오늘 제가 리뷰할 논문은 2022년 CVPR에 기재 된 Unified Transformer Tracker For Object Tracking 입니다. https://arxiv.org/abs/2203.15175
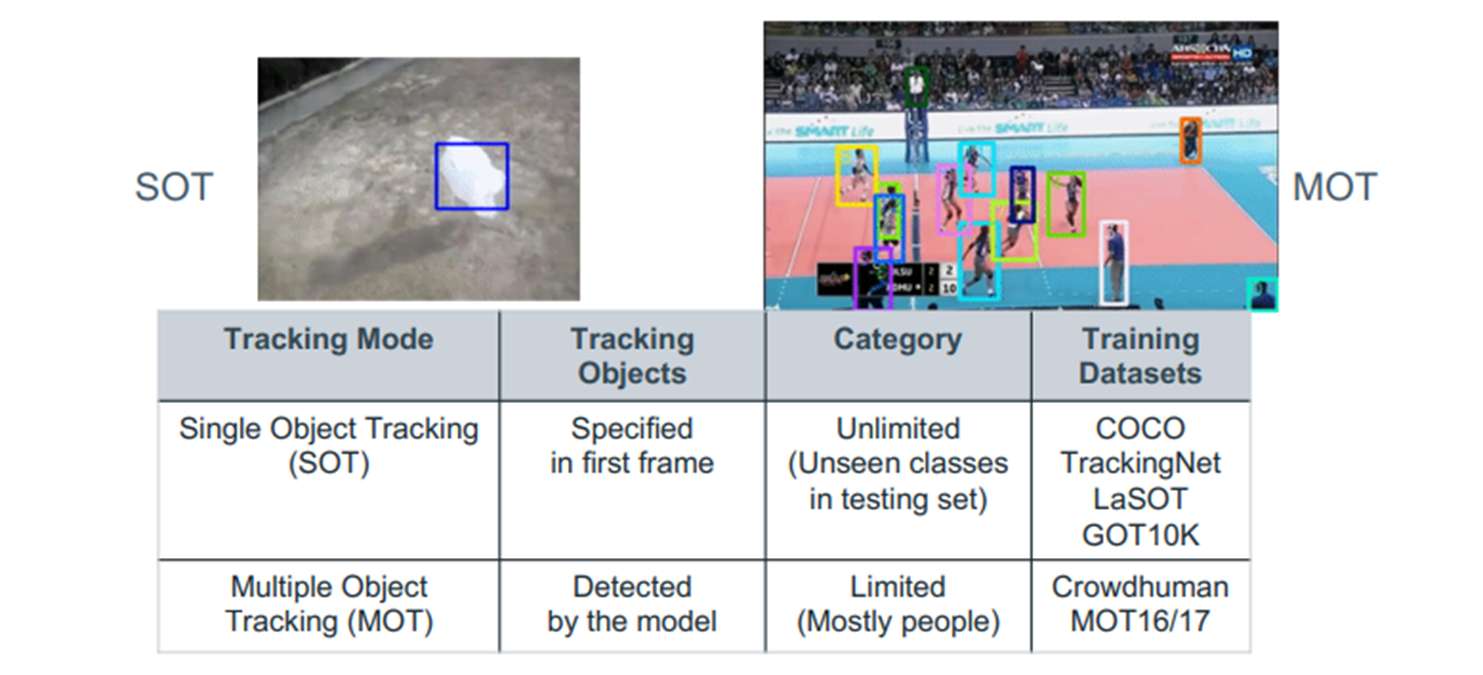
Visual Tracking은 크게 두 가지로 나뉩니다. 하나는 Single Object Tracking 나머지는 Multiple Object Tracking입니다. 이 두 분야는 독립적으로 연구 되어 왔습니다. 그러다 두 가지를 모두 수행 할 수 있는 UniTrack 모델이 최초로 제시 되었고 이 논문에서는 Transformer를 이용해 SOT와 MOT를 모두 수행할 수 있는 아키텍처를 제안합니다.
Background-1
제가 처음에 SOT와 MOT가 독립적으로 연구 되어왔다고 말했는데요. 그 이유는 SOT와 MOT가 차이가 있기 때문입니다.
-
SOT의 경우는 초기 frame만을 가지고 Sequential frame에서 object를 추적하는 것이 목적이고 테스트 dataset의 class는 제한이 없습니다. SiamFC나 DCFNet처럼 initial frame을 template으로 두고 search frame과의 correlation을 계산해 객체를 추적하는 모델이 나온 배경도 이것입니다.
