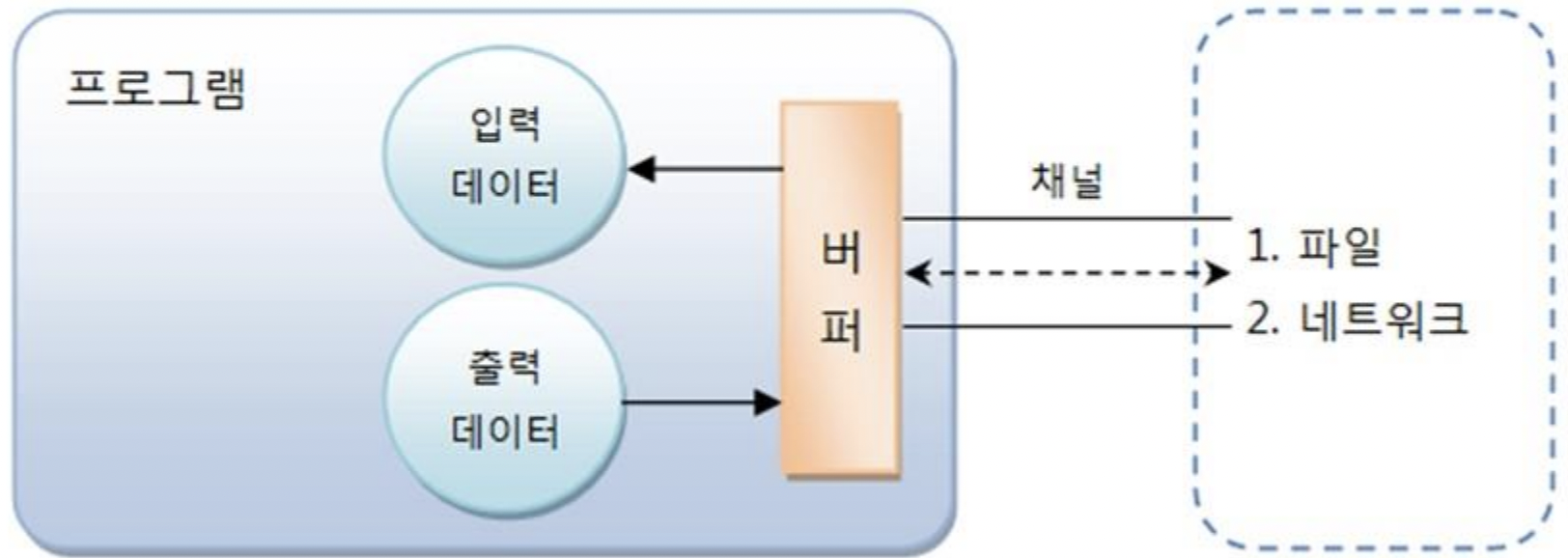
버퍼(Buffer)
버퍼는 읽고 쓰기 가능한 메모리 배열
- NIO에서는 데이터를 입출력을 하기 위해 항상 버퍼 사용
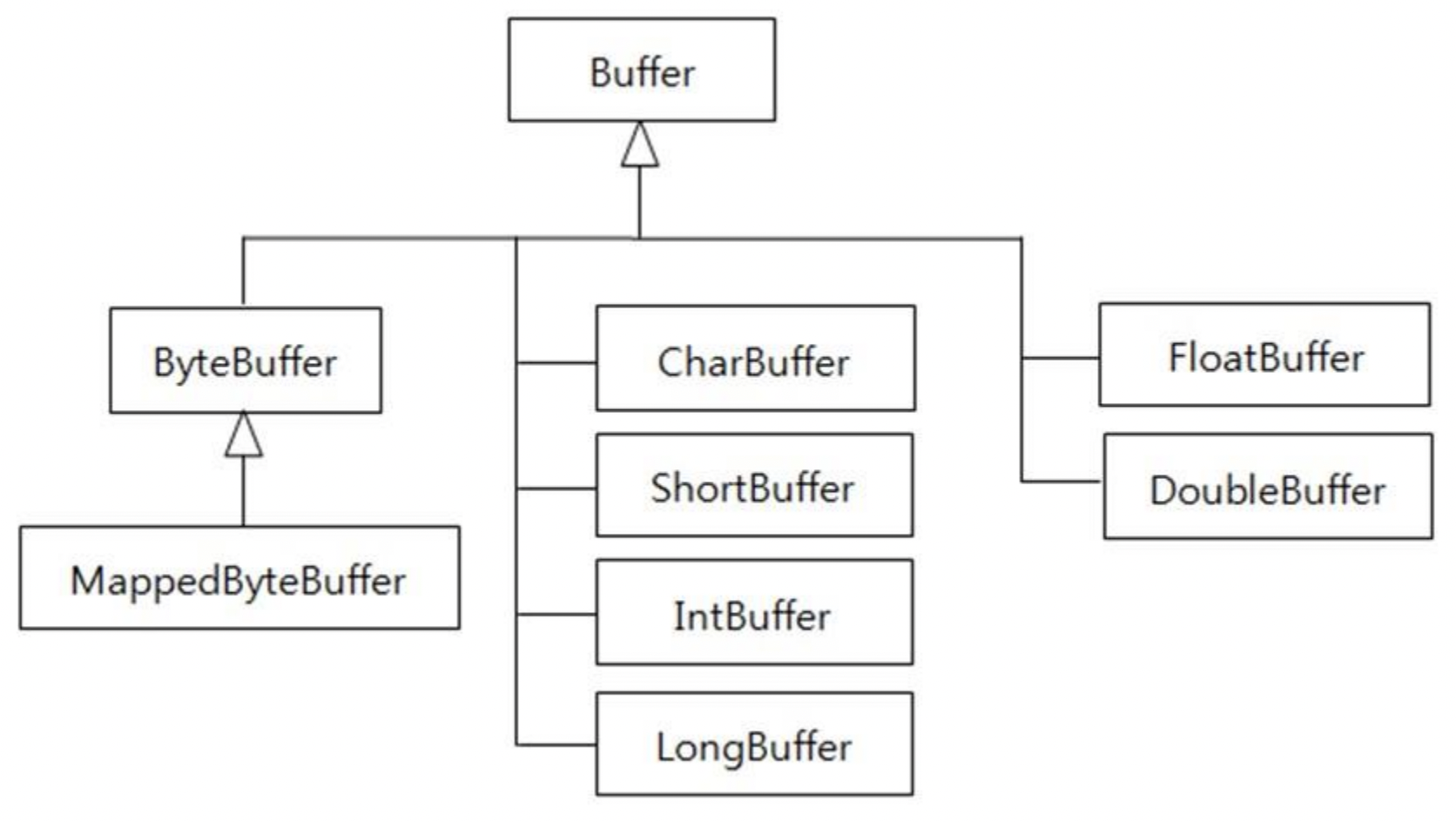
- 저장되는 데이터 타입에 따라 분류
- NIO버퍼는 저장되는 데이터 타입에 따라 별도의 클래스로 제공
- 버퍼 클래스들은 Buffer 추상 클래스를 모두 상속
- MappedByteBuffer는 파일의 내용에 랜덤하게 접근하기 위해서 파일의 내용을 메모리와 맵핑시킨 버퍼
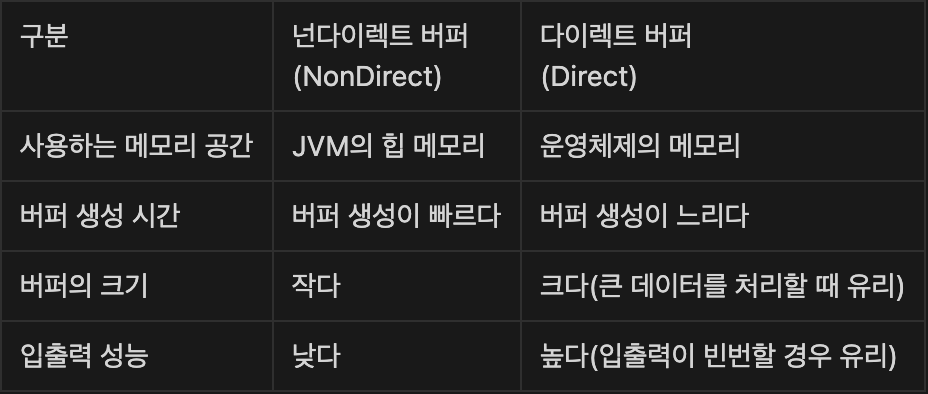
넌다이렉트 버퍼(NonDirect)
- 넌다이렉트 버퍼는 입출력을 하기위해 임시 다이렉트 버퍼를 생성하고 넌다이렉트 버퍼에 있는 내용을 임시 다이렉트 버퍼에 복사함
- 임시 다이펙트 버퍼를 사용해서 운영체제의 native IO 기능을 수행함
- allocate()메소드 : 넌다이렉트 버퍼를 생성하는 메소드
- 각 데이터 타입 별 넌다이렉트 버퍼 생성
- 매개값 - 해당 데이터 타입의 저장 개수
ByteBuffer byteBuffer = ByteBuffer.allocate(100);
