개념
정규표현식(Regular Expression)
- 문자열을 처리하는 방법 중의 하나
- 특정한 조건의 문자를 '검색'하거나 '치환'하는 과정을 매우 간편하게 처리 할 수 있도록 하는 수단
ZVON - Regular Expression Tutorial
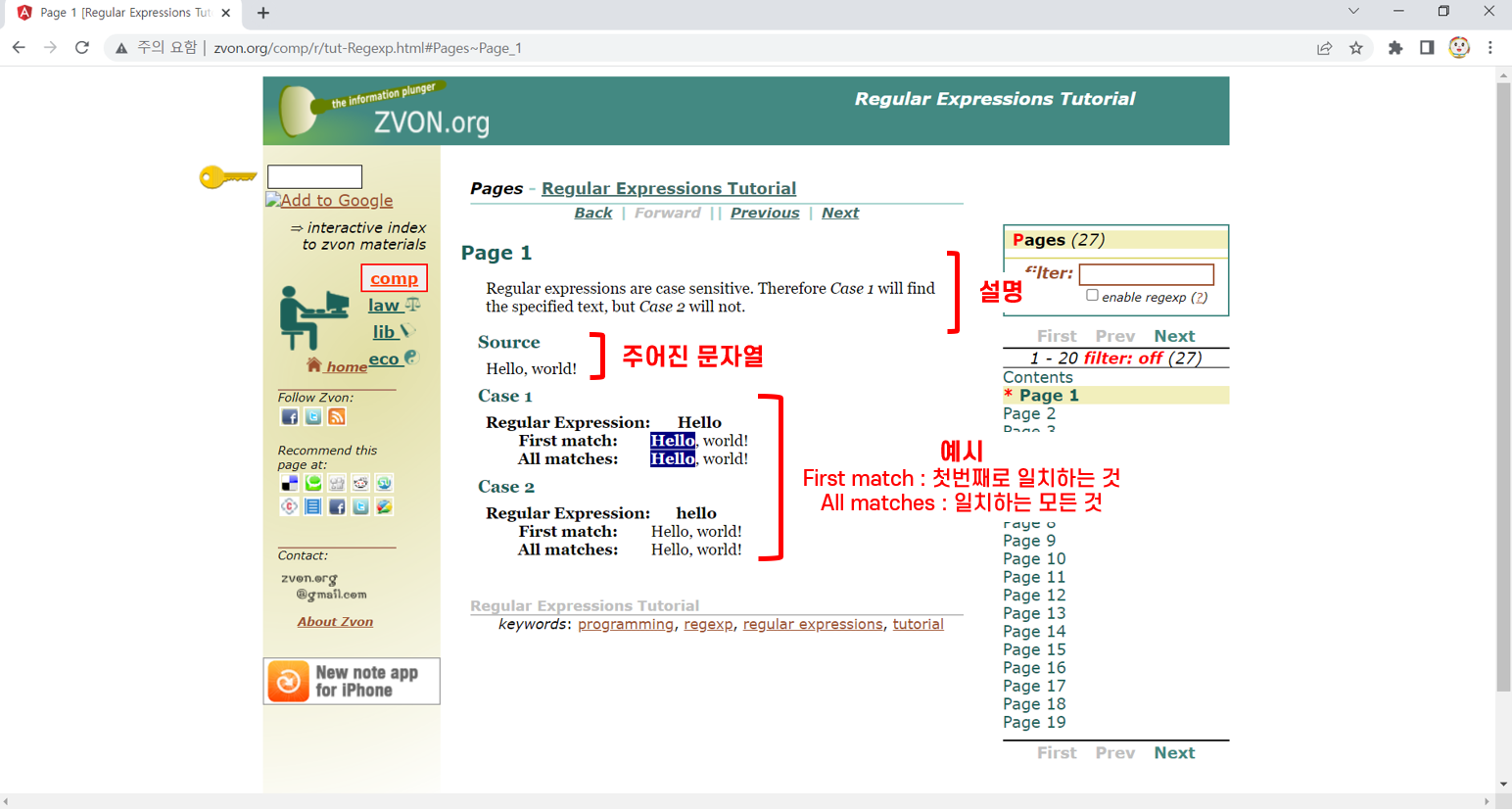
정규표현식 정리를 위해 ZVON-Regular Expressions Tutorial을 학습했다. Inflearn 강의를 참고하여 정리했다. 해당 서비스의 화면 및 설명은 아래와 같다. 메인 화면에서 Page를 선택하면 상세 화면으로 넘어간다.
