Prophet 소개
Facebook Prophet은 시계열 데이터의 예측을 위해 Facebook에서 개발한 오픈소스 라이브러리입니다. Prophet은 자동화된 이상 탐지 및 계절성 분석을 지원하며, 특히 비즈니스 예측(예: 매출, 사용자 수, 웹 트래픽 등)에 유용합니다.

Prophet의 장점
Meta(Facebook)에서는 Prophet의 장점을 다음과 같이 소개합니다:

1. 정확하고 빠르다 (Accurate and Fast)
- 정확성: Prophet은 Facebook 내부의 다양한 응용 프로그램에서 신뢰할 수 있는 예측을 제공하는 데 사용됩니다. 이를 통해 계획 수립 및 목표 설정에 큰 도움을 줍니다.
- 속도: 대부분의 경우, 다른 접근 방식보다 더 나은 성능을 보여줍니다. Stan을 사용하여 모델을 피팅하므로, 몇 초 만에 예측 결과를 얻을 수 있습니다.
2. 완전 자동화 (Fully Automatic)
- 자동 예측: 데이터가 어지럽고 복잡해도 별다른 수작업 없이 합리적인 예측 결과를 얻을 수 있습니다.
- 강건성: 이상치, 결측치, 시간 시계열의 극적인 변화에 대해 강건한 성능을 보입니다.
3. 조정 가능한 예측 (Tunable Forecasts)
- 사용자 조정 가능성: 사용자가 예측을 미세 조정하고 조정할 수 있는 다양한 가능성을 제공합니다.
- 해석 가능한 매개변수: 인간이 해석 가능한 매개변수를 사용하여 도메인 지식을 추가함으로써 예측을 개선할 수 있습니다.
4. R 또는 Python에서 사용 가능 (Available in R or Python)
- 언어 지원: Prophet은 R과 Python에서 모두 사용할 수 있으며, 동일한 Stan 코드를 기반으로 동작합니다.
- 유연성: 사용자가 편안하게 사용할 수 있는 언어를 선택하여 예측을 수행할 수 있습니다.
주요 기능
-
추세 변동: 선형 및 비선형 추세 모델링 지원.
Prophet은 데이터의장기적인 추세를 모델링할 수 있습니다.Prophet은 자동으로 최적의 추세 모델을 선택하거나, 사용자가 수동으로 설정할 수 있습니다. Prophet에서는 두 가지 주요 추세 모델을 지원합니다:-
선형 추세 (Linear Trend): 데이터가 일정한 속도로 증가하거나 감소할 때 사용됩니다.
-
비선형 추세 (Non-linear Trend): 데이터의 변화 속도가 시간에 따라 변할 때 사용됩니다. 예를 들어, 로그 변환 추세 등이 있습니다.
# 기본 설정에서는 선형 추세 모델을 사용 model = Prophet() # 이는 model = Prophet(growth='linear')와 동일 # 선택해서 사용가능 model = Prophet(growth='linear') # 선형 추세 모델 model = Prophet(growth='logistic') # 비선형 추세 모델
-
-
계절성: 주기적 변동(일, 주, 년 단위)을 모델링.
Prophet은데이터의 주기적인 변동을 모델링할 수 있습니다. 이는 주간, 월간, 연간 등의 주기로 발생하는 변동을 의미합니다. Prophet은 기본적으로 연간 계절성(yearly_seasonality)과 주간 계절성(weekly_seasonality)을 포함하며, 이는 필요에 따라 켜고 끌 수 있습니다. 추가로, 사용자 정의 계절성을 도메인 지식을 기반으로 추가할 수 있습니다.기본 계절성
-
연간 계절성 (yearly_seasonality): 데이터의 연간 주기를 반영합니다.
-
주간 계절성 (weekly_seasonality): 데이터의 주간 주기를 반영합니다.