CharBuffer charBuffer = CharBuffer.allocate(100);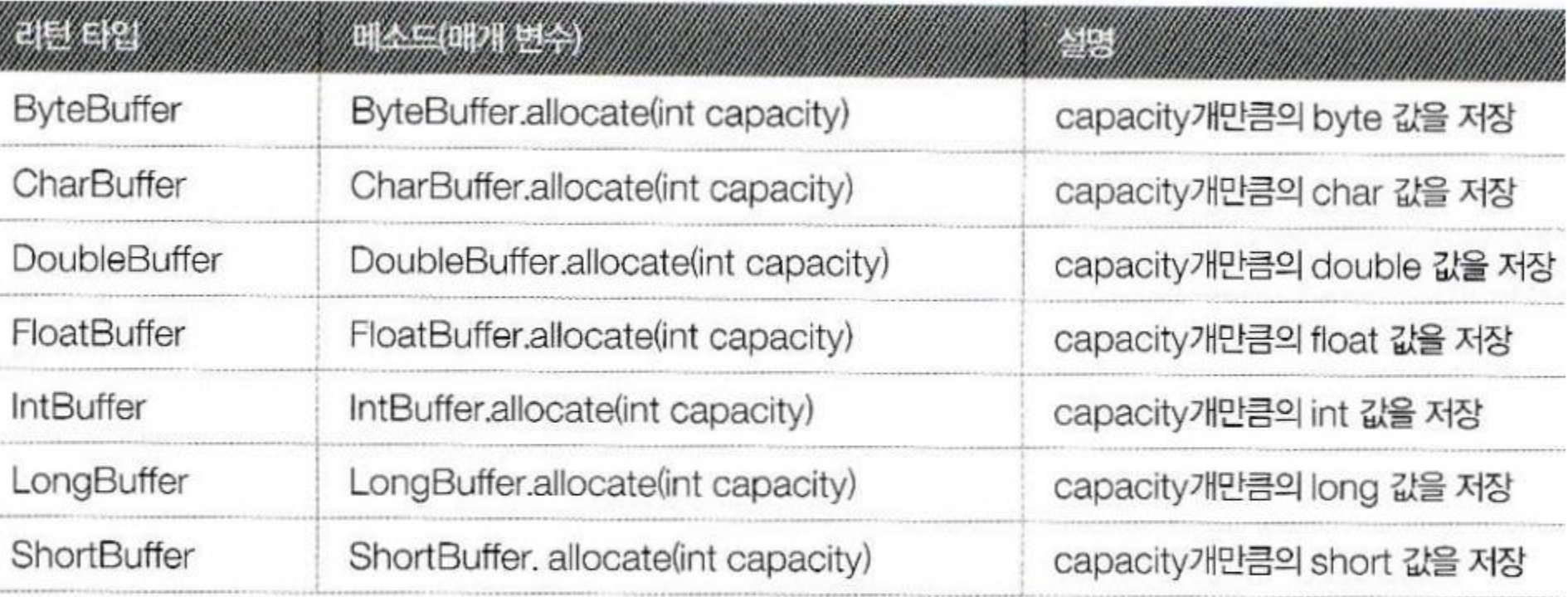
- wrap()메소드
- 각 타입별 Buffer 클래스는 모두 wrap()메소드를 가지고 있음
- 이미 생성되어 있는 타입 별 배열을 래핑해 버퍼 생성
- 길이가 100인 byte[]를 이용해서 ByteBuffer를 생성하고 길이가 100인 char[]를 이용하여 CharBuffer를 생성
- 일부 데이터만 가지고도 버퍼 생성 가능
- CharBuffer는 매개값으로 문자열을 받아 CharBuffer를 생성할 수 있음
byte[] byteArray = new byte[100];
ByteBuffer byteBuffer = ByteBuffer.wrap(byteArray);
char[] charArray = new char[100];
CharBuffer charBuffer = CharBuffer.wrap(charArray);
// Ex) 0인덱스부터 50개만 퍼버로 생성 (*일부 데이터*)
byte[] bytrArray = new byte[100];
ByteBuffer byteBuffer = ByteBuffer.wrap(byteArray,0,50);
char[] charArray = new char[100];
CharBuffer charBuffer = CharBuffer.wrap(charArray,0,50);