-
MOT의 경우는 Class가 정해져 있고(대부분 사람) frame 속에서 탐지하고 추적해야 할 object가 가변적입니다. MOT의 목표는 새롭게 추가되는 객체를 탐지하고 이전 프레임의 객체가 현재 프레임에 어디에 있는지 추적하는 것입니다. UniTrack의 경우는 Detection head를 추가해 SOT와 MOT 모두에서 사용할 수 있는 모델을 만들었는데요. UTT 또한 Detection head를 추가했습니다.
Background-2
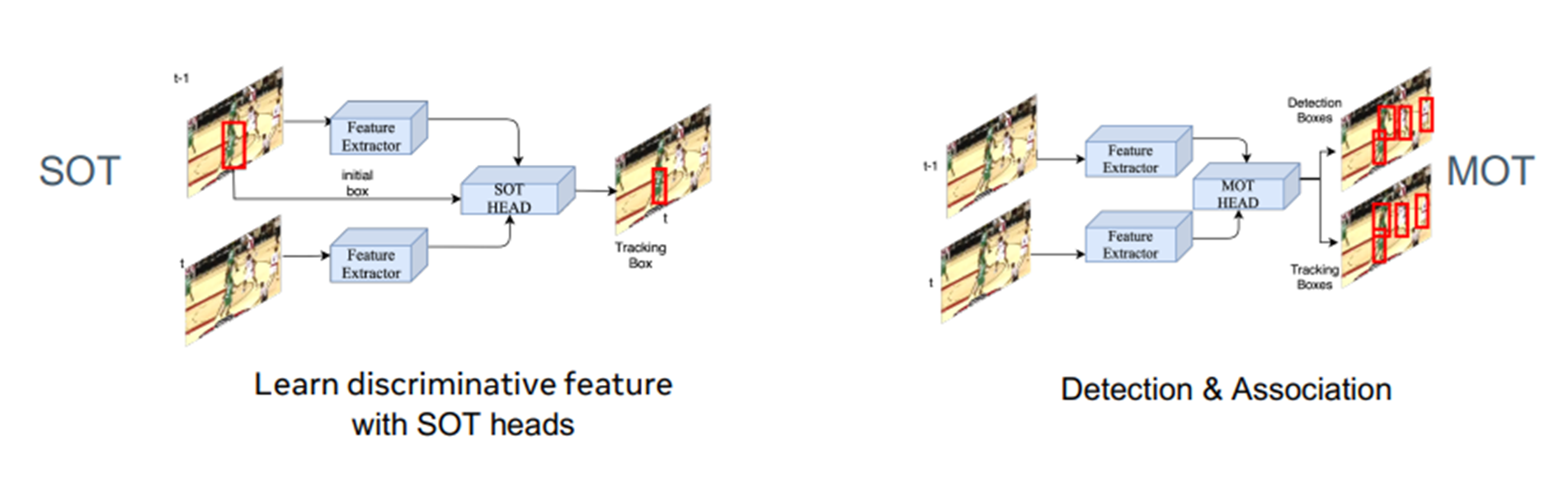
SOT와 MOT에 쓰이는 모델의 기본 골격은 Siamese 형태입니다. (썀상둥이라고 하죠) SOT의 SOTHEAD는 initial frame에서 주어진 객체가 현재 어디 있는지 추적합니다.SOT에서 correlation 기반의 알고리즘들은 SOTHEAD가 correlation filter가 됩니다. MOT의 경우는 MOT HEAD에서 새로 추가된 객체를 탐지하고 이전 프레임에 있었던 객체가 현재 어디에 있는지 추적하는 기능을 수행합니다.
