학습내용: https://d2l.ai/chapter_introduction/index.html
1. Introduction
최근까지, 우리가 사용하는 거의 모든 컴퓨터 프로그램들은 sw developer들에 의해서 코딩되어왔다.
이런 제품이 시스템을 100% 자동으로 구동하는 방법을 고안할 수 있다면 machine learning은 필요 없을것이다. 하지만 다행이도(?) 자동화하려는 많은 작업이 쉽게 인간의 독창성에 따라지진 않는다.
예를 들어:
- 지리적 정보, 위성 사진, 과거 날씨의 정보로 다음날의 날씨를 예측하는 프로그램을 작성.
- 자유 양식 문자로 표현된 질문을 받아 올바른 답을 하는 프로그램 작성
- 주어진 이미지에서 포함된 모든 사람을 식별하고 각각의 윤곽을 그리는 프로그램 작성
- 사용자가 즐길 가능성은 있지만 인터넷을 돌아다니다가 발견할 가능성은 없는 제품을 보여주는 프로그램 작성
Machine Learning은 경험에서 학습될 수 있는 강력한 기술의 연구이다. 머신러닝 알고리즘이 실측적인 데이터나 환경과의 상화작용 형태의 경험을 학습하면 학습할수록 성능이 향상된다. 자동학습되는 것이 아닌 e-commerce platform을 생각해보면, 개발자들이 스스로 학습하고 결정하고 나서야 sw에 update가 된다. 이 책에서는 머신러닝의 핵심을 가르치고, 다양한 분야의 획기적인 혁신을 가지고 온 기술인 Deep Learning에 초점을 두고 있다.
1.1. A Motivating Example
시작하기에 앞서 모두들 밥은 먹었을 것이다. 차에 타서 아이폰을 사용하면서 Elina는 "시리야"라고 부르면서 핸드폰의 음성 인식 시스템을 작동시킨다. Elina는 "콩나물 국밥 집 가는 방향" 이라고 말한다. 핸드폰은 요청된 것을 빠르게 문서로 표기해서 보여준다. 핸드폰은 우리가 방향을 물어본것을 인지하고 있고, 지도 앱을 실행시켜서 우리의 요청을 수행한다. 지도 앱이 실행되고 나서는 길의 수를 구별하고 이동시간을 예측해서 보여준다. 이 이야기는 단 몇 초 만에 스마트폰과 일상적인 상호 작용이 여러 기계학습 모델을 사용할 수 있음을 보여준다.
“Alexa”, “OK Google”, “Hey Siri” 등과 같은 wake word에 반응하는 프로그램을 작성하는 것은 불가능하다. 이것이 기계학습을 사용하는 이유이다.

Here is the trick. "Alexa"라는 단어를 인식하도록 컴퓨터를 프로그래밍하는 방법을 모르더라도 우리는 스스로 인식할 수 있습니다. 이 능력 덕분에, 오디오의 예시들과 wake word가 포함된 항목과 포함하지 않은 항목에 라벨을 지정한 거대한 dataset을 모을 수 있다. 기계학습 접근 방식에서는, wake word를 명시적으로 인식하는 시스템을 설계하려고 시도하지 않는다. 대신에, 우리는 행동이 여러 parameters에 의해 결정되는 유연한 프로그램을 정의한다. 그리고나서 그dataset을 사용해 프로그램의 성능을 향상시키는 가능한 최상의 parameters 집합을 결정한다.
parameters를 우리가 돌리고 프로그램의 행동을 조작할 수 있는 손잡이라고 생각할 수 있다. parameters를 수정하는 프로그램을 model 이라고 부른다.우리가 parameters 조작으로만 생성될 수 잇는 별개의 프로그램들(input-output mappings)의 집합을 models의 family라고 부른다. 그리고 parameters를 고르기위해 우리의 dataset을 사용하는 meta-program을 learning algorithm이라고 부른다.
Machine Learning에서 Learning은 우리의 모델에서 원하는 동작을 강요하는 손잡이들의 올바른 설정을 발견하는 과정이다. 즉, 데이터로 우리의 모델을 훈련시킨다. 훈련 과정은 일반적으로 다음과 같다.
1. Start off with a randomly initialized model that cannot do anything useful.
2. Grab some of your data (e.g., audio snippets and corresponding {yes, no}labels).
3. Tweak the knobs so the model sucks less with respect to those examples.
4. Repeat Step 2 and 3 until the model is awesome. 
요약하자면, wake word 인식기를 코딩하는 것이 아니라 label된 거대한 데이터 세트를 제시하면서 wake word를 인식하는 방법을 학습하는 프로그램을 코딩한다.
1.2. Key Components
- The data that we can learn from.
- A model of how to transform the data.
- An objective function that quantifies how well (or badly) the model is doing.
- An algorithm to adjust the model’s parameters to optimize the objective function.
1.2.1 Data
data를 유용하게 다루기 위해서는, 일반적으로 데이터에 대한 적절한 수치 표현이 필요하다. 각각의 example(or data point, data instance, sample)은 전형적으로 모델이 예측을 해야하는 features(or covariates) 라고 불리는 속성들의 집합으로 구성되어 있다. 위와 같은 지도학습 같은 경우, 예측해야 할 것은 label(or target)으로 지정된 특별한 값들이다.
