Pandas에서 데이터를 저장하고 로드하는 방법 중 하나로 .pkl(pickle) 파일을 사용할 수 있습니다.
Pickle 파일은 Python 객체를 직렬화(serialize)하여 저장하는 방식으로, 데이터를 바이너리 형식으로 변환하여 효율적으로 저장할 수 있습니다.
(참고) "데이터 직렬화"란 데이터를
저장 매체에 저장할 수 있는 형식또는네트워크를 통해 전송할 수 있는 형식으로 변환하는 것을 의미합니다.
Source: https://devopedia.org/data-serialization
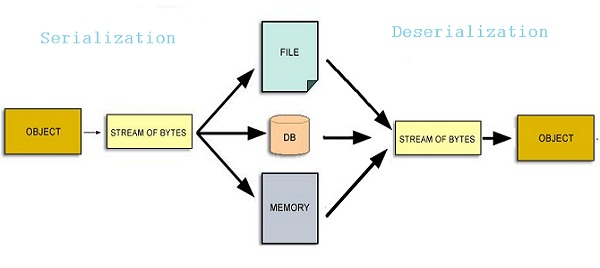
- Pickle 파일을 사용하면 데이터프레임의 구조를 그대로 유지하면서도 비교적 빠르게 저장 및 로드할 수 있다는 장점이 있습니다.
Pandas 피클 파일이란?

Pandas의 to_pickle() 및 read_pickle() 메서드를 사용하면 데이터프레임을 손쉽게 저장하고 다시 불러올 수 있습니다.
-
Pickle 파일은 CSV나 JSON과 같은 텍스트 기반 파일 형식과 달리, 데이터의 구조와 형식을 그대로 유지하면서도 보다 빠르고 쉽게 저장할 수 있습니다.
-
일반적으로, Pickle 파일은 데이터 저장 속도와 읽기 속도가 빠르며, Pandas에서 지원하는 다양한 객체를 손쉽게 저장할 수 있습니다.
-
그러나 Pickle 파일은 Python에서만 사용할 수 있는 형식이므로 다른 언어와의 호환성이 낮은 단점이 있습니다.
-
💡 (참고)
피클(Pickle)파일과파케이(Parquet)파일의 저장 및 로드 속도는 데이터의 특성, 파일 크기, 시스템 환경 등에 따라 다를 수 있습니다.
- 일부 문헌에서는 파케이 형식이 피클보다 더 빠른 성능을 보인다고 하지만, 이는 데이터의 구조와 내용에 따라 달라질 수 있습니다.
- 피클은 복잡한 데이터 구조를 유지하는 데 강점이 있지만, 대량의 데이터를 효율적으로 처리할 때는 Parquet 형식이 더 적합할 수 있습니다.
- 실제로 Pycon2023에서 대량의 데이터에 대해서는 Parquet이 더 효율적이었다는 발표도 있었습니다. (링크)
대량의 데이터를 다룰 경우 피클 파일의 크기가 커질 수 있으며, 이를 줄이기 위해 압축을 적용할 수 있습니다.
- Pandas는 다양한 압축 방식을 지원하며, 각각의 특징과 사용법이 다릅니다.
이번 글에서는 Pandas의 피클 파일에서 사용할 수 있는 주요 압축 방식(gzip, bz2, zip, xz)의 특징과 차이점을 정리하고, 언제 어떤 방식을 선택하는 것이 함께 살펴보고자 합니다.
📚 Pandas Documentation 기준 아래 내용입니다:
- https://pandas.pydata.org/docs/user_guide/io.html#pickling 중 Compressed pickle files
- 위 Documention에서는 다음과 같은 문장으로 간략하게 서술하지만,
"read_pickle(),DataFrame.to_pickle()andSeries.to_pickle()can read and write compressed pickle files. The compression types ofgzip,bz2,xz,zstdare supported for reading and writing. The zip file format only supports reading and must contain only one data file to be read."- 본 게시글에서는 이를 좀 더 면밀하게 파헤쳐보고자 하였습니다.
