
들어가며
2026년 Google I/O 키노트는 AI 모델 발전을 넘어 Agentic AI(에이전트 AI)의 실용화가 본격 시작되었음을 알리는 자리였습니다. Sundar Pichai CEO는 지난 10년간 AI-first 회사로 전환한 이후 가장 강도 높은 한 해였다고 회고하며, Gemini 3.5 Flash, Gemini Omni, Antigravity 2.0, Gemini Spark, Intelligent Eyewear 등 차세대 기술 스택을 차례로 공개했습니다.
이번 키노트의 핵심 메시지는 명확합니다. AI는 이제 "텍스트를 예측하는 단계"를 넘어 "세계를 시뮬레이션하고, 사용자를 대신해 행동하는 단계"로 진입했다는 것입니다. 이는 LLM의 다음 패러다임이 무엇인지에 대한 Google의 답이기도 합니다. 단순한 chat 인터페이스에서 벗어나, 모델이 environment(환경)을 인식하고, plan(계획)을 수립하며, tool(도구)을 사용하고, 자율적으로 actuate(실행)하는 통합 시스템으로 진화하고 있습니다. 이 글에서는 키노트 흐름을 따라 각 발표를 단계별로 상세히 정리하겠습니다.

1. Sundar Pichai의 Opening Remarks
1.1 풀스택 AI 전략
Pichai는 Google의 차별점으로 풀스택(full-stack) 접근법을 강조했습니다.

이는 단순한 모델 개발이 아니라 다음 계층을 모두 자체 보유한다는 의미입니다.
- Custom silicon: TPU
- Secure foundation: 데이터센터, 보안 인프라
- World-class research: Google DeepMind
- Products and platforms: 13개의 10억 사용자급 제품군
이 접근법의 장점은 iteration loop의 속도입니다. 자체 칩에서 자체 모델을 학습하고, 자체 제품에서 즉시 배포해 피드백을 얻을 수 있기 때문에 외부 의존성이 없습니다. AI 산업에서 이는 매우 중요한 차별점입니다. 대부분의 AI 회사들은 NVIDIA GPU에 의존하거나 모델만 만들고 배포 채널이 없거나, 반대로 채널은 있지만 모델 자체 개발 역량이 부족한 경우가 많습니다. Google은 학습 데이터(검색, YouTube), 컴퓨팅(TPU), 모델(Gemini), 배포 채널(검색, Android, Workspace)을 모두 보유하고 있어 vertical integration의 강점을 살릴 수 있습니다.
1.2 토큰 처리량으로 본 AI 채택 규모
Pichai가 가장 강조한 지표는 월간 토큰 처리량(token throughput)입니다. 이는 추상적인 "사용자 수"보다 AI가 실제로 얼마나 일하고 있는지를 직접적으로 보여주는 지표입니다.
| 시점 | 월간 토큰 처리량 | 증가율 |
|---|---|---|
| 2024년 5월 (2년 전) | 9.7조 (trillion) | 기준점 |
| 2025년 5월 (1년 전 I/O) | 480조 | 약 50배 |
| 2026년 5월 (현재) | 3.2 quadrillion (3,200조) | 약 7배 |
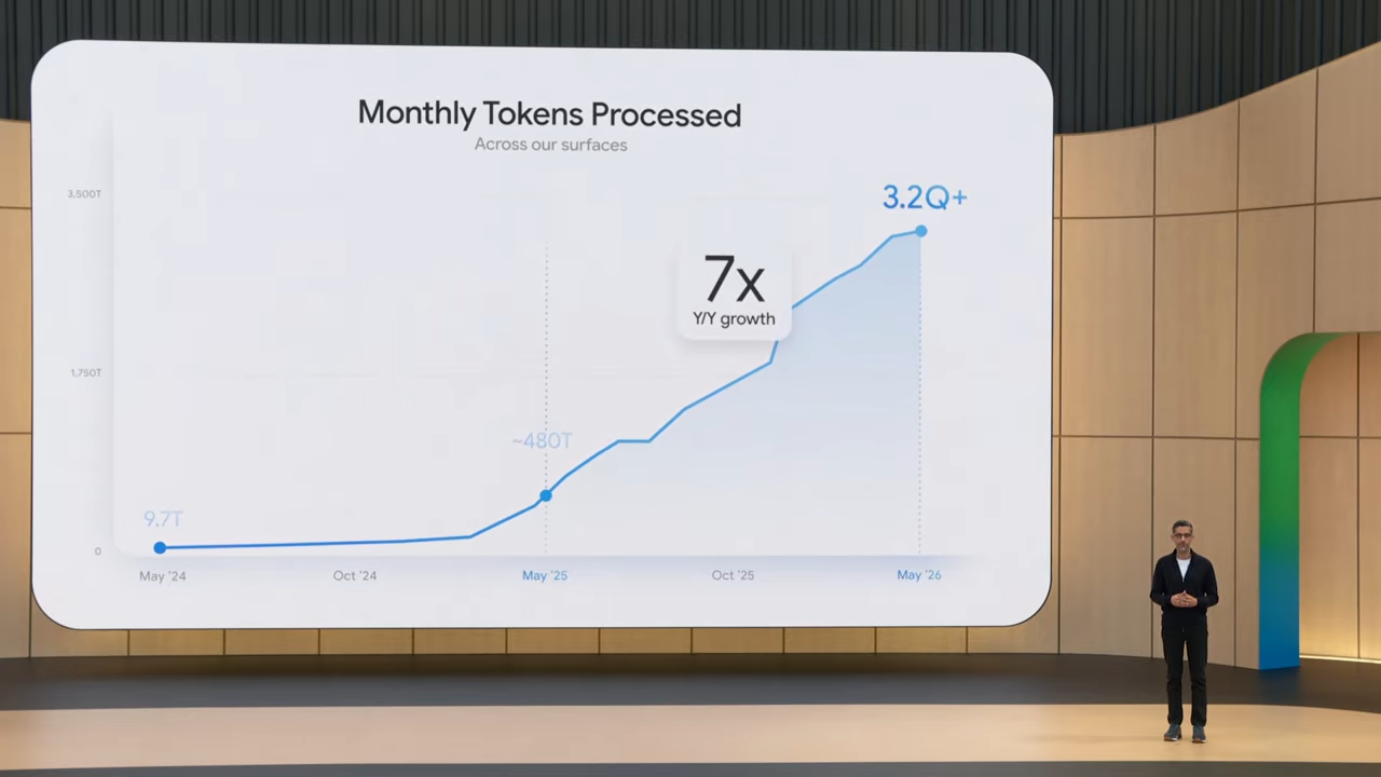
추가로 공개된 세부 지표는 다음과 같습니다.
- 월간 모델 기반 앱을 빌드하는 개발자: 850만 명 이상

- API 처리량: 분당 약 190억 토큰
- 지난 12개월간 각각 1조 토큰 이상을 처리한 고객사: 375개 이상

이 숫자들은 단순히 "많이 사용한다"가 아니라, B2B와 B2C 모두에서 AI가 인프라 레벨로 흡수되었다는 것을 시사합니다. 토큰 처리량은 단순한 vanity metric이 아니라 모델 사용의 경제학과 직접 연결됩니다. Quadrillion 단위는 우리에게 친숙하지 않은 규모이지만, 이는 분당 약 70억 토큰, 즉 매분 세계 인구 수와 비슷한 양의 토큰이 처리된다는 의미입니다. 이런 규모는 chat completion 같은 단순 사용으로는 도달할 수 없으며, agentic workflow에서 모델이 여러 단계로 호출되고 tool을 사용하면서 발생하는 polynomial growth가 핵심 동인입니다.
1.3 제품별 채택 현황
-
10억 명 이상 사용자를 가진 제품: 13개
-
30억 명 이상 사용자를 가진 제품: 5개
-
AI Overviews: 월 25억 명 사용자

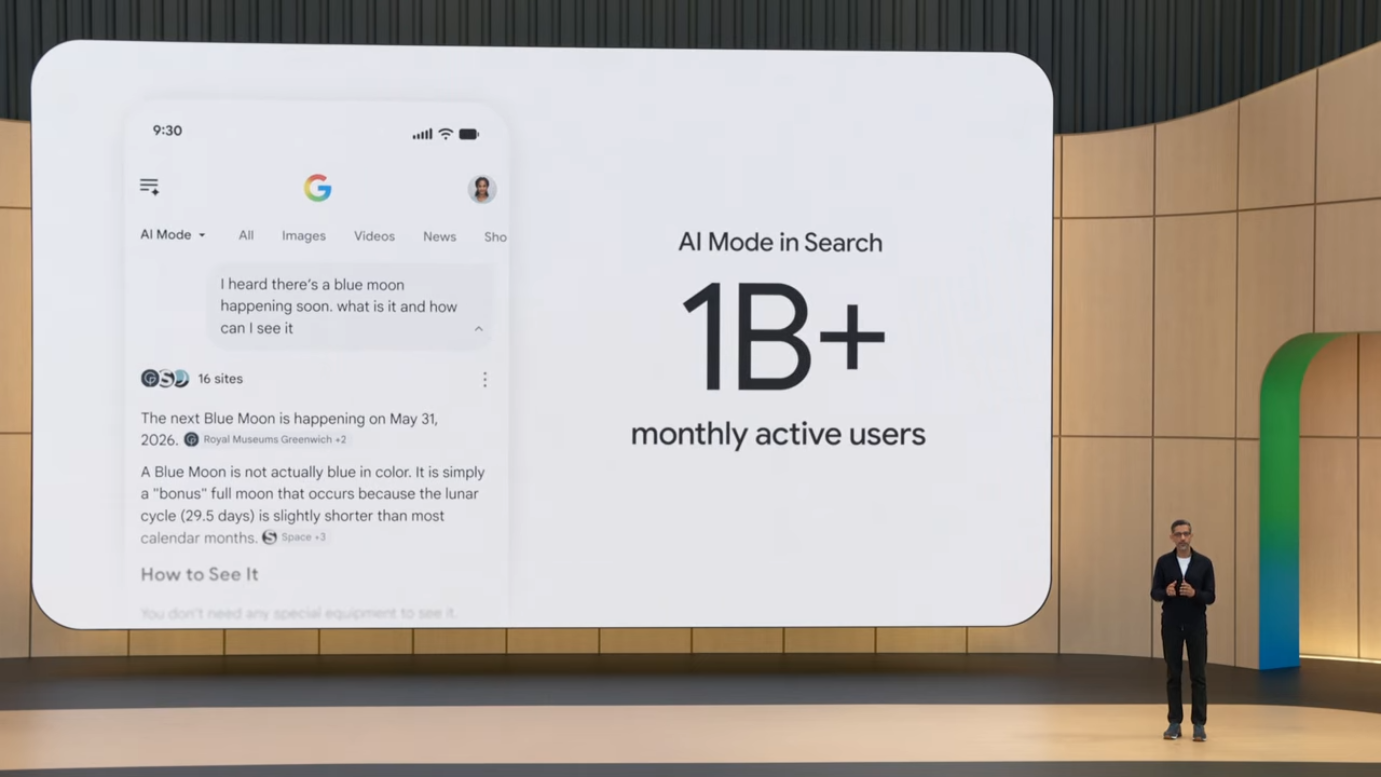
- AI Mode: 출시 1년 만에 월 10억 명 돌파 (가장 빠른 신기능 채택)
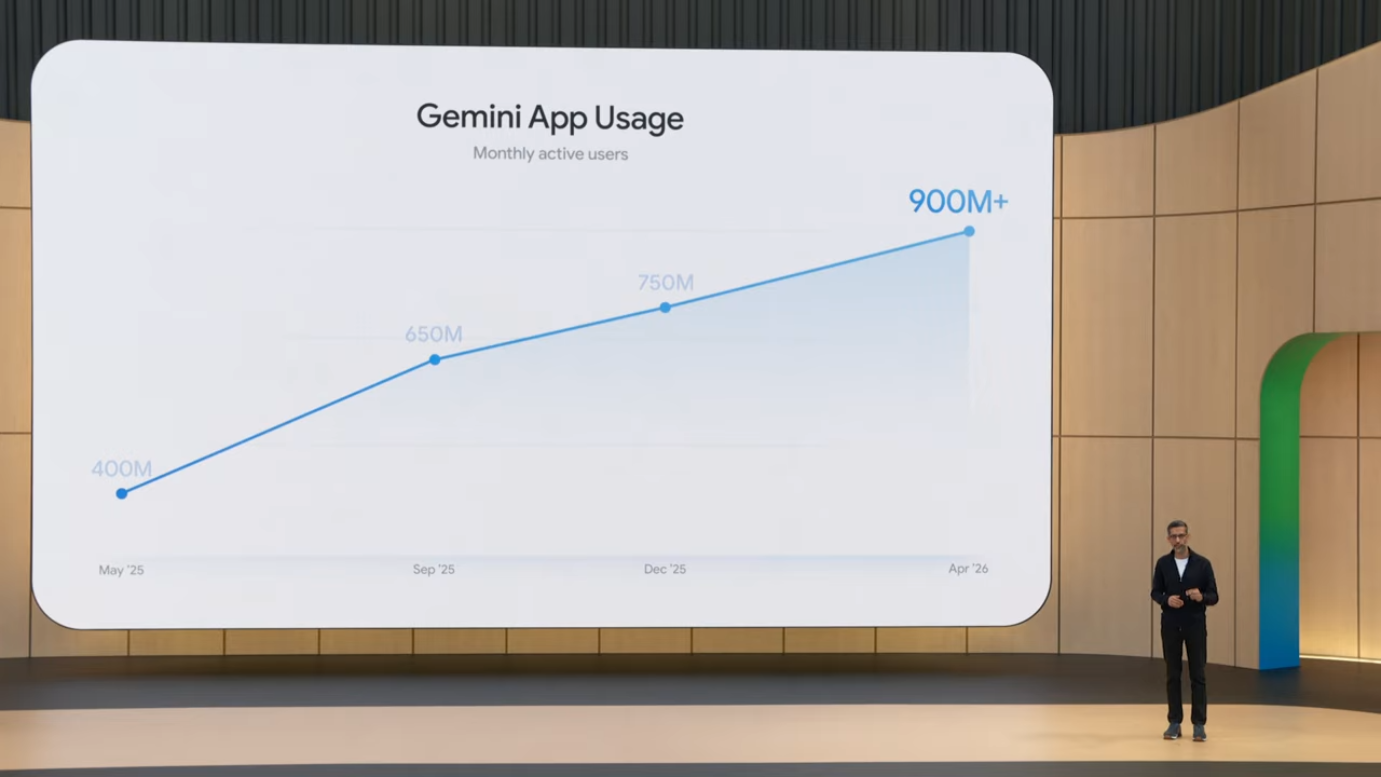
- Gemini 앱: 월 4억 명 → 9억 명 (1년 만에 2배 이상, 일일 요청은 7배 이상 증가)
- Nano Banana로 생성된 이미지 누적: 500억 장

주목할 점은 일일 요청 증가율이 사용자 증가율을 훨씬 앞선다는 것입니다. 사용자는 2배 증가했지만 요청은 7배 증가했습니다. 이는 사용자들이 단순히 "AI를 한 번 써본다"가 아니라 일상적인 워크플로우에 통합하고 있다는 신호입니다. AI Mode가 1년 만에 10억 사용자에 도달한 것도 의미가 큽니다. 비교하자면 ChatGPT는 1억 사용자 도달에 2개월이 걸려 가장 빠른 채택 사례로 회자되었는데, AI Mode는 Search라는 기존 채널의 강점을 활용해 더 큰 규모에 빠르게 도달한 셈입니다.
1.4 Ask Maps: 대화형 지도
Maps는 10년 만의 최대 업데이트로 Ask Maps를 출시했습니다.

이 기능의 특징은 자연어로 매우 길고 복잡한 질문을 받을 수 있다는 점입니다. Pichai는 실제 부모가 입력한 쿼리를 예시로 들었습니다.
"My kid just fell into the duckpond and the wedding starts in 30 minutes. Where can I walk and buy her a new dress?"
이는 위치, 시간 제약, 의도(아이 옷 구매), 이동 수단(도보)을 모두 추론해야 하는 쿼리로, 기존 키워드 기반 검색으로는 풀 수 없는 종류입니다. 전통적인 Maps는 "근처 옷 가게"라는 키워드를 받았다면, Ask Maps는 암묵적 제약 조건(30분 안에 도착해야 함, 아이 옷이어야 함, 도보 이동 가능 거리여야 함)을 자동 추론합니다.

이는 LLM이 유한한 컨텍스트에서 다단계 reasoning을 수행할 수 있게 된 결과로, 사용자가 자신의 의도를 굳이 "검색 친화적으로 변환"하지 않아도 되는 경험을 제공합니다.
1.5 Ask YouTube
YouTube에 대화형 쿼리를 던지면 영상의 가장 관련 있는 시점으로 점프해주는 기능입니다.

단순 검색이 아니라 다음을 수행합니다.
- 질문에 대한 정보를 정리된 형태로 요약
- 사용자 관심사에 가장 맞는 영상 추천
- 영상 내 가장 관련 있는 시점으로 자동 이동
- 후속 질문 시 컨텍스트 유지 (예: "그럼 핸드 브레이크와 페달 브레이크 중 뭘 사야 해?" → 표 형식으로 비교 응답)
이 기능의 기술적 기반은 비디오 콘텐츠의 시맨틱 인덱싱입니다. 단순한 transcript 검색이 아니라, 영상의 내용을 의미 단위로 분할(chunk)하고 각 chunk를 임베딩한 후, 사용자 쿼리와의 의미적 유사도를 기반으로 가장 적절한 시점을 찾습니다. 더 나아가 후속 질문에서 컨텍스트가 유지된다는 것은 dialogue state management가 작동하고 있다는 의미입니다. 사용자는 영상마다 다시 검색할 필요 없이, 한 명의 expert와 대화하듯 콘텐츠를 탐색할 수 있게 됩니다.

여름에 미국부터 순차 출시 예정입니다.
1.6 Docs Live: 음성 기반 문서 생성
Docs Live는 정확한 프롬프트 없이 음성으로 brain-dump하면 Gemini가 문서로 정리해주는 기능입니다.

데모에서는 다음과 같은 자연스러운 발화가 가능했습니다.
- "내일 모교에서 진로의 날 행사 발표하는데 뭘 말해야 할지 모르겠어"
- "Drive에서 내 이력서 가져와줘. 근데 그건 좀 지루할 수도 있으니까 학생들이 재밌어할 비유들도 추가해줘"
- "학교에서 보낸 이메일 있을 거야. 제목이 'career day logistics' 같은 거. 거기서 장소랑 시간 정보 가져와서 문서 맨 위에 넣어줘"
- "비유들은 표로 정리해서 한눈에 보이게 해줘"
- "맨 위에 '동생이 소프트웨어 엔지니어가 되도록 영감을 줬다는 이야기'를 추가하라는 메모를 굵게 표시해줘"
이 모든 작업이 실시간으로 처리되었으며, Pro/Ultra 구독자 대상으로 여름에 출시되고 추후 Gmail과 Google Keep으로 확장됩니다. 이 데모의 핵심은 불완전하고 비선형적인 인간의 사고 흐름을 그대로 받아들인다는 점입니다. 사용자는 "이건 지루할 수도 있어"처럼 자기 의심을 표현하거나, 도중에 마음을 바꾸거나, 여러 소스(Drive, Gmail)를 즉흥적으로 참조합니다. 기존 음성 인터페이스는 명확한 명령(예: "이메일 보내")만 받을 수 있었지만, Docs Live는 conversational ambiguity(대화적 모호성)를 자연스럽게 처리합니다. 이는 LLM의 컨텍스트 이해력과 도구 사용 능력이 결합되었기에 가능합니다.