이미지 데이터를 다룰 때, 각 개별 사진이 example을 구성할 수 있으며 각 사진은 각 픽셀의 밝기에 해당하는 숫자 값의 정렬된 list로 표시된다. 200 200 사진은 200 200 3 = 120000 수치값으로 구성되어 있다. (각각 공간 위치에서의 RGB channel) 또 다른 경우에 연령, 생명 징후, 진단과 같은 일련의 표준적인 features가 주어지면 환자의 생존 여부를 예측하려고 할 수 있다.
하지만, 모든 데이터가 쉽게 fixed-length 벡터로 표현될 수는 없다. 인터넷에서 얻어진 이미지가 모두 동일한 해상도나 모양으로 나타나진 않을 것이다. 또한 글자 데이터는 더 다루기 힘들게 고정된 길이의 표현으로 있지 않는다. 고객 리뷰만 봐도 아주 짧은것이 있고 한페이지 가까이 되는 리뷰가 있다. 기존 방법에 비교해 Deep Learning의 가장 큰 이점 중 하나는 models이 다양한 길이의 데이터를 처리할 수 있다는 것이다.
일반적으로, 많은 데이터를 가질수록, 일은 더 쉬워진다. 데이터가 더 많을수록, 매우 효과적으로 모델을 학습시킬 수 있고, 미리 정의된 가정에 덜 의존적이게 된다. 빅데이터로의 변환은 현대의 딥러닝 발전에 중요한 원인 중 하나이다.
마지막으로, right data가 필요하다. 만약 데이터가 오점으로 가득 차거나, 선별된 특징들이 관심 타겟을 예측하지 못하는 경우 학습은 실패할 것이다. Garbage in, Garbage out. 또한 이 garbage data에 대한 결과를 바로 알려줘야한다. 예를 들어, 이력서를 심사하는 데 과거의 채용 결정 데이터가 예측 모델을 훈련하는 데 사용된다면 기계학습 모델은 실수로 과거의 부당함을 포착하고 자동화할 수 있습니다.
1.2.2 Models
대부분의 기계학습은 데이터를 어떤 감각으로 변형하는 것과 관련이 있다. 모델을 통해서 한 유형의 데이터를 수집해 계산 기계로 나타내고, 다른 유형의 예측을 뱉어낸다. 특히, 데이터로부터 측정될 수 있는 통계학적인 모델에 관심이 있다. 단순한 모델은 적절하게 단순한 문제를 다루는데 용이하지만, 이 책에서 우리가 주목하는 문제는 고전적인 방법의 확장을 필요로 한다. 이 모델은 위에서 아래로 연결된 수많은 데이터의 연속적인 변환으로 구성되므로 딥러닝이라는 이름이 붙습니다.
1.2.3. Objective Functions
학습기계의 형식적인 수학적 시스템을 향상시키기 위해서, 모델이 얼마나 좋고 나쁜지를 측정할 수 있는 공식적인 방법이 필요하다. 기계학습에서 (일반적으로는 최적화에서) 우리는 이것을 Objective Functions 이라고 한다. 단지 협약일 뿐이지만 일반적으로 목적함수는 낮을수록 좋다. 일반적으로 낮을수록 좋기때문에 이러한 함수를 Loss function 이라고도 한다.
수치 예측에서 가장 흔한 손실함수는 squared error(예측값과 실체값 차이의 제곱) 이다. Classification에서 흔한 목적은 error 수치를 최소화 하는것이다. 전자 같은 경우 최적화하기 쉽지만 후자와 같은 경우는 바로 최적화 하기에는 어렵다. 이러한 경우 surrogate objective를 최적화하는 것이 일반적이다.
일반적으로 손실 함수는 모델의 parameters와 관련하여 정의되며 데이터 세트에 따라 다르다. 훈련을 위해 수집된 몇 가지 예제로 구성된 세트에서 발생하는 loss를 최소화해서 모델 매개변수 최상의 값을 학습한다. 그러나 훈련 데이터에서 좋다고 해도 보이지 않는 데이터에서도 좋다는 보장은 없습니다. 그래서 우리는 일반적으로 데이터를 Train Dataset와 Test Dataset 두 개로 분할하여 모델의 성능을 관찰한다. 하지만 모델이 너무 훈련 데이터에만 잘 수행한다면 overfitting이라는 문제점이 생긴다.
1.2.4. Optimization Algorithms
데이터와 표현, 모델, 잘 정의된 목적 함수를 얻은 후에는 손실 함수를 최소화하기 위해 가능한 최상의 매개변수를 검색할 수 있는 알고리즘이 필요하다. 딥러닝을 위한 인기 있는 최적화 알고리즘은 Gradient descent 이다. 간단히 말해서, 이 방법은 각 단계에서 각 매개변수에 대해 해당 매개변수를 약간만 교란시키면 훈련 세트 손실이 어떤 방식으로 이동하는지 확인하는 것이다. 그런 다음 손실을 줄일 수 있는 방향으로 매개변수를 업데이트합니다.