CharBuffer charBuffer = CharBuffer.wrap("NIO 입출력은 버퍼를 이용합니다."); //(*문자열*)다이렉트 버퍼(Direct)
- allocateDirect()메소드 : 다이렉트 버퍼를 생성하는 메소드
- JVM 힙 메모리 바깥쪽 (운영체제가 관리하는 메모리)에 다이렉트 버퍼 생성
- 각 타입 별 Buffer클래스에는 없고 ByteBuffer에서만 제공
- 타입 별로 생성하고 싶으면 ByteBuffer로 버퍼를 생성 후 asXXXBuffer() 메소드로 해당 타입의 Buffer를 얻을 수 있음
- asXXXBuffer() 메소드(각 타입 별 다이렉트 버퍼 생성)
- asLongBuffer(), asFloatBuffer(), asDoubleBuffer()...등등
- 다이렉트 ByteBuffer를 생성하고 호출
- 초기 다이렉트 ByteBuffer 생성 크기에 따라 저장 용량 결정
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(100); //100개의 byte값 저장
CharBuffer charBuffer = ByteBuffer.allocateDirect# 8강
# 1. NIO
기존 `java.io` API와 다른 새로운 입출력 API
| 구분 | IO | NIO |
| --- | --- | --- |
| 입출력 방식 | 스트림 방식 | 채널 방식 |
| 버퍼 방식 | 넌버퍼 | 버퍼 |
| 동기 / 비동기 | 동기 | 동기 / 비동기 모두 |
| 블로킹 / 넌블로킹 | 블로킹 | 블로킹 / 넌블로킹 모두 |
- 스트림: 입/출력 스트림이 구분되어 있기 때문에 입력시 입력 스트림을, 출력시 출력 스트림을 생성해야 함
채널: 양방향으로 입출력이 가능함. 입력과 출력을 위 별도 채널 만들 필요 없음.
- 넌버퍼: 1바이트씩 읽고 출력. 속도를 위해 버퍼 보조스트림을 이용하기도 함. 데이터를 별도로 저장해야 함
버퍼: 기본적으로 버퍼를 사용해 입출력 성능 좋음. 데이터를 별도로 저장할 필요 없음
- 블로킹: read()/write()메소드를 호출하면 데이터 입/출력 전까지 스레드는 블로킹 상태. interrupt로 빠져나오는 것이 불가하며 블로킹을 탈출하는 방법은 스트림을 닫는 것 뿐임.
넌블로킹: 스레드를 interrupt함으로써 빠져나올 수 있음. 입/출력 시 스레드가 블로킹되지 않음.
IO: 클라이언트 수 적음, 대용량, 순차처리 필요한 경우
NIO: 클라이언트 수 많음, 적은용량, 입출력이 빨리 끝나는 경우
# 2. 파일
IO에서는 파일의 속성정보를 읽기 위해 `File`클래스를 제공해 줬음.