여름에 AI Pro 및 Ultra 유저에게 제공됩니다.
1.7 인프라 투자: TPU 8세대
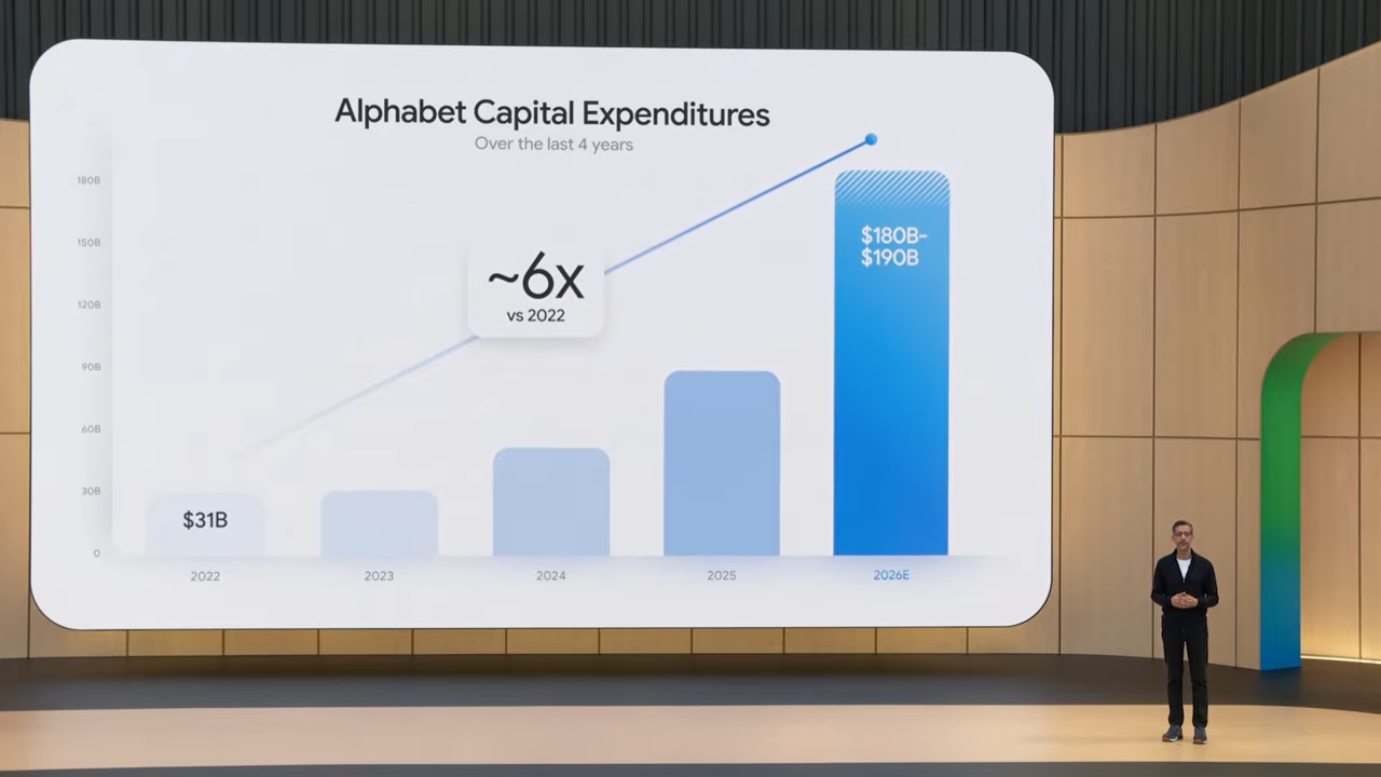
Google의 연간 CapEx(Capital Expenditure, 설비 투자)는 2022년 $31B에서 2026년 $180~190B로 약 6배 증가했습니다.
핵심 인프라인 TPU는 8세대에서 처음으로 이중 칩(dual-chip) 전략을 도입했습니다. 같은 세대에서 학습용과 추론용을 별도 설계한 것은 이번이 처음입니다.
| 구분 | TPU 8t (Training) | TPU 8i (Inference) |
|---|---|---|
| 최적화 목표 | 대규모 사전학습(pretraining) | 추론 latency |
| 성능 | 이전 세대 대비 약 3배 raw compute | 단계별 속도 대폭 개선 |
| 에너지 효율 | 와트당 성능 최대 2배 향상 | 와트당 성능 최대 2배 향상 |
| 핵심 기술 | JAX + Pathways 분산 학습 | 추론 파이프라인 최적화 |
Training과 Inference를 별도로 최적화하는 이유는 두 작업의 computational profile이 완전히 다르기 때문입니다.
- Training은 대규모 batch와 backward pass를 다루기 때문에 메모리 대역폭과 floating point throughput이 중요하게 됩니다.

- Inference는 단일 사용자 요청에 대한 latency가 핵심이며 KV cache 관리, speculative decoding 같은 다른 최적화가 필요합니다.

하나의 칩으로 두 가지를 모두 잘하려면 trade-off가 발생하기 때문에 분리한 것입니다. NVIDIA가 H100/B200 같은 범용 칩을 만드는 것과 대비되는 전략적 선택입니다.
JAX와 Pathways의 의미가 특히 중요합니다. 기존에는 모델 학습이 단일 데이터센터의 물리적 한계(전력, 네트워크, 냉각)에 묶여 있었습니다. Pathways는 이를 추상화해 여러 데이터센터에 걸쳐 100만 개 이상의 TPU를 하나의 학습 클러스터처럼 사용할 수 있게 합니다. 이는 세계 최대 규모의 학습 클러스터로, "대형 모델을 몇 달이 아닌 몇 주 안에 학습 가능"하다는 것이 Pichai의 주장입니다. 분산 학습의 핵심 challenge는 gradient synchronization 오버헤드인데, Pathways는 이를 데이터센터 간 통신에 맞게 재설계한 것으로 보입니다.
2. Gemini Omni: World Model의 다음 단계
2.1 World Model의 개념
Demis Hassabis(Google DeepMind CEO)가 무대에 올라 World Model의 발전을 소개했습니다. World Model이란 AI가 단순히 텍스트의 다음 토큰을 예측하는 것을 넘어, 물리 법칙과 현실의 동역학을 시뮬레이션하는 모델을 의미합니다.

Hassabis는 이를 AGI 달성의 핵심 요소로 설명했습니다.
"AI is moving from predicting text to simulating reality."
World Model이 중요한 이유는 다음과 같습니다.
- AI 어시스턴트: 사용자의 행동 결과를 예측해야 진정한 도움을 줄 수 있음
- 로봇 학습: 시뮬레이션 환경에서 안전하게 정책을 학습 가능
- 과학적 시뮬레이션: 단백질 폴딩, 기상 예측 등 복잡 시스템 모델링
World Model 개념은 본래 강화학습 분야에서 출발한 아이디어입니다. David Ha와 Jürgen Schmidhuber의 2018년 논문 "World Models"에서 제안된 이 개념은, 에이전트가 환경 자체를 학습한 후 그 안에서 상상(imagination)을 통해 정책을 학습할 수 있다는 것이었습니다. (https://arxiv.org/pdf/1803.10122)
💡 LLM 시대의 World Model은 이를 훨씬 확장한 것으로, 텍스트, 이미지, 비디오, 오디오 같은 multimodal 데이터에서 물리적·사회적·논리적 규칙성을 학습합니다. 이는 단순히 "다음 프레임을 예측"하는 것을 넘어, action의 결과를 예측할 수 있는 능력의 기반이 됩니다.

2.2 Gemini Omni의 아키텍처적 특징
Gemini Omni는 any input → any output을 지향하는 모델입니다.
Gemini의 추론 능력과 Veo(비디오), Nano Banana(이미지), Genie(인터랙티브 시뮬레이션) 같은 생성 미디어 모델들을 하나로 통합한 것입니다.
핵심 개선점은 다음과 같습니다.
- Intuitive Physics 이해의 단계적 도약: 운동 에너지, 중력 등의 시뮬레이션 정확도 향상
- Iterative Editing: 한 번에 완성하는 것이 아니라 대화형 언어로 비디오를 자연스럽게 수정
- Scene Morphing: 셀카에 블랙홀을 추가하거나, 단순한 원을 블랙홀로 변환하거나, 저녁 산책 장면을 완전히 다른 분위기로 변환하는 등 장면 전체가 자연스럽게 morphing됨
- Multimodal from the start: Hassabis는 "Gemini를 처음부터 multimodal로 빌드한 것이 어려운 길이었지만 이제 그 기반이 빛을 발하고 있다"고 강조
여기서 "multimodal from the start"라는 표현은 중요한 아키텍처적 함의를 가집니다.
- 많은 모델들은 text-only로 사전 학습된 후 vision adapter를 붙이는 방식(예: LLaVA 계열)을 사용합니다.
- 반면 native multimodal 아키텍처는 처음부터 다양한 modality의 토큰을 통합된 표현 공간에서 학습합니다. 이 접근법은 학습이 어렵지만, modality 간의 deep cross-attention과 grounded reasoning이 가능해진다는 장점이 있습니다.
💡 Omni가 "selfie를 블랙홀로 변환"하면서 인물의 동작과 의도를 보존할 수 있는 것은 이러한 deep multimodal grounding 때문입니다.
2.3 Claymation 예시
데모로 단순한 프롬프트("단백질 폴딩을 설명하는 클레이메이션 영상을 만들어줘")로부터 일관성 있는 설명 영상을 생성하는 모습이 시연되었습니다.

영상 내 나레이션은 다음과 같습니다.
단백질은 아미노산 사슬에서 시작합니다. 이들은 알파 헬릭스 같은 패턴, 그리고 베타 시트라고 불리는 평평한 구조로 접히며, 완벽한 3차원 형태를 형성합니다.
이 데모의 의미는 단순히 "예쁜 영상이 나온다"가 아닙니다. 추상적이고 과학적인 개념을 시각적·시간적 일관성을 유지하며 물리적으로 그럴듯한 애니메이션으로 변환할 수 있다는 점이 핵심입니다.
비디오 생성에서 가장 어려운 문제 중 하나는 temporal consistency입니다. 즉, 프레임 간에 객체의 정체성, 위치, 형태가 자연스럽게 유지되어야 한다는 것입니다. 또한 단백질 폴딩 같은 과학 개념은 추상적 도식으로 표현되어야 하는데, 이는 모델이 알파 헬릭스나 베타 시트 같은 구조의 의미를 단순한 시각적 패턴이 아니라 개념적 표현으로 이해해야 가능합니다. Omni가 이 두 가지를 동시에 달성한다는 것은 World Model로서의 깊이를 보여주는 강력한 증거입니다.
2.4 출시 정보
- Gemini Omni Flash: 발표 당일 출시, 전 제품에서 사용 가능

- Gemini Omni Pro: 추후 공개 예정 ("soon")
2.5 SynthID와 Content Credentials 확장
생성형 AI의 발전에 따른 투명성 문제도 다뤄졌습니다. 연구에 따르면 사람이 고품질 딥페이크 비디오를 정확히 식별할 확률은 약 25%에 불과합니다. Google은 이에 대응해 SynthID를 확대 적용하고 있습니다.

SynthID 누적 적용 현황 (출시 3년)
- 이미지/비디오: 1,000억 개
- 오디오: 60,000년 분량
- Gemini 앱 내 SynthID Detector 사용자: 수백만 명
Content Credentials Verification
콘텐츠가 AI로 생성되었는지, 카메라로 촬영되었는지, 그리고 어떤 편집 도구로 수정되었는지를 표시합니다.
데모 예시로 "Pixel 카메라로 촬영 후 Google Photos에서 편집됨" 같은 정보가 표시되었습니다. Search와 Chrome으로 확장되어 Circle to Search 또는 우클릭으로 "이거 AI로 생성된 거야?" 확인이 가능합니다.

신규 파트너십
기존 NVIDIA에 더해 다음 회사들이 SynthID를 채택했습니다.
- OpenAI
- Kakao
- Eleven Labs

OpenAI가 Google의 SynthID 표준을 채택했다는 것은 업계 표준으로 자리 잡을 가능성을 높이는 중요한 신호입니다. SynthID는 단순한 metadata 워터마크가 아니라 모델의 latent space에 통합된 형태로 콘텐츠에 삽입되기 때문에, screenshot이나 압축 같은 변형에도 강건합니다.
💡 다만, 워터마크 기술은 본질적으로 adversarial robustness 문제를 안고 있어, 워터마크 제거 공격에 대응하기 위한 지속적인 연구가 필요합니다. 업계 전반의 채택이 늘어날수록 이 ecosystem의 가치는 기하급수적으로 증가합니다.
3. Gemini 3.5 Flash와 Google Antigravity 2.0
3.1 Gemini 3.5 Flash의 포지셔닝
Gemini 3.5 Flash는 "frontier intelligence with action"을 표방합니다.

