Reinforcement Learning 강화학습 개요
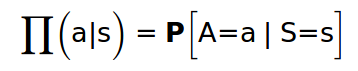
- Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto 책에 챕터 1 인트러덕션 파트의 모르는 부분을 다른 아티클들과 더불어 정리했습니다.
책의 요약은 아래 미디엄에 영문으로 1-1, 1-2, 1-3으로 저장해뒀습니다.
shorturl.at/vyGJU
- 이 글은 https://www.g2.com/articles/reinforcement-learning 와 여러 reference의 내용을 번역, 정리한 글이며 가장 기초적인 개념을 담은 글입니다. 오역, 틀린 내용은 댓글로 부탁드립니다. 내용은 의역하여 정리 하였습니다.
누군가는 강화학습은 학습과정을 게임화시키는 것과 같다고 했다. 이런 말이 나오게된 이유는 뭘까? 강화학습은 시행착오의 과정을 겪기 때문이다. 옳은 action을 취하면 보상을 받고 틀린 action을 취하면 환경에서 페널티를 준다. 한마디로 강화학습은 빨리 받아들이고 배우게 하거나 많은 보상을 잃게 한다. 이런 과정에서 사람의 지도학습은 필요하지 않다. 강화학습은 머신이 실수로 하여금 배우게 하고 trial and error라는 방법으로 문제를 풀게한다. 과거의 데이터들이 중요했던 SL(Supervised learning)과는 다르게 스스로의 action에서 배우게 된다. 이 학습하는 머신을 우리는 agent/learner라고 부른다.
이 학습 시스템은 환경에 explore/observe 행동을 하게되는데 이때 The Exploration — Exploitation Dilemma가 오기도 한다. 이 딜레마는 explore(탐험)과 exploit(공적)들 사이에서 오는 딜레마인데 목표지향적인 RL의 목적지는 주어진 states들의 가장 잘 알려진 액션을 고르는 것이기 때문이다. 하지만 Richard S. Sutton and Andrew G. Barto의 책에 의하면, 이는 수학적으로도 아직 제대로 밝혀진것이 없어서 그냥 우리가 알아둬야 할 점은 RL의 학습 특성상 SL, UL에서는 이런 딜레마가 없는데 RL만 가지고 있다는 것이다.
강화학습은 모든 상황에서 대입할 수 있는 답은 아님을 유의하자. 예를 들면, 문제를 풀 데이터가 충분한 상황에서는 SL를 쓰는 것이 더 이상적이다. RL는 시간소비가 많이 되므로 다른 학습들보다도 많은 컴퓨터 자원들을 소비한다.
용어들을 알아보자.
agent, decision maker, leaner: 학습을 하는 ai 시스템을 의미.
action: agent가 움직일수 있는 모든 가능성들의 set
environment: agent의 움직일 수 있는 세상이며 agent가 feedback을 주는 환경. 환경은 현재 state(agent가 있는)와 action(agent가 현재 취하는)을 입력받고 reward, 다음 state를 뱉어낸다.
state: 에이전트가 스스로 찾아낸 상황. 환경의 어떤 한 지점이나 순간이라 표현 할 수 있겠다.
reward: 한 액션마다, 에이전트는 환경으로부터 보상을 받는데 이는 positive(긍정) / negative(부정)일 수 있다.
policy: 에이전트가 다음 액션을 결정하는 전략이다. 가장 큰 리워드를 받는 액션을 선택하기 위해 state와 action을 매핑한다.
model: 환경을 보는 agent의 시각. 위에서 policy가 매핑한 state-action pair를 확률분포(probability distributions)에 매핑한다. (일반적으로, 확률분포는 다양한 타입들이 있는것 같다.[1])
value function: 간단히 말하자면, v.f.는 얼마나 state가 agent에 우호적인가를 말해준다. state의 밸류는 에이전트의 장기적 리워드를 나타내기 때문이다.
discount factor (γ): discount factor는 얼마나 agent가 당장의 현재와 조금 먼 시간에서 리워드를 중요하게 생각하는가를 결정하는 요소. γ는 0-1사이에 위치. 만약 0이라면, agent는 당장의 리워드를 원할것이고 1이라면 action들을 평가할때 미래 리워드의 전체 합을 생각해서 계산할것이다.
RL의 중요한 요소들
이 내용에선 [2],[3]을 같이 적절히 섞어 번역했습니다. 그림들은 다 [2]의 아티클에서 발췌하였습니다.
1. policy:
현재 state부터의 action을 결정하는 전략. agent의 행동은 항상 스스로 결정하는것이기에 전략이 중요함.
1) stochastic policy
만약, agent가 다음 방향을 어느쪽으로 정해야할지 모를때는 랜덤한 확률을 여러방향으로 줘서 계산한다. 이를 stochastic policy라고한다.
[2]
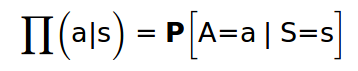
여기서 프로덕트는 어떤 팔러시를 선택했는가를 나타내고, a는 action, s는 current state를 나타낸다.
