다음은 아래 "Berkeley CS294 강의"에 대한 요약 및 필기 내용을 정리한 것입니다. 틀린 내용이 있다면 댓글 부탁드립니다 🙌
- Course : CS294-158 SP24 Deep Unsupervised Learning
- Instructor: Pieter Abbeel
- Lecture # : L1. Introduction
본 강의는 Introduction 강의라 개요를 다룹니다. 해당 포스트는 제가 별도로 자료 조사 및 정리를 수행해서 추가적으로 작성한 것이므로, 본 강의 내용과 상이합니다.
딥러닝 학습 방법론의 계층적 분류
딥러닝 방법론은 크게 지도(Supervised), 준지도(Semi-Supervised), 비지도(UnSupervised), 강화학습(Reinforced) learning으로 구분할 수 있습니다.
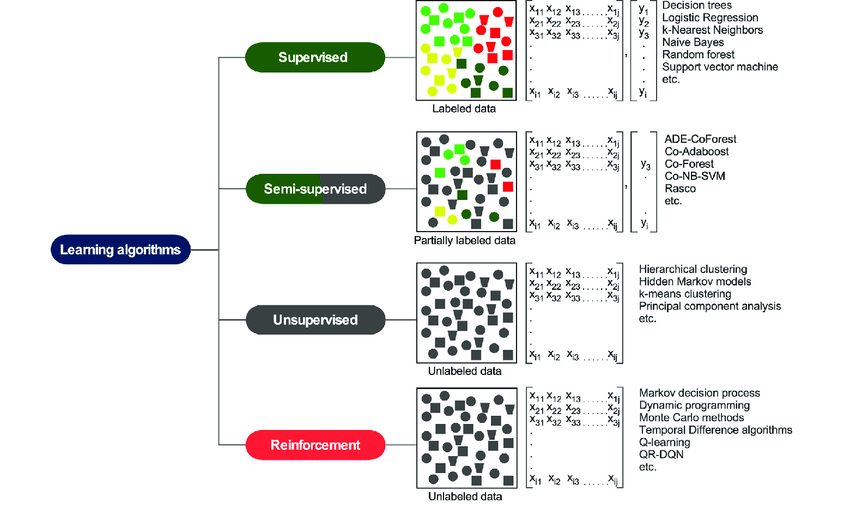
출처: Machine learning in the prediction of cancer therapy (논문)