원칙
기본
- 대소문자 구분
- 띄어쓰기 구분
위치와 이스케이핑
- ^<문자> : <문자>로 시작
- <문자>$ : <문자>로 끝
- \<문자> : <문자>를 문법적으로 해석하는 것이 아니라 <문자> 그 자체로 인식 (escape)
- \$ : 문자열에 있는 $을 찾음
모든 문자
- . : 아무 문자 1개 (문자열 전체)
- . n개 : 아무 문자 n개 (앞에서부터 n개씩 끊어 인식)
- 0123456789012 → ...... 적용 → 0123456789012
특정 문자
- [] : 문자 후보 중 해당하는 1개
- [AHQ] : A, H, Q 중 하나
- [-] : 범위 지정
- [A-Z] : 알파벳 대문자 A부터 Z까지 모두
- [a=z] : 알파벳 소문자 a부터 z까지 모두
- [0-9] : 숫자 0부터 1까지 모두
- [^] : 후보에 해당하는 것을 제외 (부정)
서브 패턴
- ( | ) : 문자열 후보
- (apple|grape|orange) : apple, grape, orange 중 하나
수량자
-
<문자>* : <문자>가 0개~여러개 존재 (있을수도 있고 없을수도 있음)
-
<문자>+ : <문자>가 1개~여러개 존재 (반드시 1개 이상)
-
<문자>? : <문자>가 0개~1개 (없거나 1개)
-
{<숫자>} : <숫자> 개수 만큼
-
{<숫자>,} : <숫자> 이상
- {1, } = +
- {0, } = *
-
{<숫자1>, <숫자2>} : <숫자1> 이상 <숫자2> 이하
- {0,1} = ?
-
<수량자>? : <수량자> 범위 중 가장 작은 수를 의미 (게으른 수량자)
- 탐욕적인 수량자 방지
- div 태그로 감싸진 각각을 선택하고 싶은데 전체가 선택되는 예시
<div>test</div> <div>test2</div> <!-- <div>.+</div>로 검색 시 전체가 체크 (Greedy)--> <!-- <div>+?</div>로 검색 시 첫 번째 div 태그 세트만 체크 (Lazy)--> - *? : 0개
- +? : 1개
- 탐욕적인 수량자 방지
경계
- w (word)
- \w : 단어 (공백X, 특수문자 X)
- [A-z0-9__]와 의미 동일
- \w<숫자> : <숫자> 길이인 단어
- \W : 단어 X (공백, 특수문자)
- \w : 단어 (공백X, 특수문자 X)
- d (digit)
- \d : 숫자
- [0-9]와 의미 동일
- \D : 숫자 X
- \d : 숫자
- b (boundary)
- \b : 범위
- \b\w : 단어 시작 범위 (첫 문자)
- \w\b : 단어 끝 범위 (마지막 문자)
- \b\w\b : 길이가 1인 단어만 표시
- \b<문자> : 문자열 시작에 있는 <문자>
- <문자>\b : 문자열 끝에 있는 <문자>
- \B : 범위 X (범위 제외한 모두)
- \b : 범위
- A or Z
- \A : 전체 문자열에서 시작점
- \A... : 전체 문자열의 시작에 존재하는 문자 3개
- \A<문자> : 전체 문자열의 시작에 존재하는 <문자>
- \Z : 전체 문자열에서 끝점
- \A : 전체 문자열에서 시작점
전방/후방 탐색
- (?=<문자>) : <문자>로 검색은 하지만 선택 결과에 <문자> 미포함
