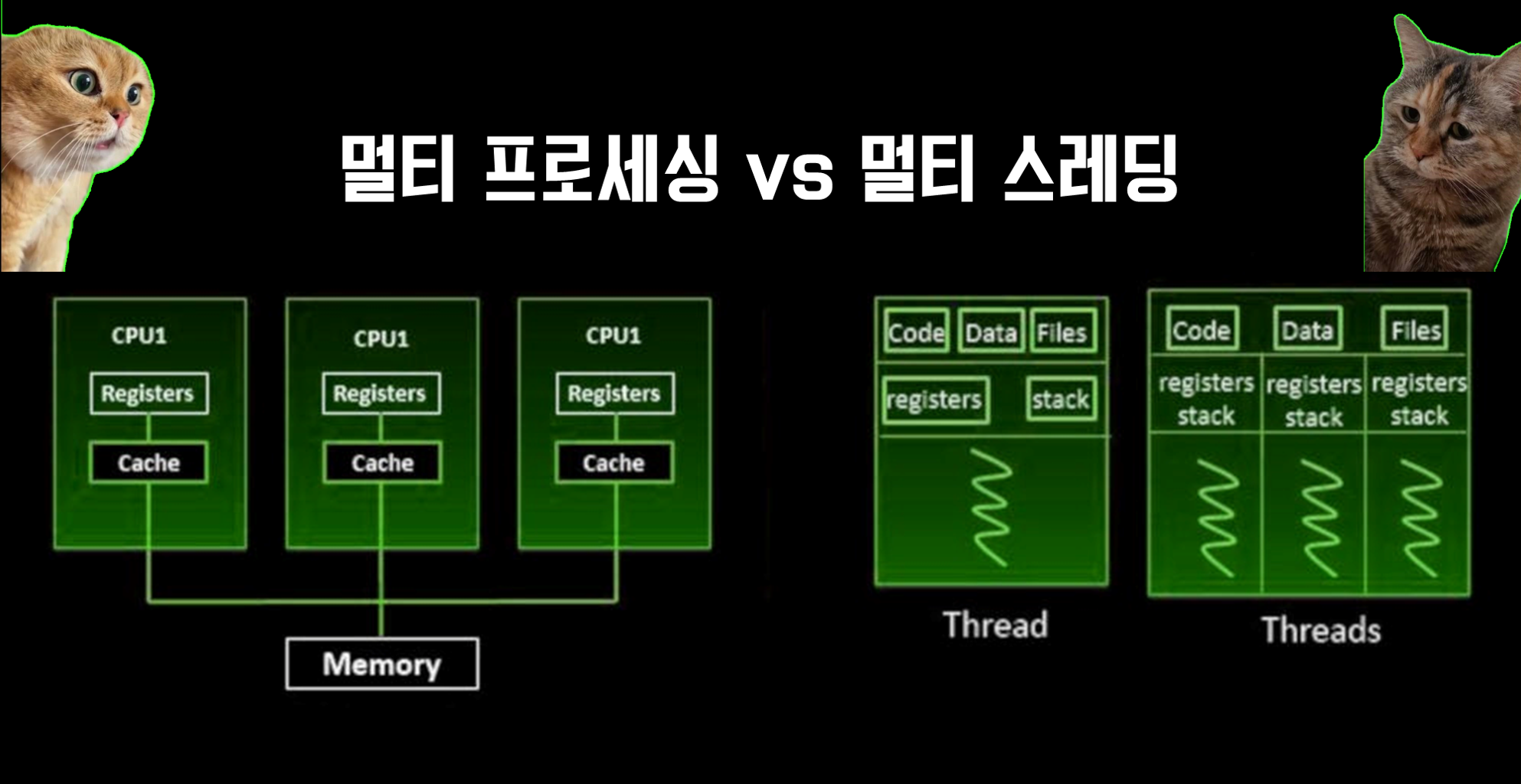
멀티프로세싱과 멀티스레딩에서 자원 분할과 작업 할당은 각각 다르게 이루어집니다. 이 과정을 이해하기 위해서는 먼저, 컴퓨터의 자원(특히 CPU와 메모리) 사용 방식과 작업의 종류(예: CPU 집약적 vs. I/O 집약적)를 고려해야 합니다.
멀티프로세싱(Multiprocessing)의 자원 분할
멀티프로세싱에서는 각 프로세스가 독립된 메모리 공간을 가집니다. 이는 각 프로세스가 시스템의 자원을 독립적으로 할당받는다는 의미입니다. CPU 자원의 분할은 운영 체제의 스케줄러에 의해 관리되며, 여러 프로세스 간에 CPU 시간을 공정하게 분배합니다.