Motivation
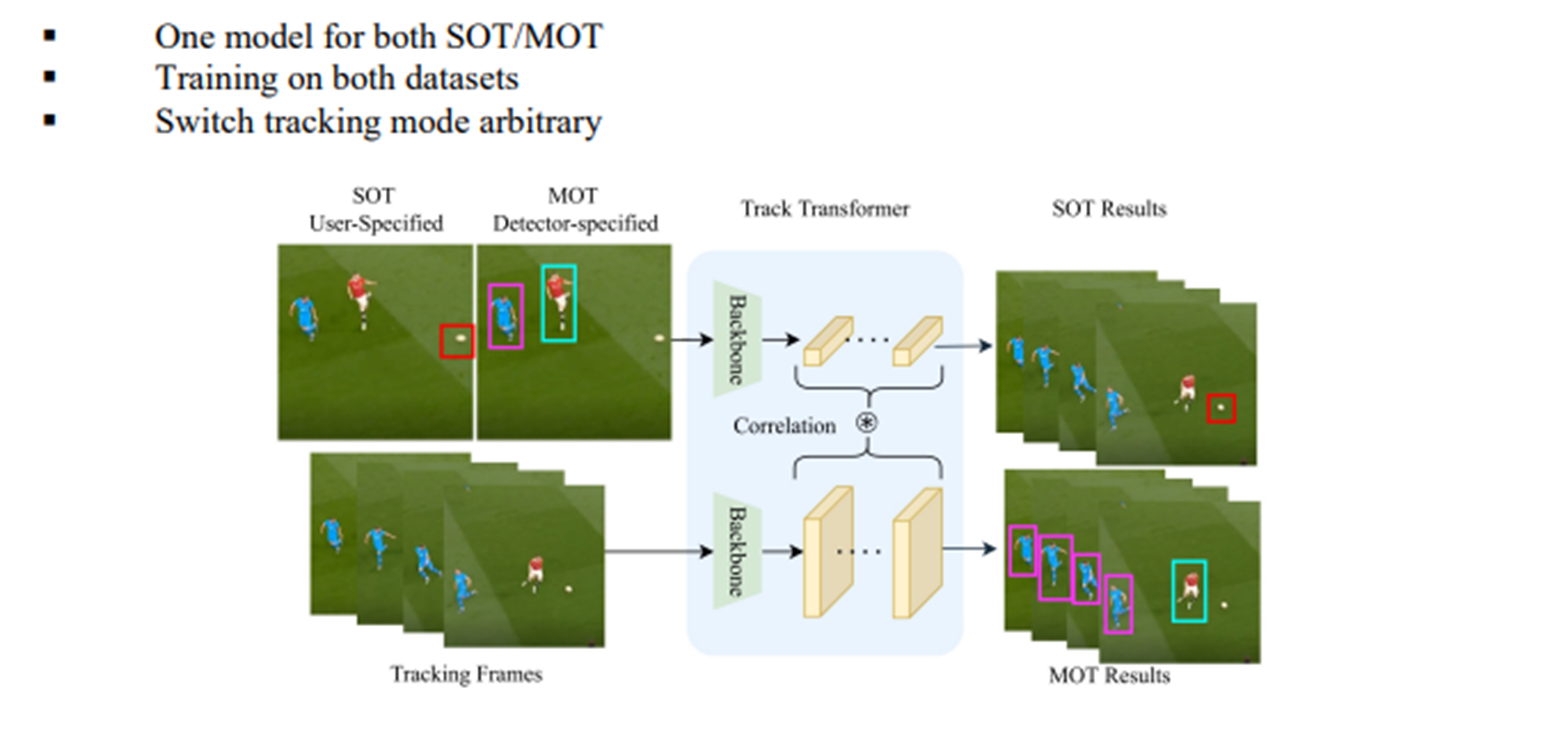
UTT의 아이디어는 Reference 와 Tracking Frames로부터 Target representation과 Target Proposal 정보를 추출한 후 Target Transformer에서 Correlation 연산을 통해 Object의 위치를 예측하자는 것입니다.