# 기본 연간 계절성을 활성화 model = Prophet(yearly_seasonality=True) # 기본 주간 계절성을 활성화 model = Prophet(weekly_seasonality=True) # 연간 계절성을 비활성화 model = Prophet(yearly_seasonality=False) # 주간 계절성을 비활성화 model = Prophet(weekly_seasonality=False) # 사용자 정의 계절성 추가 model.add_seasonality(name='monthly', period=30.5, fourier_order=5)
-
휴일 효과: 공휴일 및 특별 이벤트에 대한 효과를 반영.
Prophet은공휴일 및 특별 이벤트가 시계열 데이터에 미치는 영향을 반영할 수 있습니다. 이를 위해 공휴일 리스트를 제공하여 모델에 추가할 수 있습니다.from prophet.make_holidays import make_holidays_df # 공휴일 리스트 생성 holidays = make_holidays_df(year_list=[2015, 2016, 2017, 2018, 2019], country='US') # 모델 초기화 시 공휴일 추가 model = Prophet(holidays=holidays) -
결측치 처리: 자동으로 결측치를 처리하고 불규칙한 시계열 데이터를 다룰 수 있음.
Prophet은
결측치를 자동으로 처리할 수 있으며, 불규칙한 시계열 데이터에서도 잘 작동합니다. 결측치를 별도로 처리할 필요 없이 Prophet 모델에 데이터를 그대로 입력하면 됩니다.