1. 주요 압축 방식 비교
주요 압축 기법들(gzip, bz2, xz, zstd)의 특징을 정리해보면 다음과 같이 정리해볼 수 있습니다.
| 압축 방식 | 압축률 | 압축 속도 | 해제 속도 | 사용 용도 | 특징 |
|---|---|---|---|---|---|
| gzip | 중간 | 빠름 | 빠름 | 일반적인 데이터 압축 | 많은 시스템에서 기본 지원 |
| bz2 | 높음 | 느림 | 느림 | 높은 압축률이 필요할 때 | CPU 사용량이 높음 |
| zip | 중간~낮음 | 빠름 | 빠름 | 다양한 파일을 묶을 때 | 윈도우 환경에서 널리 사용 |
| xz | 매우 높음 | 매우 느림 | 느림 | 장기 보관용 백업 | 압축 해제가 느릴 수 있음 |
각각의 기법들에 대해서 좀 더 자세하게 들여다 볼까요? 👀
2. 각 압축 방식의 특징 및 사용 예제
(1) gzip
-
특징:
- 압축 및 해제 속도가 빠르며, 네트워크 전송 시에도 많이 사용됩니다.
-
적합한 상황:
- 빠른 데이터 저장 및 로딩이 필요한 경우
- 파일 크기보다는 속도가 중요한 경우
예제 코드:
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# gzip 압축을 적용하여 피클 저장
df.to_pickle('data.pkl.gz', compression='gzip')
# 저장된 피클 파일을 읽기
df_loaded = pd.read_pickle('data.pkl.gz', compression='gzip')(2) bz2
-
특징:
- 높은 압축률을 제공하지만, 압축 및 해제 속도가 느립니다.
-
적합한 상황:
- 저장 공간 절약이 중요한 경우
- 압축/해제 속도가 느려도 괜찮은 경우
예제 코드:
# bz2 압축 적용
df.to_pickle('data.pkl.bz2', compression='bz2')
df_loaded = pd.read_pickle('data.pkl.bz2', compression='bz2')(3) zip
-
특징:
- 여러 파일을 하나로 묶을 수 있으며, 다양한 운영체제에서 널리 지원됩니다.
-
적합한 상황:
- 여러 개의 파일을 하나의 압축 파일로 저장해야 하는 경우
- 호환성이 중요한 경우 (특히 Windows 환경)
예제 코드:
# zip 압축 적용
df.to_pickle('data.pkl.zip', compression='zip')
df_loaded = pd.read_pickle('data.pkl.zip', compression='zip')(4) xz
-
특징:
- 매우 높은 압축률을 제공하지만, 압축 및 해제 속도가 매우 느립니다.
-
적합한 상황:
- 장기 보관용 데이터 압축
- 저장 공간을 최대한 절약해야 하는 경우
예제 코드:
# xz 압축 적용
df.to_pickle('data.pkl.xz', compression='xz')
df_loaded = pd.read_pickle('data.pkl.xz', compression='xz')3. 언제 어떤 압축 방식을 선택해야 할까?
각 방식의 특징을 종합하여, 상황별 적합한 압축 방식을 정리해보았습니다.
| 상황 | 추천 압축 방식 | 이유 |
|---|---|---|
| 속도가 가장 중요한 경우 | gzip | 빠른 압축 및 해제 |
| 최대 압축률이 필요한 경우 | xz | 매우 높은 압축률 제공 |
| 속도보다 압축률이 중요한 경우 | bz2 | gzip보다 높은 압축률 제공 |
| 여러 개의 파일을 묶을 때 | zip | 호환성이 좋고 여러 파일을 압축 가능 |
4. 결론
Pandas에서 피클 파일을 저장할 때 압축을 적용하면 파일 크기를 줄이고, 전송 및 저장 공간을 절약할 수 있습니다. 하지만 각 압축 방식마다 장단점이 존재하므로, 데이터의 특성과 사용 목적에 맞춰 적절한 압축 기법을 선택하는 것이 중요합니다.
- gzip: 빠른 압축 및 해제 속도가 필요한 경우 추천
- bz2: 높은 압축률을 원하지만 속도는 중요하지 않은 경우
- zip: 여러 개의 파일을 묶어 저장하거나, Windows 환경에서 호환성을 고려할 때
- xz: 최대한 높은 압축률이 필요하지만 속도가 느려도 괜찮을 때
개인적으로 업무에서는 주로 gzip을 활용하지만, 이번 글을 통해 다양한 압축 기법의 특성을 정리하며 대안을 찾아보고자 했습니다.
여러분은 어떤 압축 방식을 주로 사용하시나요? 각자의 경험과 활용 사례를 공유해 주세요! 😊
오늘도 읽어주셔서 감사합니다 🙇♂️