하지만, 현실은 이렇게 위와 같이 아릅답게 4가지의 범주로 들어가지 않고, 새로운 학습 방법론들이 많이 나오기 시작하며 한번 정리를 해볼 필요성을 느꼈습니다.
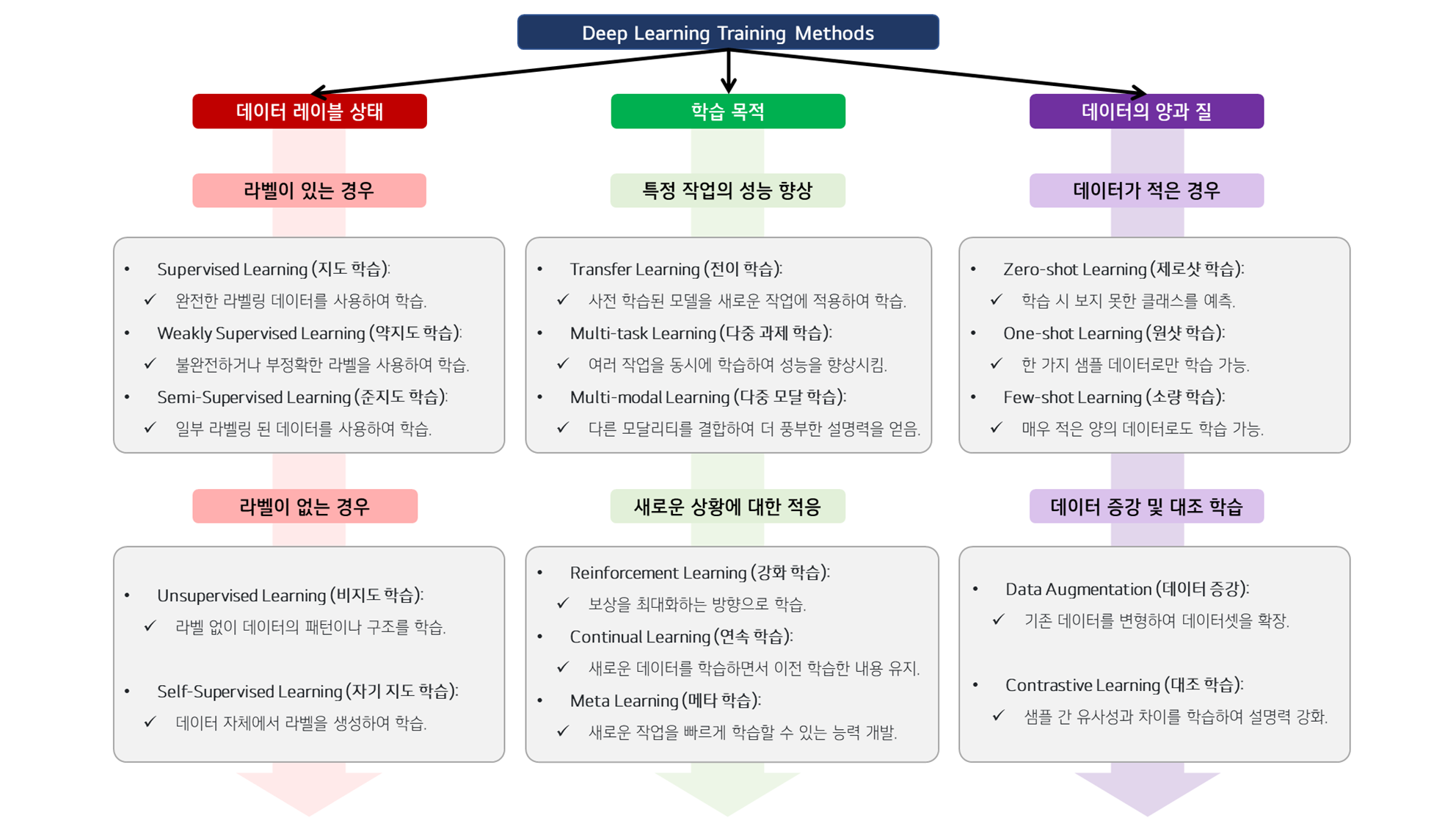
딥러닝 학습 방법론은 데이터 라벨링 상태, 학습 목적, 데이터의 양과 질, 그리고 데이터 모달리티와 같은 다양한 기준에 따라 계층적으로 분류할 수 있습니다.
이러한 기준을 바탕으로 재구성된 학습 방법론의 계층적 분류를 해볼 수 있습니다.
1. 데이터 라벨링 상태에 따른 분류
-
1.1 라벨이 있는 경우
- Supervised Learning (지도 학습): 완전한 라벨링 데이터를 사용하여 학습.
- Weakly Supervised Learning (약지도 학습): 불완전하거나 부정확한 라벨을 사용하여 학습.
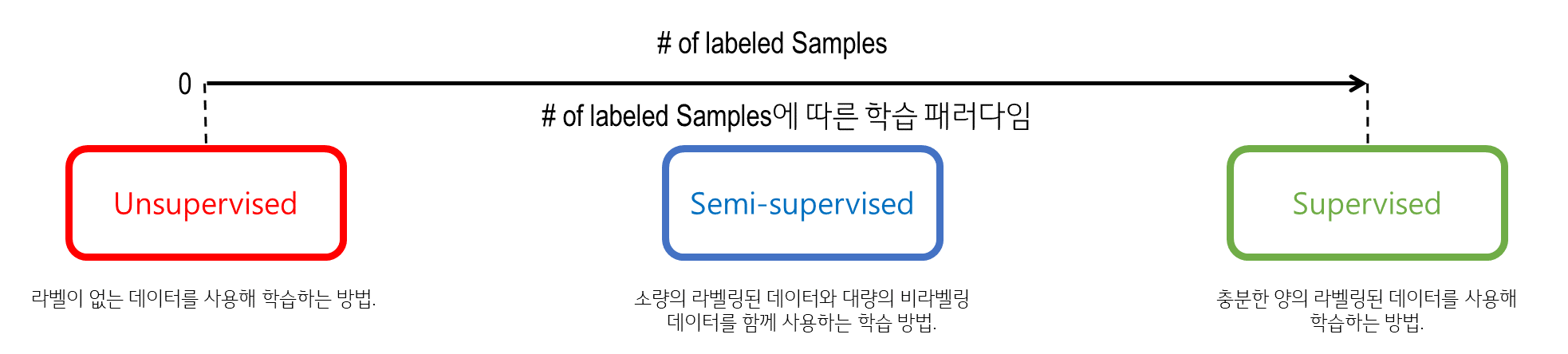
- Semi-Supervised Learning (준지도 학습): 일부 라벨링된 데이터와 비라벨링된 데이터를 함께 사용하여 학습.
-
1.2 라벨이 없는 경우
- Unsupervised Learning (비지도 학습): 라벨 없이 데이터의 패턴이나 구조를 학습.