1.3. Kinds of Machine Learning Problems
1.3.1. Supervised Learning
지도 학습은 입력 feature가 주어질때 레이블을 예측하는 작업을 다루는 것이다. 각각의 feature와 label의 쌍은 example이라고 부른다. 때때로 context가 명확하면, 해당 labels를 알 수 없는 경우에도 입력 모음을 참조하기 위해 examples 라는 용어를 사용할 수 있다. 우리의 목표는 어떤 입력이든 label 예측을 매핑하는 모델을 생성하는 것입니다.
구체적인 예를 들자면, 만약 우리가 의료 서비스에 종사한다면, 환자가 심장마비가 올 것인지 아닌지 예측하고 싶을것이다. 여기서 "heart attack" 또는 "no heart attack” 이 label이 된다. 입력 feature는 심장박동 수, 이완기 혈압, 수축기 혈압과 같은 생명 징후가 된다.
parameters를 선택하기 위해, labeled된 examples 데이터 세트를 모델에 제공하기 때문에 통제를 하기 시작한다.(여기서 각 examples는 실제 레이블과 일치) 확률적인 용어로, 우리는 일반적으로 주어진 입력 특징들 label의 조건부 확률을 측정하는 것에 초점을 둔다. 기계학습 내에서는 단지 여러 패러다임중 하나이지만, Supervised Learning 은 대부분 머신 러닝을 성공적으로 적용하고 있다. 많은 중요한 작업들이 사용가능한 데이터들이 주어졌을 때 알려지지 않은 것의 확률을 측정하면서 활발하게 설명될 수 있기 때문이다.
예를 들어:
- Predict cancer vs. not cancer, given a computer tomography image.
- Predict the correct translation in French, given a sentence in English.
- Predict the price of a stock next month based on this month’s financial reporting data.
비공식적으로, 학습 과정은 아래와 같이 진행된다.
First, grab a big collection of examples for which the features are known and select from them a random subset, acquiring the ground-truth labels for each.
Sometimes these labels might be available data that have already been collected (e.g., did a patient die within the following year?) and other times we might need to employ human annotators to label the data, (e.g., assigning images to categories).
Together, these inputs and corresponding labels comprise the training set.
We feed the training dataset into a supervised learning algorithm, a function that takes as input a dataset and outputs another function: the learned model.
Finally, we can feed previously unseen inputs to the learned model, using its outputs as predictions of the corresponding label.
1.3.1.1. Regression
아마도 가장 단순한 지도학습이라고 생각나는 것이 회귀(regression)일 것이다. 예를 들어 주택 판매 데이터 집합을 고려해보자. 테이블을 구성할 때, 행은 각각의 집을 의미하고, 각 열에는 그와 관련된 집의 면적, 침실 수, 화장실 수, 시내 중심지까지 시간이 될 수 있다. 뉴욕에 산다면 이 특징 벡터는 [600, 1, 1, 60]이 될 수 있다. 이러한 특징벡터는 대부분의 기계학습 알고리즘에서 필수적이다.
회귀를 문제로 만드는 것은 사실 출력값이다. 너가 새로운 집을 구하러 왔다고 해보자. 너는 주어진 위의 정보들로부터 집의 공정한 시장 가치를 평가하고 싶을것이다. 라벨(=판매 가격)은 수치 값이다. 라벨이 임의의 숫자 값을 가질 때 이를 회귀 문제라고 한다. 우리의 목표는 예측이 실제 라벨 값에 거의 근접한 모델을 생성하는 것이다.
많은 전형적인 문제들이 회귀 문제를 잘 설명한다. 사용자가 영화에 부여할 등급을 예측하는 것은 회귀 문제로 생각할 수 있으며 2009년에 이것에 대한 훌륭한 알고리즘을 설계했다면 백만 달러의 Netflix 상을 받았을 수도 있다. 병원에서 환자가 머무는 기간을 예측하는 것 또한 회귀 문제이다.
- How many hours will this surgery take?
- How much rainfall will this town have in the next six hours?
기계학습을 전혀 경험해보지 못했다하더라도, 회귀 문제는 비공식적으로라도 접했을 것이다. 예를 들어, 배수관 수리를 위해 도급업자가 작업하는데 3시간을 보냈다고 생각해보라. 그 후 그는 당신에게 350달러의 청구서를 보냈다.
이제 친구가 같은 도급업자를 2시간 동안 고용하고 250달러의 청구서를 받았다고 상상해 보라. 그런 다음 누군가가 다가오는 청구에 얼마를 예상하냐고 묻는다면 더 많은 시간을 일하면 더 많은 비용이 든다는 것과 같은 합리적인 가정을 할 수 있다. 또한 기본급과 도급업자 인건비 또한 포함되어 있다는 것을 가정할 수 있다. 만약 이 가정이 진실이라면, 이미 도급업자의 가격책정 구조를 알아볼 수 있다: 시간당 100달러에 출장비 50달러.