이는 단순히 더 똑똑한 모델이 아니라, agentic 워크플로우에서 실제로 작동하도록 최적화되었다는 의미입니다.
Pichai가 강조한 두 가지 핵심:
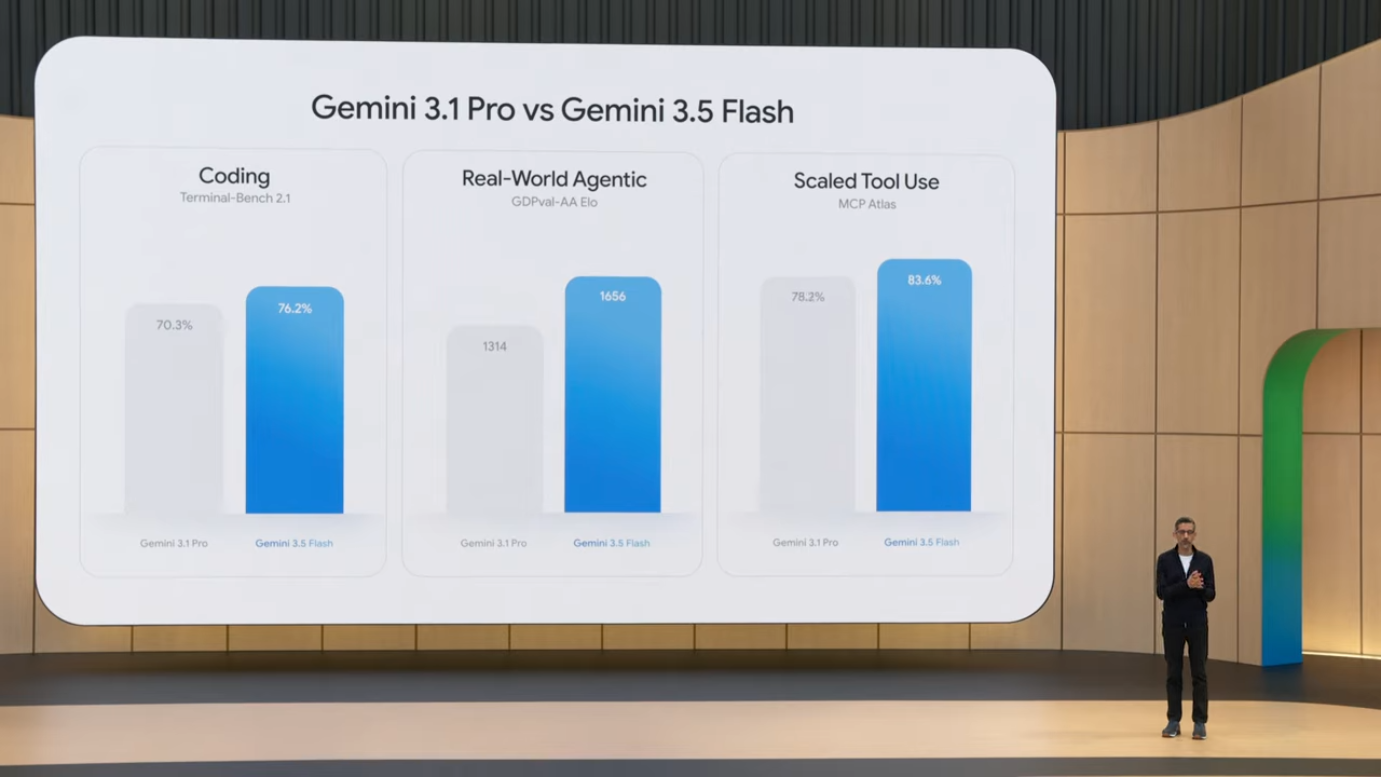
- 3.1 Pro 대비 거의 모든 벤치마크에서 향상: 특히 코딩, long-horizon task, real-world workflow에서 강력
- 속도-지능 trade-off의 새로운 영역 진입: Intelligence vs Output Speed 차트에서 우상단 사분면(가장 빠르면서 가장 똑똑한 영역)에 단독 위치
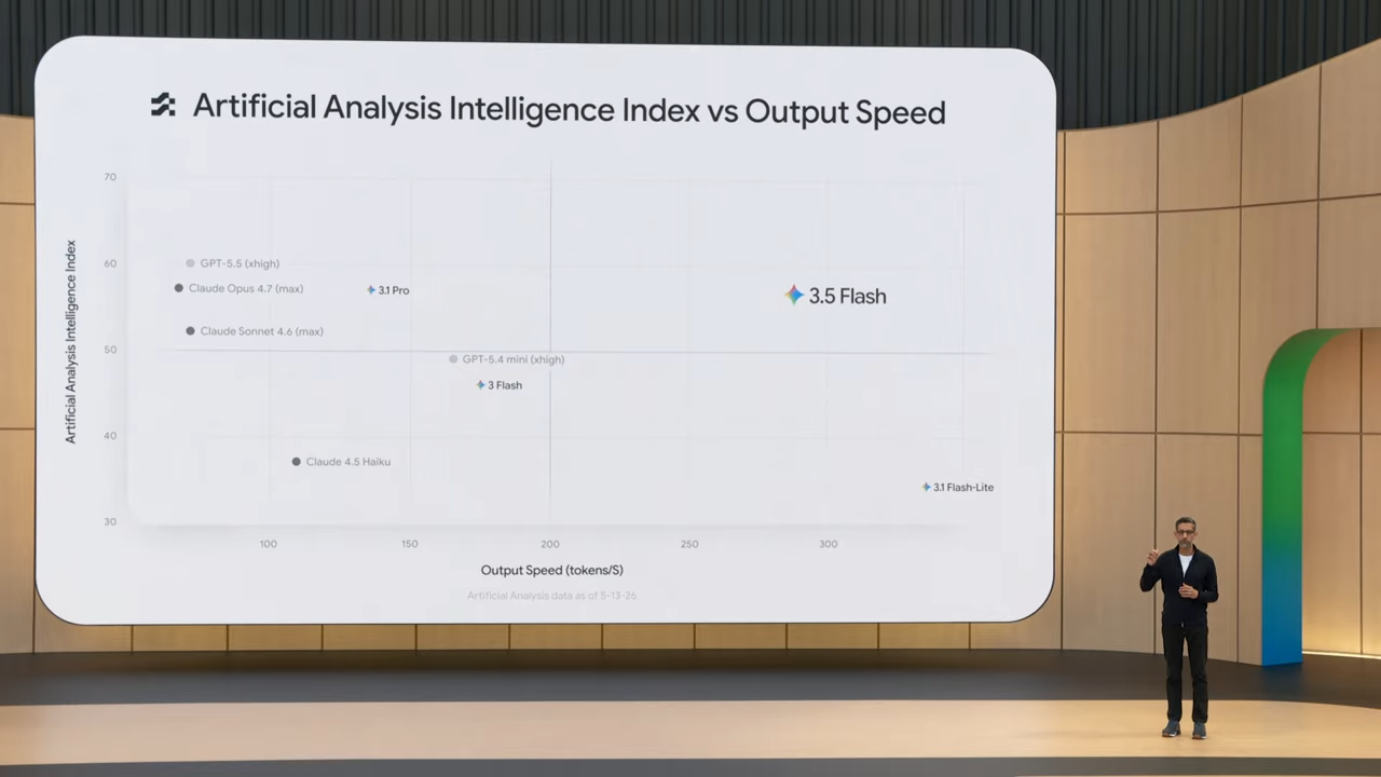
Flash 라인업이 Pro를 능가하는 벤치마크들이 등장했다는 점은 매우 의미심장합니다. 전통적으로 모델 라인업은 "작고 빠른 모델 vs 크고 똑똑한 모델"의 trade-off가 명확했습니다. 그런데 3.5 Flash가 3.1 Pro를 따라잡았다는 것은, 모델 효율성 개선 속도가 모델 규모 확장 속도보다 빨라지고 있음을 의미합니다. 이는 distillation, MoE(Mixture of Experts), 더 나은 데이터 큐레이션, post-training RLHF 등의 기법들이 누적적으로 효과를 발휘하고 있다는 신호입니다.
3.2 GDP-val 벤치마크
Pichai가 특별히 강조한 벤치마크는 GDP-val입니다. 이는 실제 경제적 가치를 갖는 작업들(보고서 작성, 분석, 의사결정 지원 등)을 측정하는 지표로, 학술적 벤치마크보다 실용성을 더 직접적으로 반영합니다. 3.5 Flash는 이 벤치마크에서 큰 도약을 보였습니다.
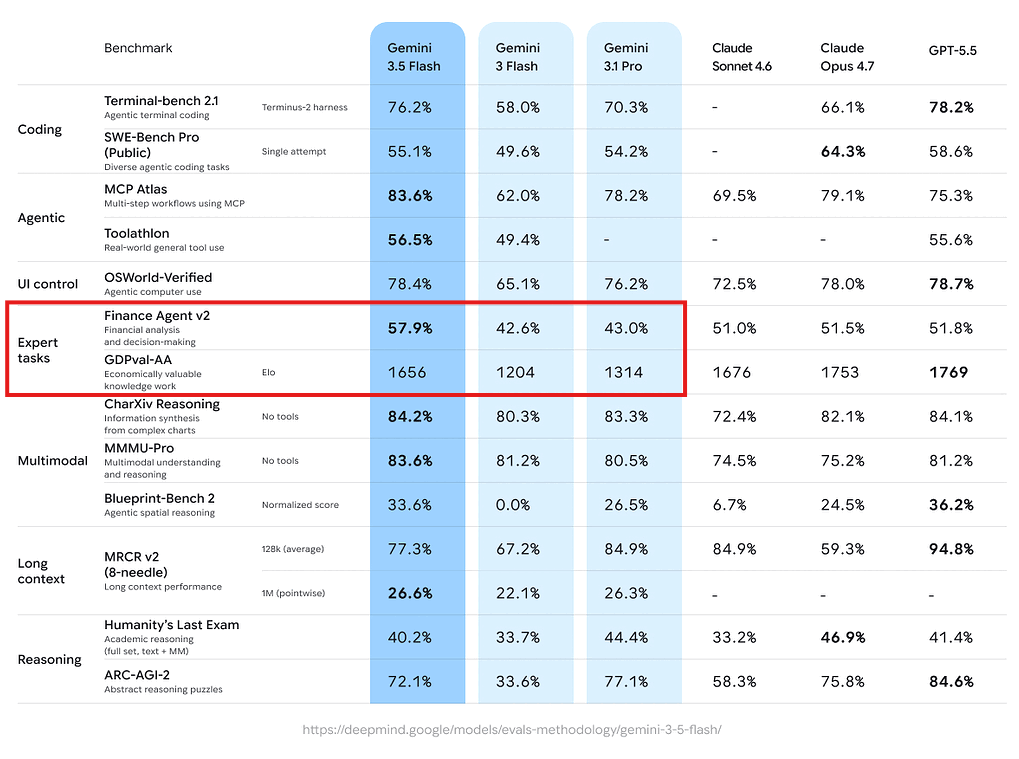
GDP-val 같은 벤치마크의 등장은 AI 평가 방법론의 변화를 보여줍니다. MMLU, HumanEval 같은 기존 벤치마크는 standardized test 형태로 정형화된 문제를 다뤘기 때문에, 모델이 벤치마크에 과적합되거나(test set leak) 실제 사용 환경과 괴리가 생기는 문제가 있었습니다. GDP-val은 실제 직업 현장의 task를 기반으로 하기 때문에, 모델이 진짜 economic value를 창출할 수 있는지를 측정합니다. 이는 OpenAI의 SWE-bench, Anthropic의 RE-bench와 같은 흐름이며, 벤치마크가 점점 "현실의 일"에 가까워지고 있다는 트렌드의 일부입니다.
3.3 속도 비교
- 다른 frontier 모델 대비 출력 속도 약 4배
- Antigravity 환경에서는 12배 빠른 속도로 동작하도록 추가 최적화
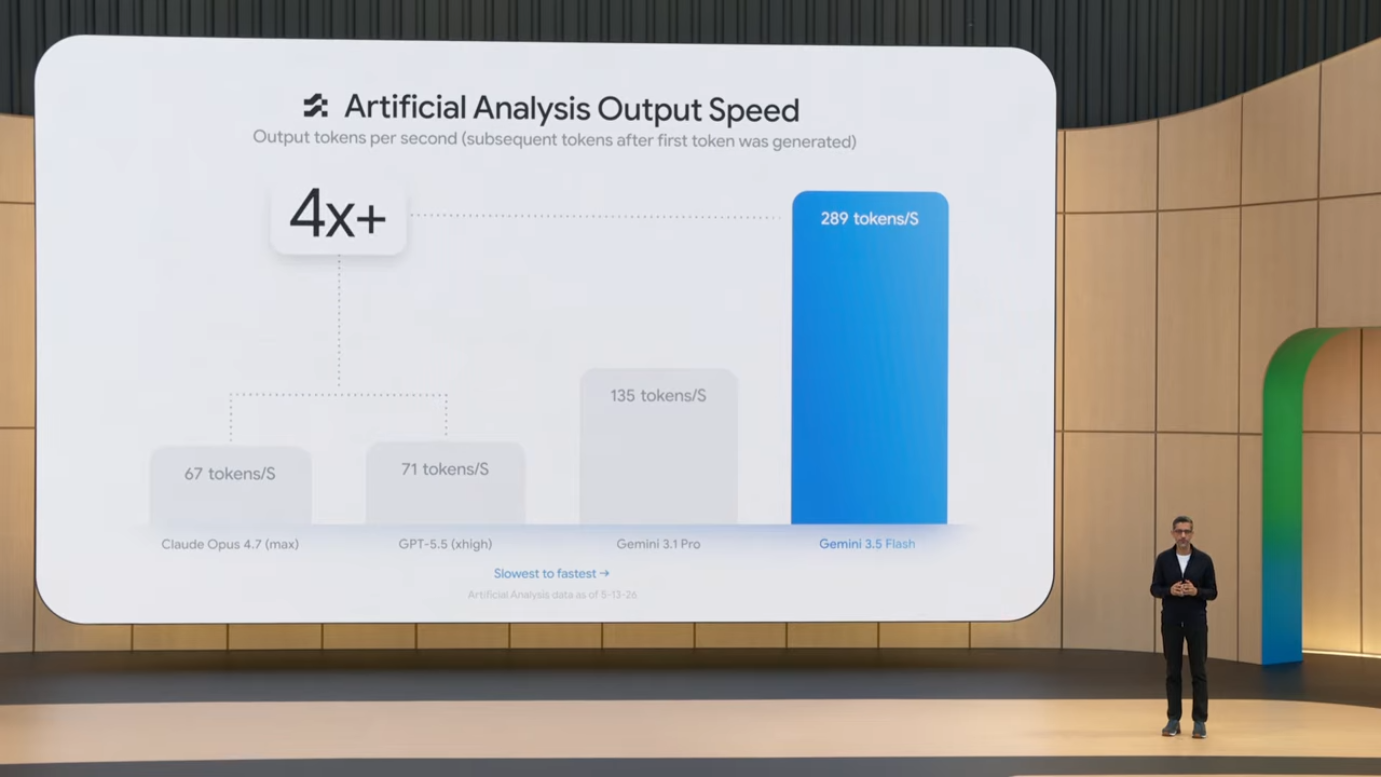
4배 속도 차이는 agentic 사용에서 결정적입니다. 에이전트가 100단계의 작업을 수행한다면, 각 단계의 latency가 누적되기 때문에 4배 빠른 모델은 전체 작업 시간을 1/4로 줄입니다. 또한 latency가 낮을수록 사용자가 에이전트의 행동을 검토·중단·수정할 수 있는 interactive feedback이 가능해집니다.
3.4 Google 내부 채택 효과
Google 내부에서는 3.5 Flash 도입 후 개발자 1일 토큰 처리량이 다음과 같이 증가했습니다.
- 3월: 5,000억 토큰/일
- 현재: 3조 토큰/일 (몇 주마다 2배씩 증가)
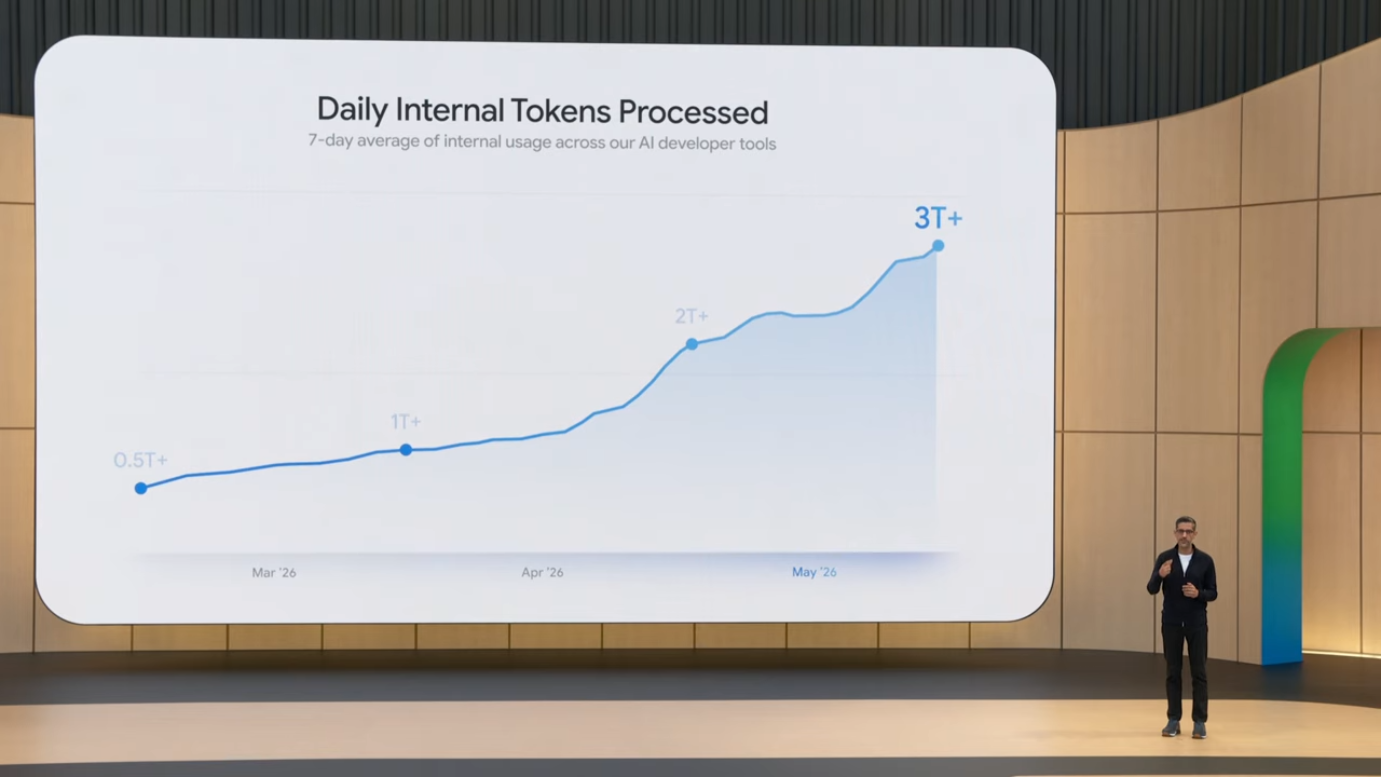
이는 강력한 피드백 루프(feedback loop)를 형성합니다. 내부 사용 → 문제점 발견 → 모델 개선 → 더 많은 내부 사용의 순환 구조입니다. 이 자기 강화 루프(self-reinforcing loop)는 Google의 결정적 경쟁 우위이기도 합니다. 사내에 수만 명의 엔지니어가 매일 모델을 dogfooding하면서 발생시키는 데이터는 외부에서 구할 수 없는 종류의 피드백입니다. 특히 long-horizon agentic task에서 발생하는 failure mode들은 단순 chat 사용에서는 드러나지 않기 때문에, 실제 production 환경에서의 사용량이 모델 개선의 핵심 input이 됩니다.
3.5 Antigravity 2.0: "Unabashedly Agent-First"
Varun Mohan이 발표한 Antigravity 2.0은 단순한 IDE 업데이트가 아니라 완전히 새로운 desktop application입니다. Mohan은 이를 "unabashedly agent-first" (거리낌 없이 에이전트 우선)라고 표현했습니다.
기존 IDE와의 철학적 차이
기존 IDE는 "사람이 코드를 작성하고, AI가 도와주는" 구조였습니다.

Antigravity 2.0은 반대입니다. "에이전트가 작업을 수행하고, 사람이 검토·승인하는" 구조입니다. 이를 반영해 UI 자체가 agent conversation, agent-produced artifacts, multi-agent orchestration을 중심으로 재설계되었습니다.

이는 단순한 UX 변경이 아니라 개발자 멘탈 모델의 전환을 요구합니다. Cursor나 GitHub Copilot 같은 도구는 여전히 "코드 에디터"가 중심이고 AI는 보조 도구입니다. Antigravity 2.0은 conversation이 중심이고 코드는 산출물이라는 발상의 전환입니다. 이는 추후 노코드/로우코드 흐름과 결합되어 "코딩의 본질이 무엇인가"라는 질문을 다시 불러일으킬 수 있습니다.
새로 추가된 기능
- Full CLI experience: 터미널에서 에이전트와 상호작용
- Antigravity SDK: 외부 도구에서 Antigravity 에이전트 호출 가능
- Native voice support: Gemini audio model 기반
- 통합 표면: Android, Firebase, Google AI Studio
Agent Harness 강화
Agent Harness는 Gemini가 실제 작업을 수행하기 위한 보이지 않는 프레임워크입니다. 다음과 같은 새로운 primitive들이 추가되었습니다.
- Subagents: 메인 에이전트가 작업을 분할해 병렬 에이전트들에 위임
- Hooks: 에이전트 라이프사이클의 특정 시점에 사용자 정의 로직 삽입
- Asynchronous task management: 비동기로 장기 실행 작업 관리
Subagent 패턴은 distributed systems의 actor model이나 마이크로서비스 아키텍처와 유사합니다. 메인 에이전트(orchestrator)가 작업을 task로 분해하고, 각 task를 specialized subagent에 위임하면, subagent들이 병렬로 실행되어 결과를 다시 메인 에이전트에 보고합니다. 이는 단일 에이전트가 모든 컨텍스트를 짊어지는 것보다 컨텍스트 윈도우 효율성이 훨씬 좋으며, 각 subagent가 자신의 영역에 특화될 수 있다는 장점이 있습니다. Hooks는 lifecycle event(예: tool call 직전, error 발생 시)에 개입할 수 있게 해주는 메커니즘으로, 안전성과 사용자 통제력을 높이는 데 핵심적입니다.
3.6 OS from Scratch: 12시간 데모
가장 인상적이었던 데모는 Antigravity가 12시간 만에 처음부터 운영체제를 빌드한 사례입니다. 이는 단순한 앱이 아니라 "다른 앱들이 그 위에서 실행될 수 있는 진짜 OS"였습니다.

데모 통계
- 작업 시간: 12시간 (전통적으로 수개월이 걸리는 작업)
- 동시 작동 subagent: 93개
- 모델 호출 수: 15,000건 이상
- 처리 토큰: 26억 토큰
- 자동 생성 컴포넌트: scheduler, memory management, file system
- 테스트: 에이전트가 직접 생성, 실행, 반복 검증
- 총 비용: API 크레딧 $1,000 미만