- Self-Supervised Learning (자기 지도 학습): 데이터 자체에서 라벨을 생성하여 학습.
2. 학습 목적에 따른 분류
- 2.1 특정 작업의 성능 향상
- Transfer Learning (전이 학습): 다른 작업에서 학습한 모델을 새로운 작업에 적용하여 학습.
- Multi-task Learning (다중 과제 학습): 여러 작업을 동시에 학습하여 성능을 향상시킴.
- Multi-modal Learning (다중 모달 학습): 서로 다른 데이터 모달리티를 결합하여 더 풍부한 표현과 성능을 얻음.
- 2.2 새로운 상황에 대한 적응
- Reinforcement Learning (강화 학습): 보상을 최대화하는 방향으로 학습.
- Continual Learning (연속 학습): 새로운 데이터를 학습하면서 이전에 학습한 내용을 유지.
- Meta Learning (메타 학습): 다양한 작업을 학습하면서 새로운 작업을 빠르게 학습할 수 있는 능력 개발.
3. 데이터의 양과 질에 따른 분류
-
3.1 데이터가 적은 경우
- Zero-shot Learning (제로샷 학습): 학습 시 보지 못한 클래스를 예측.
- One-shot Learning (원샷 학습): 한 가지 샘플 데이터로만 학습 가능.
- Few-shot Learning (소량 학습): 매우 적은 양의 데이터로도 학습 가능.
-
3.2 데이터 증강 및 대조 학습
- Data Augmentation (데이터 증강): 기존 데이터를 변형하여 데이터셋을 확장.
- Contrastive Learning (대조 학습): 데이터 간의 유사성과 차이를 학습하여 설명력 강화.
1. 데이터 라벨링 상태에 따른 분류
1.1 라벨이 있는 경우
1.1.1 Supervised Learning (지도 학습)
-
정의: Supervised Learning은 주어진 입력 데이터에 대한 정답(라벨)이 있는 상태에서 모델을 학습하는 방법입니다. 입력과 출력 쌍을 통해 학습하며, 모델은 새로운 입력에 대해 올바른 출력을 예측하는 것을 목표로 합니다.
- 사용 목적: 분류(Classification), 회귀(Regression) 문제 해결. 예: 이메일 스팸 필터링, 이미지 인식, 질병 예측.
- 적용 방법: 대량의 라벨링된 데이터셋을 사용해 모델을 훈련합니다. 각 입력 데이터에 대해 정답 라벨을 제공하고, 모델은 이를 기반으로 학습합니다.
- 학습 방법: 손실 함수(loss function)를 최소화하는 방향으로 경사하강법(Gradient Descent)과 같은 최적화 알고리즘을 사용해 가중치를 업데이트합니다.
- 연구 예시: ResNet은 ImageNet 데이터셋을 사용해 학습된 지도 학습 모델로, 깊은 네트워크 학습을 위해 잔차 연결(residual connections)을 도입해 이미지 분류 문제에서 높은 성능을 보여주었습니다.
(추가용어) Active Learning (능동 학습)
- 정의: 모델이 가장 유용할 것으로 판단되는 데이터를 선택하여 라벨링을 요청하고 학습하는 방법
- 방법:
- 초기 모델 학습
- 비라벨링 데이터에 대한 불확실성 측정
- 가장 불확실한 데이터 선택 및 라벨링 요청
- 새로 라벨링된 데이터로 모델 재학습
- 2-4 과정 반복
1.1.2 Weakly Supervised Learning (약지도 학습)
-
정의: Weakly Supervised Learning은 불완전하거나 부정확한 라벨을 사용하는 학습 방법입니다. 정확한 라벨을 얻기 어려운 상황에서 사용됩니다.
- 사용 목적: 라벨링 비용을 줄이거나, 정확한 라벨을 얻기 힘든 경우. 예: 이미지에서 대략적인 레이블만 제공 가능한 경우.
- 적용 방법: 휴리스틱, 도메인 지식, 노이즈 모델링 등을 사용해 불완전한 라벨을 보완합니다.
- 학습 방법: 다중 인스턴스 학습(Multi-instance Learning), 노이즈 모델링 기법이 주로 사용됩니다.
- 연구 예시: Deep Multiple Instance Learning(DMIL)은 병리학적 이미지 분석에서 불완전한 라벨을 처리하는 데 효과적입니다.
