scikit-learn 특징
- 다양한 머신러닝 알고리즘을 구현한 파이썬 라이브러리
- 심플하고 일관성 있는 API, 유용한 온라인 문서, 풍부한 예제
- 머신러닝을 위한 쉽고 효율적인 개발 라이브러리 제공
- 다양한 머신러닝 관련 알고리즘과 개발을 위한 프레임워크와 API 제공
- 많은 사람들이 사용하며 다양한 환경에서 검증된 라이브러리
scikit-learn의 주요 모듈
| 모듈 | 설명 |
|---|---|
sklearn.datasets | 내장된 예제 데이터 세트 |
sklearn.preprocessing | 다양한 데이터 전처리 기능 제공 (변환, 정규화, 스케일링 등) |
sklearn.feature_selection | 특징(feature)를 선택할 수 있는 기능 제공 |
sklearn.feature_extraction | 특징(feature) 추출에 사용 |
sklearn.decomposition | 차원 축소 관련 알고리즘 지원 (PCA, NMF, Truncated SVD 등) |
sklearn.model_selection | 교차 검증을 위해 데이터를 학습/테스트용으로 분리, 최적 파라미터를 추출하는 API 제공 (GridSearch 등) |
sklearn.metrics | 분류, 회귀, 클러스터링, Pairwise에 대한 다양한 성능 측정 방법 제공 (Accuracy, Precision, Recall, ROC-AUC, RMSE 등) |
sklearn.pipeline | 특징 처리 등의 변환과 ML 알고리즘 학습, 예측 등을 묶어서 실행할 수 있는 유틸리티 제공 |
sklearn.linear_model | 선형 회귀, 릿지(Ridge), 라쏘(Lasso), 로지스틱 회귀 등 회귀 관련 알고리즘과 SGD(Stochastic Gradient Descent) 알고리즘 제공 |
sklearn.svm | 서포트 벡터 머신 알고리즘 제공 |
sklearn.neighbors | 최근접 이웃 알고리즘 제공 (k-NN 등) |
sklearn.naive_bayes | 나이브 베이즈 알고리즘 제공 (가우시안 NB, 다항 분포 NB 등) |
sklearn.tree | 의사 결정 트리 알고리즘 제공 |
sklearn.ensemble | 앙상블 알고리즘 제공 (Random Forest, AdaBoost, GradientBoost 등) |
sklearn.cluster | 비지도 클러스터링 알고리즘 제공 (k-Means, 계층형 클러스터링, DBSCAN 등) |
estimator API
- 일관성: 모든 객체는 일관된 문서를 갖춘 제한된 메서드 집합에서 비롯된 공통 인터페이스 공유
- 검사(inspection): 모든 지정된 파라미터 값은 공개 속성으로 노출
- 제한된 객체 계층 구조
- 알고리즘만 파이썬 클래스에 의해 표현
- 데이터 세트는 표준 포맷(NumPy 배열, Pandas DataFrame, Scipy 희소 행렬)으로 표현
- 매개변수명은 표준 파이썬 문자열 사용
- 구성: 많은 머신러닝 작업은 기본 알고리즘의 시퀀스로 나타낼 수 있으며, Scikit-Learn은 가능한 곳이라면 어디서든 이 방식을 사용
- 합리적인 기본값: 모델이 사용자 지정 파라미터를 필요로 할 때 라이브러리가 적절한 기본값을 정의
API 사용 방법
- Scikit-Learn으로부터 적절한
estimator클래스를 임포트해서 모델의 클래스 선택 - 클래스를 원하는 값으로 인스턴스화해서 모델의 하이퍼파라미터 선택
- 데이터를 특징(feature) 배열과 대상(target) 벡터로 배치
- 보통 X, y 로 표현
- 모델 인스턴스의
fit()메서드를 호출해 모델을 데이터에 적합 - 모델을 새 데이터에 대해서 적용
- 지도 학습: 대체로
predict()메서드를 사용해 알려지지 않은 데이터에 대한 레이블 예측 - 비지도 학습: 대체로
transform()이나predict()메서드를 사용해 데이터의 속성을 변환하거나 추론

API 사용 예제
import numpy as np
import matplotlib.pyplot as plt
plt.style.use(['seaborn-whitegrid'])
# 데이터 생성
x = 10 * np.random.rand(50)
y = 2 * x + np.random.rand(50)
plt.scatter(x, y)
# 2차 함수 모양으로 그래프 그리기
step1. 적절한 'estimator'클래스를 import해서 모델의 클래스 선택
from sklearn.linear_model import LinearRegressionstep2. 클래스를 원하는 값으로 인스턴스화, 모델의 하이퍼 파라미터 선택
model = LinearRegression(fit_intercept=True) # 하이퍼 파라미터 선택
model.get_params() # 모델의 하이퍼 파라미터들
'''
{'copy_X': True,
'fit_intercept': True,
'n_jobs': None,
'normalize': 'deprecated',
'positive': False}
'''