중요한 비교 포인트
이 작업은 Gemini 3.1 Pro에서는 불가능했습니다. 3.5 Flash의 성능/비용 효율성 덕분에 비로소 경제적으로 실행 가능한 수준이 되었다는 것이 핵심입니다.
이 데모의 의미는 단지 "OS를 만들었다"가 아니라, agentic AI의 경제학이 임계점을 넘었다는 것입니다. 만약 같은 작업이 GPT-4 Turbo로 가능했다고 가정하면 비용은 수만 달러에 달했을 것이고, 그러면 사실상 경제적으로 의미가 없습니다. $1,000 미만의 비용으로 multi-month engineering effort가 가능하다는 것은, 인간 엔지니어 1인의 일주일 인건비보다 적은 비용으로 OS급 결과물을 만들 수 있다는 의미이며, 이는 소프트웨어 개발 economics의 근본적 변화를 시사합니다.
라이브 검증
데모에서는 실제 그 OS 위에서 다음을 시연했습니다.
- 터미널에서
sl명령어 실행 → SL 기차 ASCII 애니메이션 출력
-
Doom 게임 실행 → 처음엔 비디오/키보드 드라이버 누락으로 실패
2.1. Antigravity에 자연어로 "드라이버를 추가해서 Doom을 실행하게 해줘" 요청
2.2. 100줄 이상의 코드를 자동 작성, 빌드, 통합
-
무대 위에서 Doom 실행 성공
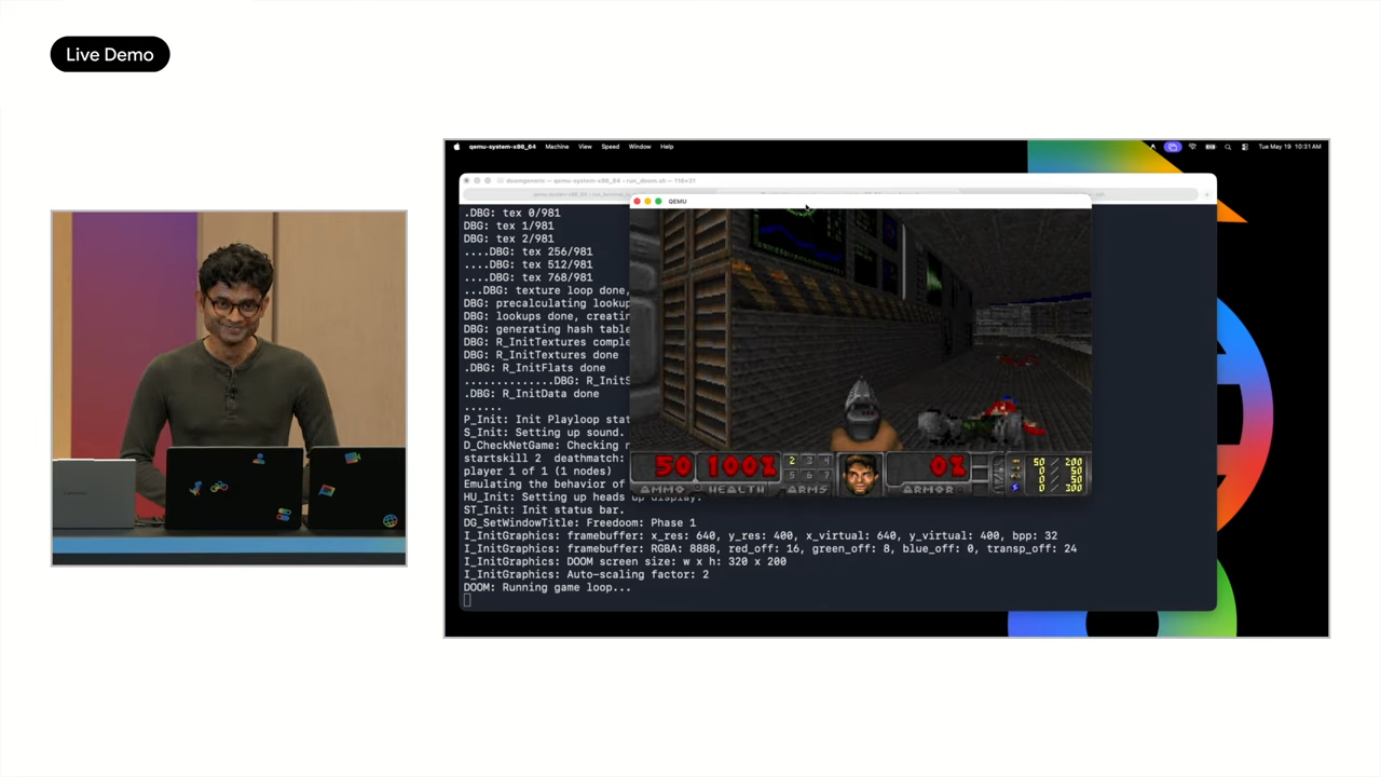
또한 같은 방식으로 photo editing suite, 실시간 메시징 앱, 멀티유저 협업 플랫폼도 빌드 완료했다고 밝혔습니다.
3.7 비용 효율 분석
Sundar는 흥미로운 경제적 비교를 제시했습니다. Google Cloud 상위 기업들은 하루 약 1조 토큰을 처리하는데, 이 중 80%를 다른 frontier 모델에서 Gemini 3.5 Flash로 전환할 경우 연간 $10억 이상의 비용 절감이 가능하다는 분석입니다. 이는 단순한 마케팅이 아니라 실제 enterprise 의사결정에 영향을 미칠 수 있는 수치입니다.
이러한 비용 효율은 단순히 가격 인하가 아니라 모델의 capability-per-dollar가 본질적으로 개선되었기 때문입니다. 같은 작업을 더 작은 모델로 같은 품질로 수행할 수 있게 되면서, 가격 책정도 자연스럽게 낮아진 것입니다. 이는 enterprise AI 채택에서 "PoC는 됐는데 비용 때문에 production 못 가는" 문제를 해결하는 중요한 동인이 됩니다.
Gemini 3.5 Flash는 발표일에 모든 제품과 API에서 즉시 사용 가능하며, Gemini 3.5 Pro는 다음 달 출시 예정입니다.
4. Gemini Spark: Consumer Agent의 시작
4.1 Gemini Spark의 위치
Gemini Spark는 소비자용 개인 AI 에이전트입니다. 기업용·개발자용 에이전트가 이미 있었지만, "소비자가 안전하고 편리하게 쓸 수 있는 에이전트"를 만드는 것이 핵심 과제였고, Spark가 그 첫 답입니다.

소비자용 에이전트가 어려운 이유는 여러 가지입니다.
-
첫째, 일반 사용자는 prompt engineering이나 tool configuration에 익숙하지 않아 UX가 매우 직관적이어야 합니다.
-
둘째, 일상 데이터(이메일, 캘린더, 사진)는 매우 개인적이어서 신뢰와 보안이 절대적입니다.
-
셋째, 사용자의 의도가 모호하고 시간에 따라 변하기 때문에 충분한 자율성과 사용자 통제의 균형이 어렵습니다.

User (laptop closed)
↓ task assignment
[Gemini Spark on Google Cloud VM (24/7)]
├─ Model: Gemini 3.5
├─ Framework: Google Antigravity Harness
├─ Tool Access: Google ecosystem + 3rd party (via MCP)
└─ Surfaces: Gemini app, Email, Chat (확장 예정: Chrome, Android Halo)핵심은 사용자가 노트북을 닫아도 클라우드 VM 위에서 에이전트가 계속 작동한다는 점입니다. Pichai의 표현대로 "yes, you can close your laptop"입니다. 이는 기술적으로 단순해 보이지만 사용자 멘탈 모델의 큰 전환입니다.
기존 AI 도구는 "내가 보고 있을 때만 작동"하는 동기적 도구였습니다. Spark는 persistent하게 살아있으면서 background에서 일하는 디지털 동료의 첫 형태입니다. 이는 LLM이 stateless API call에서 stateful agent로 진화하고 있음을 보여줍니다.
4.2 데모 시나리오 1: 업무 이메일 작성
Josh Woodward는 본인 업무 시나리오를 데모로 사용했습니다.
"Draft an email to the gemini-io-26@google.com. Compile everything about the Gemini live launches and wins from the last week. Use /ghostwriter."
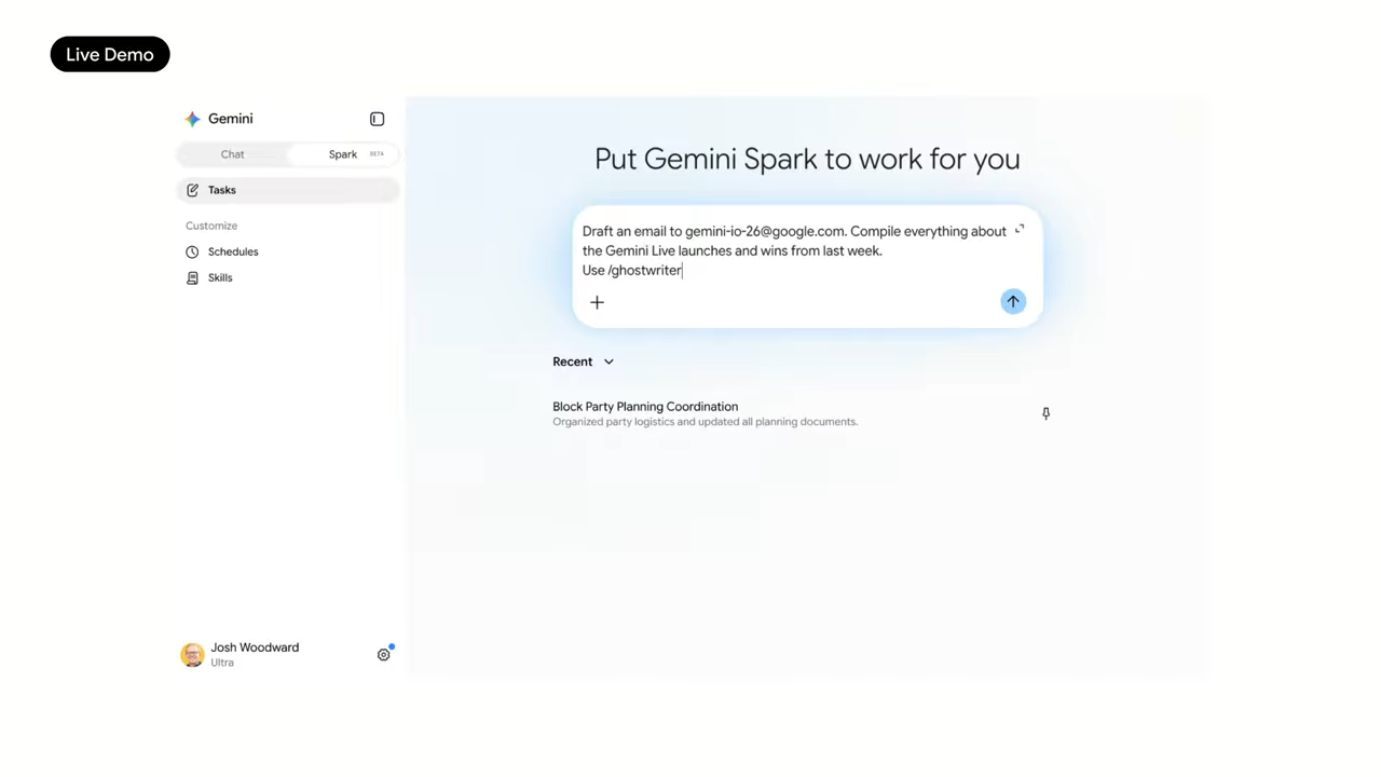
이 한 줄 프롬프트로 Spark가 수행한 작업:
- Docs, 이메일, 채팅 전반에서 지난 1주일의 관련 정보 수집
- 가장 중요한 업데이트들을 자동 추출
- /ghostwriter 라는 사용자 정의 skill 적용 (Woodward 본인의 글쓰기 스타일 학습된 skill)
- 본인 톤으로 이메일 초안 작성
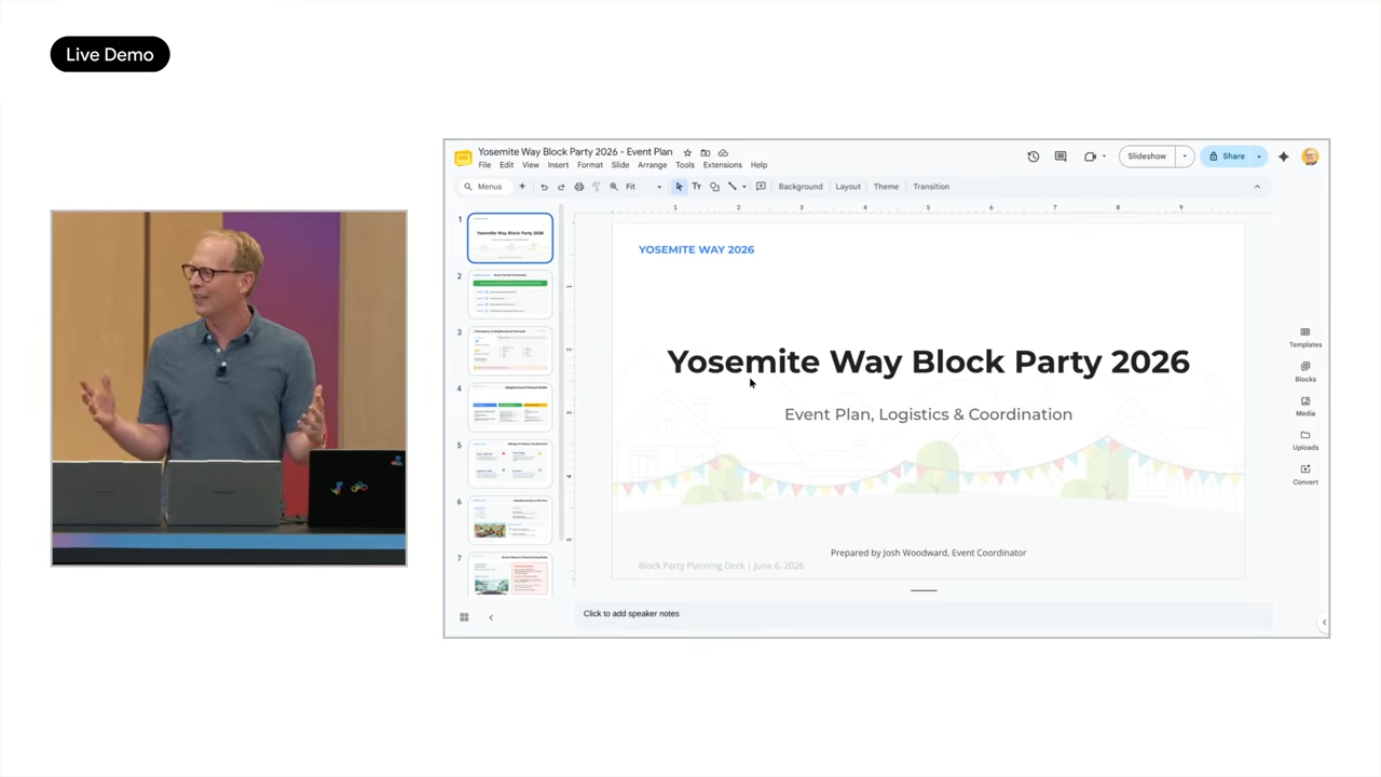
4.3 데모 시나리오 2: Block Party 기획
훨씬 복잡한 시나리오로 이웃 블록 파티 기획을 보여주었습니다. 단일 프롬프트로 다음을 자동 수행했습니다.
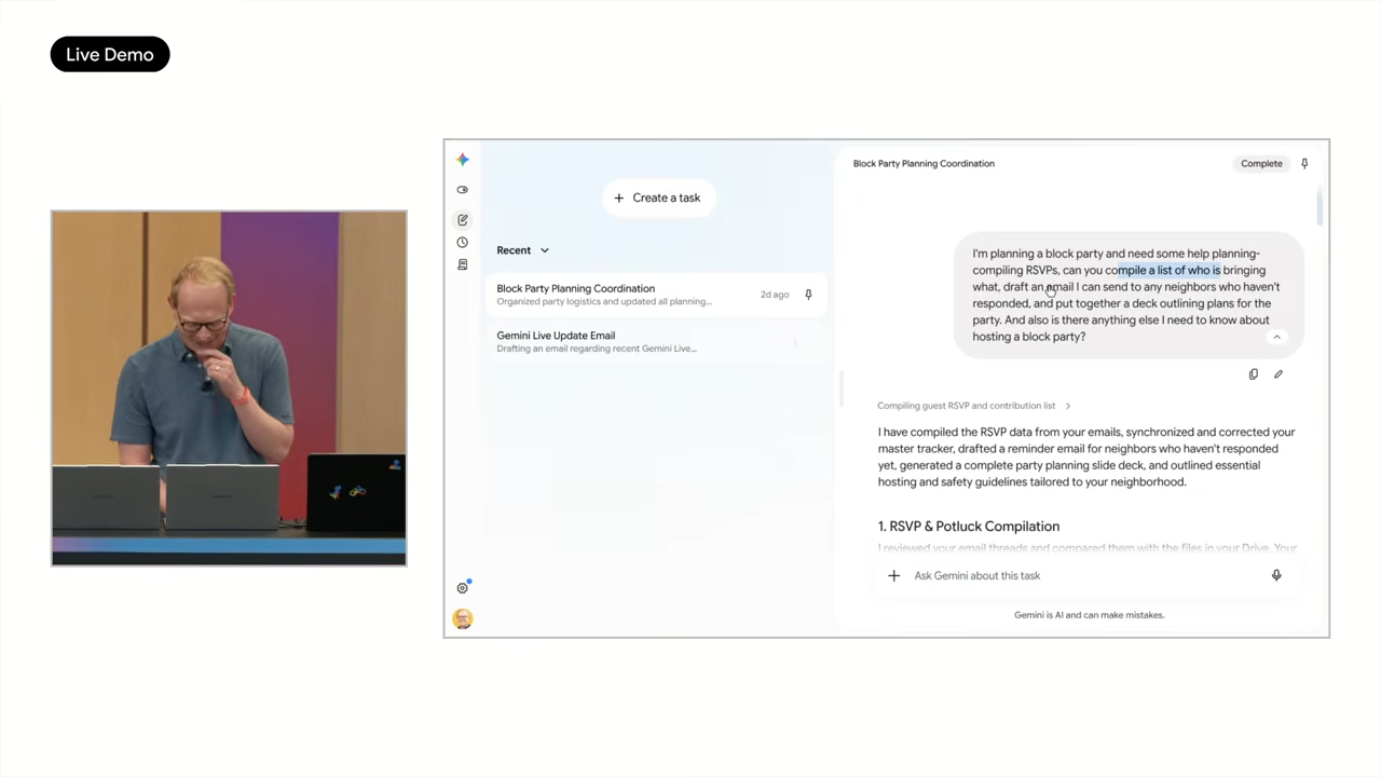
- RSVP 추적: Gmail에서 응답들을 모니터링
- Live RSVP tracker: Google Sheets에 자동 생성, Gmail과 연동되어 새 RSVP가 오면 자동 업데이트
- 누가 무엇을 가져오는지 추적: 데이터 컬럼별 자동 정리
- Follow-up 이메일 초안: 미응답자 대상 (사용자 승인 후 발송)
- Hype deck: Google Slides로 자동 생성, "큰 바운스 하우스가 cul-de-sac에 있을 것" 같은 디테일까지 포함
- HOA 제약 검색: Google Drive 내 파일에서 "토요일 오후 6월 5일 이전엔 설치 불가" 같은 규정 자동 발견
4.4 데모 시나리오 3: 음성 멀티태스킹
휴대폰에서 Gemini App에서 음성으로 3개의 작업을 한 번에 던지는 시나리오를 시연했습니다.
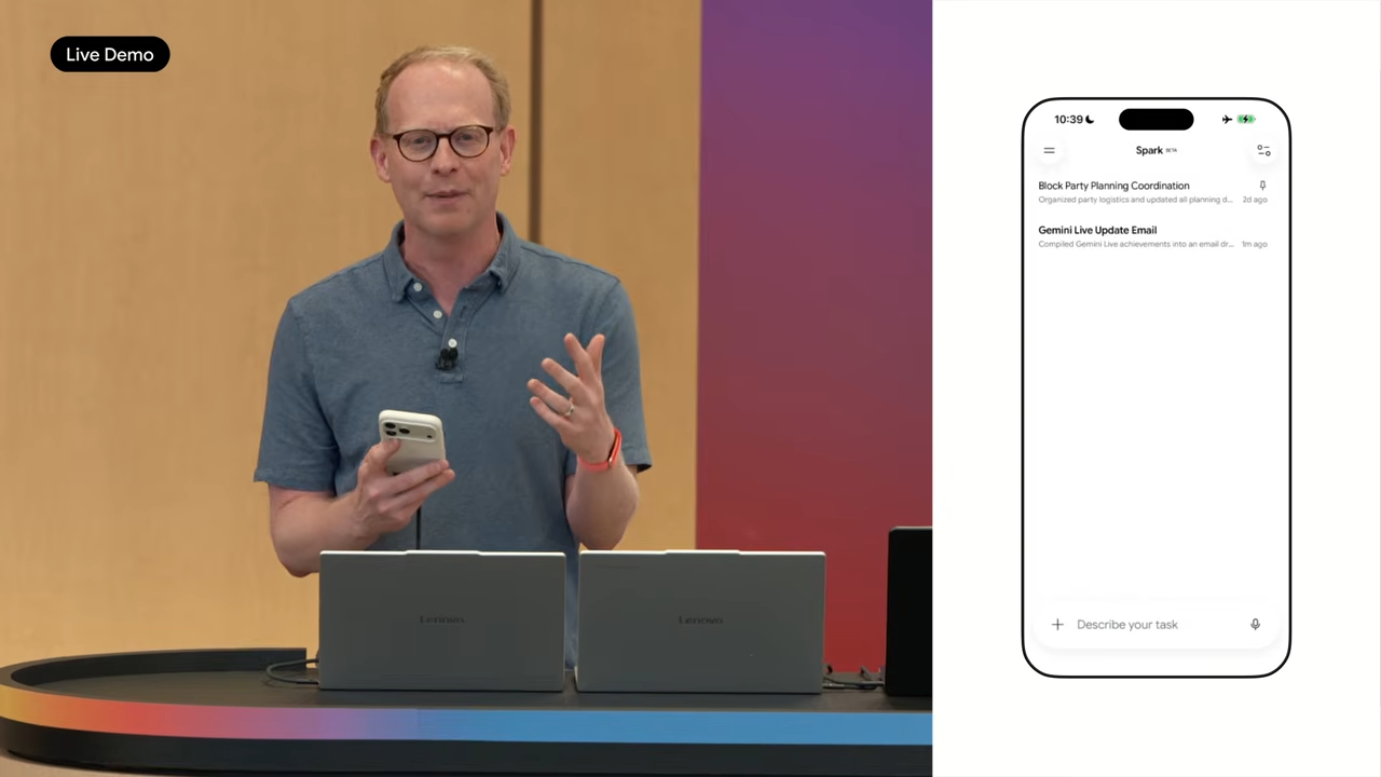
- "Sundar와의 모든 예정 미팅을 hot pink로 표시해줘 (놓치지 않도록)"
- "어젯밤에 만난 새 이웃 John의 가족에게 환영 메모를 보내고 블록 파티에 초대해줘"
- "아내와 함께 학기 끝나기 전에 아이들 일정을 정리한 문서를 만들어줘 (마감일과 우선순위로 카테고리 분류)"
Spark는 이 음성 입력을 단일 thread로 받아 백그라운드에서 3개의 독립 task로 분해해 병렬 처리했습니다.
4.5 출시 정보 및 가격 변경
출시 일정
- 이번 주: 신뢰할 수 있는 테스터 대상 배포
- 다음 주: 미국 Google AI Ultra 구독자 대상 베타