이 경우에서는, 도급업자의 가격과 정확히 매칭되는 parameters 를 생산할 수 있었지만 이것이 불가능할 때도 있다. 예를 들어, 분산의 일부가 두 가지 기능 외에 몇 가지 요인으로 인해 발생하는 경우이다. 이런경우에는, 우리의 예측과 도출된 값 사이의 차이를 최소화하는 모델의 학습을 시도할 것이다. 대부분의 챕터에서, squared error 손실함수 최소화에 초점을 둘것이다. 나중에 보겠지만, 이 손실은 데이터가 Gaussian noise에 의해 손상되었다는 가정에 해당한다.
1.3.1.2. Classification
회귀모델이 how many?를 설명하는데 좋은 모델이라면, 많은 문제들이 이 템플릿에 기울지 않을 것이다. 예를들어, 은행에서 모바일 앱에 수표 스캔 기능을 추가하려고 합니다. 여기에서는 고객이 스마트폰 카메라로 수표 사진을 찍는 것이 포함되고 앱이 자동적으로 이미지에서 보이는 텍스트를 이해해야한다. 특히, 필기 문자를 알려진 문자 중 하나로 매핑하는 것과 같이 필기 텍스트를 훨씬 더 강력하게 이해해야한다. 이런 종류의 which one? 문제가 classification 이다. 많은 기술이 적용되지만 회귀에 사용되는 것과는 다른 알고리즘으로 처리된다.
Classification 에서는, 우리는 모델이 이미지의 픽셀 값과 같은 features에 주목하기를 원하고 어떤 category(= class) 인지 예측한다. 필기 문자에서, 우리는 0-9까지 10개의 클래스를 가진다. 가장 단순한 형태의 분류는 두개의 클래만 존재할 때인데, 이 문제를 binary classification 이라고 한다. 예를 들어, 우리의 데이터셋이 동물의 이미지로 구성되어 있고, 라벨 클래스는 {cat, dog}이다. 회귀에서는, 수치 값을 출력하기 위해 regressor를 찾고, 분류에서는 예측된 클래스 배치의 출력값을 가지고 있는 classifier를 찾는다.
책이 더 기술적으로 발전함에 따라, {cat, dog}와 같이 하드 범주 할당만 출력할 수 있는 모델을 최적화하는 것은 어려울 수 있다. 이런 경우에는 모델을 가능성으로 표현하는 것이 더 쉽다. example의 특징이 주어지면 모델은 각 클래스에 가능한 확률을 할당한다. {cat, dog} 동물 분류를 다시 생각해보면, 분류기는 이미지를 보고 이미지가 고양이일 확률을 0.9로 출력할 수 있다. 우리는 이 숫자를 분류기가 이미지를 고양이로 예측하는 것을 90% 확신한다라고 해석할 수 있다. 예측된 클래스에 대한 확률의 크기는 한 가지 불확실성을 전달한다. 이것은 뒤 챕터에서 더 얘기할 것이다.
두개 이상의 클래스를 가질 때, 이 문제를 multiclass classification 라고 한다. 일반적인 예로는 손으로 쓴 문자 인식이 있다{0, 1, 2, ...9, a, b, c,...}. 분류 문제의 일반적인 손실함수는 cross-entropy 이다.
아래와 같은 버섯을 마당에서 발견했다고 하자.

이제, 분류기를 생성하고 사진의 이 버섯이 독이 있는지 예측하도록 훈련한다고 가정하자. 우리의 독물 탐지 분류기는 그림이 독버섯일 확률이 0.2라고 출력한다. 다른 말로, 분류기는 독버섯이 아닐거라고 80% 확신한다. 그럼에도 불구하고, 그것을 먹으려면 바보가 되어야 할 것이다. 왜냐하면 맛있는 저녁의 확실한 이점이 그것 때문에 죽을 위험의 20%만큼 가치가 없기 때문이다. 즉, 불확실한 위험의 영향이 이익보다 훨씬 크다. 따라서 손실 함수로 발생하는 예상 위험을 계산해야 합니다. 즉, 결과의 확률과 관련된 이득(또는 위해성)을 곱해야 합니다. 이런 경우에서는, 버섯을 먹음으로써 발생하는 손실은 0.2 ∞ + 0.8 ∞ = ∞, 반면에 버렸을 때의 손실은 0.2 0 + 0.8 1 = 0.8 이다. 우리의 주의는 정당했다: 어떤 균학자가 말해도, 버섯은 사실 독버섯이다.
분류는 binary, multiclass, 아니면 multi-label classification 보다 훨씬 더 복잡해질 수 있다. 예를 들어, 계층 구조를 다루기 위한 분류에는 몇 가지 변형이 있다. 계층구조는 많은 클래스간에 어떤 관계가 존재할 것이라고 가정한다. 그래서 모든 오류가 같은 것은 아니다 - 오류를 범해야 한다면 먼 클래스보다 관련 클래스로 잘못 분류할 것이다. 대게 이런것을 hierarchical classification 이라고 한다. 초기의 한 예는 동물들을 계층 구조로 조직한 Linnaeus에 의한 것이다.