작업이 N개의 프로세스에 분배될 때, 이론적으로는 각 프로세스에 작업의 1/N을 할당할 수 있습니다. 하지만 실제 분할은 작업의 성격, 프로세스의 실행 상태, 시스템의 다른 요구 사항 등에 따라 달라질 수 있습니다. 예를 들어, 어떤 프로세스는 CPU를 많이 사용하는 반면, 다른 프로세스는 대기 상태에 있을 수 있습니다.
멀티스레딩(Multithreading)의 자원 분할
멀티스레딩에서는 모든 스레드가 프로세스의 메모리 공간을 공유합니다. 따라서, 메모리 자원은 별도로 분할되지 않고, 모든 스레드가 같은 메모리 영역에 접근할 수 있습니다. CPU 자원의 경우, 운영 체제의 스레드 스케줄러가 각 스레드에 CPU 시간을 할당합니다.
스레드 간의 작업 분할은 프로세스 내에서 이루어지며, 스레드가 수행하는 작업은 일반적으로 더 작고, 구체적인 작업 단위로 나누어집니다. 멀티스레딩 환경에서는 I/O 작업이 진행되는 동안 다른 스레드가 CPU를 사용할 수 있어, 전체적인 프로그램의 효율성을 높일 수 있습니다.
⭐ (Q&A) 여기서 잠깐!!
Q. 멀티프로세스에서 `프로세스A`와 `프로세스B`가 있다고 가정해보겠습니다. 그럼 4이라는 가용 자원이 있을때 만약 프로세스A가 먼저 끝나면 나머지 프로세스인 프로세스B가 남은 자원 4개를 다 쓰도록 바뀌도록 자동으로 할당해주나요?A. 실제로 프로세스A가 종료되어 자원이 반환될 때, 프로세스B가 자동으로 모든 자원을 활용하도록 시스템이 재조정되는 것은 보장되지 않습니다. 자원의 재할당은 운영 체제의 스케줄링 알고리즘과 정책에 따라 결정되며, 다른 대기 중인 프로세스나 시스템의 전반적인 자원 관리 전략에 의해 영향을 받습니다. 프로세스B가 추가 자원을 활용하려면, 해당 프로세스가 병렬 처리를 지원하고 추가 CPU 코어를 효율적으로 활용할 수 있는 구조로 설계되어야 합니다.
⭐ 추가 설명: 자원 할당의 동작 방식
✅ CPU 코어 할당: 가용 자원이 CPU 코어라고 할 때, 각 프로세스는 운영 체제에 의해 하나 이상의 CPU 코어에 할당될 수 있습니다. 프로세스A와 프로세스B가 각각 2개의 CPU 코어를 사용하고 있다면, 이는 프로세스가 실행되는 동안 동시에 2개의 작업을 수행할 수 있음을 의미합니다.✅ 동적 재할당: 프로세스A가 작업을 완료하고 종료되면, 그 프로세스에 할당되었던 자원(여기서는 CPU 코어)은 시스템에 반환됩니다. 이후 운영 체제의 스케줄러는 이제 사용 가능한 자원을 다시 분배할 수 있게 됩니다. 하지만, 자동으로 프로세스B가 나머지 자원을 모두 사용하도록 할당받는 것은 자동으로 이루어지지 않습니다.✅ 자원의 재할당 조건: 프로세스B가 추가적인 CPU 코어를 사용할 수 있게 되는지 여부는 여러 요소에 의해 결정됩니다. 이는 운영 체제의 스케줄링 정책, 프로세스의 우선순위, 그리고 프로세스B가 추가 자원을 효과적으로 활용할 수 있는지(예: 병렬 처리가 가능한 작업인지)에 따라 달라질 수 있습니다.✅ 자원 사용의 최적화: 대부분의 현대 운영 체제는 시스템 자원을 효율적으로 활용하기 위한 복잡한 스케줄링 알고리즘을 사용합니다. 프로세스A가 종료되어 자원이 반환되면, 이 자원은 시스템의 다른 대기 중인 프로세스에 할당될 수 있습니다. 그러나, 특정 프로세스가 자동으로 모든 가용 자원을 독점하도록 시스템이 재조정하는 것은 일반적인 경우가 아닙니다.
작업 할당 방식
실제 작업 할당은 애플리케이션 레벨에서 개발자가 결정합니다. 멀티프로세싱이나 멀티스레딩을 사용할 때, 각각의 프로세스나 스레드에 할당할 작업의 크기와 범위는 프로그램의 구조와 요구 사항에 따라 달라집니다. 예를 들어, 데이터 처리 작업을 여러 프로세스에 분배할 때는 각 프로세스가 처리할 데이터의 양을 균등하게 나누거나, 특정 조건에 맞는 데이터를 할당하는 방식으로 분할할 수 있습니다.