NIO에서는 파일의 속성정보와 인터페이스를 `java.nio.file`, `java.nio.file.attribute` 패키지에서 제공해줌.
# 3. 경로
### java.nio.file.Path
IO의 `java.io.File` 클래스에 대응되는 NIO 인터페이스
`Path`의 구현 객체를 얻기 위해 `get()` 메소드를 호출함
```java
Path path = Paths.get(String first, String... more) // 인자로 들어온 파일의 정보가 path에 들어감
Path path = Paths.get(URI uri);경로는 한 문자열로 지정해도 되고, 여러 문자열로 나누어서 지정해도 됨. 절대경로, 상대경로 모두 가능.
int compareTo(Path other);: 파일의 경로가 동일하면 0, 상위면 음수, 하위면 양수 리턴Path getFileName();: 부모 경로를 제외한 파일 리턴FileSystem getFileSystem();: FileSystem 객체 리턴Path getName(int index);: index번째 경로의 Path 객체 리턴(C:\Temp\dir\file.txt 일 때 0→Temp)int getNameCount();: 중첩 경로 수(위 예시라면 3 리턴)Path getParent();: 바로 위 폴더의 Path 리턴Path getRoot();: 루트 디렉토리의 Path 리턴Iterator<Path> iterator();: 경로에 있는 모든 디렉토리와 파일을 Path 객체로 만들고 반복자를 리턴Path normalize();: 상대 경로로 표기할 때 불필요한 요소를 제거WatchKey register(…);: WatchService를 등록File toFile();: java.io.File 객체로 리턴String toString();: 파일 경로를 문자열로 리턴URI toURI();: 파일 경로를 URI 객체로 리턴
java.nio.file.FileSystem
FileSystem fileSystem = FileSystem.getDefault();- getFileStores(); : 드라이버 정보를 가진 FileStore 객체들을 리턴
java.nio.file.FileStore