Unified Transformer Network For Object Tracking
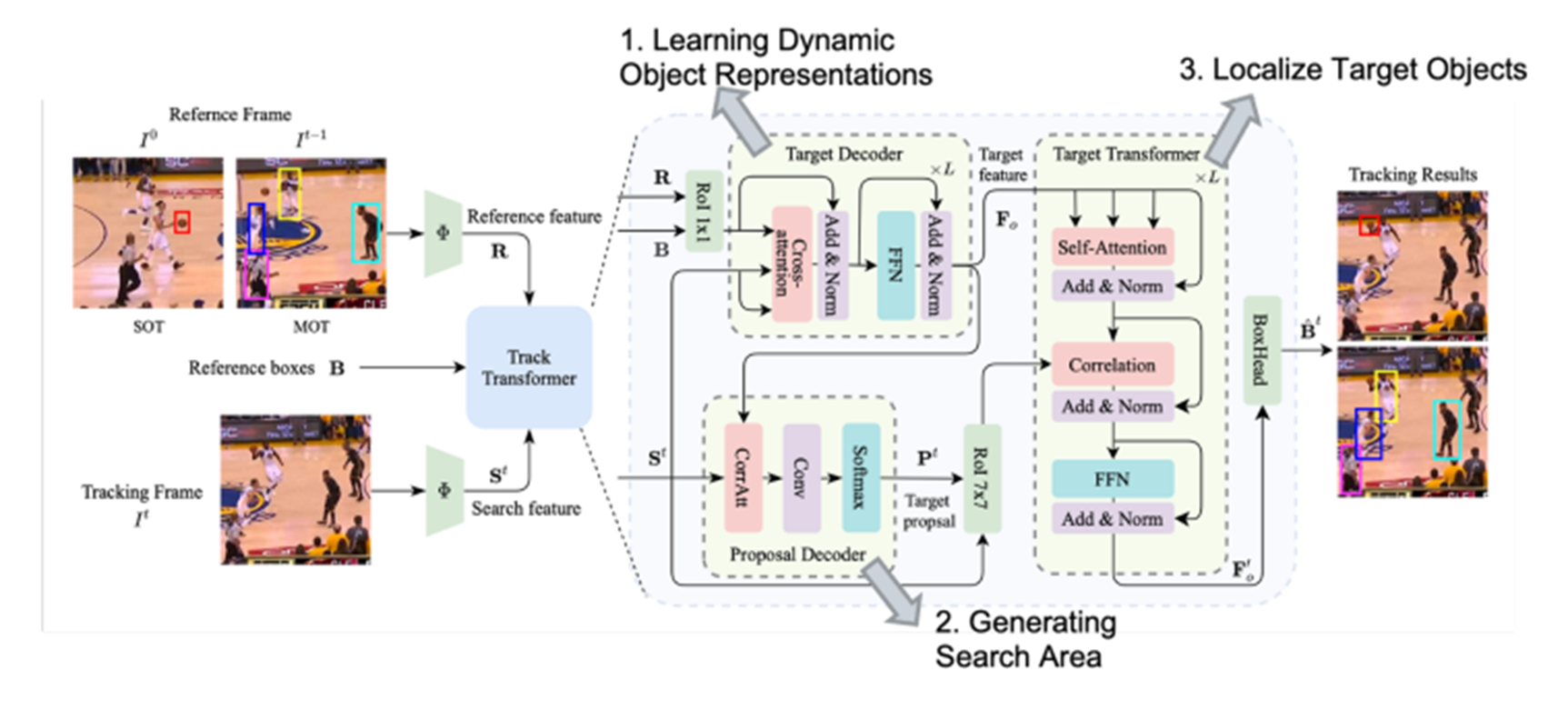
SOT 와 MOT를 동시에 수행하는 모델은 UniTrack이 최초입니다. 하지만 UniTrack의 경우는 backbone은 sharing하지만 SOT와 MOT를 수행하는 task head는 독립적으로 구성했습니다. 이 때문에 각 task head가 다른 task dataset에 학습이 가능한 지에 대해 논란이 있고 또한 성능이 각 task의 SOTA모델에 크게 뒤떨어집니다. 반면 UTT는 하나의 tracking head가 SOT MOT 작업을 모두 수행합니다. 먼저 target decoder로부터 target feature를 추출합니다. 그리고 proposal decoder에서 search area를 정하는데 필요한 proposal 정보를 추출합니다. 이것을 통해 연산이 줄어들어 빠른 tracking이 가능합니다. Target feature와 proposal 정보를 얻었다면 이것들을 target transformer에 집어 넣어 현재 frame에서 localization을 예측합니다.