멀티프로세싱과 멀티스레딩 모두 작업의 병렬 처리를 통해 성능을 향상시키지만, 그 구현 방식과 사용 사례는 크게 다릅니다. 멀티프로세싱은 독립적인 작업이 많고, 각 작업이 상당한 양의 CPU 자원을 필요로 할 때 유리하며, 멀티스레딩은 작업 간에 자원을 공유해야 하거나 I/O 바운드 작업이 많을 때 효과적입니다.
작업 할당과 자원 분배 방식에 대해 더 자세히 설명하겠습니다. 기본적으로, 멀티프로세싱과 멀티스레딩 환경에서의 자원 할당은 자동과 수동(개발자 지정) 방식을 모두 포함할 수 있습니다.
자동 할당(시스템)
- 가용 자원의 자동 분배: 운영 체제의 스케줄러가 프로세스나 스레드에 대해 CPU 시간을 자동으로 할당합니다. 이 경우, 스케줄러는 시스템의 현재 부하, 프로세스의 우선순위, 프로세스의 상태(실행 중, 대기 중 등)와 같은 여러 요인을 고려하여 자원을 분배합니다. 디폴트로, 시스템은 가능한 공정하게 자원을 분배하려고 시도하지만, 이는 "1/N"이라는 고정 비율로 정확히 분배된다는 의미는 아닙니다.
수동 할당(개발자 지정)
- 개발자에 의한 명시적 분배: 개발자는 프로그램의 요구 사항과 작업의 특성을 고려하여, 각 프로세스나 스레드에 할당될 작업의 양이나 자원의 사용을 명시적으로 지정할 수 있습니다. 예를 들어, 데이터 처리 작업을 여러 프로세스에 분배할 때 특정 기준에 따라 작업을 나눌 수 있으며, 이는 작업의 효율성과 실행 시간에 영향을 미칠 수 있습니다.
멀티프로세싱 자원 할당 예시
이 예시에서는 대량의 데이터를 4개의 청크로 나누고, 각 청크를 별도의 프로세스에 할당하여 병렬로 처리합니다. 이는 개발자가 작업의 분배를 명시적으로 지정한 경우입니다.
from multiprocessing import Pool
def my_task(data_chunk):
# 복잡한 계산 수행
result = sum(data_chunk)
return result
if __name__ == "__main__":
data = range(1000000) # 대량의 데이터
chunks = [data[i::4] for i in range(4)] # 데이터를 4개의 청크로 나눔
with Pool(4) as p: # 4개의 프로세스 풀 생성
results = p.map(my_task, chunks) # 각 청크를 별도의 프로세스에 할당위 파이썬 코드에서 multiprocessing.Pool을 사용하여 멀티프로세싱을 구현할 때, 자원 할당은 다음과 같이 이루어집니다:
프로세스 풀과 CPU 코어 할당
-
프로세스 풀 생성: Pool(4)에 의해 4개의 별도 프로세스가 생성됩니다. 이는 멀티프로세싱을 위한 프로세스 풀로, 병렬 작업을 수행하기 위해 준비된 프로세스 집합입니다. -
CPU 코어 사용: 시스템에 8개의 CPU 코어가 있는 경우, Pool(4)에 의해 생성된 각 프로세스는 이용 가능한 CPU 코어 중 하나를 사용할 수 있게 됩니다. 여기서 중요한 점은, 프로세스 풀에 의해 생성된 프로세스 수가 시스템의 CPU 코어 수보다 적기 때문에, 모든 프로세스가 동시에 실행될 수 있으며, 각각 별도의 CPU 코어에 할당될 가능성이 높습니다.
작업 처리 방식
-
병렬 처리: 생성된 4개의 프로세스는 동시에 실행되어 각각 할당된 작업(데이터 청크)을 처리합니다. 시스템에 여유 코어가 충분히 있기 때문에, 이 프로세스들은 서로 경쟁 없이 각자의 코어에서 실행될 수 있습니다. -
자원 활용 최적화: 8개의 코어 중 4개만 사용되므로, 나머지 코어는 시스템의 다른 프로세스나 작업에 사용될 수 있습니다. 이는 멀티태스킹 환경에서 시스템 자원을 효율적으로 활용할 수 있게 해줍니다.
(참고) 그럼 어떻게 해야 가용 자원을 다 쓸 수 있을까?