동물 분류의 경우, 모델이 푸들을 슈나우쳐로 실수하는 것이 그렇게 나쁘진 않겠지만, 푸들을 공룡으로 헷갈렸다면 큰 패널티를 받아야 한다. 모델을 사용하는 방법에 따라 관련 계층이 달라질 수 있다. 예를 들어, 딸랑이 뱀과 가터 뱀은 계통 발생 나무에 가까이 있을 수 있지만, 가터(스타킹)라고 착각하는 것은 치명적일 수 있다.
1.3.1.3. Tagging
일부 분류 문제는 이진 또는 다중 클래스 분류 설정에 깔끔하게 들어맞는다. 예를 들어, 우리는 고양이와 개를 구별하기 위해 정상적인 이진 분류기를 훈련시킬 수 있다. 컴퓨터 비전의 현재 상태를 감안할 때, 우리는 이것을 기성 도구로 쉽게 할 수 있습니다. 그럼에도 불구하고, 우리의 모델이 아무리 정확해도, 분류기가 그림 1.3.3에 나오는 네 마리의 동물이 등장하는 인기 있는 독일 동화인 브레멘의 타운 뮤지션의 이미지를 만났을 때, 우리는 곤경에 빠질 수 있다.

사진에는 나무 배경에 고양이, 수탉, 개, 당나귀가 있다. 궁극적으로 모델을 사용하여 무엇을 하고자 하는지에 따라, 이항 분류 문제로 취급하는 것은 의도에 맞지 않을 수 있다. 대신, 우리는 그 모델이 고양이, 개, 당나귀, 그리고 수탉을 묘사한다고 말할 수 있는 옵션을 주고 싶을지도 모른다.
서로 배타적이지 않은 클래스를 예측하는 것을 배우는 것을 multi-label classification 이라고 한다. 자동-태깅 문제가 전형적으로 multi-label 분류를 잘 설명한다. 사람들이 기술 블로그의 게시물에 적용할 수 있는 태그(예: “machine learning”, “technology”, “gadgets”, “programming languages”, “Linux”, “cloud computing”, “AWS”)를 생각해 보자. 특정 글은 5-10개 태그를 가지고 있을 수도 있다. “cloud computing” 관련 포스트는 "AWS"를 언급할 가능성이 높고, "machine learning" 관련 포스트는 "programming languages" 를 다룰 것이다.
1.3.1.4. Search
정보 검색 분야에서, 우리는 일련의 항목에 순위를 매기고 싶다. 웹 검색을 예로 들어보자. 목표는 특정 페이지가 쿼리와 관련이 있는지 여부를 결정하는 것이 아니라, 많은 검색 결과 중 어떤 것이 특정 사용자와 가장 관련이 있는지 확인하는 것이다. 우리는 관련 검색 결과의 순서에 매우 관심이 있으며 학습 알고리즘은 더 큰 집합에서 정렬된 하위 집합을 생성해야 한다. 즉, 알파벳에서 처음 다섯 글자를 만들라고 하면 "A B C D E"와 "C A B E D"를 반환하는 것에는 차이가 있다. 결과 집합이 동일하더라도 집합 내의 순서가 중요하다.
이 문제의 가능한 해결책 하나는 먼저 세트의 모든 요소에 해당하는 관련성 점수를 할당한 다음 최상위 요소를 검색하는 것이다. 구글 검색 엔진의 PageRank는 점수 시스템의 초기 예로 적합하지만 실제 query에 의존하지 않는다는 점에서 특이했다. 오늘날 검색 엔진은 기계 학습과 행동 모델을 사용하여 쿼리 의존적 관련성 점수를 얻는다.
1.3.1.5. Recommender Systems
추천 시스템은 검색과 순위와 더불어 중요한 문제이다. 사용자에게 관련 항목 집합을 표시하는 것이 목표인 것은 비슷하다. 주된 차이점은 추천자 시스템의 맥락에서 특정 사용자에 대한 personalization를 강조한다는 것이다. 예를 들어, 영화 추천에서 공상과학 팬과 희극 감상 팬과의 결과 페이지는 상당히 다를 것이다. 소매 제품, 음악 및 뉴스 추천과 같은 다른 추천 환경에서도 유사한 문제가 발생합니다.
엄청난 경제적 가치에도 불구하고, 예측 모델 위에 단순하게 구축된 추천 시스템은 몇 가지 심각한 개념적 결함을 있다. 우선 우리는 censored feedback(검열된 피드백)만 관찰한다: 사용자는 자신이 강하게 느끼는 영화를 우선적으로 평가한다. 예를 들어, 5점 척도에서 5등급과 1등급을 많이 받지만 3등급은 눈에 띄게 적다는 것을 알 수 있다. 검열, 인센티브 및 피드백 루프를 처리하는 방법에 대한 이러한 많은 문제는 중요한 공개 연구 질문이다.
