requests.get("https://search.naver.com/search.naver?display=15&f=&filetype=0&page=2&query=ez2on&research_url=&sm=tab_pge&start=1&where=web")
soup = BeautifulSoup( req.text.replace('\\', ''), 'html.parser')
# a 태그인데 class가 link_tit 인 것을 찾아라
selected = soup.select("a.link_tit")
print(type(selected))
<!-- selected의 데이터 타입... -->
<class 'bs4.element.ResultSet'>-
selected 데이터는 아래와 같이 모든 a.link_tit 의 contents 이다. 너무 많아서 이미지로 대체한다.

-
그럼 어떻게 제목과 URL만?
for item in selected :
print(" ".join(item.strings)+":"+item['href'])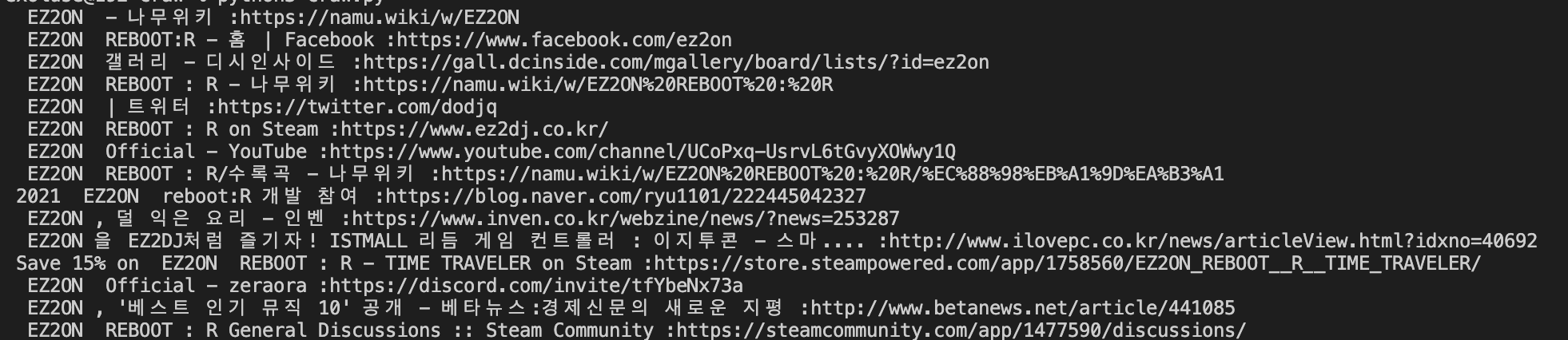
참 쉽죠?^_^

뭐래 ㅋ
해설은 이러하다.
# ResultSet 타입의 selected 돌리기 시작
for item in selected :
# 출력
# " ".join(item.strings) : a 태그 안의 문자열을 " "로 합쳐서 모두 표시
# item["href"] : a 태그의 href 속성을 취득
print(" ".join(item.strings)+":"+item['href'])다음 포스팅에서는
아직 뭘할지 모른다 ㅋ BeautifulSoup 공식문서 공부 하면서 강의 들으면서 필요한게 생기면 또 포스팅 하겠다. 끝

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.