-
이상치 처리: 이상치에 강건한 모델링.
Prophet은이상치에 강건한 모델링을 제공합니다. 이상치가 있는 데이터에서도 모델은 강건하게 작동합니다. 추가적으로 제거가 필요하면, 사용자는 이상치를 수동으로 제거할 수 있습니다.# 이상치가 포함된 데이터 train_data.loc[train_data['ds'] == '2017-07-01', 'y'] = None # 특정 날짜의 이상치를 결측치로 설정
코드 실습
실습 데이터
Kaggle: Panama Electricity Load Forecasting
해당 데이터셋은 파나마의 전력 부하(MW)를 예측하기 위한 시계열 데이터입니다. 날씨 변수와 특별한 날(공휴일, 학교 휴일 등)을 참조하여 예측하는 것이 목적입니다. Kaggle에서 제공되고 있으며, 이번 포스팅에서는 이를 활용한 시계열 예측을 수행해보도록 하겠습니다.
데이터셋 개요
- 목적: 파나마의 전력 부하(MW)를 예측
- 참조 변수: 날씨 변수 및 특별한 날
- 특징: 총 15개의 특징(features)을 포함
데이터셋 구성
1. 특징(features):
- 총 15개의 특징을 포함
- 12개의 연속적인 수치형 변수: 날씨 변수
- 3개의 특별한 날 관련 변수: 공휴일, 공휴일 ID, 학교 휴일
-
결측치 없음: 데이터셋에 결측치가 없음
-
예측 대상: 'nat_demand' 열에 있는 파나마의 전력 부하