1.3.1.6. Sequence Learning
비디오 조각들은 어떻게 다룰까? 이 경우 각 조각은 서로 다른 수의 프레임으로 구성될 수 있다. 그리고 각 프레임에서 무슨 일이 일어나고 있는지에 대한 우리의 추측은 이전 프레임이나 이후의 프레임을 고려하면 훨씬 더 강력할 수 있다. 언어 또한 마찬가지이다. 한 가지 인기 있는 딥러닝 문제는 기계 번역이다. 즉, 일부 소스 언어로 된 문장을 수집하고 다른 언어로 된 문장을 예측하는 작업이다.
이러한 문제는 기계 학습에서 가장 흥미로운 응용 프로그램 중 하나이며 Sequence Learning 의 예이다. 입력 시퀀스를 수집하거나 출력 시퀀스를 방출하는 모델이 필요하다. 특히, sequence to sequence learning 은 기계 번역 및 음성 텍스트 변환과 같이 입력과 출력이 모두 가변 길이 시퀀스인 문제를 고려한다. 모든 유형의 시퀀스 변환을 고려하는 것은 불가능하지만, 다음과 같은 특별한 경우들이 언급될 가치가 있다.
Tagging and Parsing
Automatic Speech Recognition
Text to Speech
Machine Translation
1.3.2. Unsupervised and Self-Supervised Learning
지금까지의 예제들은 모두 지도학습과 관련되어 있다.
상사가 당신에게 거대한 데이터 덤프를 건네주고 그것으로 데이터 과학을 하라고 말할지도 모른다. 이것은 모호하게 들린다. 왜냐하면 그렇기 때문이다. 우리는 이 문제의 클래스를 unsupervised learning 이라고 부르고, 우리가 물어볼 수 있는 질문의 유형과 수는 우리의 창의성에 의해서만 제한된다. 이제 다음과 같은 몇 가지 질문에 대해 설명하겠습니다.
- Can we find a small number of prototypes that accurately summarize the data? Given a set of photos, can we group them into landscape photos, pictures of dogs, babies, cats, and mountain peaks? Likewise, given a collection of users’ browsing activities, can we group them into users with similar behavior? This problem is typically known as clustering .
- Can we find a small number of parameters that accurately capture the relevant properties of the data? The trajectories of a ball are quite well described by velocity, diameter, and mass of the ball. Tailors have developed a small number of parameters that describe human body shape fairly accurately for the purpose of fitting clothes. These problems are referred to as subspace estimation. If the dependence is linear, it is called principal component analysis.
- Is there a representation of (arbitrarily structured) objects in Euclidean space such that symbolic properties can be well matched? This can be used to describe entities and their relations, such as “Rome” “Italy” “France” “Paris”.
- Is there a description of the root causes of much of the data that we observe? For instance, if we have demographic data about house prices, pollution, crime, location, education, and salaries, can we discover how they are related simply based on empirical data? The fields concerned with causality and probabilistic graphical models address this problem.
- Another important and exciting recent development in unsupervised learning is the advent of generative adversarial networks. These give us a procedural way to synthesize data, even complicated structured data like images and audio. The underlying statistical mechanisms are tests to check whether real and fake data are the same.
비지도 학습의 한 형태로, 자기 지도 학습은 레이블이 없는 데이터를 활용하여 다른 부분을 사용하여 데이터의 일부 보류된 부분을 예측하는 것과 같은 훈련에 대한 감독을 제공한다. 텍스트의 경우 레이블링 노력 없이 큰 말뭉치에서 주변 단어(컨텍스트)를 사용하여 무작위로 마스크된 단어를 예측하여 모델을 "빈칸 채우기"로 훈련시킬 수 있다. 이미지의 경우 동일한 이미지의 두 잘린 영역 사이의 상대적 위치를 알려주는 모델을 교육할 수 있다.
1.3.3. Interacting with an Environment
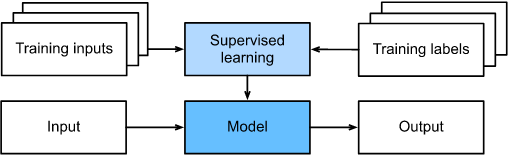
지금까지, 우리는 데이터가 실제로 어디에서 오는지, 또는 기계 학습 모델이 출력을 생성할 때 실제로 어떤 일이 일어나는지 다루지 않았다. 그것은 지도 학습과 비지도 학습이 이러한 문제를 매우 정교한 방식으로 다루지는 않기 때문이다. 어느 경우든, 우리는 먼저 큰 데이터 더미를 잡은 다음 다시는 환경과 상호 작용하지 않고 패턴 인식 기계에 작동시킨다. 왜냐하면 모든 학습은 알고리즘이 환경과 단절됐을 때 발생하고, 이것을 가끔 offline learning 이라고 한다. 지도 학습의 경우, 환경에서 데이터 수집을 고려하는 과정은 아래와 같다.