(추가용어) Weak Supervision (약지도 학습)
- 정의: 저품질 또는 불완전한 라벨을 사용해 학습하는 방법
- 방법:
- 휴리스틱 규칙 사용하여 라벨 생성
- 크라우드소싱을 통한 대량의 저품질 라벨 수집
- 다양한 소스의 약한 라벨을 결합하여 더 강한 라벨 생성
(추가용어) Distant Supervision (원격 지도 학습)
- 정의: 외부 지식베이스나 데이터베이스를 활용하여 자동으로 라벨을 생성하는 방법
- 방법:
- 외부 지식베이스와 비라벨링 데이터 매칭
- 매칭된 정보를 바탕으로 라벨 자동 생성
- 생성된 라벨로 모델 학습
1.1.3 Semi-Supervised Learning (준지도 학습)
-
정의: Semi-Supervised Learning은 소량의 라벨링된 데이터와 대량의 비라벨링된 데이터를 함께 사용하여 학습하는 방법입니다. 이 방법은 라벨링 비용을 줄이면서도 높은 성능을 유지할 수 있습니다.
- 사용 목적: 대량의 비라벨링된 데이터가 존재하지만, 라벨링된 데이터가 부족한 상황. 예: 텍스트 분류, 이미지 분류.
- 적용 방법: 모델은 라벨링된 데이터로 지도 학습을 하고, 비라벨링된 데이터에는 비지도 학습을 적용해 추가적인 정보를 추출합니다.
- 학습 방법: Consistency Regularization, Entropy Minimization 등 다양한 기법을 사용해 의미 있는 패턴을 학습합니다.
- 연구 예시: MixMatch는 라벨링된 데이터와 비라벨링된 데이터를 혼합하여 이미지 분류 작업에서 뛰어난 성능을 발휘합니다.
1.2 라벨이 없는 경우
1.2.1 Unsupervised Learning (비지도 학습)
-
정의: Unsupervised Learning은 라벨이 없는 데이터를 사용해 데이터의 숨겨진 패턴이나 구조를 학습하는 방법입니다. 데이터 자체의 구조를 이해하고 이를 바탕으로 분류하거나 변환합니다.
- 사용 목적: 군집화(Clustering), 차원 축소(Dimensionality Reduction), 밀도 추정(Density Estimation). 예: 고객 세분화, 이상 탐지.
- 적용 방법: 라벨이 없는 데이터를 입력받아 데이터 간의 유사성을 기반으로 패턴을 찾습니다.
- 학습 방법: K-means, PCA, Autoencoders 등의 알고리즘을 사용해 데이터의 내재된 구조를 학습합니다.
- 연구 예시: Word2Vec은 단어 벡터를 학습하기 위해 비지도 학습을 사용해 단어 간의 유사성을 벡터 공간에 매핑합니다.
(추가용어) Self Supervision (자기 지도 학습)
- 정의: 데이터 자체에서 학습 신호를 생성하여 학습하는 방법
- 방법:
- 데이터의 일부를 가리고 나머지로 가려진 부분을 예측하게 하기
- 이미지 회전 각도 예측하기
- 문장의 단어 순서 예측하기
1.2.2 Self-Supervised Learning (자기 지도 학습)
-
정의: Self-Supervised Learning은 데이터의 일부를 제거하거나 변형한 후 이를 복원하는 과제를 통해 학습하는 방법입니다. 라벨 없이도 학습할 수 있는 강력한 방법론입니다.
- 사용 목적: 대량의 비라벨링된 데이터를 활용해 유용한 표현(representation)을 학습. 예: 텍스트, 이미지, 비디오 데이터.
- 적용 방법: 텍스트 데이터에서 단어를 마스킹하거나, 이미지의 일부를 제거하고 이를 복원하도록 학습합니다.
- 학습 방법: BERT, SimCLR, MoCo와 같은 모델을 사용해 데이터를 스스로 라벨링하여 고품질의 표현을 학습합니다.
- 연구 예시: BERT는 텍스트 데이터에서 특정 단어를 마스킹하고 이를 예측하는 방식으로 학습됩니다.
(추가용어) Self Training (자기 훈련)
- 정의: 라벨이 있는 데이터로 학습한 모델을 사용하여 라벨이 없는 데이터에 대한 예측을 수행하고, 이를 새로운 학습 데이터로 사용하는 방법
- 방법:
- 라벨이 있는 데이터로 초기 모델 학습
- 라벨이 없는 데이터에 대해 예측 수행
- 높은 신뢰도의 예측 결과를 새로운 라벨로 사용
- 새로운 데이터셋으로 모델 재학습
- 2-4 과정 반복
2. 학습 목적에 따른 분류
2.1 특정 작업의 성능 향상
2.1.1 Transfer Learning (전이 학습)
-
정의: Transfer Learning은 한 작업에서 학습한 모델을 다른 유사한 작업에 적용하는 방법입니다. 사전 학습된 모델을 새로운 작업에 맞게 미세 조정(fine-tuning)하여 사용합니다.