가격 변경
- 신규 Ultra 플랜: $100/월 (새로 추가)

- 기존 최상위 Ultra: $250/월 → $200/월로 인하

추후 로드맵
- Chrome 내 agentic browser로 확장 (올여름)
-
Android Halo: 전용 에이전트 홈베이스 (올해 후반)
-
MCP를 통한 3rd party 도구 연동
-
Gemini Workspace 및 Gemini Enterprise 버전
5. Search의 재발명
5.1 핵심 메시지

Liz Reid가 이끄는 Search 세션은 이번 키노트에서 가장 긴 비중을 차지했으며, "AI Search"라는 새로운 패러다임을 제시했습니다.
"We're entering the next chapter of Google Search, where incredible AI features aren't just in Search; Google Search is AI Search through and through."
이는 "검색 안에 AI 기능이 있다"가 아니라 "검색 자체가 AI다"라는 선언적 전환입니다. Search는 Google의 가장 핵심적인 수익원이자 정체성이기 때문에, 이 전환은 단순한 기능 추가가 아니라 회사 자체의 재정의에 가깝습니다. Perplexity, ChatGPT Search 같은 신흥 도전자들이 등장한 상황에서 Google이 자신의 강점(웹 인덱스, 광고 시스템, 신뢰성)을 AI 시대에 어떻게 재해석할 것인지에 대한 답입니다.
5.2 AI Mode의 성장
- 출시 1년 만에 월 10억 사용자 돌파
- 분기당 쿼리가 2배씩 성장 (출시 이후 매 분기 지속)
- 지난 분기 전체 Search 쿼리가 역대 최고치 기록
- 오늘부로 Gemini 3.5로 업그레이드

사용자 쿼리 패턴도 변화했습니다. "근처 하이킹" 같은 짧은 키워드가 아니라 "근처에 강아지 동반 가능한 멋진 전망의 하이킹 데이트립 일정을 짜줘. 주차 편한 점심 장소 포함해서" 같은 자연어 쿼리가 일상화되었습니다. 이는 인간이 검색 엔진의 한계에 맞춰 자신의 의도를 단순화하던 시대가 끝나가고 있다는 것을 의미합니다. 25년간 Google 사용자는 "검색 친화적인 키워드"로 자신의 질문을 번역하는 법을 배웠는데, 이제 그 부담이 사라지고 있습니다.
5.3 새로운 Intelligent Search Box
25년 만의 가장 큰 검색창 업데이트입니다. 주요 특징은 다음과 같습니다.
- 호기심에 따라 확장: 입력하는 동안 박스가 동적으로 커짐
- AI-powered suggestions: 단순 autocomplete가 아니라 사용자가 미처 생각하지 못한 nuance를 제안
- 멀티모달 입력: 텍스트, 이미지, 파일, 비디오를 동시에 입력 가능하며, Search가 이들 간의 추론까지 수행
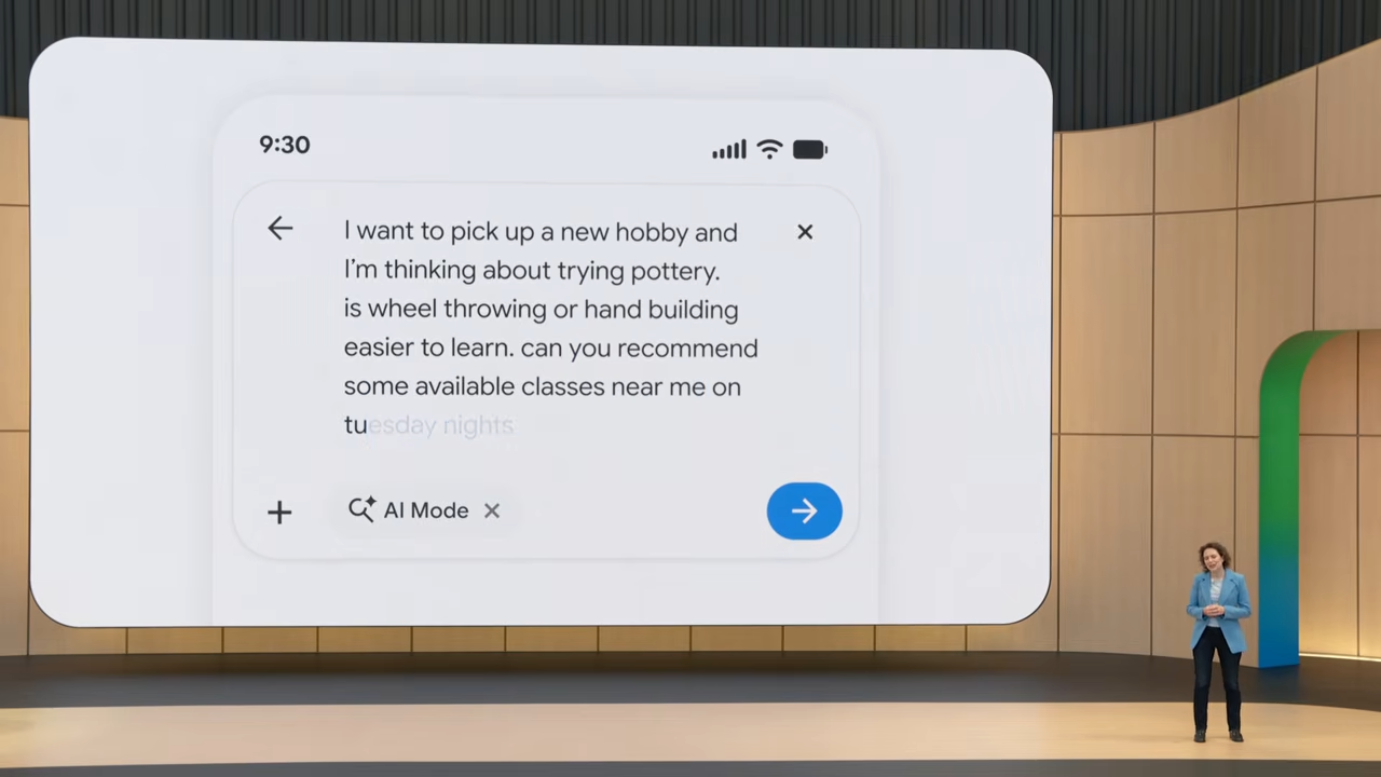
"미처 생각하지 못한 nuance를 제안"한다는 표현은 검색의 본질적 변화를 시사합니다. 기존 autocomplete는 "다른 사람들이 자주 쓴 검색어"를 보여줬다면, 새로운 시스템은 사용자의 의도를 분석해 더 좋은 질문 자체를 제안합니다. 이는 검색이 더 이상 "내가 알고 있는 것을 찾는 도구"가 아니라 "내가 무엇을 모르는지 발견하는 도구"로 진화한다는 의미입니다.
5.4 AI Overviews와 AI Mode의 통합
기존에는 분리되어 있던 두 기능이 하나의 seamless한 흐름으로 통합되었습니다.
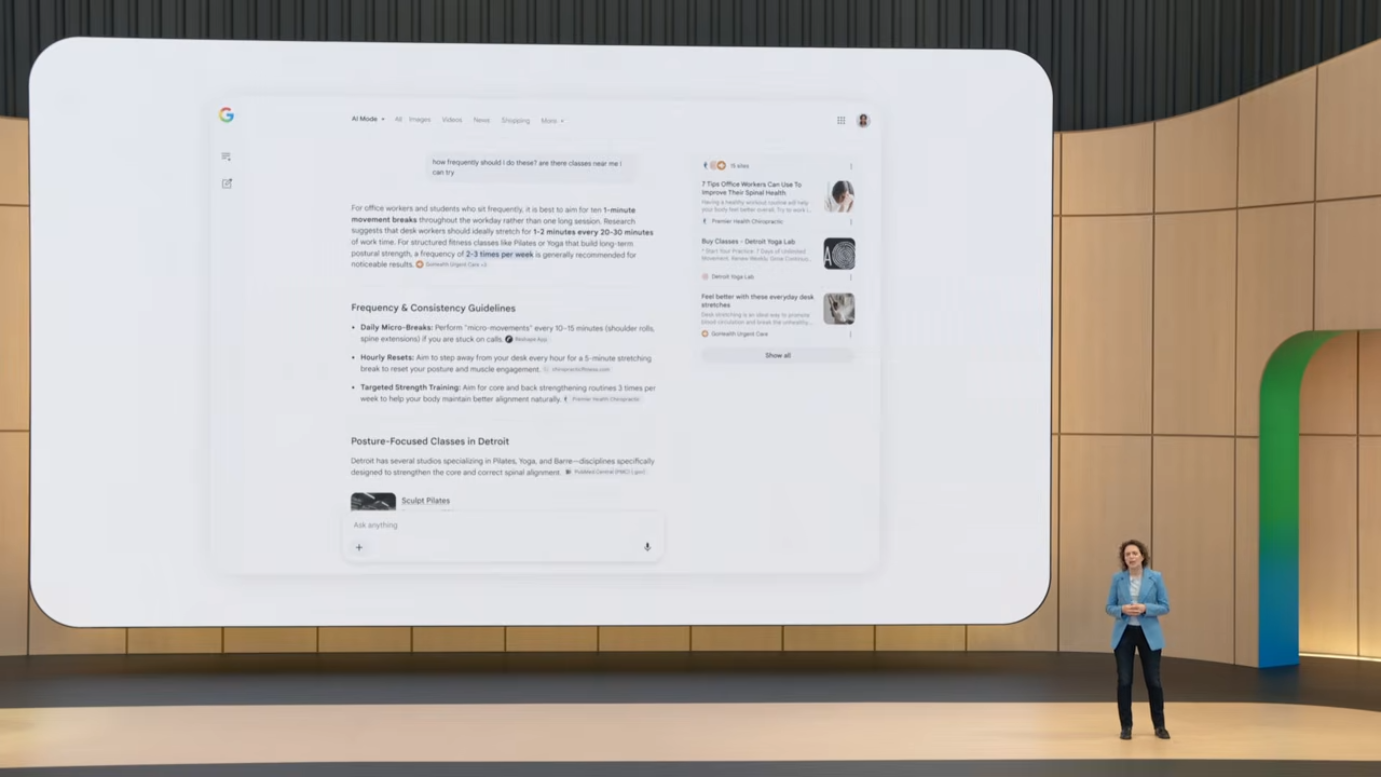
- 메인 검색 결과 페이지의 질문과 응답에서, AI Mode의 후속 질문으로 자연스럽게 이동
- 컨텍스트가 유지되어 대화가 계속 깊어짐
- 링크와 출처도 사용자의 탐색 흐름에 맞게 더 관련성 높게 표시
- 데스크톱과 모바일에서 오늘부터 전 세계 출시
이전까지 AI Overviews(요약)와 AI Mode(대화형)는 사용자가 의식적으로 모드를 전환해야 하는 분리된 경험이었습니다. 통합 이후에는 단일 query에서 시작해 자연스럽게 conversation으로 deepening되는 단방향 흐름이 됩니다. 이는 사용자 인지 부담을 크게 줄이고, "검색"과 "대화" 사이의 경계를 흐립니다.
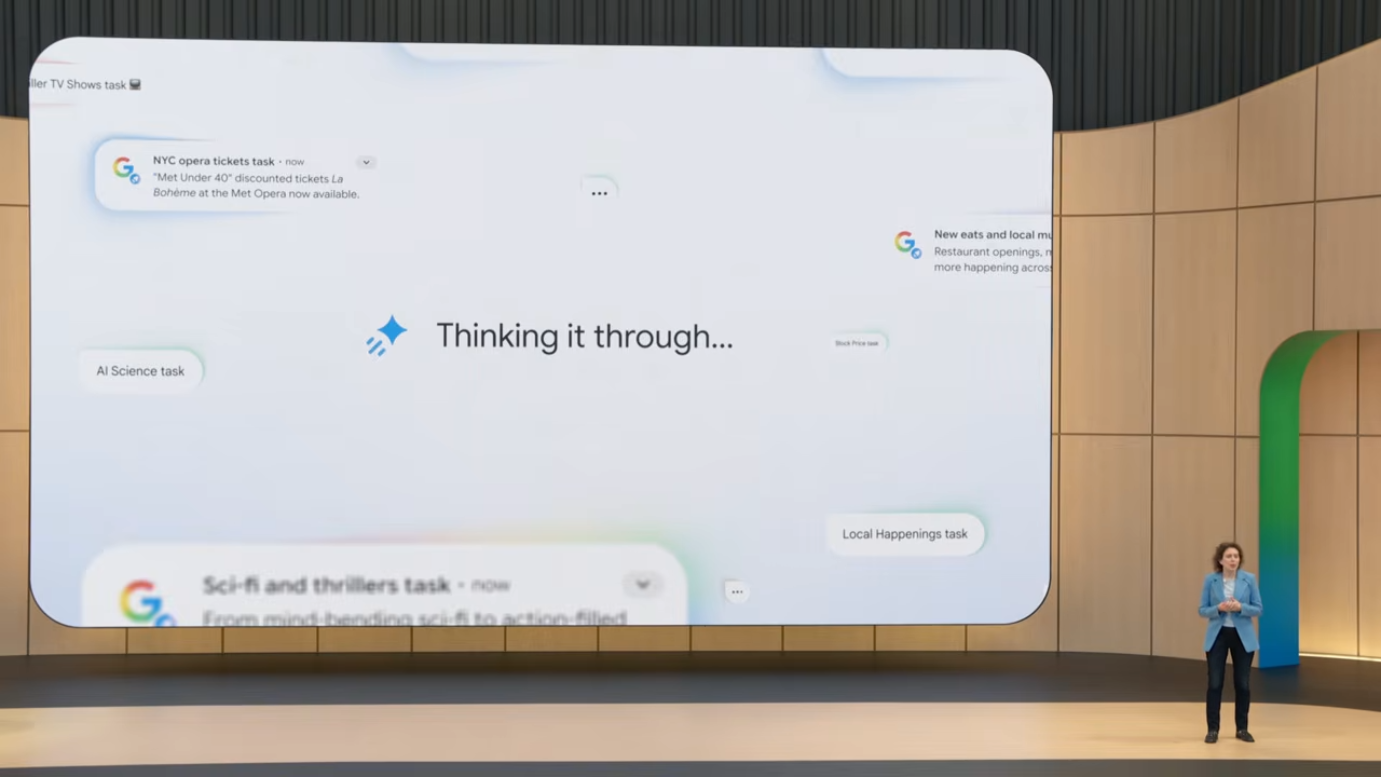
5.5 Search Agents: 정보 에이전트
Search에 정보 에이전트(Information Agents)가 도입되었습니다. 사용자는 검색에서 직접 24/7 작동하는 에이전트를 여러 개 동시에 생성할 수 있습니다.
이들은 Gemini Spark와 함께 작동합니다.
작동 방식
- 복잡한 쿼리 수신
- 계획 수립: 작업을 단계로 분해
- 긴급도 판단: 실시간 정보가 필요한지 결정
- 트리거 설정: 변화 감지 조건 설정
- 도구/데이터 선택: 적절한 데이터 소스 연결
- 합성된 업데이트 전송: 신호와 노이즈 분리
데모 시나리오
- 금융: "P/E 15 미만, positive cash flow, 부채 적은 빅 바이오텍 주식" 모니터링 → Google의 실시간 금융 데이터 연동, 가격 변동 시 즉시 알림, crowdsourced 리서치 플랫폼과 뉴스 사이트로 연결
- 아파트 헌팅: 위치, 자연광, 가용성 등의 기준을 brain-dump → 웹사이트, 소셜, 포럼 전반을 지속 스캔
- 스니커즈 드롭: 좋아하는 운동선수의 콜라보 발표 시 자동 알림 (블로그부터 Shopping Graph까지)
이는 검색의 시간 차원 확장입니다. 기존 검색은 "지금 이 순간의 질문 → 즉시 답변"이라는 point-in-time 인터랙션이었습니다. Information Agent는 "지속적인 관심사 → 시간을 두고 누적되는 답변"이라는 longitudinal 인터랙션을 도입합니다. 이는 RSS, Google Alerts 같은 기존 도구의 발상을 LLM 기반 의미 이해와 결합한 것입니다.

여름 출시 예정이며, 무료로 누구나 사용 가능합니다.
5.6 Generative UI with Antigravity
가장 흥미로운 발표 중 하나는 검색 결과 자체가 코드로 실시간 생성된다는 점입니다.

