웹 크롤링을 위한 준비물
- BeautifulSoup 설치
pip install bs4- requests 설치
pip install requests필요 라이브러리 import
import requests
from bs4 import BeautifulSouprequests 로 URL 접속
req = requests.get("https://finance.naver.com/item/main.naver?code=035720");접속한 웹사이트의 컨텐츠 취득
soup = BeautifulSoup(req.content, 'html.parser')요소 선택 이게 중요함.
-
먼저 뭘 선택할지 개발자도구로 확인
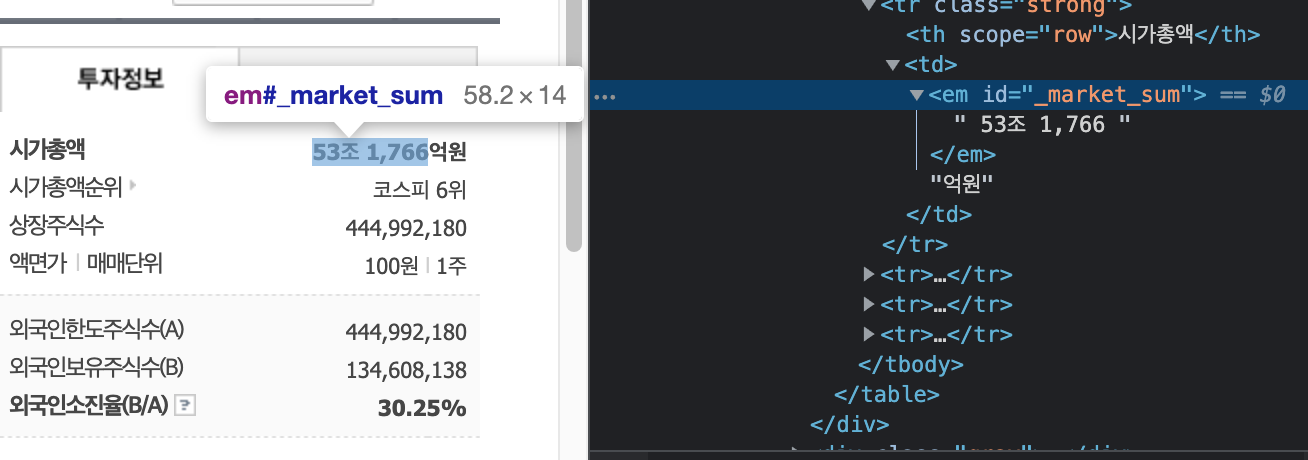
-
셀렉터를 작성 (이게 매우 중요하다.)
text1 = soup.select("#_market_sum")[0].text;-
공식 문서의 셀렉터 부분을 참고하면 될거 같다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/ -
한글 문서도 있다
https://www.crummy.com/software/BeautifulSoup/bs4/doc.ko/ -
확인 (한글이 꺠져 보인다. 확인이 필요함...)
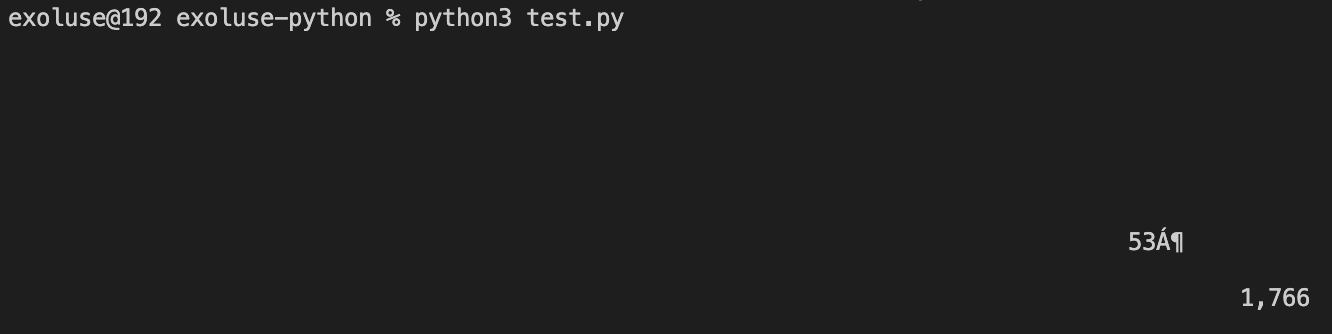
전체 소스는 이러하다
#-*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
req = requests.get("https://finance.naver.com/item/main.naver?code=035720");
soup = BeautifulSoup(req.content, 'html.parser')
text1 = soup.select("#_market_sum")[0].text;
print(text1)처음으로 접해본 크롤링
확실히 매력적인 기능이다. 직접 웹사이트에 들어가지 않아도 URL과 특정 요소의 셀렉터만 가지고 컨텐츠를 끌고 올수 있다는건 흥미롭다. 하지만 과도한 크롤링은 접속 차단을 유발하므로 남발은 금하자. 끝

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.