- 사용 목적: 소규모 데이터셋에서 높은 성능을 얻기 위해 사용. 예: 컴퓨터 비전, 자연어 처리.
- 적용 방법: 대규모 데이터셋에서 학습된 모델을 활용해 특정 작업에 맞게 재학습합니다.
- 학습 방법: 사전 학습된 모델의 일부 계층을 고정하거나, 전체 네트워크를 미세 조정합니다.
- 연구 예시: ResNet은 ImageNet에서 사전 학습된 모델로, 이를 미세 조정하여 다양한 이미지 분류 작업에 적용할 수 있습니다.
2.1.2 Multi-task Learning (다중 과제 학습)
정의: Multi-task Learning은 여러 관련된 작업을 동시에 학습하는 방법입니다. 작업 간의 공통 정보를 공유함으로써 일반화 성능을 향상시킬 수 있습니다.
- 사용 목적: 여러 작업 간의 시너지를 통해 성능을 향상시키고, 모델의 효율성을 높이기 위해 사용. 예: 자율 주행, 컴퓨터 비전.
- 적용 방법: 하나의 모델이 여러 작업을 동시에 학습하도록 설계합니다.
- 학습 방법: 하드 파라미터 공유(Hard Parameter Sharing), 소프트 파라미터 공유(Soft Parameter Sharing) 기법을 사용해 작업 간의 균형을 유지합니다.
- 연구 예시: Uber의 Multi-task Neural Networks는 자율 주행 차량에서 여러 작업을 동시에 처리할 수 있도록 설계되었습니다.
2.1.3 Multi-modal Learning (다중 모달 학습)
-
정의: Multi-modal Learning은 텍스트, 이미지, 음성 등 여러 가지 서로 다른 데이터 모달리티를 결합하여 학습하는 방법입니다. 다양한 형태의 데이터를 통합하여 더 풍부한 표현과 성능을 얻는 것이 목표입니다.
- 사용 목적: 여러 모달리티 간의 관계를 이해하고, 이를 통해 복합적인 문제를 해결하기 위해 사용. 예: 텍스트-이미지 변환, 비디오 설명 생성.
- 적용 방법: 모델은 서로 다른 모달리티 간의 상호 작용을 학습하고, 이를 결합해 통합된 표현을 생성합니다.
- 학습 방법: Cross-modal Attention, Joint Embedding, Transformer 기반 모델 등이 사용됩니다.
- 연구 예시: CLIP(OpenAI)은 이미지와 텍스트를 동시에 학습해, 텍스트 설명과 일치하는 이미지를 찾거나, 이미지를 설명할 수 있는 강력한 모델을 개발했습니다.
2.2 새로운 상황에 대한 적응
2.2.1 Reinforcement Learning (강화 학습)
-
정의: Reinforcement Learning은 에이전트가 환경과 상호작용하며, 보상을 최대화하는 방향으로 정책을 학습하는 방법입니다. 에이전트는 행동을 선택하고, 그 행동의 결과로부터 보상을 얻습니다.
- 사용 목적: 복잡한 의사 결정 문제, 게임, 로봇 제어, 자율 주행 등. 예: 체스, 바둑, 자율 주행 차량.
- 적용 방법: 에이전트는 환경에서 시도와 오류(trial and error)를 통해 학습하며, 장기적인 보상을 최대화하는 방향으로 정책을 개선합니다.
- 학습 방법: Q-learning, SARSA, DQN, Policy Gradients 등이 사용됩니다.
- 연구 예시: DeepMind의 AlphaGo는 수백만 번의 게임을 통해 바둑에서 사람을 능가하는 성능을 보여주었습니다.
2.2.2 Continual Learning (연속 학습)
-
정의: Continual Learning은 모델이 새로운 데이터나 작업을 학습하면서 이전에 학습한 내용을 잃지 않도록 하는 방법입니다. 연속적으로 변화하는 환경에 적응하며 성능을 유지합니다.
- 사용 목적: 변화하는 데이터 분포, 새로운 작업에 유연하게 대응하기 위해 사용. 예: 로봇 제어, 자율 주행, IoT 시스템.
- 적용 방법: 모델은 새로운 데이터를 학습할 때마다 이전에 학습한 내용을 보존하며, 점진적으로 학습합니다.
- 학습 방법: EWC, GEM, Replay-based Methods 등이 사용됩니다.
- 연구 예시: DeepMind의 Progress & Compress는 여러 작업을 순차적으로 학습하며, 이전 작업의 성능을 유지합니다.
2.2.3 Incremental Learning (점진적 학습)
-
정의: Incremental Learning은 새로운 데이터나 클래스가 추가될 때 모델을 점진적으로 업데이트하는 방법입니다. 주로 동일한 작업 내에서 새로운 데이터나 클래스를 추가하는 데 중점을 둡니다.
