강화학습 시리즈는 패스트캠퍼스 박준영 강사의 수업과 Sergey Levine의 Deep Reinforcement Learning 그리고 서튼의 강화학습 교재를 참고하여 만들어졌고 어떤 상업적 목적이 없음을 밝힙니다.
Review
우리는 이전 시간에 MDP를 정의했고 최적 정책과 최적 가치 함수에 대해서 살펴 보았다. MDP의 원래 목표는 누적 보상의 최대화 하는 것이다. 하지만 MDP 환경이 Stochastic하기 때문에 누적 보상의 기댓값 즉 가치 함수를 최대화 하는 것으로 바뀐다. 이게 직관적으로 이해하기 어려울 수 있는데 우리가 일상 생활에서 어떤 선택을 할 때 이 것을 했을 때 내가 겪게 될 미래를 계산하는데 이 과정이 어떤 행위에 대한 가치 함수를 따져 정책을 개선하는 과정이랑 동일하다.
정리하면 MDP의 목표는 최적 가치 함수를 찾는 것인데 이것은 최적 정책을 찾으면 해결 된다.
오늘 이 시간에는 MDP의 근간을 이루는 아이디어인 Dynamic Programming에 대해서 알아 볼 예정이다.
강화학습 문제
강화학습 문제를 풀었다는 것은 MDP를 풀었다는 말이고 이것은 최적 정책 를 찾았다는 것을 의미한다.
강화학습 문제를 풀었다 = MDP를 풀었다. = 를 찾았다.
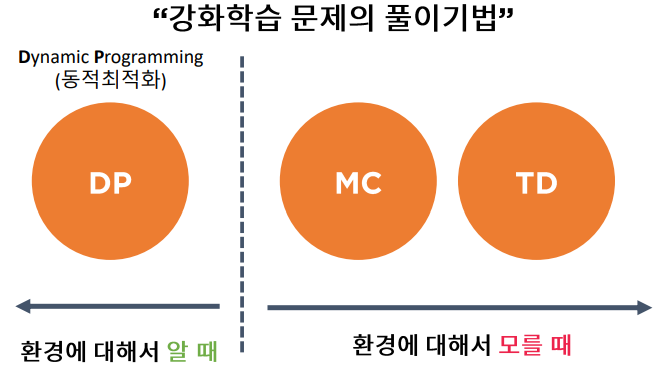
강화 학습을 문제를 푸는 기법은 Agent가 환경에 대해서 알고 있는 유무에 따라서 두 가지로 나뉜다. (환경을 안다는 것은 상태천이 행렬에 대해서 알고 있음을 의미한다.)
강화학습 문제의 풀이 기법
환경에 대해서 알 때:Dynamic Programming
환경에 대해서 모를 때: MC(Monte Carlo),TD(Temporal Difference)
동적 계획법
동적 계획법
복잡한(큰) 문제를 작은 문제로 나눈 후 작은 문제의 해법을 조합해 큰 문제의 해답을 구하는 기법의 총칭
동적 계획법으로 해결할 수 있는 문제는 다음과 같은 특징을 가진다.
최적 하위구조 (Optimal Substructure)
- 하위 문제의 최적은 큰 문제에서도 최적이다.
중복 하위문제(Overlapping Problems)
- 큰 문제의 해를 구하기 위해서, 작은 문제의 최적 해를 재사용.
최적 정책 각 상태에서 가장 Q가 큰 값을 선택하는 것이고 이는 각 state(최적 하위구조)의 해답을 계속 누적해(중복 하위문제) 최적 정책 가 만들어짐을 의미한다. 그러므로 MDP 문제는 Dynamic Programming이 해결할 수있는 문제에 속한다. (환경이 알려져 있을 때)
정책 평가과 정책 개선
Dynamic Programming을 이용하여 MDP를 푸는 과정은 정책 평가와 정책 개선 순서로 진행된다. 정책 평가는 쉽게 말해 V값을 갱신하는 것이고 정책 개선은 갱신된 가치값을 토대로 Policy를 갱신하는 것이다. 이 일련의 과정을 거치면 V와 Q는 최적 가치로 반드시 수렴하는데 이것은 바나흐의 고정점 정리로 보장된다.
정책 평가(Policy Evaluation)는 반복적인 과정을 통해 Bellman 기댓값 방정식의 최적해를 구하는 방법 중 하나이다.
정책 평가(Policy Improvement)는 쉽게 말해 개선된 로 V값을 갱신하는 과정이다.
우리는 지난 번에 Dynamic Programming을 이용할 수 있는 Grid World에서 가치를 구하는 방법으로
역행렬 연산을 통해 한번에 Value를 구하는 방법을 알아보았다. 하지만 역행렬이 존재하지 않는 경우가 대부분이기에 Iterative Updating 방식을 통해 Value를 계속해서 구해 나간다.
정책 평가 알고리즘
Input: 현재 정책 ,가치함수
Repeat:
각 상태 s에 대하여:
until 수렴
정책 개선 알고리즘
Input: 현재 정책 ,가치함수
output: 개선된 정책
계산
정책 반복
정책 반복 (Policy Iteration)은 정책 평가와 정책 개선을 적용해 Bellman 방정식을 푸는 알고리즘이다.
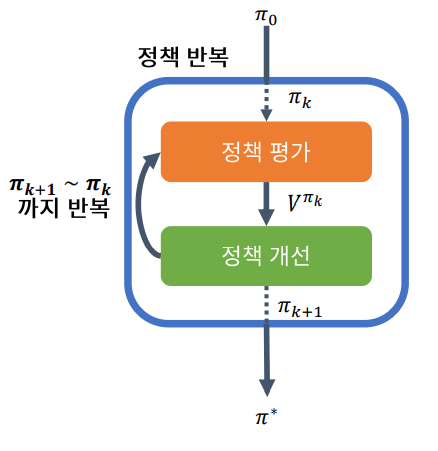
이 루프를 계속 진행하며 정책 평가를 계속 반복하면 바나흐 고정점 정리에 의해 V는 최적 가치 에 수렴한다.
즉, MDP를 DP를 활용해서 효율적으로 풀 수 있다.
정책 개선 정리 (Policy improvement theorem)
마지막으로 정책을 개선했을 때 이전 정책 보다 Value 값이 정말 더 커질까? 그것은 정책 개선 정리에 의해 참으로 밝혀졌다.
개선 후 정책: (이렇게 Stochastic이 아닌 정책을 Deterministic Policy라고 한다.)

Conclusion
우리는 이번 시간에 Dynamic Programming을 이용하여 MDP를 푸는 방법에 대하여 알아 보았다. 최적 가치 는 존재하지만 비선형이며 유일하게 존재하는 것이 아님이 밝혀져 한번에 계산하는 방법이 없다. 대신에, 그것을 푸는 방법으로 정책 반복 알고리즘을 배웠다. 정책 반복 알고리즘은 개선된 정책으로 V를 계산하는 정책 평가 개선된 V로 정책을 개선하는 정책 개선 알고리즘으로 이루어졌다. 정책 반복 알고리즘안에 루프를 계속한다면 바나흐의 고정점 정리에 의해 V와 Q는 최적 가치 에 반드시 수렴하게 되고 수렴 했을 때 정책을 최적 정책 라고 한다.