드라이버를 나타내는 클래스
java.nio.file.Files
파일과 디렉터리의 생성 및 삭제, 이들의 속성을 읽는 메소드 제공
4. 와치 서비스
디렉터리 내부에서 파일 생성, 삭제, 수정 등의 내용 변화를 감시하는 데 사용됨
WatchService watchService = FileSystems.getDefault().newWatchService();
path.register(watchService, StandardWatchKinds.ENTRY_CREATE,StandardWatchKinds.ENTRY_MODIFY, StandardWatchKinds.DELETE,프로그램은 무한루프를 돌면서 WatchService의 take() 메소드를 호출하여 watchKey가 큐에 들어올 때까지 대기하고 있다가 WatchKey가 큐에 들어오면 WatchKey를 얻어 처리함
while (true)
WatchKey watchKey = watchService.take();
```(100).asCharBuffer(); //50개의 char 값 저장
IntBuffer intBuffer = ByteBuffer.allocateDirect(100).asIntBuffer();//25개의 int값 저장
- 운영체제의 메모리를 할당 받기 위해 운영체제의 함수를 호출해야 하고, 여러 가지 잡다한 처리를 해야 하므로 상대적으로 버퍼 생성이 느림
- 다이렉트 버퍼는 한 번 생성해 놓고 재사용함
- 운영체제가 관리하는 메모리를 사용하므로 운영체제가 허용하는 범위 내에서 대용량 버퍼를 생성 시킬 수 있음
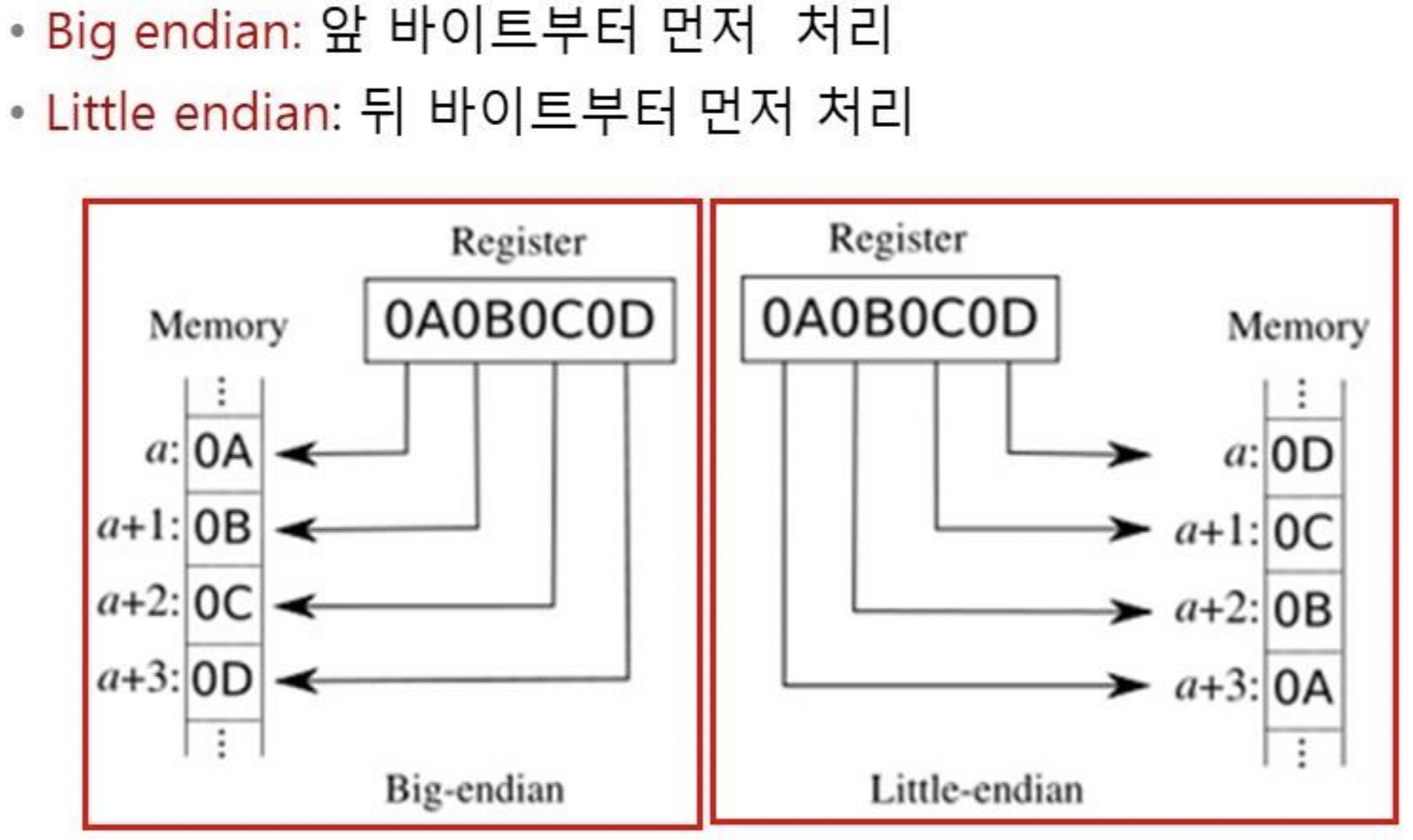
byte 해석 순서(ByteOreder)
-
운영체제는 두 바이트 이상을 처리할 때 처리 효율이나 CPU디자인 상의 문제로 바이트 해석 순서를 정함
-
데이터를 외부로 보내거나 외부에서 받을 때도 영향을 미치기 때문에 바이트 데이터를 다루는 버퍼도 이를 고려해야 함
-
운영 체제가 사용하는 바이트 해석 순서 확인 방법 nativeOrder
System.out.println("네이티브의 바이트 해석 순서:"+ByteOrder.nativeOrder());- JVM은 동일한 조건으로 클래스 실행해야 하므로 무조건 Big endian