파이썬의 `multiprocessing` 모듈은 프로세스당 CPU 코어 수를 직접 지정하는 기능을 직접 제공하지 않습니다. CPU 코어의 할당과 스케줄링은 운영 체제의 작업이며, `multiprocessing` 라이브러리는 이러한 낮은 수준의 자원 관리에 직접 개입하지 않습니다. 그러나, 전체 CPU 코어를 최대한 활용하려는 목적이라면, 작업을 더 많은 프로세스에 분배하거나 시스템의 병렬 처리 능력을 최대로 활용하는 방법을 고려할 수 있습니다.ㅤ전체 CPU 코어 사용하기 : 시스템에 있는 모든 CPU 코어를 사용하려면, `multiprocessing.cpu_count()` 함수를 사용하여 시스템에 있는 코어의 수를 확인하고, 이를 `Pool`의 인자로 사용할 수 있습니다. 이 방법은 시스템의 모든 CPU 코어를 활용하여 병렬 처리를 수행하려는 경우 유용합니다. 아래 예시를 참고해주세요 🤗
# 전체 CPU 코어 사용하기
from multiprocessing import Pool, cpu_count
def my_task(data_chunk):
# 복잡한 계산 수행
result = sum(data_chunk)
return result
if __name__ == "__main__":
data = range(1000000) # 대량의 데이터
num_cores = cpu_count() # 시스템의 CPU 코어 수 확인
chunks = [data[i::num_cores] for i in range(num_cores)] # 데이터를 CPU 코어 수만큼 청크로 나눔
with Pool(num_cores) as p: # 시스템의 모든 CPU 코어 사용
results = p.map(my_task, chunks)멀티스레딩 자원 할당 예시
이 멀티스레딩 예시에서는 전체 작업 범위를 4개로 나누어 각 스레드가 처리하도록 합니다. 이러한 방식은 각 스레드가 처리할 데이터의 양을 명확하게 지정할 수 있기 때문에, 작업의 분배가 고르게 이루어지도록 할 수 있습니다.
import threading
def my_task(start, end):
# 범위 내의 숫자 합계 계산
result = sum(range(start, end))
print(f"Result: {result}")
threads = []
for i in range(4):
# 전체 범위를 4개의 부분으로 나누어 각 스레드에 할당
t = threading.Thread(target=my_task, args=(250000*i, 250000*(i+1)))
threads.append(t)
t.start()
for t in threads:
t.join()제시된 예시 코드에서는 각 스레드가 처리하는 데이터의 양을 균등하게 분배하였습니다. 이는 각 작업 단위가 동일한 자원을 소비한다고 가정했을 때 유용합니다. 하지만 실제로는 작업의 복잡도가 다를 수 있으므로, 위에서 언급한 방법들을 통해 작업 분배 방식을 보다 세밀하게 조정할 필요가 있습니다.
작업의 복잡도나 자원 소비량을 고려하여 작업을 할당하는 것은 멀티스레딩 프로그램의 성능을 최적화하는 데 중요한 요소입니다. 따라서, 작업의 특성을 정확히 파악하고, 이에 기반한 적절한 작업 분배 전략을 선택하는 것이 중요합니다.
(참고) 그렇다면 어떻게 멀티스레딩 프로그램의 성능을 최적화를 할까?
queue를 사용해서 task의 복잡도를 정의하고 이를 args로 넣어주면 각 스레드가 처리할 데이터의 양을 명확하게 정의해줄 수 있습니다. (아래 예시코드 참고)
import time
import queue
# 작업 함수
def worker(work_queue):
while not work_queue.empty():
try:
# 큐에서 작업을 가져옴
task = work_queue.get_nowait()
except queue.Empty:
break
# 작업의 내용(여기서는 단순히 일정 시간 대기하는 것으로 가정)
print(f"{threading.current_thread().name} is processing task: {task}")
time.sleep(task)
print(f"{threading.current_thread().name} finished task: {task}")
# 작업 완료를 큐에 알림
work_queue.task_done()
# 작업 큐 생성 및 작업 추가
work_queue = queue.Queue()
tasks = [2, 4, 6, 8, 1, 3, 5, 7] # 각 숫자는 작업의 "복잡도"를 나타냄(예: 처리 시간)
for task in tasks:
work_queue.put(task)
# 스레드 생성 및 시작
num_threads = 4
threads = []
for i in range(num_threads):
t = threading.Thread(target=worker, args=(work_queue,))
t.start()
threads.append(t)
# 모든 스레드의 작업이 완료될 때까지 대기
for t in threads:
t.join()
print("All tasks are completed.")