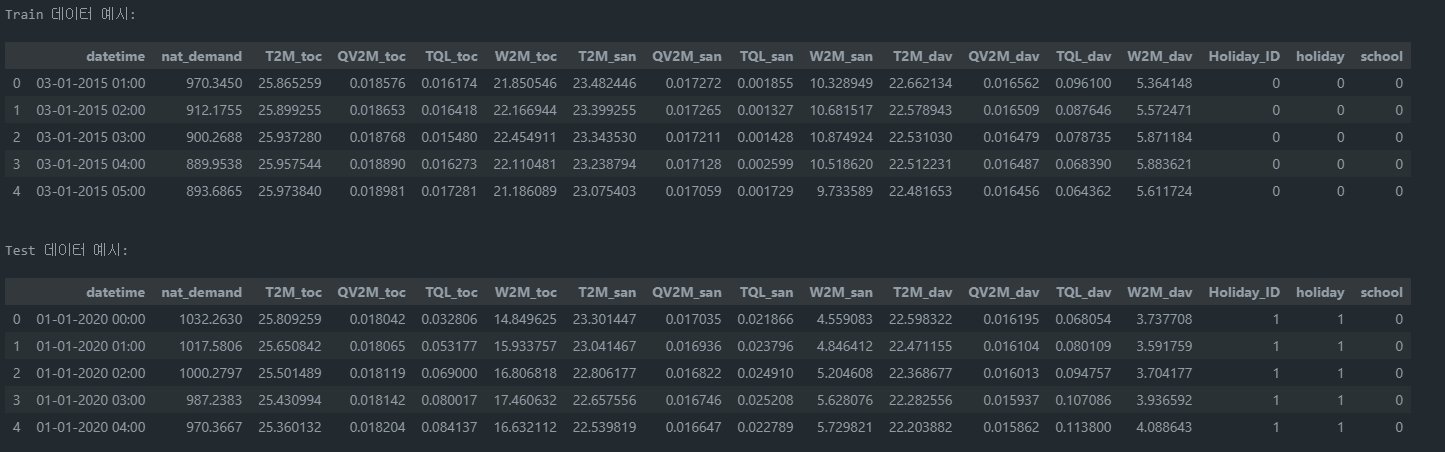
Column 설명
- ds: 날짜 및 시간 (datetime)
- T2M_toc, QV2M_toc, TQL_toc, W2M_toc: 특정 지역(toc)의 날씨 변수 (온도, 습도, 강수량, 풍속 등)
- T2M_san, QV2M_san, TQL_san, W2M_san: 다른 지역(san)의 날씨 변수
- T2M_dav, QV2M_dav, TQL_dav, W2M_dav: 또 다른 지역(dav)의 날씨 변수
- Holiday_ID: 공휴일 ID
- holiday: 공휴일 여부 (True/False)
- school: 학교 휴일 여부 (True/False)
nat_demand: 파나마의 전력 부하 (MW)
이 데이터셋은 나머지 변수들을 활용하여 파나마의 전력 부하(net_demand)를 예측하는 데 사용될 수 있습니다. 다양한 날씨 변수와 특별한 날을 고려하여 전력 부하를 예측함으로써, 전력 회사는 효율적으로 전력 공급을 관리하고 최적화할 수 있습니다. 각각 train과 test y 데이터의 양상을 살펴보시죠.
Train y
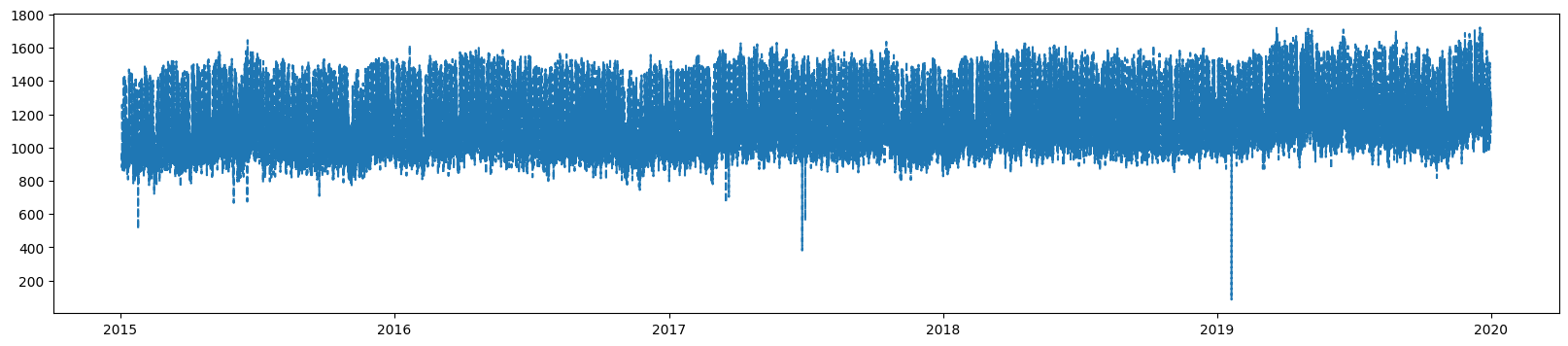
Test y
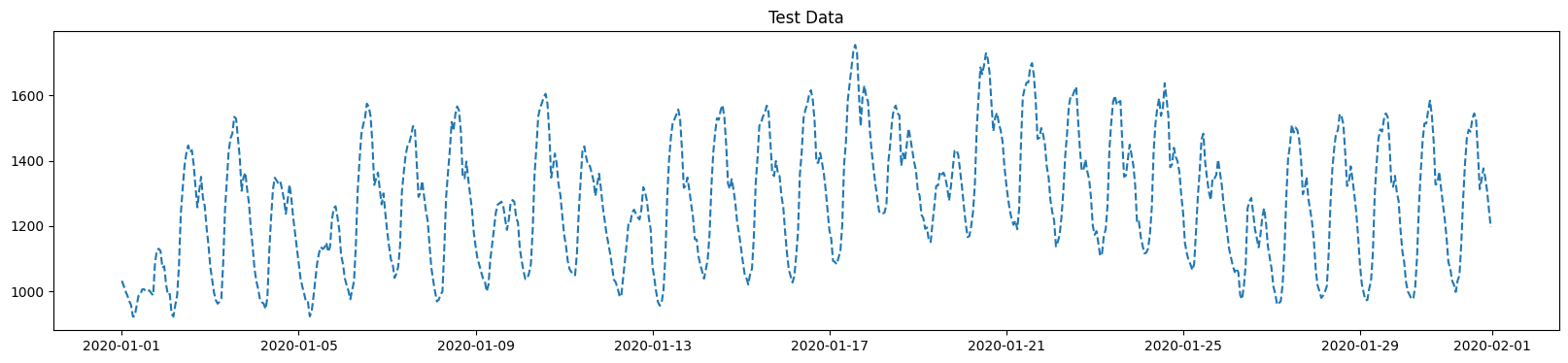
데이터 준비
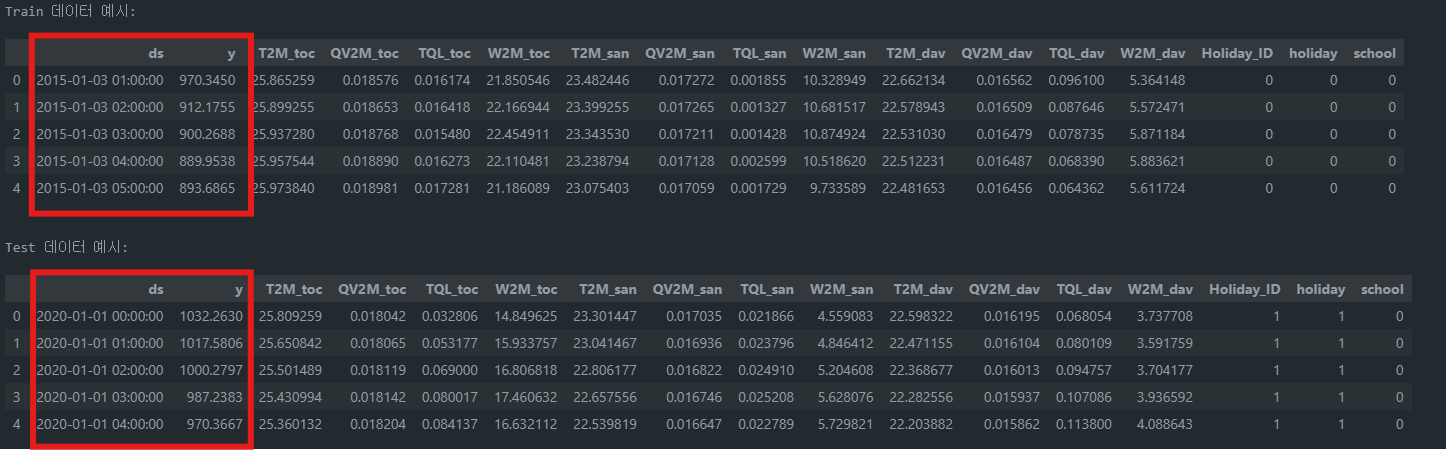
Prophet에서 요구하는 데이터 형식은 ds (datetime)와 y (value) 컬럼을 포함해야 합니다.