- 사용 목적: 모델의 전체 재학습 없이 새로운 정보를 통합하기 위해 사용. 예: 새로운 클래스의 추가, 데이터 확장.
- 적용 방법: 모델의 기존 구조를 유지하면서 점진적으로 새로운 데이터를 통합합니다.
- 학습 방법: 새로운 데이터가 추가될 때마다 기존 모델을 부분적으로 업데이트합니다.
- 연구 예시: 이미지 분류 작업에서 새로운 클래스가 지속적으로 추가되는 환경에서 활용됩니다.
2.2.4 Online Learning (온라인 학습)
-
정의: Online Learning은 데이터가 순차적으로 도착할 때 실시간으로 모델을 업데이트하는 방법입니다. 각 데이터 포인트에 대해 즉시 학습 및 예측을 수행합니다.
- 사용 목적: 실시간 데이터 처리 및 즉각적인 모델 업데이트가 필요한 경우 사용. 예: 스트리밍 데이터 분석, 금융 거래.
- 적용 방법: 데이터가 스트림 형태로 지속적으로 유입될 때 모델을 실시간으로 학습 및 업데이트합니다.
- 학습 방법: 각 데이터 포인트가 도착할 때마다 모델을 즉시 학습하고 예측을 업데이트합니다.
- 연구 예시: 실시간 주가 예측에서 매순간 도착하는 새로운 데이터를 반영해 모델을 업데이트합니다.
2.2.5 Meta Learning (메타 학습)
-
정의: Meta Learning은 "학습을 학습하는" 방법론으로, 새로운 작업을 빠르게 학습할 수 있는 모델을 만드는 데 중점을 둡니다. 다양한 작업을 학습하며 일반화된 학습 전략을 터득하는 것이 목표입니다.
- 사용 목적: 새로운 작업에 대한 학습 속도를 높이고, 소량의 데이터로도 효과적으로 학습할 수 있도록 하기 위해 사용. 예: Few-shot Learning.
- 적용 방법: 모델은 다수의 작업을 학습하면서, 새로운 작업에 빠르게 적응할 수 있는 능력을 개발합니다.
- 학습 방법: MAML, Reptile, Prototypical Networks 등의 알고리즘이 사용됩니다.
- 연구 예시: MAML 알고리즘은 새로운 작업에 대한 적응성을 높이는 메타 학습 방법을 제공합니다.
3. 데이터의 양과 질에 따른 분류
3.1 데이터가 적은 경우
3.1.1 Zero-shot Learning (제로샷 학습)
-
정의: Zero-shot Learning은 학습에 사용되지 않은 새로운 클래스에 대해 예측을 수행하는 방법입니다. 모델이 기존의 지식과 특성을 일반화하여, 이전에 본 적 없는 클래스를 인식하는 것이 목표입니다.
- 사용 목적: 새로운 클래스의 라벨링 데이터가 전혀 없을 때 사용. 예: 새로운 제품 카테고리의 자동 분류.
- 적용 방법: 학습 중에 보지 못한 클래스의 설명(예: 텍스트 설명, 속성 벡터)과 기존 클래스의 특성을 기반으로 예측합니다.
- 학습 방법: Attribute-based 모델, Semantic Embedding 모델, Knowledge Transfer 모델 등이 사용됩니다.
- 연구 예시: Xian et al.은 Zero-shot Learning의 벤치마크 데이터셋을 제안하고, 새로운 클래스 인식 성능을 평가했습니다.
3.1.2 One-shot Learning (원샷 학습)
-
정의: One-shot Learning은 새로운 클래스를 학습하기 위해 단 하나의 예제만을 사용하는 학습 방법입니다. Few-shot Learning의 특수한 형태로 볼 수 있습니다.
- 사용 목적: 단일 예제만으로도 새로운 클래스를 학습하고 예측하기 위해 사용. 예: 얼굴 인식, 생물종 인식.
- 적용 방법: 이전에 학습한 유사한 작업의 정보를 활용하여, 새로운 클래스를 단일 예제만으로 학습합니다.
- 학습 방법: Siamese Networks, Matching Networks 등이 사용되며, 두 입력 간의 유사성을 학습합니다.
- 연구 예시: Vinyals et al. (2016)의 Matching Networks는 One-shot Learning을 통해 단일 예제만으로 새로운 클래스를 학습하는 데 성공했습니다.