# ↓ 모델을 보니, 다양한 파라미터들이 있다. 기본적으로 디폴트 값들이 들어가 있다.
# 아까 estimagtor API 의 많은 파라미터 들이 디폴트로 기본값 지정이 되어 있다.
# copy_X = True : 실제 입력될 데이터를 복사해서 사용할지 여부 (디폴트 True : 입력 데이터의 사본을 만들어서 사용합니다)
# fit_intercept=True : 상수 형태의 값이라는 것을 의미를 True 로 둠 (위 예제에서 우리는 상수를 다루고 있다)
# n_jobs=None : 모델을 돌릴때 여러개 job 을 주어서 돌릴수 있다. (패러렐 하게)
# CPU 의 여러 코어를 사용해서 병렬로 알고리즘을 돌릴수 있다
# normalize=False : 정규화가 되었는지 여부.step3. 데이터를 특징(feature) 배열과 대상(target) 벡터로 배치
x.shape # (50,)
X = x[:, np.newaxis] # 차원추가, 차원추가를 하는 이유는 'feature 의 배열' 로 만들기 위함
X # (50, ) → (50, 1)
# 위와 같이 , y 는 그대로 사용하고 x 만 특징배열 로 변환했다 -> Xstep4. 모델 인스턴스의 fit() 메소드를 호출하여 모델의 데이터를 적합(fit) (학습!)
model.fit(X, y) # LinearRegression() 객체step5. 모델에 새 데이터를 적용해본다
주어진 새로운 관측치(x 값들) 에 대해 학습된 모델이 '예측' 할수 있다.
# 새 데이터 만들기
xfit = np.linspace(-1, 11)
# ★ 적용할 데이터도 모델에 넣어주려면
# 학습할때 넣어준 것과 같은 '특징벡터 (feature vector)' 로 변환하여 넣어주어야 한다!
Xfit = xfit[:, np.newaxis] # 차원축을 추가해주어 2차원 벡터 형태로 만듬 (50, ) -> (50, 1) # 예측하기
yfit = model.predict(Xfit)
yfit # 예측한 결과(벡터)가 담겨 있다위 결과를 시각화 해보자 (과연 잘 예측한걸까?)
plt.scatter(x, y) # 학습에 사용한 데이터
plt.plot(xfit, yfit, '--r') # 새로운 데이터 -> 예측값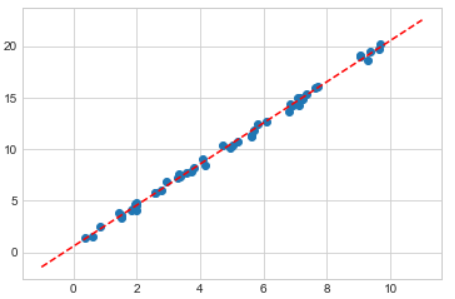
소감
scikit-learn에 대한 포스팅은 아직 끝나지 않았다.
우선 데이터에 적절한 estimator 클래스를 선택해서
모델의 클래스를 가져오는게 중요한거 같다.


기록중