import pandas as pd
# 데이터 로드
train_data = pd.read_csv('./data/panama/train.csv')
test_data = pd.read_csv('./data/panama/test.csv')
# 컬럼 이름 변경
train_data.rename(columns={'datetime': 'ds', 'nat_demand': 'y'}, inplace=True)
test_data.rename(columns={'datetime': 'ds', 'nat_demand': 'y'}, inplace=True)
# 날짜 형식 변환
train_data['ds'] = pd.to_datetime(train_data['ds'], format='%d-%m-%Y %H:%M')
test_data['ds'] = pd.to_datetime(test_data['ds'], format='%d-%m-%Y %H:%M')설명:
pd.read_csv: CSV 파일을 DataFrame으로 로드하는 함수입니다.rename(columns=...): 컬럼 이름을 변경하여 Prophet이 요구하는 형식에 맞춥니다.pd.to_datetime: 문자열을 datetime 객체로 변환합니다.
모델 학습 및 예측
모델 초기화 및 학습
from prophet import Prophet
# 모델 초기화
model = Prophet()
# 추가 변수 (exogenous variables) 등록
regressors = ['T2M_toc', 'QV2M_toc', 'TQL_toc', 'W2M_toc',
'T2M_san', 'QV2M_san', 'TQL_san', 'W2M_san',
'T2M_dav', 'QV2M_dav', 'TQL_dav', 'W2M_dav',
'Holiday_ID', 'holiday', 'school']
for regressor in regressors:
model.add_regressor(regressor)
# 모델 학습
model.fit(train_data)설명:
Prophet(): Prophet 모델을 초기화합니다.add_regressor: 모델에 외부 변수를 추가합니다.fit: 주어진 데이터로 모델을 학습시킵니다.
주의 사항:
- 외부 변수를 추가할 때, 훈련 데이터와 예측 데이터에 동일한 변수가 있어야 합니다.
- 외부 변수는 수치형 변수여야 합니다. 범주형 변수일 경우, one-hot-encoding과 같이 수치형으로 변환을 수행해주어야 합니다.
- 데이터의 시간 형식과 간격을 확인하여 일관되게 유지해야 합니다.
예측 수행
# 예측을 위한 미래 데이터프레임 생성 (테스트 데이터와 동일한 기간)
future = test_data[['ds'] + regressors]
# 예측 수행
forecast = model.predict(future)
# 예측 결과 확인
print(len(forecast), len(test_data)) # 744 744설명:
make_future_dataframe: 예측을 위한 미래 데이터프레임을 생성합니다.predict: 예측을 수행합니다.print: 예측 결과를 출력합니다.
시각화
Prophet은 Plotly 기반 시각화 함수와 Matplotlib 기반 시각화 함수를 제공합니다.
1. 예측 결과 시각화 (Plotly 사용)
from prophet.plot import plot_plotly, plot_components_plotly
# 예측 결과 시각화 (Plotly)
fig_forecast = plot_plotly(model, forecast)
fig_forecast.show()
# 컴포넌트 시각화 (Plotly)
fig_components = plot_components_plotly(model, forecast)
fig_components.show()설명:
plot_plotly: Plotly를 사용하여 예측 결과를 시각화합니다. 예측 결과를 인터랙티브하게 확인할 수 있으며, 마우스로 그래프를 확대하거나 특정 구간을 자세히 볼 수 있습니다.plot_components_plotly: Plotly를 사용하여 예측 결과의 컴포넌트(추세, 계절성, 휴일 효과 등)를 시각화합니다. 각 컴포넌트가 시계열 데이터에 어떤 영향을 미치는지 쉽게 파악할 수 있습니다.