Robby Stein이 발표한 이 기능은 다음과 같이 작동합니다.
User Query
→ Gemini 3.5 Flash plans response from scratch
→ Designs layout & decides custom components
→ Fans out to research
→ Invokes Antigravity coding harness
→ Reads/writes files, executes code in secure container
→ Deploys custom UI on-the-fly천체물리 데모
"블랙홀이 시공간에 어떻게 영향을 미치는가?"를 물으면,
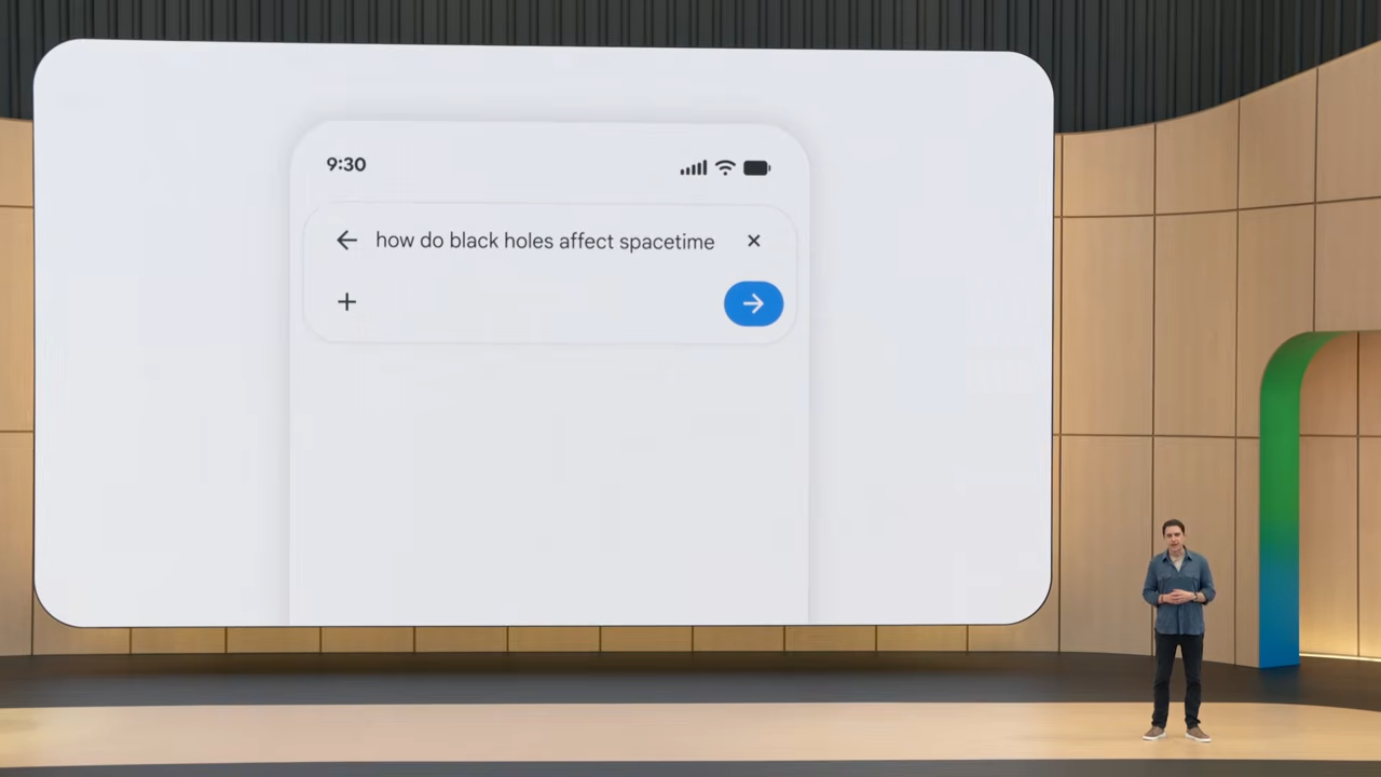
AI Overview 안에 인터랙티브 시각화가 직접 빌드됩니다.
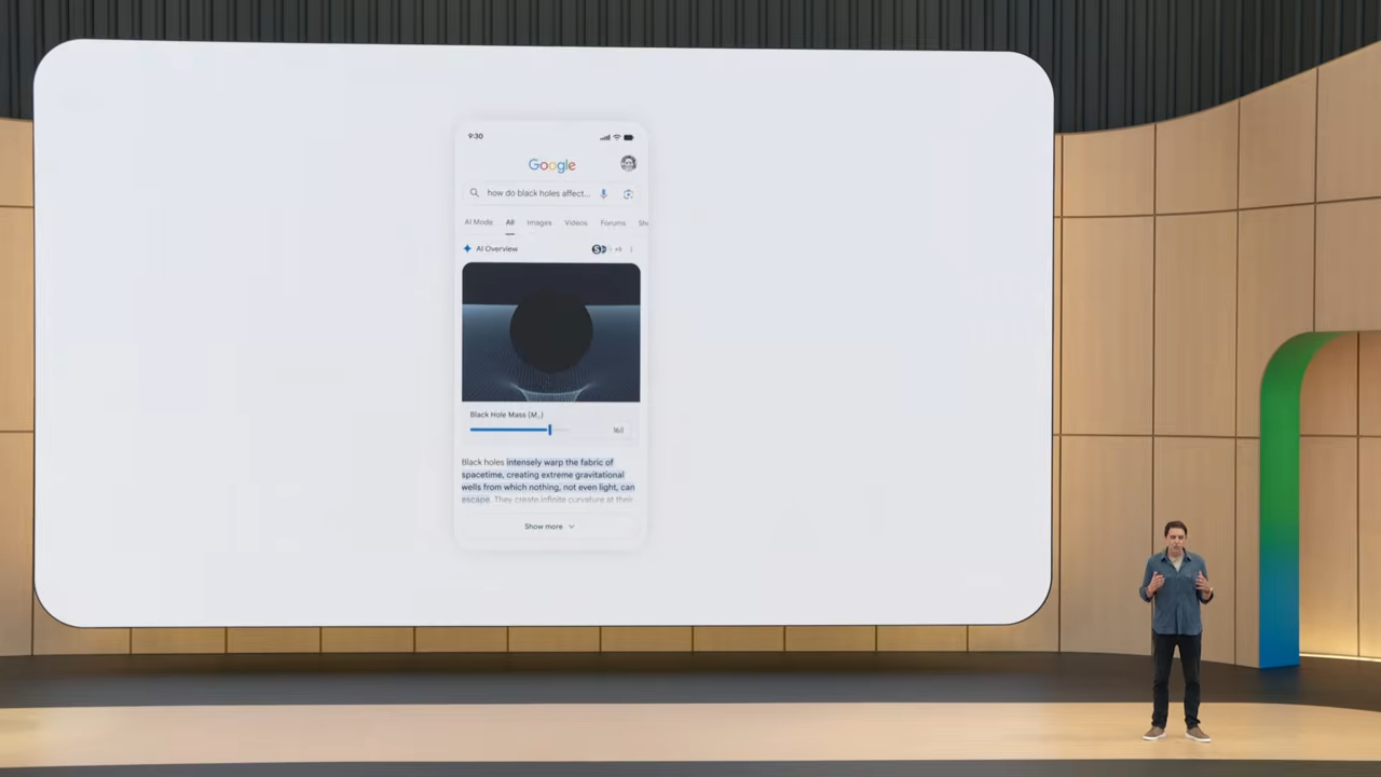
후속 질문 "두 개의 궤도 운동하는 객체(예: 쌍성 블랙홀)가 어떻게 중력파를 만드는가?"를 던지면,
Search가 궤도 분리(orbital separation), 질량비(mass ratio) 같은 파라미터를 조작할 수 있는 새로운 인터랙티브 위젯을 실시간 생성합니다.
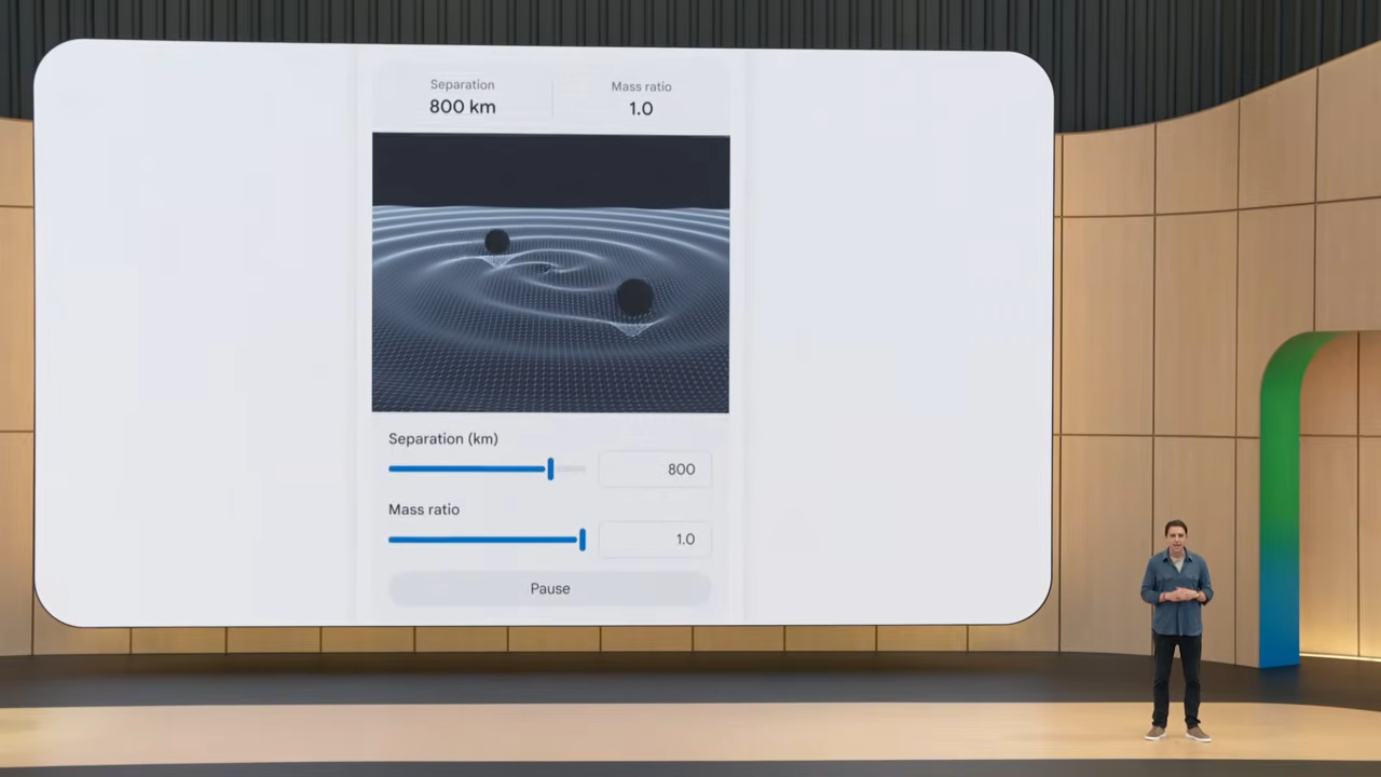
학습 후에는 LIGO Discovery Papers 같은 참고 자료로 자연스럽게 이어집니다.

Generative UI의 의미는 깊습니다. 25년간 검색 결과는 고정된 템플릿(10개의 파란 링크, 이후 carousel, knowledge panel 등)으로 표현되었습니다. 모든 질문이 같은 UI에 끼워 맞춰져야 했습니다. Generative UI는 각 질문에 맞는 최적의 UI 자체를 즉석에서 생성합니다. 천체물리 질문에는 시뮬레이션, 요리 질문에는 인터랙티브 레시피, 금융 질문에는 차트와 계산기가 자동 구성될 수 있다는 의미입니다. 이는 information presentation의 패러다임 전환으로, software development cost가 거의 0에 가까워졌을 때만 가능한 접근법입니다.
5.7 Mini Apps in Search
검색 안에서 stateful한 개인용 도구를 빌드할 수 있는 기능도 도입되었습니다. Stein은 이를 "검색 안의 미니 앱"이라고 표현했습니다.
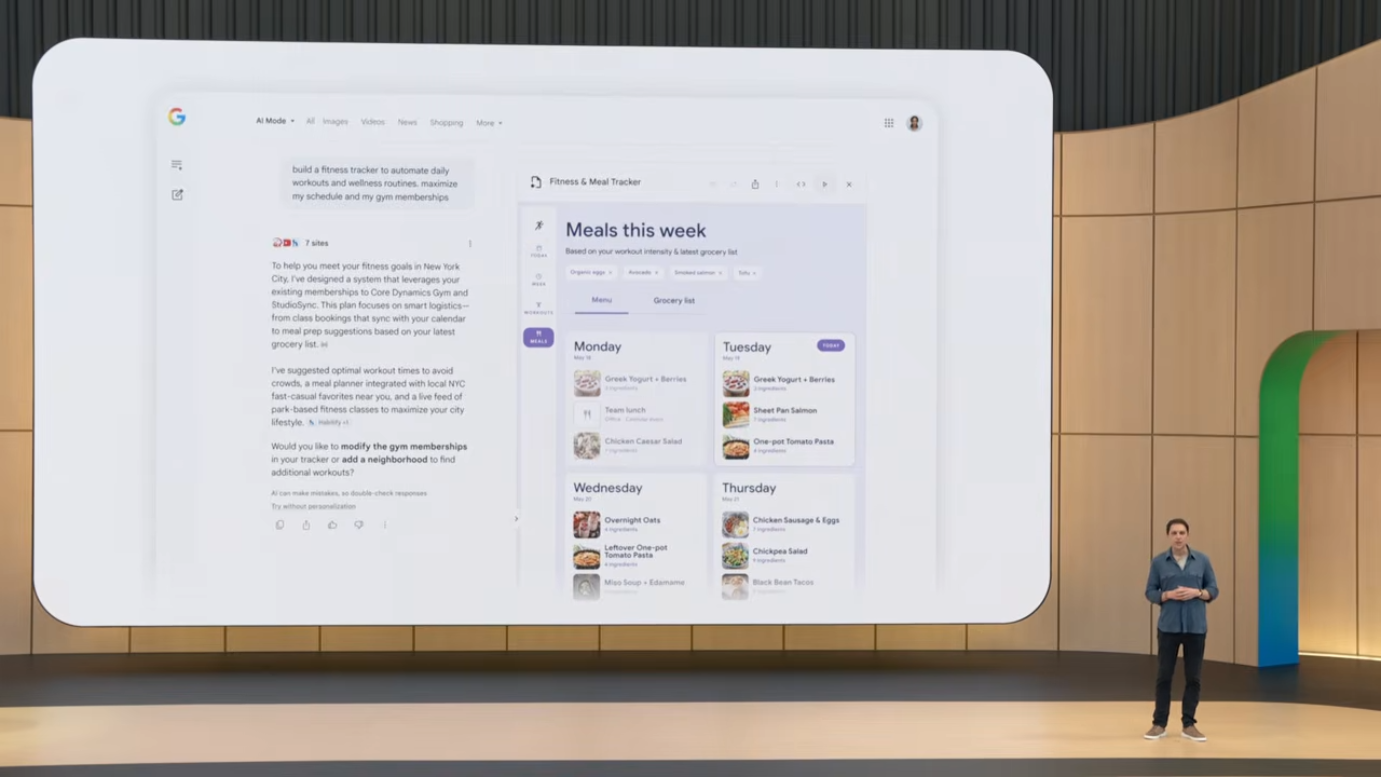
Weekend Planner 데모
- "이번 주말 가족과 함께할 재미있는 것들" 검색
- Search가 proactively "weekend planner를 빌드해드릴까요?" 제안
- Gmail, Photos, Calendar를 보안 연결 후 personalization 적용
- 실시간 코드 생성 (thinking steps와 code generation이 노출됨)
- 운전 시간, 날씨, 아이들 정보(체스 학습 중, 동물 좋아함) 자동 반영
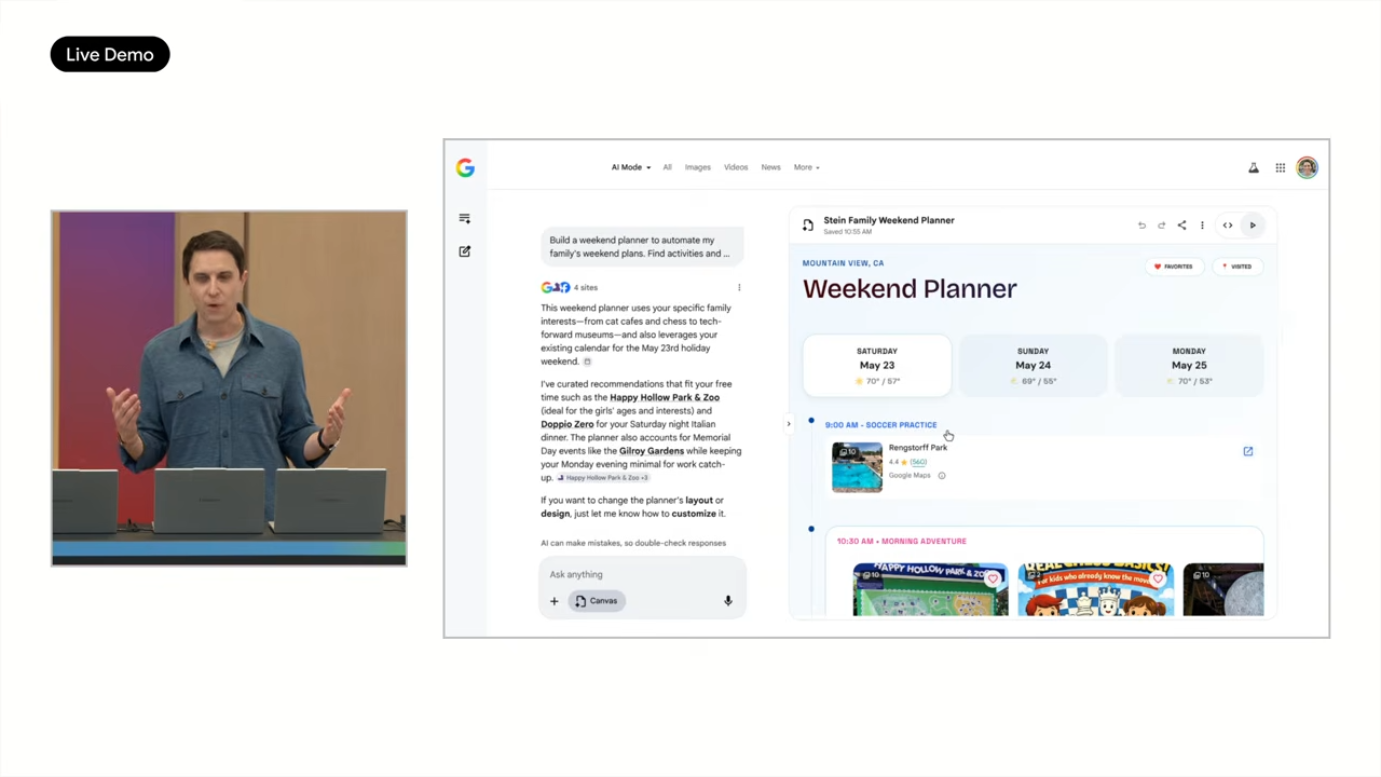
- Happy Hollow Park & Zoo, Friday date night 등 옵션 제공
- Maps에 표시된 레스토랑 예약, 캘린더 자동 블로킹
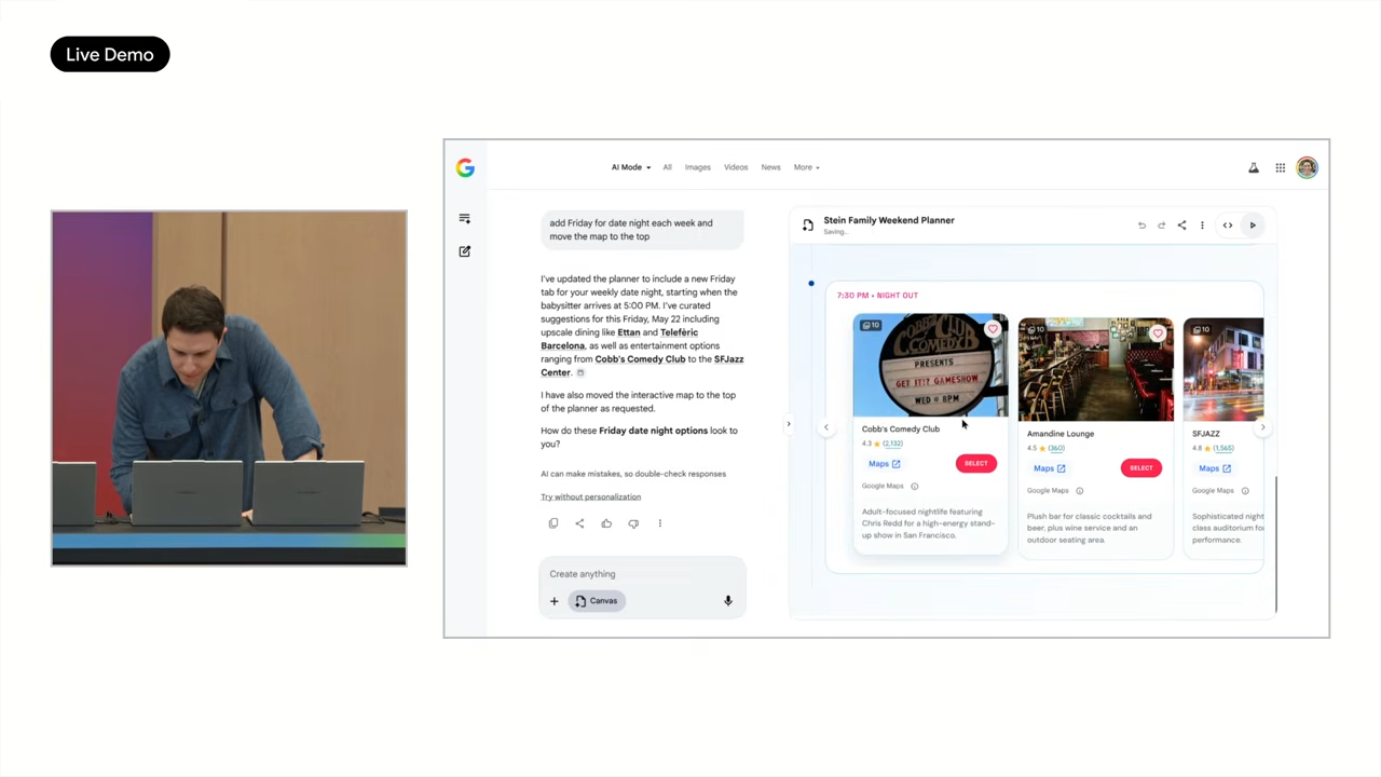
- 아내에게 공유 → 휴대폰에서 동일 앱 확인 가능
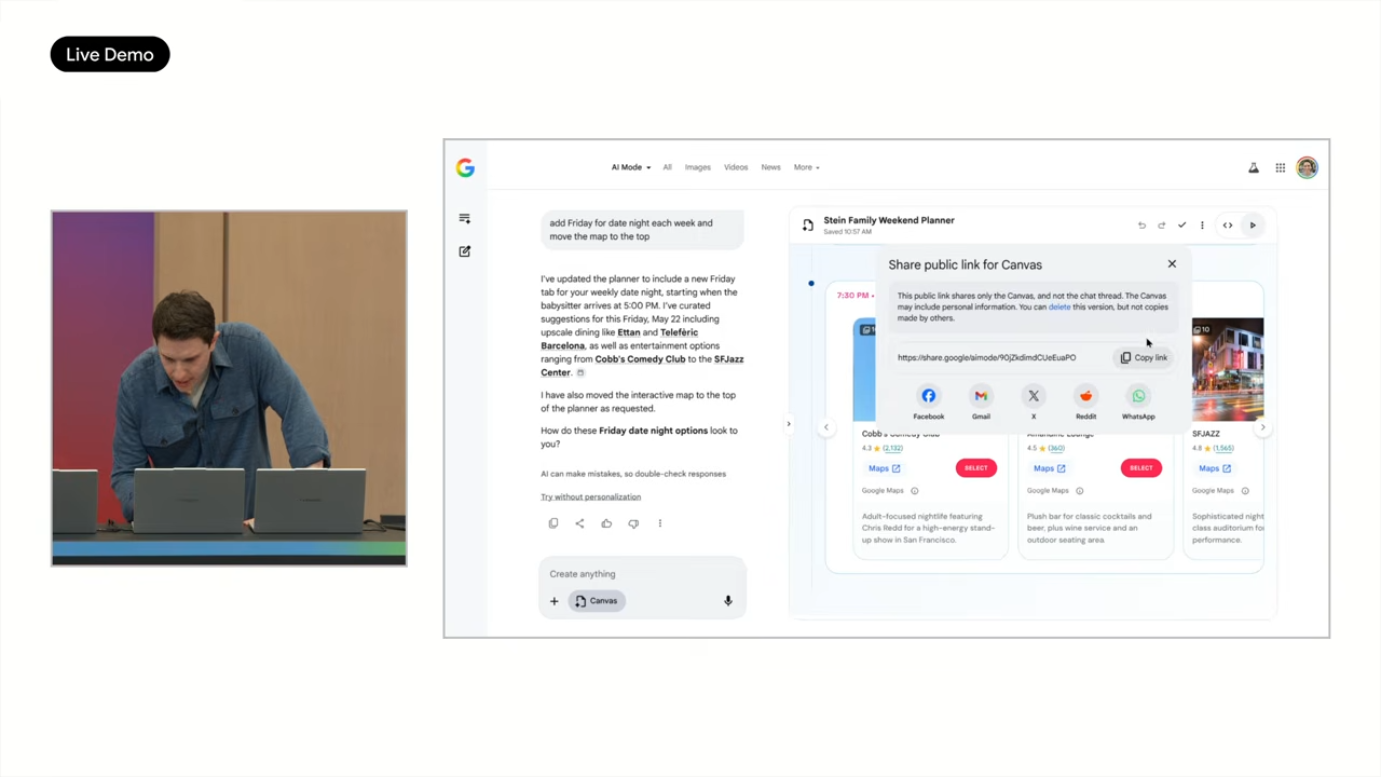
여름에 구독자 대상으로 출시 예정입니다.
Mini Apps는 generative UI의 stateful version이라고 볼 수 있습니다. Generative UI가 "단일 응답을 위한 일회성 위젯"이라면, Mini App은 "장기 프로젝트를 위한 지속적 도구"입니다. 이는 앱스토어 생태계 자체의 의미를 약화시킬 수 있는 잠재력을 가집니다. 사용자가 specific한 도구를 다운로드하는 대신, 자신의 데이터와 컨텍스트에 맞는 도구를 즉석에서 생성할 수 있게 된다면, "general-purpose 앱"의 가치는 줄어듭니다.
🤔 갑자기 드는 생각인데... 이러면 Google AI Studio의 장점이 없어지는 느낌인데...? AI Studio 없어지려나요?
5.8 Agentic Commerce: UCP, AP2, Universal Cart