2) deterministic Policy
체계적인 접근방식을 취하고 있다면 이미 어느 시점에서 어떤 방향으로 가야하는지 알고 있으므로, 상태를 작업에만 매핑하면 됨(랜덤한 확률 불필요)
[2]
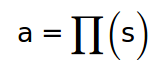
2. Reward signal:
매 state마다, 에이전트 the reward signal or simply reward라고 불리는 시그널을 환경에서 바로 받는데, 에이전트가 어떤 액션을 취했느냐에 따라 리워드는 positive/negative가 나온다. 리워드 시그날은 에이전트가 전략(policy)를 바꾸게 할 수 있다. 예를 들자면, 만약 에이전트의 액션이 부정적인 리워드를 이끌어냈다면 에이전트는 전체 리워드를 위해서 팔러시를 바꾸게 된다.
3. Value Function
value function은 에이전트가 리워드와 장해물에 가중치를 둠으로써 어떤 방향으로 향하는게 더 현실가능성이 높은지를 알려준다.
[2]
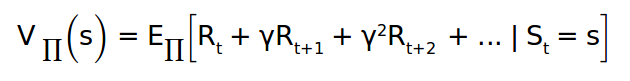
s는 현재 state이다. 프러덕트는 에이전트의 행동을 정하는 팔러시이고, 지금 이 식에서 프러덕트는 delayed reward를 하고 있다. R은 state를 감으로써 얻은 리워드를 의미한다. ‘γ'는 가중치가 미래 리워드에 영향을 끼치게 돕는 디스카운트 요소이다.
정리하자면, state안에서의 밸류는 현재 리워드와 그 상태에서 다른 선택을 하면 얻을 수 있는 미래 리워드의 총합이다. 우리는 미래 리워드를 낮게 측정하는데 확실하지 않기 때문이다.
Model
[2][4]
1) model free RL
특정한 state에 도달하기 위한 액션을 결정하는 것이 중요하다. learning자체가 중요하니까 경험을하는것과 결정을 내리는 과정이 중요하다.
2) model based RL
Transition Model, Reward Model등이 모델의 종류안에 있다. 경로를 중요하게 보기때문에 planning을 강조하는 경향이 있다.
[4]
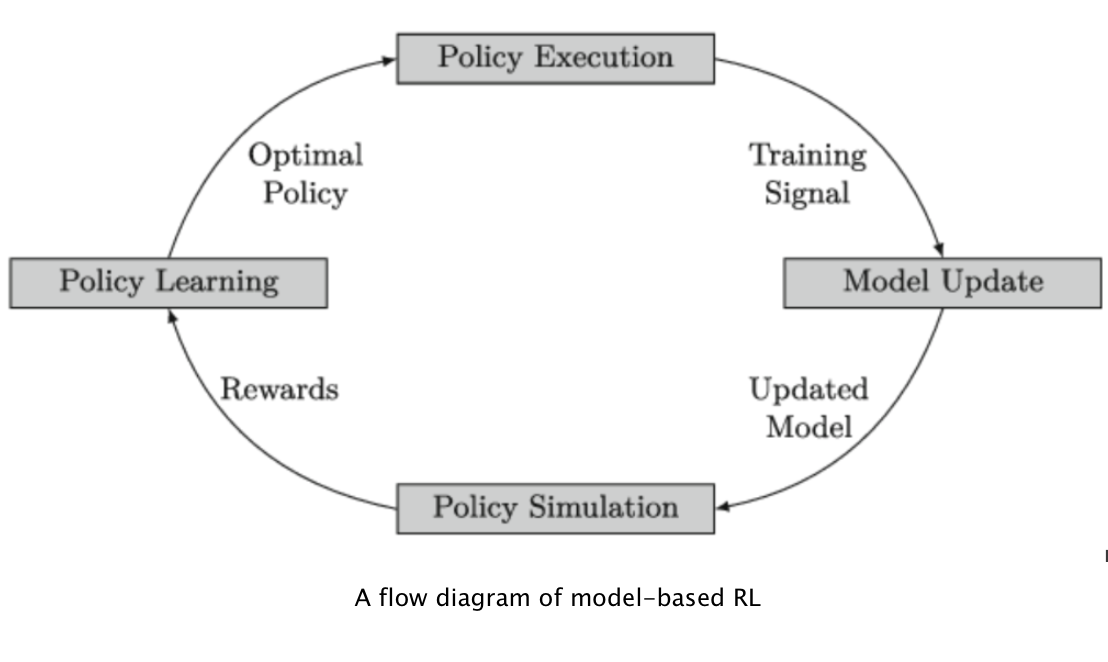
보통 모델기반의 RL이 더 샘플에 효율적이다. 무슨 말이냐면, 팔러시를 배우기 위한 데이터가 덜 필요하다. 예를 들면 m-b RL은 그냥 반응하기보다 계획을 할 수 있고 실제 환경에서 직접 해보지 않고도 시뮬레이션이 가능하다.
모델에 대한 더 자세한 내용들과 어떻게 팔러시를 어플라이하는지, 밸류펑션은 어떻게 어플라이하는지등을 다음에 정리하도록 하겠다.
Reference
[1] https://www.analyticsvidhya.com/blog/2017/09/6-probability-distributions-data-science/
[2]https://becominghuman.ai/components-of-an-rl-agent-and-its-application-on-snake-1b3b6c8e1de5