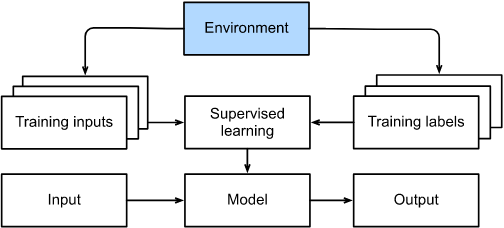
이런 오프라인 학습의 단순함에는 나름의 매력이 있다. 좋은 점은, 우리는 이러한 다른 문제들로부터 어떠한 방해도 받지 않고, 단독으로 패턴 인식에 대해 고려할 수 있다는 것이다. 하지만 단점은 문제 제형이 상당히 제한적이라는 것이다. 여기서 단순히 예측만 하는 것이 아니라 행동을 선택하는 것에 대해 고민할 필요가 있다. 게다가, 예측과 달리, 행동은 실제로 환경에 영향을 미친다. 지능형 에이전트를 훈련시키려면 해당 에이전트의 행동이 향후 관찰에 영향을 미칠 수 있는 방식을 고려해야 한다.
1.3.4. Reinforcement Learning
기계 학습을 사용하여 환경과 상호 작용하고 조치를 취하는 agent를 개발하는 데 관심이 있다면 아마도 reinforcement learning (강화 학습)에 초점을 맞추게 될 것이다. 로봇 공학, 대화 시스템 및 비디오 게임을 위한 인공지능(AI) 개발도 포함될 수 있다. 강화학습 문제에 딥러닝을 적용하는 Deep reinforcement learning 이 인기를 끌고 있다. 시각적인 입력만으로 Atari 게임에서 인간을 이긴 획기적인 딥 Q 네트워크와 보드게임 바둑에서 세계 챔피언을 물리친 알파고 프로그램이 두 가지 두드러진 예이다.
강화 학습은 agent가 일련의 시간 단계에 걸쳐 환경과 상호 작용하는 문제에 대한 매우 일반적인 설명을 제공한다. 시간 단계마다, agent는 환경으로부터 어떤 observation 을 얻게 되고 어떤 메커니즘을 통해서 다시 환경으로 전송되는 action 을 선택해야만 한다. 마지막으로, agent는 환경으로부터 보상을 받게 된다. 이 과정의 그림이 아래와 같다. 강화학습 agent의 행동은 정책에 의해 통제된다. 간단히 말해서, policy 는 환경에 대한 관찰에서 행동으로 매핑되는 기능일 뿐이다. 강화 학습의 목표는 좋은 정책을 만드는 것이다.
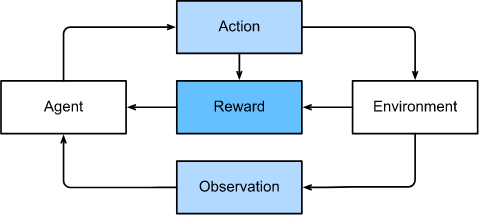
강화 학습 프레임워크의 일반성을 과장하기는 어렵다. 예를 들어, 모든 지도 학습 문제를 강화 학습 문제로 생각할 수 있다. classification에 문제가 있다고 생각해보자. 우리는 각 클래스에 대응하는 한개의 행동으로 강화 학습 에이전트를 만들 수 있습니다. 그런 다음 원래의 지도 학습 문제에서 손실 함수와 동일한 보상을 주는 환경을 만들 수 있다.
이것은 다시말해, 강화학습이 지도학습이 다루지 못한 많은 문제들을 다룰수 있다는 것이다. 예를들어, 지도학습에서는 우리는 항상 훈련 입력값이 올바른 라벨과 함께 온다고 예상한다. 하지만 강화학습에서는, 우리는 각각의 관찰에 대해 환경이 최적의 행동을 말해준다고 가정하지 않는다. 일반적으로, 우리는 약간의 보상을 받을 뿐이다. 게다가, 환경은 우리에게 어떤 행동이 보상을 초래했는지조차 말해주지 않을지도 모른다.
따라서 강화 학습자는 credit assignment 문제를 해결해야 한다. 즉, 결과에 대해 신용을 부여하거나 책임을 질 행동을 결정하는 것이다. 또한 부분적으로 관찰 가능한 문제를 다룰 수 있어야 한다. 마지막으로, 어느 시점에서든 강화 학습자는 한 가지 좋은 정책을 알고 있을 수 있지만, 에이전트가 시도하지 않은 다른 더 나은 정책이 많이 있을 수 있다는 것을 알아야 한다.
환경을 충분히 관찰하고 난 후, 이 강화학습 문제를 Markov decision process 라고 부른다. 전의 행동에 의존하지 않는 상태가 될 때, 이 문제를 contextual bandit problem 이라고 한다. 어떠한 상태도 없을 때, 초기에 알려지지 않은 보상이 있는 일련의 사용 가능한 action만 있을 때, 이 문제는 전형적인 multi-armed bandit problem 이다.
1.4. Roots
비록 많은 딥러닝 방법이 최근의 발명이지만, 데이터와 신경망(많은 딥러닝 모델의 이름)으로 프로그래밍하는 핵심 아이디어는 수세기 동안 연구되어 왔다. 사실, 인간은 오랫동안 데이터를 분석하고 미래의 결과를 예측하고자 하는 욕망을 가지고 있었고 많은 자연과학이 여기에 뿌리를 두고 있다.