2. 예측 결과 시각화 (Matplotlib 사용)
from prophet.plot import plot_forecast_component, add_changepoints_to_plot
# 예측 결과 시각화 (Matplotlib)
fig1 = model.plot(forecast)
plt.show()
# 컴포넌트 시각화 (Matplotlib)
fig2 = model.plot_components(forecast)
plt.show()설명:
plot: Matplotlib을 사용하여 예측 결과를 시각화합니다. 기본적으로 Prophet의 예측 결과를 시각화하며, 실제 데이터와 예측된 데이터, 예측 구간 등을 포함합니다.plot_components: Matplotlib을 사용하여 예측 결과의 컴포넌트를 시각화합니다. 추세, 주기성(계절성), 휴일 효과 등의 개별 컴포넌트를 시각화하여 데이터의 변동 요인을 시각적으로 분석할 수 있습니다.
가능 이슈
⚠️ 하지만! 여기서
2가지 문제점을 마주하실 수 있습니다!!
(1) 첫번째는 JupyterLab을 사용하는 분들의 경우 별도로 Plotly를 실행하실 경우, 시각화 코드는 실행은 되지만 결과가 보이지 않는 문제가 발생할 수 있습니다.
이 문제를 해결하기 위한 몇 가지 방법을 제안해 드리겠습니다:
-
주피터랩 확장 프로그램 설치:
JupyterLab에서 Plotly를 사용하려면 추가 확장 프로그램이 필요할 수 있습니다. 다음 명령어로 설치해보세요:jupyter labextension install jupyterlab-plotly -
렌더러 설정:
노트북 시작 부분에 다음 코드를 추가하여 렌더러를 명시적으로 설정해보세요:import plotly.io as pio pio.renderers.default = "jupyterlab" -
인라인 모드 사용:
plotly.offline.init_notebook_mode()를 사용하여 인라인 모드를 활성화해보세요:import plotly.offline as pyo pyo.init_notebook_mode(connected=True) -
명시적으로 그래프 표시:
fig.show()대신display(fig)를 사용해보세요:from IPython.display import display display(fig) -
주피터랩 재시작:
변경사항이 적용되지 않을 경우 주피터랩을 완전히 종료하고 다시 시작해보세요.
(2) 두번째는 Prophet의 plot 함수는 기본적으로 전체 예측 기간을 시각화하므로, 훈련 데이터와 예측 기간이 모두 포함됩니다. 따라서, 결과로 나온 그래프의 모양이 이쁘지 않을 확률이 매우매우 높습니다.
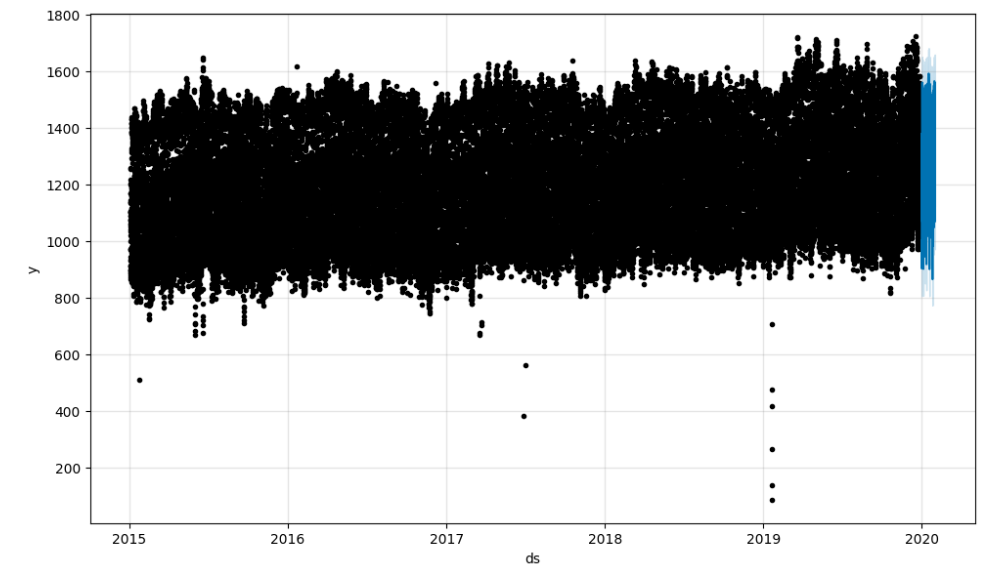
테스트 기간만 시각화하고 싶다면, 아래와 같이 예측 결과를 필터링하여 원하는 기간만 시각화할 수 있습니다.