Target Decoder
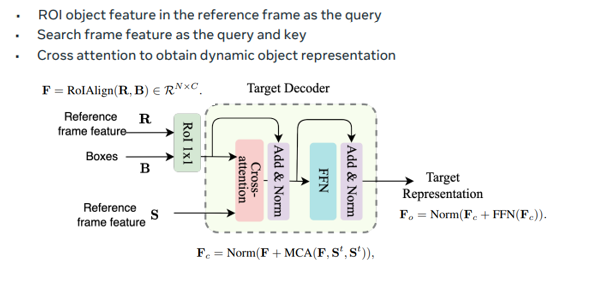
Target Decoder에서는 Target representation 정보를 추출합니다. UTT의 핵심 아이디어는 Reference 정보를 모델에게 주는 것이라고 하였습니다. Reference 정보를 어떻게 주면 될까요? N개의 object에 대한 feature map을 RoIAlign형식으로 tensor를 구성해서 모델에게 주면 됩니다. 그런데 이것 만으로는 충분하지 않습니다. Visual Tracking은 주위 배경 정보 또한 아주 중요합니다. 왜냐하면 객체들이 비슷하게 생겼다면 그것을 구분할 수 있는 단서는 주위 배경 정보기 때문입니다. Context information을 주기 위해서 이 연구에서는 Multi-head Cross Attention을 추가했습니다. F가 query 이고 search frame feature가 key,value 역할을 합니다.
Proposal Decoder
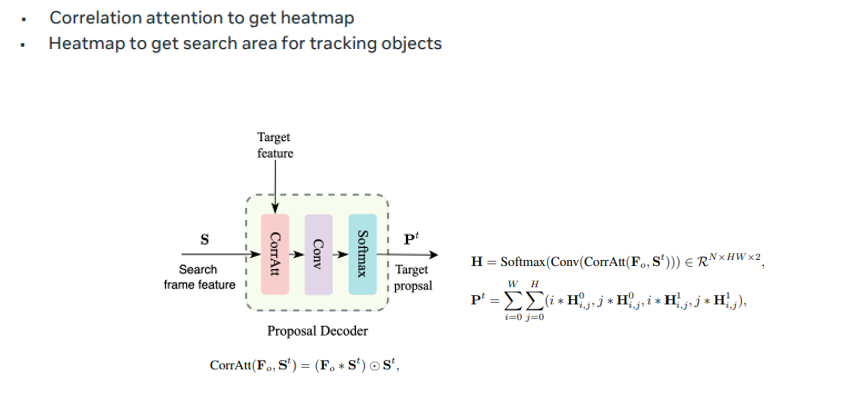
Proposal Decoder는 Search area 정보를 만드는 Decoder입니다. 만약 resolution이 크거나 large-scale video인 경우 전체 영역에서 객체를 찾으며 계산량이 매우 많겠죠? 그래서 현재 객체가 있을 법한 지역을 추립니다 Proposal Decoder를 Heap map H를 반환하는데 top-left 와 bottom right 좌표의 확률적 분포를 나타냅니다
이것으로 Target Reprentation 과 Proposal 정보를 추출했습니다. 이제 이 정보들을 Track Transforemr에 넣으면 됩니다.
Track Transformer
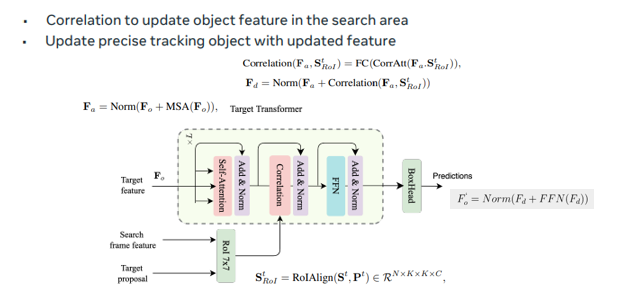
Track Transformer의 특징은 Target representation 정보를 self-attention 연산을 거친 후 Search frame feature과 Target proposal의 roi로 만들어진 텐서와의 correlation 연산을 수행합니다. 이렇게 최종 결과물이 나오고 이것을 토대로 task head 가 MOT나 SOT task를 수행합니다.
Training

UTT는 SOT MOT dataset을 번갈아 가면서 총 800,000 번의 iteration을 거쳐 학습했습니다.

우선 SOT Iteration을 살펴봅시다.
- 먼저 을 수행하는데요. 이것은 Test Decoder의 Target Representation 을 학습시키기 위해 Multi-head Cross Attention을 Self-Attention으로 학습시킨다는 의미입니다. 초기에 정의된 모델은 사물 자체의 representation learning 능력이 떨어지기 때문에 우선 스스로 tracking하는 것으로 representation 을 학습합니다.
- 그 다음 을 통해 객체의 위치를 Prediction 합니다.