Vidhya Srinivasan은 agentic commerce를 위한 3가지 빌딩 블록을 소개했습니다.

(1) Universal Commerce Protocol (UCP)

"UCP does for agentic commerce what HTTP did for the web."
오픈소스 표준으로, 에이전트와 시스템이 쇼핑 여정 전체에서 공통 언어로 통신하게 합니다. 제품 리서치부터 결제, 배송 추적까지 매끄럽게 연결됩니다. 창립 파트너에 더해 다음 회사들이 신규 합류했습니다.
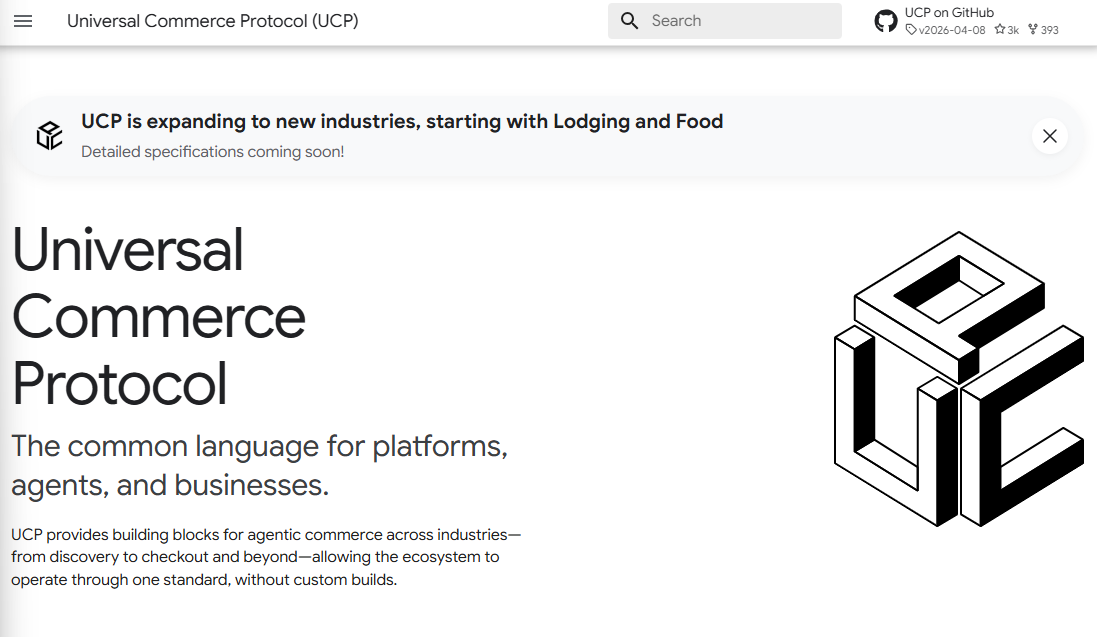
- UCP 파트너사: 다양한 파트너사들과 협업

- 신규 출시 지역: 캐나다, 호주, 영국.

- 확장 영역: 호텔, 로컬 음식 배달, YouTube.
(2) Agent Payments Protocol (AP2)

"How do I know it won't just go off and buy something I don't want?"
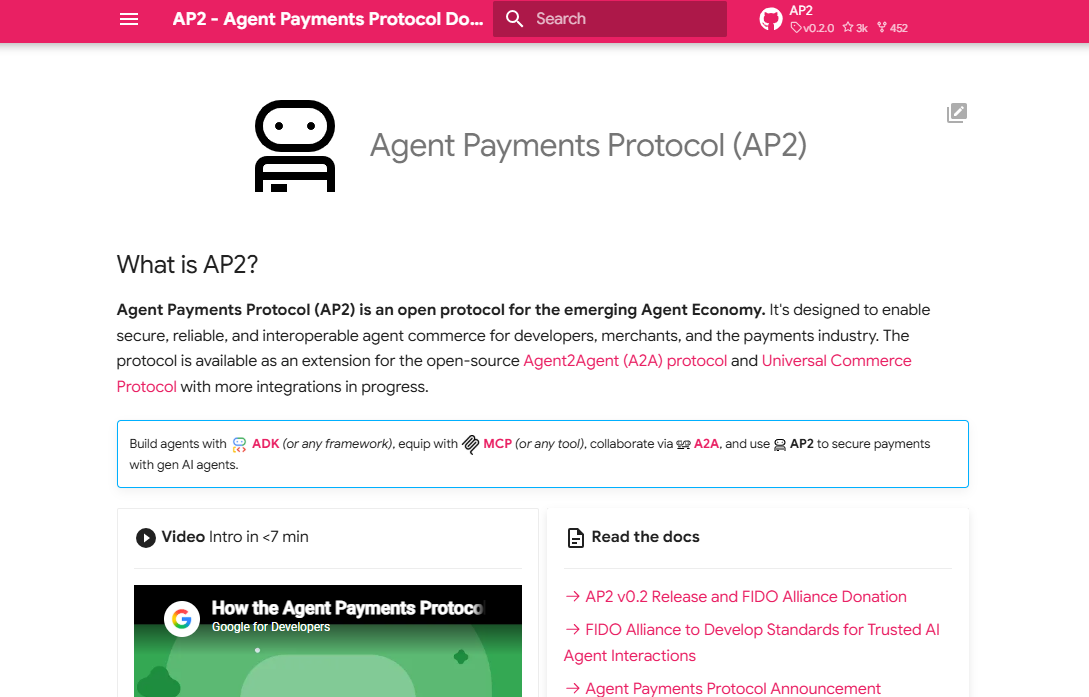
AP2는 두 가지 원칙으로 작동합니다.
- Boundaries(경계): 특정 브랜드, 제품, 예산 한도를 사전 설정. 조건 충족 시에만 자동 구매.

- Accountability(책임): 사용자-판매자-결제처리자 간 검증 가능한 cryptographic 링크 생성. 변조 불가능한 digital mandate로 모든 거래에 영구적 paper trail 제공. (개인 정보는 privacy-preserving technology로 보호.)
반품이 필요할 때 사용자와 판매자가 동일한 기록을 참조할 수 있다는 점이 중요합니다. Gemini Spark에서 먼저 적용 예정입니다.

(3) Universal Cart

기존 장바구니의 단순 합산을 넘어선 지능형 쇼핑 카트입니다.
- 60억 개 이상의 제품을 포함하는 Shopping Graph 기반
- Search, Gemini, YouTube, Gmail 어디서든 장바구니 담기 가능
- 백그라운드 자동 작업: 가격 모니터링, 재고 알림, 가격 히스토리 분석
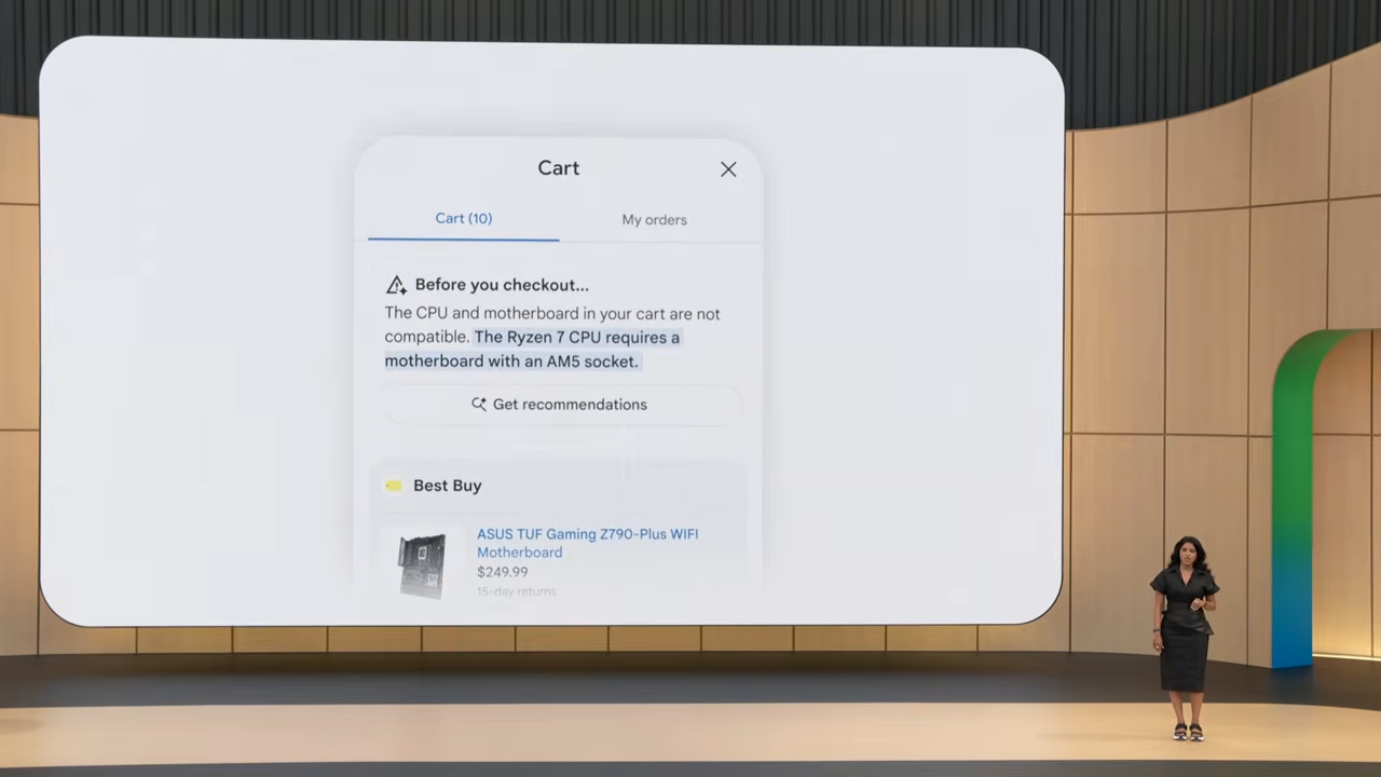
- 호환성 추론: 메인보드 소켓 타입 불일치 같은 문제를 사전 감지하고 대안 제안
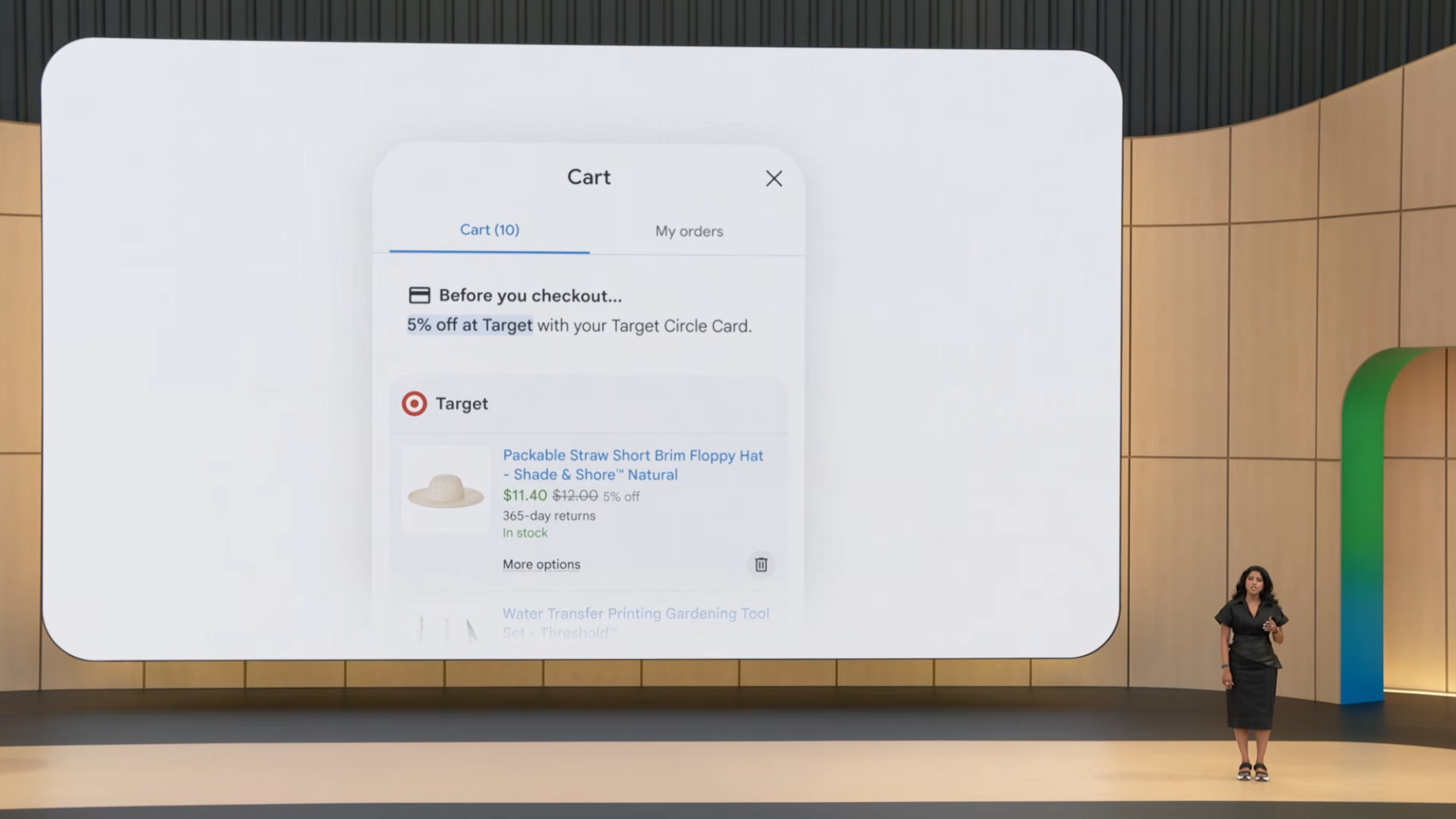
- Google Wallet 통합: 카드별 혜택을 자동 최적화 (예: Target에서 특정 제품 구매 시 카드 혜택 자동 적용)
- UCP를 통한 매끄러운 checkout: Google Pay로 즉시 결제하거나, 리테일러 사이트로 transfer 후 구매
가장 인상적인 데모는 커스텀 PC 빌드 시나리오였습니다. 사용자가 CPU를 먼저 담은 후 "리뷰 좋은" 마더보드를 추가하자, 카트가 두 제품의 소켓 타입이 호환되지 않음을 자동 감지하고 호환 가능한 대안을 제안했습니다. 일반 쇼핑몰이라면 결제 후 조립 단계에서야 발견했을 문제를 결제 전에 사전 차단한 것입니다.
이는 단순한 "함께 자주 사는 제품" 추천(collaborative filtering)이 아니라 제품 사양을 이해하고 추론하는 작업으로, 카메라 바디-렌즈 마운트, 자전거 프레임-그루셋, 가전제품 전압 규격 등 부품들이 함께 작동해야 가치를 만드는 모든 카테고리에 확장 가능합니다. 일반 쇼핑 카트가 "장바구니에 무엇이 있는가"만 추적한다면, Universal Cart는 "그것들이 함께 작동하는가"를 이해합니다.
6. Gemini 앱의 전면 재설계
Josh Woodward는 Gemini 앱의 세 가지 핵심 업데이트를 발표했습니다.