- 시각화 표기 구역을
xlim을 통해 조절하여 설정해주면 test 결과만 볼 수 있습니다.
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 테스트 기간만 필터링
forecast_test_period = forecast[forecast['ds'].isin(test_data['ds'])]
# 전체 예측 결과를 시각화
fig = model.plot(forecast)
# x축의 범위를 테스트 기간으로 제한
plt.xlim([test_data['ds'].min(), test_data['ds'].max()])
# 테스트 데이터 실제값 추가
plt.plot(test_data['ds'], test_data['y'], 'r.', label='Actual')
# 그래프 표시
plt.show()
# Plotly를 사용하여 컴포넌트 시각화
fig_components = model.plot_components(forecast_test_period)
fig_components.show()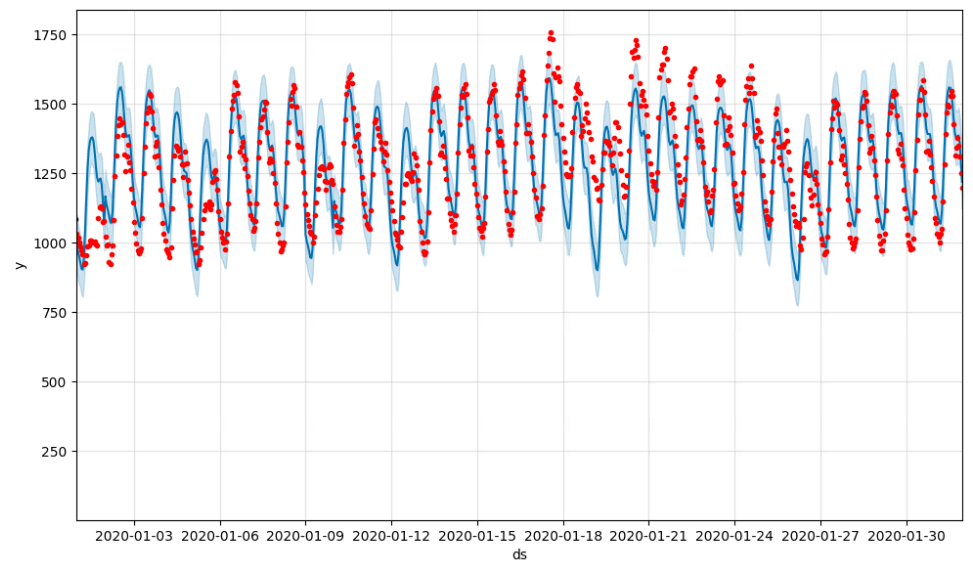
설명:
-
warnings.filterwarnings('ignore'): 경고 메시지를 무시하도록 설정합니다. -
forecast[forecast['ds'].isin(test_data['ds'])]: 테스트 데이터의 기간에 해당하는 예측 결과를 필터링합니다. -
model.plot(forecast): Prophet 모델의 예측 결과를 시각화합니다. 전체 예측 결과가 표시됩니다. -
plt.xlim([test_data['ds'].min(), test_data['ds'].max()]): x축의 범위를 테스트 기간으로 제한합니다. -
plt.plot(test_data['ds'], test_data['y'], 'r.', label='Actual'): 테스트 데이터의 실제 값을 그래프에 추가합니다. -
plt.show(): 그래프를 화면에 표시합니다. -
model.plot_components(forecast_test_period): Prophet 모델의 컴포넌트를 시각화합니다. Plotly를 사용하여 각 컴포넌트(추세, 계절성, 휴일 효과 등)를 시각화합니다. -
아니면 그냥 마음 편하게 직접 시각화 결과를 구현하는 방법도 있습니다.