생물학적 영감은 neural networks 에 이름을 붙였다. 한 세기 이상 동안(알렉산더 베인, 1873년, 제임스 셔링턴, 1890년) 연구자들은 상호작용하는 뉴런의 네트워크와 유사한 계산 회로를 조립하기 위해 노력해 왔다. 시간이 흐르면서, 생물학에 대한 해석은 덜 연관 되었지만, 그 이름은 남아있다. 오늘날 대부분의 네트워크에서 찾을 수 있는 몇 가지 핵심 원칙이 있다.
- The alternation of linear and nonlinear processing units, often referred to as layers.
- The use of the chain rule (also known as backpropagation) for adjusting parameters in the entire network at once.
초기에 급속한 발전 후에, 신경망에 대한 연구는 1995년부터 2005년까지 부진했다. 이것은 주로 두 가지 이유 때문이었다. 첫째, 네트워크를 훈련을 위해 계산비용이 매우 많이 든다. 지난 세기 말에는 랜덤 액세스 메모리가 풍부했지만, 계산 능력은 부족했다. 둘째, 데이터 세트는 상대적으로 작았다. 실제로 1932년 피셔의 아이리스 데이터 세트는 알고리즘의 유효성을 테스트하는 데 널리 사용되는 도구였다. 손으로 쓴 6만 개의 숫자가 있는 MNIST 데이터 세트는 거대하다고 여겨졌다.
데이터와 계산의 부족을 감안할 때, kernel methods, decision trees 및 graphical models와 같은 강력한 통계 도구가 경험적으로 우수하다는 것이 입증되었다. 신경망과 달리 훈련에 몇 주가 걸리지 않았고 강력한 이론적 보장과 함께 예측 가능한 결과를 제공했기 때문이다.
1.5. The Road to Deep Learning
World Wide Web, 수억 명의 사용자를 온라인으로 서비스하는 기업의 출현, 저렴한 고품질 센서, 저렴한 데이터 스토리지(Kryder's Law), 특히 GPU로 저렴한 컴퓨팅(Moore's Law)의 보급으로 인해 이러한 많은 양의 데이터가 즉시 사용 가능해짐에 따라 많은 것이 바뀌었다. 계산적으로 불가능해 보이는 알고리즘과 모델들이 갑자기 관련성이 있게 되었다.
결과적으로, 기계 학습과 통계학에서 스위트 스팟은 (일반화된) 선형 모델과 커널 방법에서 deep neural networks(심층 신경망)으로 이동했다. 이것은 또한 상당 시간 동안 암흑기 상태였던 multilayer perceptrons , convolutional neural networks, long short-term memory, Q-Learning 과 같은 딥러닝의 핵심들이 지난 10년 후에 "다시 발견된" 이유들 중 하나이다.
- 딥러닝 프레임워크는 아이디어를 전파하는 데 중요한 역할을 해왔다. 간편한 모델링을 가능하게 하는 1세대 프레임워크는 Caffe, Torch, Theano가 있다. 많은 중요한 논문이 이 도구들을 사용하여 작성되었다. 현재는 TensorFlow(고급 API Keras를 통해 종종 사용됨), CNTK, Caffe2, Apache MXNet으로 대체되었다. 딥러닝을 위한 필수 도구라 여겨지는 3세대 도구는 모델을 설명하기 위해 Python NumPy와 유사한 구문을 사용한 Chainer에 의해 주도되었다. 이 아이디어는 PyTorch, MXNet의 Gluon API, 그리고 Jax에 의해 채택되었다.
더 나은 도구를 구축하는 연구자와 더 나은 신경망을 구축하는 통계학적 모델링의 분업은 일을 크게 단순화시켰다. 예를 들어, 선형 로지스틱 회귀 모델을 훈련하는 것은 2014년 카네기 멜론 대학의 새로운 기계 학습 박사 학생들에게 줄 가치가 있는 사소한 숙제 문제였습니다. 하지만 이제 이 작업은 10줄 이하의 코드로 수행될 수 있다.
1.6. Success Stories
machine learning은 비록 보이지 않지만 널리 퍼져 있다. AI가 각광을 받고 있는 것은 최근의 일로, 이전에는 다루기 힘들다고 여겨졌던 문제에 대한 해결책과 소비자와 직접적인 관련이 있는 것이 주요인이다. 그러한 발전의 많은 부분은 딥러닝에 기인한다.
1.7. Characteristics
1.8. Summary
-
Machine learning studies how computer systems can leverage experience (often data) to improve performance at specific tasks. It combines ideas from statistics, data mining, and optimization. Often, it is used as a means of implementing AI solutions.
-
As a class of machine learning, representational learning focuses on how to automatically find the appropriate way to represent data. Deep learning is multi-level representation learning through learning many layers of transformations.
-
Deep learning replaces not only the shallow models at the end of traditional machine learning pipelines, but also the labor-intensive process of feature engineering.
-
Much of the recent progress in deep learning has been triggered by an abundance of data arising from cheap sensors and Internet-scale applications, and by significant progress in computation, mostly through GPUs.
-
Whole system optimization is a key component in obtaining high performance. The availability of efficient deep learning frameworks has made design and implementation of this significantly easier.
