
데이터 베이스
여러 사람이 공유하고 사용할 목적으로 통합 관리되는 데이터들의 모임
데이터 베이스 특징
- 실시간 접근성 - 비정형적인 조회에 대해 실시간으로 응답 가능하다.
- 동시 공용 - 여러 사용자가 같은 내용의 데이터를 사용할 수 있다.
- 지속적인 변화 - DB는 항상 최신의 데이터를 유지해야 한다.
- 내용에 의한 참조 - 사용자가 원하는 내용으로 데이터를 찾는다.
DBMS
데이터베이스 내 데이터에 접근하도록 도와주는 시스템
데이터 베이스 언어
-
DDL (Data Definition Language)
데이터 베이스 구조를 정의, 수정, 삭제하는 언어
--> create, alter, drop -
DML (Data Manipluation Language)
데이터 베이스 내 자료를 검색, 수정, 삽입, 삭제하는 언어
--> select, insert, update, delete -
DCL (Data Control Language)
데이터에 대해 무결성을 유지, 보호와 관리를 위한 언어
--> commit, revoke, grant, rollback- 무결성
데이터의 정확성, 일관성, 유호성이 유지되는 것
정확성 - 중복 또는 누락이 없는 것
일관성 - 변하지 않는 것
- 무결성
DB 쿼리 실행 순서
From, on, join > where, group by, having > select > distinct > order by > limit
group by 란?
특정 컬럼을 그룹화하는 것이며 distinct처럼 중복을 제거하는 것이 특징
delete, truncate, drop 차이
- delete
테이블 내 원하는 데이터만 삭제할 수 있으며 테이블 용량은 변함이 없다.
데이터 삭제 후 되돌릴 수 있다 -> rollback - truncate
테이블 내 데이터를 한 번에 지우는 방식으로 테이블 용량도 줄고 인덱스도 삭제된다.
테이블을 지울 수 없으며 데이터 삭제 후 되돌릴 수 없다. - drop
테이블 자체를 삭제하는 방식이며 삭제 후 되돌릴 수 없다.
having, where 차이
- having
그룹을 필터링할 때 사용하며 집계함수 사용 가능하다. - where
개별 행에 필터링하는데 사용하며 집계 함수 사용 불가능하다 -> 집계 전 필터링하는 데 사용
join
두 테이블을 결합하는 연산
왜 join을 사용하나? 여러 테이블의 데이터를 조합하여 처리하기 위해!
inner join, outer join 차이
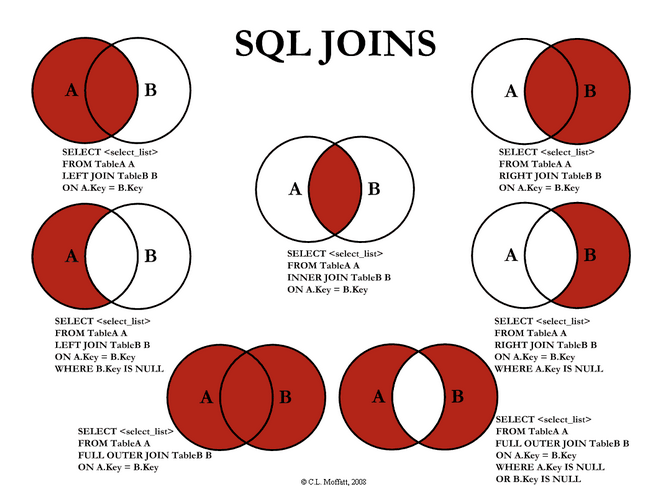
- inner join
서로 연관된 내용만 검색하는 조인 방법 즉 교집합 - outer join
한 쪽에는 데이터가 있고 다른 쪽에는 데이터가 없는 경우, 데이터가 있는 쪽의 내용이 모두 출력되는 조인 방법 즉 합집합
left join, right join 차이
- left join
왼쪽 테이블 기준으로 오른쪽의 테이블을 매치하고 왼쪽 테이블을 모두 출력한다.
왼쪽은 무조건 표시하고 매치되는 레코드가 없으면 null 표시 - right join
오른쪽 테이블 기준으로 왼쪽 테이블을 매치하고 오른쪽 테이블을 모두 출력한다.
오른쪽은 무조건 표시하고 매치되는 레코드가 없으면 null 표시
join 사이에서 and는 join 조건만 사용하며
전체 쿼리에 대한 조건은 맨 아래 where and (-----) 사용하는 것이 좋다.
join 절 pk 쓰는 이유?
pk 설정 시 index도 설정된다. 즉 쿼리 탐색 속도가 높아진다.
join에서 on과 where 차이
on이 where보다 먼저 실행되어 join하기 전에 필터링이 되며
where은 join한 후 필터링이 된다.

안녕