- Loss는 와 ground truth 의 차로 구합니다. 는 IoU loss를 의미하고 은 1-norm loss를 의미합니다. loss는 이 두가지 loss의 가중치 합으로 구성합니다. 그리고 앞에 는 reference frame으로 부터의 self-attention과 tracking loss를 모두 loss로 사용한다는 의미입니다.

- MOT는 SOT와 달리 Detection 과정이 더 필요하다고 설명했습니다.
- 로 detection 모델이 classification을 수행하고 Loss 값을 계산합니다. 이 연구에서는 Detection Model로 DETR을 사용했고 Loss function은 DETR에서도 사용했던 Hungarian Loss입니다.
- 로 Prediction을 수행합니다.
- Prediction Loss는 SOT의 두번째 Loss와 동일합니다.
- MOT의 최종 Loss는 Prediction Loss와 Detection Loss의 합으로 정의합니다.
Compared to SOTA
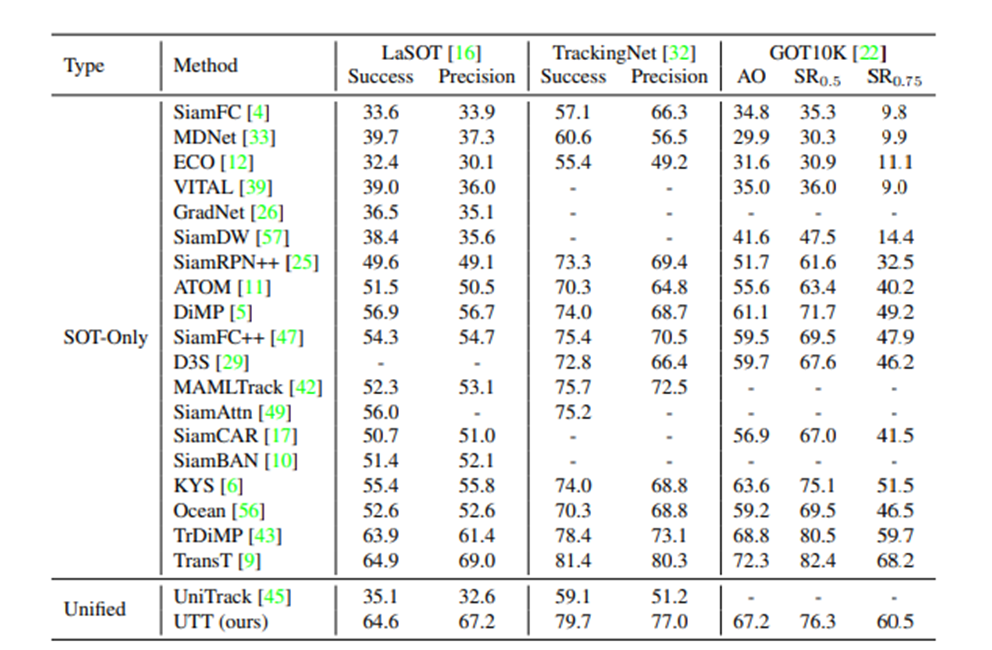
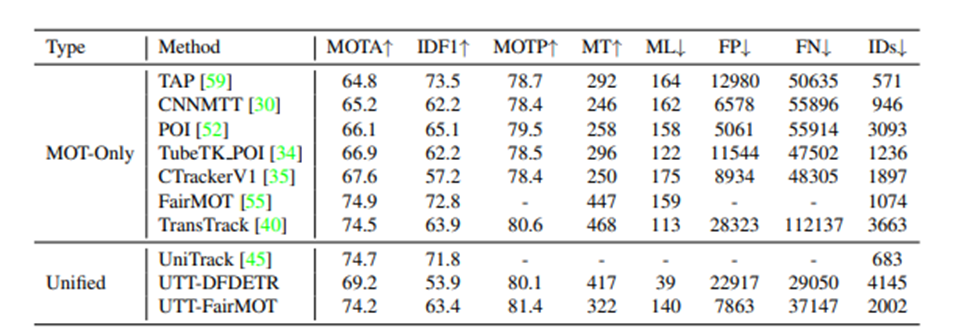
UniTack보다 성능이 월등히 좋은 것을 확인할 수 있습니다. 또한 SOT MOT의 SOTA 모델과 성능을 비교했을 때 거의 비슷한 성능을 내고 있는 것을 확인할 수 있습니다.
이상으로 Unified Transformer Tracker for Object Tracking 를 마치겠습니다.