3.1.3 Few-shot Learning (소량 학습)
-
정의: Few-shot Learning은 매우 적은 수의 학습 데이터로도 높은 성능을 발휘할 수 있는 모델을 학습하는 방법입니다. 일반적으로 소량의 예제(예: 1-shot, 5-shot)로 새로운 클래스를 학습할 수 있는 모델을 목표로 합니다.
- 사용 목적: 라벨링된 데이터가 극히 적은 상황에서 사용. 예: 드물게 발생하는 질병의 진단, 드문 물체의 인식.
- 적용 방법: 이전에 학습한 유사한 작업에서 얻은 경험을 활용해 소량의 데이터를 빠르게 학습합니다.
- 학습 방법: Prototypical Networks, Matching Networks, Relation Networks 등이 사용됩니다.
- 연구 예시: Matching Networks는 소량의 학습 데이터로도 새로운 클래스에 빠르게 적응할 수 있는 Few-shot Learning 모델입니다.
3.3 데이터 증강 및 대조 학습
3.3.1 데이터 증강 (Data Augmentation)
-
정의: 데이터 증강은 학습에 사용되는 원본 데이터를 다양한 방식으로 변형하여 데이터셋을 확장하는 방법입니다. 이는 모델이 다양한 입력 형태에 대해 강인해질 수 있도록 도와줍니다.
- 사용 목적: 데이터가 부족하거나 불균형한 상황에서 데이터의 다양성을 높이고, 과적합을 방지하며 모델의 일반화 성능을 향상시키기 위해 사용됩니다.
- 적용 방법: 이미지 회전, 크롭, 색상 변화, 스케일 조절 등과 같은 변형 기법을 적용하여 새로운 학습 데이터를 생성합니다.
- 학습 방법:
- 이미지 증강 기법: 회전, 자르기, 확대/축소, 색상 변환, 뒤집기 등.
- 음성 증강 기법: 소음 추가, 시간 왜곡, 속도 변화 등.
- 텍스트 증강 기법: 단어 삽입, 삭제, 교체, 순서 변경 등.
- 고급 증강 기법: CutMix, MixUp, CutOut 등을 사용해 데이터를 혼합하거나 일부를 제거하는 방식.
- 연구 예시:
- CutMix: 두 이미지를 혼합하여 새로운 학습 데이터를 생성, 다양한 이미지 분류 작업에서 성능을 개선.
- MixUp: 두 이미지를 선형 결합하여 새로운 학습 샘플을 만들어, 모델의 일반화 능력을 향상시킴.
- GANs 기반 증강: StyleGAN 등은 새로운 이미지를 생성해 데이터셋을 확장하고 성능을 높임.
3.3.2 대조 학습 (Contrastive Learning)
-
정의: 대조 학습은 학습 과정에서 데이터의 유사성과 차이를 학습하여 모델의 성능을 향상시키는 방법입니다. 이 기법은 데이터의 잠재적 표현을 개선하고, 특정 목적에 맞는 고품질의 임베딩을 생성하는 데 초점을 맞춥니다.
- 사용 목적: 데이터 간의 유사성을 강조하고 차이를 학습함으로써 고차원 데이터의 잠재 표현을 최적화하기 위해 사용됩니다. 특히, 데이터가 복잡하거나 다양한 경우에 유용합니다.
- 적용 방법: 데이터 포인트 간의 유사성을 극대화하고, 다른 데이터 포인트와의 차이를 극대화하는 방식으로 학습합니다. 주로 대조적 손실 함수(Contrastive Loss) 또는 삼중 항 손실(Triplet Loss)를 사용합니다.
- 학습 방법:
- Contrastive Loss: 유사한 데이터 쌍은 가깝게, 다른 데이터 쌍은 멀리 떨어지도록 학습.
- Triplet Loss: 앵커(anchor) 샘플, 양성(positive) 샘플, 음성(negative) 샘플 간의 거리 관계를 최적화하여 학습.
- Self-Supervised Learning 기법: SimCLR, MoCo 등은 대조 학습을 통해 강력한 데이터 표현을 학습함.
- 연구 예시:
- SimCLR: Self-Supervised Learning에서 대조적 손실을 사용해 이미지 표현을 학습하며, 지도 학습 없이도 강력한 성능을 발휘.
- Triplet Loss: 얼굴 인식 모델에서 유사한 얼굴은 가깝게, 다른 얼굴은 멀리 배치되도록 학습해 높은 인식 정확도를 달성.
4. Unsupervised Learning의 중요성
Unsupervised Learning은 라벨이 없는 데이터에서 패턴과 구조를 학습하는 방법으로, 데이터의 숨겨진 구조를 발견하거나 데이터의 압축을 통해 더 효율적인 모델을 만드는 데 사용됩니다.