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
# 실제값과 예측값 병합
result = test_data.copy()
result['yhat'] = forecast.set_index('ds').loc[test_data['ds']]['yhat'].values
# 예측 결과 시각화
plt.figure(figsize=(20, 4))
plt.plot(result['ds'], result['y'], label='Actual')
plt.plot(result['ds'], result['yhat'], label='Predicted', linestyle='dashed')
plt.fill_between(forecast['ds'], forecast['yhat_lower'], forecast['yhat_upper'], color='gray', alpha=0.2)
plt.legend()
plt.show()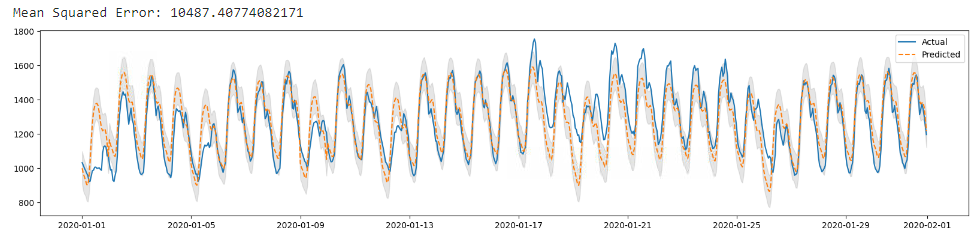
설명:
test_data.copy(): 테스트 데이터를 복사하여result데이터프레임을 생성합니다.forecast.set_index('ds').loc[test_data['ds']]['yhat'].values: 예측 결과에서 테스트 기간에 해당하는 예측 값을 추출합니다.result['yhat'] = ...: 추출한 예측 값을result데이터프레임에 추가합니다.plt.figure(figsize=(20, 4)): 그래프의 크기를 설정합니다.plt.plot(result['ds'], result['y'], label='Actual'): 테스트 데이터의 실제 값을 그래프에 추가합니다.plt.plot(result['ds'], result['yhat'], label='Predicted', linestyle='dashed'): 예측 값을 그래프에 추가합니다.plt.fill_between(forecast['ds'], forecast['yhat_lower'], forecast['yhat_upper'], color='gray', alpha=0.2): 예측 값의 불확실성 구간을 회색 음영으로 표시합니다.plt.legend(): 범례를 추가합니다.plt.show(): 그래프를 화면에 표시합니다.
성능 평가
예측 결과를 실제 테스트 데이터와 비교하여 성능을 검증합니다.
from sklearn.metrics import mean_squared_error
# 실제값과 예측값 병합
result = test_data.copy()
result['yhat'] = forecast.set_index('ds').loc[test_data['ds']]['yhat'].values
# 성능 평가 (MSE)
mse = mean_squared_error(result['y'], result['yhat'])
print(f'Mean Squared Error: {mse}')설명:
mean_squared_error: 실제값과 예측값의 평균 제곱 오차를 계산합니다.copy: 데이터프레임을 복사합니다.set_index: 데이터프레임의 인덱스를 설정합니다.loc: 특정 행을 선택합니다.
요약
이번 포스트에서는 Prophet에 대한 소개와 이를 활용한 시계열 예측을 수행해보았습니다.
- 데이터 준비: Prophet에서 요구하는 형식에 맞춰 데이터를 준비합니다.
- 모델 초기화 및 학습: Prophet 모델을 초기화하고 학습 데이터를 사용하여 모델을 학습시킵니다.
- 예측 수행: 미래 데이터프레임을 생성하고 예측을 수행합니다.
- 시각화: Prophet의 내장 함수를 사용하여 예측 결과와 컴포넌트를 시각화합니다.
- 성능 평가: 예측 결과를 실제 데이터와 비교하여 성능을 평가합니다.
긴 글 읽어주셔서 감사합니다 ⭐
