s3 list object v2
s3 list object
사용하면 s3 버킷에 저장되어 있는 파일들을 읽을 수 있다.
그런데 문제는, 1,000개까지만 불러와지는 것이었다.
몇 천개 이상을 한번에 불러오는 로직을 구현할 때, 당연히 제대로 작동하지 않을 수 밖에 없었다. 공식 문서에도 이렇게 첫 줄에 친절하게 적혀 있었는데 삽질을 꽤 했던 기억이..😭
https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListObjectsV2.html

그렇다면 한번에 1,000개 초과되는 파일들을 가져오려면 어떻게 할까?
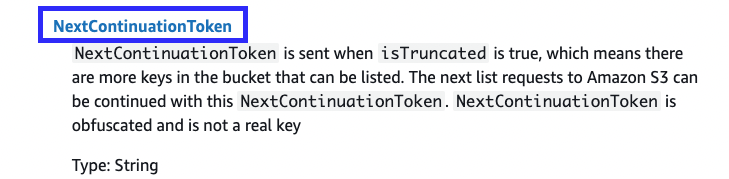
NextContinuationToken 을 이용했다.
요청에 대한 isCruncated가 true이면 토큰이 전송되고, 이 뜻은 버킷에 나열할 수 있는 키가 (파일들이) 더 많이 존재한다는 의미.
그래서 있는 동안 (true) 반복해주고, 없으면 (false) 멈추도록 한다.
이렇게 하면 1,000개가 넘는 파일도 잘 읽어올 수 있다.
try {
const params = {
Bucket: "S3 버킷 이름",
Prefix: "하위 경로",
}
do {
response = await s3.listObjectsV2(params).promise()
getObjects = tempObjects.concat(res.Contents)
// 더 읽을 파일들이 존재할 때
if (response.IsTruncated) {
params.ContinuationToken = response.NextContinuationToken
}
// ex) 전체 가져온 파일을 찍어본다.
getObjects.forEach((e) => {
console.log(e)
})
} while (response.IsTruncated)
return getObjects
} catch (error) {
return false
}
항상 공식 문서를 꼼꼼히 읽는 습관을 들이자.

developer / not moving for fortune, only aiming for clear sense of purpose. That's all.