1. Geoffrey Hinton의 관점
Geoffrey Hinton은 그의 2014년 AMA(Ask Me Anything) 세션에서, 인간의 뇌가 약 개의 시냅스를 가지고 있고 우리가 약 초를 살기 때문에 데이터보다 훨씬 많은 파라미터를 가지고 있다고 언급했습니다. 이는 우리가 더 많은 양의 Unsupervised Learning을 해야 함을 의미합니다. 그는 인간의 지각 입력(Perceptual Input)에서 얻을 수 있는 제약 조건의 수가 많기 때문에, Unsupervised Learning이 필요하다고 설명했습니다. 이러한 설명은 데이터의 패턴을 학습하고 압축(Compression)하는 것이 인간의 지능과 어떻게 연결되는지를 시사합니다.

2. Yann LeCun의 "LeCake" 비유
Yann LeCun은 2016년 NeurIPS 키노트 강연에서 "LeCake" 비유를 통해 Unsupervised Learning의 중요성을 강조했습니다. 그는 강화 학습이 케이크의 체리에 해당하고, 지도 학습이 아이싱에 해당하는 반면, Unsupervised Learning은 케이크의 대부분을 차지한다고 설명했습니다. 이는 Unsupervised Learning이 매우 큰 데이터 볼륨을 처리하고 일반화된 학습을 가능하게 하는 핵심 기술임을 나타냅니다. LeCun은 기계가 상식을 가지고 일반화하려면 엄청난 양의 정보가 필요하며, 이를 달성하는 방법이 바로 Unsupervised Learning이라고 강조했습니다.

3. Ideal Intelligence와 Compression
Unsupervised Learning의 또 다른 중요한 측면은 "Ideal Intelligence"로 정의되는 개념입니다. 이 개념에 따르면, 지능은 데이터를 압축하고 패턴을 찾는 능력으로 측정될 수 있습니다. Kolmogorov Complexity 이론에 따르면, 패턴을 모두 찾아내는 것은 데이터의 짧은 설명을 의미하며, 이는 최적의 추론(Optimal Inference)과 연결됩니다. 이러한 압축을 통해 얻어진 정보는 최적의 행동을 결정하는 인공지능(AI) 시스템에도 적용될 수 있습니다. 예를 들어, Unsupervised Learning을 통해 D1 데이터 분포에서 사전 학습한 후, D2 데이터 분포에서 미세 조정을 진행하면 더 빠르게 학습할 수 있습니다.

4. 응용 분야
Unsupervised Learning은 이미지 생성, 텍스트-이미지 변환, 오디오 생성, 텍스트 생성, 비디오 생성 등 다양한 분야에서 강력한 응용력을 발휘하고 있습니다. 실제로, Google 검색 엔진은 BERT와 같은 Unsupervised Learning 모델을 활용하여 검색 결과를 개선하였으며, 이는 Unsupervised Learning이 실제 산업에서 어떻게 생산 수준의 임팩트를 줄 수 있는지를 보여줍니다. BERT는 방대한 양의 텍스트 데이터를 비지도 학습을 통해 단어 간의 관계를 이해하고, 이를 기반으로 자연어 처리 작업에서 탁월한 성능을 발휘합니다.

Unsupervised Learning은 데이터의 라벨링 없이도 풍부한 패턴을 학습할 수 있는 능력 덕분에 점점 더 많은 산업과 연구 분야에서 중요성이 강조되고 있습니다. 이를 통해 Unsupervised Learning은 기존의 지도 학습과 비교해 라벨링에 의존하지 않으면서도 풍부한 정보를 추출할 수 있어, 미래의 데이터 분석 및 인공지능 기술의 핵심이 될 것으로 기대됩니다.
Conclusion
본 강의에서 언급하듯이, Unsupervised Learning의 중요성은 데이터의 라벨링 없이도 숨겨진 패턴과 구조를 학습할 수 있다는 점에 있습니다. 이는 대규모 데이터에서 유의미한 정보를 추출할 수 있는 강력한 도구로서, 라벨링 비용과 시간을 절감하며, 새로운 도메인이나 작업에 신속하게 적응할 수 있는 유연성을 제공합니다.
이러한 이유로 Unsupervised Learning은 다양한 산업 및 연구 분야에서 점점 더 중요한 역할을 맡고 있으며, 미래의 인공지능 기술 발전에 필수적인 요소로 자리매김하고 있습니다.
앞으로의 강의 학습 및 정리를 통해 Unsupervised Learning의 핵심 개념과 다양한 응용 사례를 체계적으로 학습함으로써, 이 방법론이 제공하는 강력한 잠재력을 깊이 이해하고, 이를 실무에 효과적으로 적용할 수 있는 능력을 키워나가고자 합니다.