- 운영체제와 JVM의 바이트 해석 순서가 다를 경우
- JVM이 운영체제와 데이터 교환 할 때 자동 처리
- 다이렉트 버퍼를 이용할 경우 운영체제의 native I/O를 사용
- 운영체제의 기본 해석 순서로 JVM의 해석 순서를 맞추는 것이 성능에 도움이 됨
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(100).order(ByteOrder.nativeOrder());Buffer의 위치 속성


⭐️ 읽기 모드로 변경하기 위해 flip() 메소드 호출
limit => position, position = 0
⭐️ 3바이트를 읽음
new byte[3], position = 3
⭐️ mark() 호출
mark = 3, (돌아오는 위치 지정)
⭐️ 2바이트를 읽음
position = 5,
⭐️ position = limit, position = mark
(position을 mark위치로 이동) reset()메소드 호출
if. mark가 없는 상태에서 reset() 메소드를 호출하면 InvalidMarkException 예외가 발생
⭐️ rewind()(버퍼를 되감아 동일한 데이터를 한 번 더 읽고 싶을 때)
position = 0
if. mark가 position이나 limit보다 커지면 mark는 소멸됨
⭐️ claer() (모든 속성을 초기화 단, 데이터는 삭제되지 않음)
position = 0, limit = capacity, mark는 소멸됨
⭐️ compact() (읽지 않은 데이터 뒤에 새로운 데이터 저장)
position = 복사한 마지막 데이터 다음 위치, limit = capacity
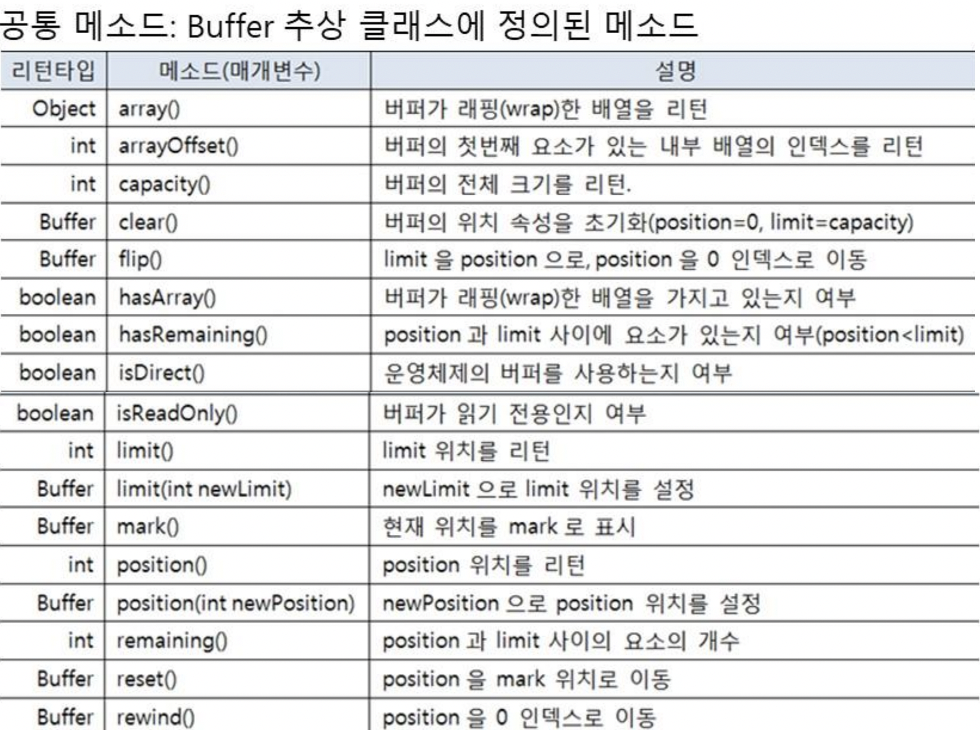
버퍼의 메소드
- 데이터 읽기 : get(...)
- 데이터 저장 : put(...)
- Buffer 추상 클래스에는 없고, 각 타입 별 하위 Buffer클래스가 가짐
버퍼 예외의 종류
버퍼 예외 발생 주요 원인
1. 버퍼가 다 찼을 때, 데이터를 저장하려는 경우
2. 버퍼에서 더 이상 읽어올 데이터가 없을 때 데이터를 읽으려는 경우