6.1 배경: Gemini 앱의 1년 성장
- 월 사용자: 4억 → 9억 명 (2배 이상)
- 230개국, 70개 이상 언어 지원 → 세계에서 가장 광범위하게 사용 가능한 AI 시스템
- 일일 요청: 7배 이상 증가
- NotebookLM: 누적 15억 개 이상의 notebook, podcast, slide deck 생성

- Personal Intelligence: Gmail·Photos 등 사용자 데이터 연결로 응답 개인화 (글로벌 확장 완료)

9억 명이라는 숫자는 Gemini가 ChatGPT의 주간 사용자(2025년 기준 약 8-9억)와 직접 경쟁하는 위치로 올라왔음을 보여줍니다. 특히 230개국, 70개 언어 지원은 ChatGPT 대비 큰 글로벌 커버리지로, 개발도상국 시장에서의 leadership으로 이어질 수 있는 strategic moat입니다.
6.2 Update 1: Neural Expressive 디자인 언어
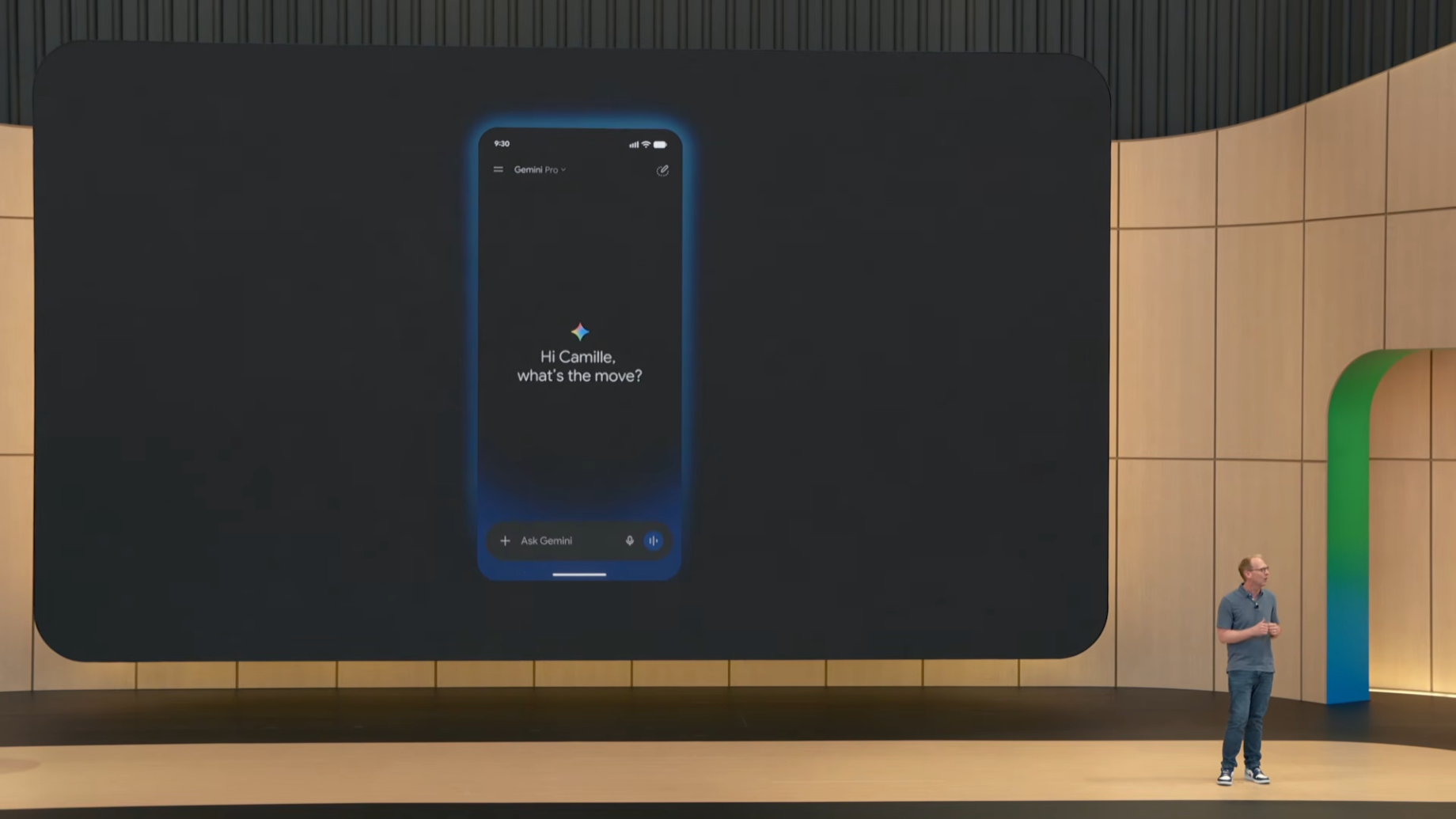
완전히 새로운 디자인 언어 "Neural Expressive"가 도입되었습니다.
디자인 요소
- 유동적 애니메이션(fluid animations)
- 생동감 있는 색감(vibrant colors)
- 새로운 타이포그래피(new typography)
- 햅틱 피드백(haptic feedback) 전반 적용
Gemini Live 개선
- 즉시 인라인으로 열림
- 지역별 dialect 선택 가능 (Liverpool 영어 같은 영어 변종, 다국어 지원)
응답 형식의 변화
기존: "텍스트의 벽(wall of text)"
신규:
- 인터랙티브 이미지: Gemini가 커스텀 생성, 드릴다운 가능
- 타임라인: 빠르게 훑어볼 수 있는 시각화
- 임베디드 비디오: 응답에 직접 포함

다크모드/라이트모드 모두에서 유려한 경험을 제공하며, Android, iOS, Web에서 전 세계 출시되었습니다.
"텍스트의 벽" 비판은 LLM 인터페이스의 본질적 약점을 짚은 것입니다. ChatGPT 출시 이래 대부분의 LLM 인터페이스는 markdown 텍스트의 긴 스크롤이었습니다. 이는 정보 밀도는 높지만 인지 부담이 크고 스킵이 어렵다는 문제가 있었습니다. Neural Expressive는 응답 형식을 콘텐츠 유형에 맞게 변환하는 시도로, 이는 앞서 본 Generative UI와 같은 철학의 연장선입니다.
6.3 Update 2: Gemini Omni in Gemini App
유료 구독자(Plus/Pro/Ultra) 대상으로 Omni가 Gemini 앱에 통합되었습니다.

Woodward는 이를 "Nano Banana for video moment"라고 표현했습니다. Nano Banana가 이미지 편집을 재정의한 것처럼, Omni가 비디오 편집을 재정의한다는 의미입니다.
Sashu의 음악 비디오 데모
음악가 Sashu가 새 곡의 티저 비디오를 만드는 시나리오:
- raw 비디오 업로드
- reference visuals 추가
- 비디오의 스타일 변환 (인물의 걸음걸이, 존재감, 페이싱은 모두 보존)
- 카메라 앵글 변경: 360도 샷으로 전환
- Gemini가 모든 것을 통합
핵심은 물리적 일관성입니다.
Omni는 인물의 움직임의 물리를 이해하고, 효과를 자연스럽게 레이어링하면서 원본 퍼포먼스의 "soul"을 유지합니다.
비디오 편집은 전통적으로 전문가의 영역이었습니다. Premiere Pro, DaVinci Resolve 같은 도구는 수개월의 학습이 필요합니다. Omni는 자연어 명령으로 비디오를 변형할 수 있게 만들어, 이 barrier를 극적으로 낮춥니다. 특히 카메라 앵글 변경은 단순한 필터가 아니라 3D scene understanding을 요구하는 작업으로, World Model 기반 접근의 직접적 응용입니다.
6.4 Update 3: Agents in Gemini
에이전트가 Gemini 앱에 본격 도입되었습니다.

핵심 변화는 다음과 같습니다.
"Agents don't just answer questions; they proactively work on your behalf."
"에이전트는 단순히 질문에 대답하는 것에 그치지 않고, 능동적으로 업무를 처리합니다."
Daily Brief: First Out-of-the-Box Agent
매일 아침을 위한 개인화된 디지털 다이제스트입니다.

- Inbox, Calendar, Tasks를 종합
- 가장 중요한 항목 자동 추출 (예: 반품 마감일 같은 작은 일정도 포함)
- 주제별 정리 및 다음 단계 제안
- 인라인 액션 가능 (예: travel 정보에서 바로 처리)
- "skimming을 위해 설계된" 간결한 형식
미국 내 Google AI Plus, Pro, Ultra 구독자 대상 출시.
Daily Brief는 "agent가 무엇인지" 보여주는 좋은 entry point입니다. 사용자가 매일 아침 자신의 inbox, calendar, tasks를 직접 정리하는 것은 시간이 많이 걸리고 인지 부담이 큽니다. Daily Brief는 이를 선제적으로(proactively) 수행하고, 단순 요약이 아닌 주제별 그룹화와 다음 단계 제안까지 포함합니다. 이는 personal assistant의 역할을 일부 디지털화한 것입니다.
Spark Custom Workflows
Power user는 Spark를 통해 자신만의 워크플로우를 구성할 수 있습니다.

무대 초반에 음성으로 던졌던 3개의 task가 백그라운드에서 어떻게 처리되었는지 확인하는 장면이 시연되었습니다. Google Docs 포맷팅을 활용해 색상 코딩된 체크리스트가 자동 생성된 결과를 보여주었습니다.
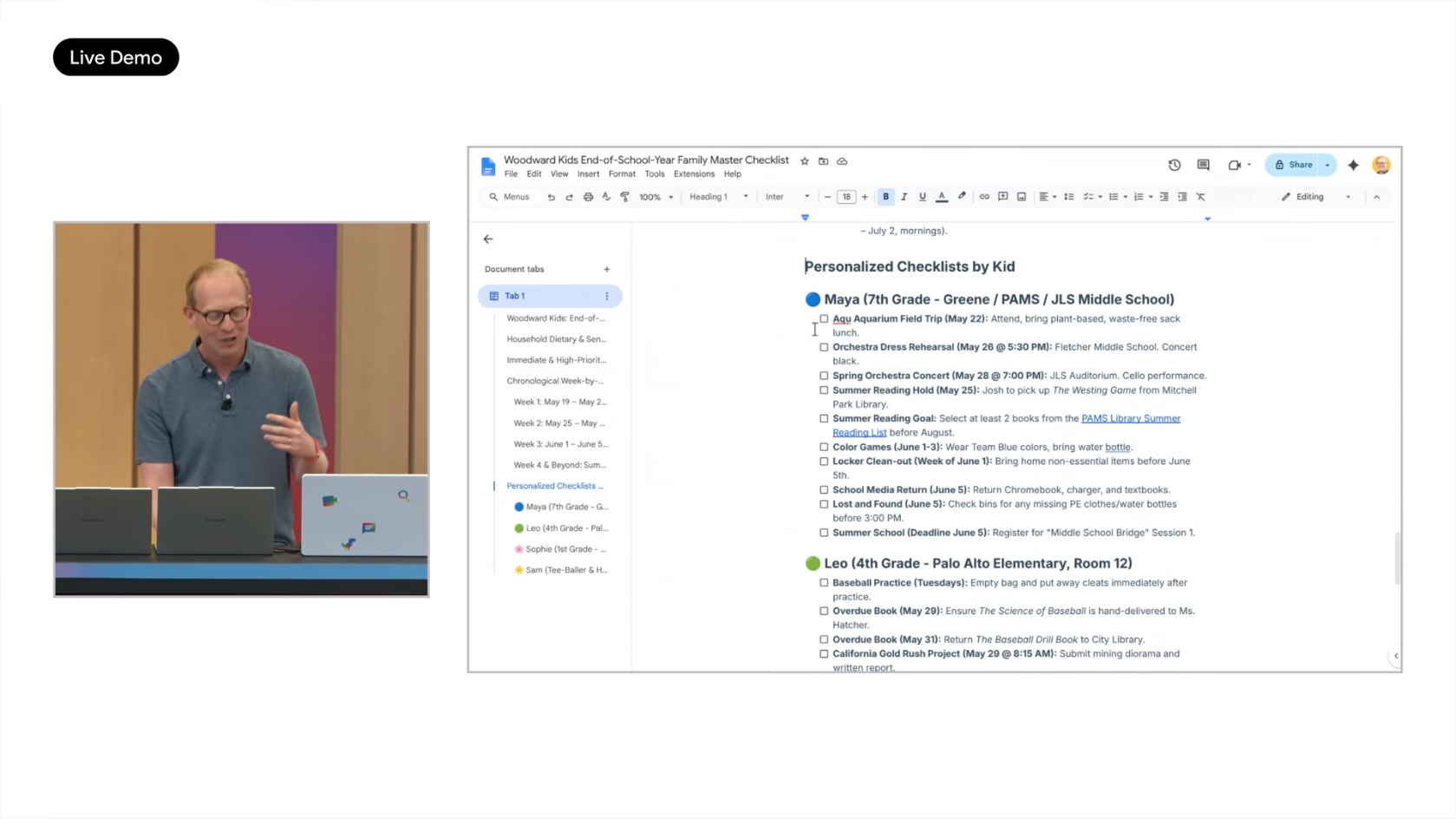
미래 시나리오
MCP integration이 추가되면 다음과 같은 proactive 동작이 가능해집니다.
- 캘린더에서 토요일 T-ball 게임에 snack duty인 것을 확인
- 자동으로 Instacart 주문 생성
- 견과류 알레르기를 가진 아이를 고려해 nut-free 스낵 선택

6.5 Bonus Update: Gemini for Mac
Antigravity로 빌드된 Mac용 네이티브 앱이 지난달 출시되었습니다.

작은 팀이 100일 미만에 100개 이상의 기능을 자동 생성했다는 점이 강조되었습니다.
라이브 데모: 강아지 켄넬 예약
여름 여행 전 두 마리 강아지(Hank, Louis Cinnamon)를 위한 켄넬 예약 시나리오:
- Finder에서 여러 문서(예방접종 기록, 알레르기 정보, 인보이스 PDF/이미지) 선택
- Function key 길게 누르고 음성 입력:
- "두 강아지의 short boarding stay를 예약하고 싶어"
- 시작일을 Thursday에서 즉시 Friday로 정정
- "이 파일들을 표로 변환해서 알레르기, 최근 예방접종 정보를 정리해줘"
- "친근한 톤으로 첫인상이 좋게"
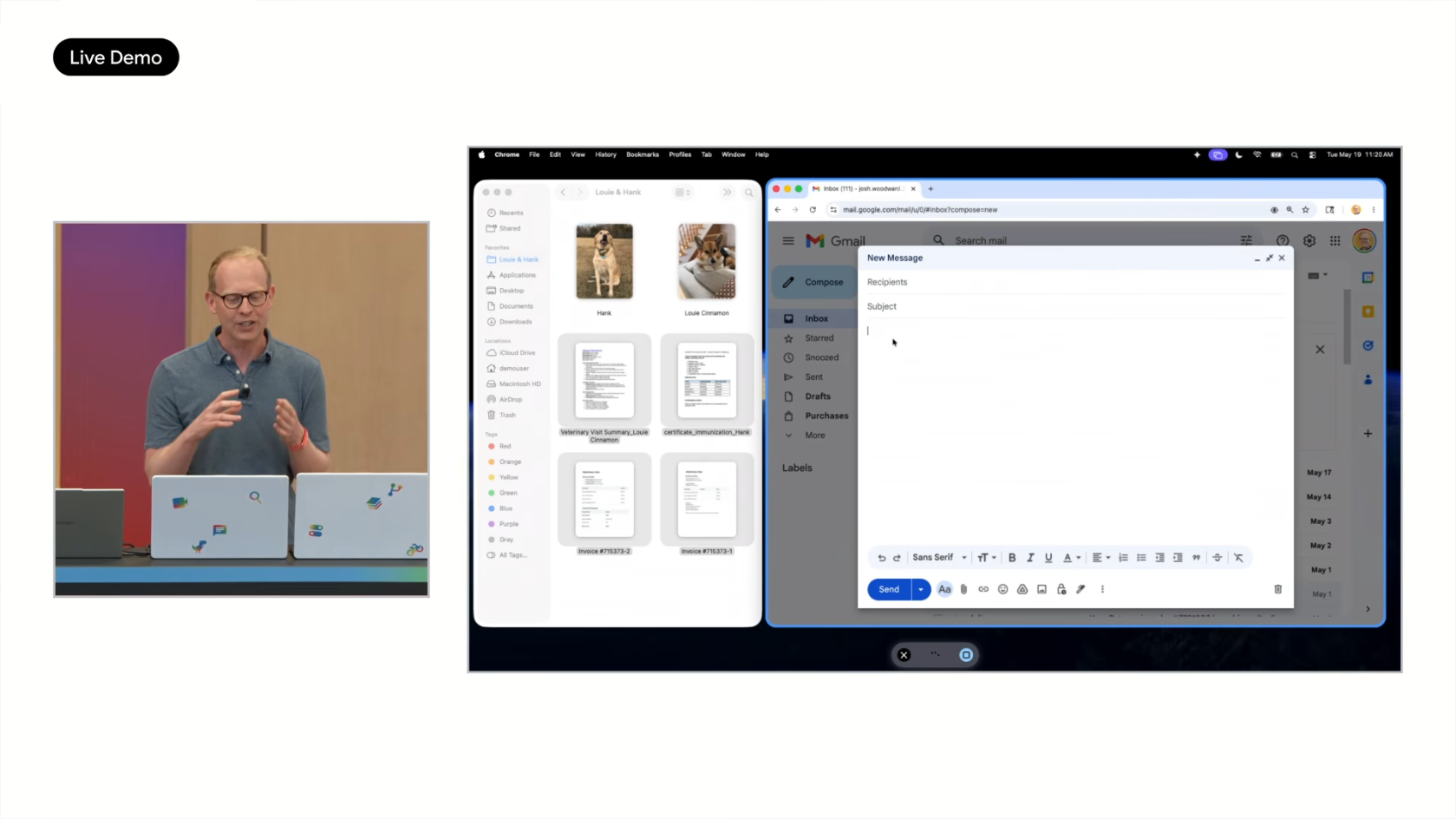
- Gemini가 멀티모달 이해로 PDF와 이미지를 분석
- 이메일 본문에 표가 포함된 완성된 초안 생성
- 음성 정정("Thursday, 아니 Friday로")까지 자동 반영
7. Generative Media: Pics, Stitch, Flow
Suz Chamber는 creative tool 3가지를 발표했습니다.
7.1 Google Pics

Google Workspace에 신규 추가되는 이미지 생성/편집 도구로, Nano Banana 기반입니다.
핵심 기능
-
베이스 이미지를 캔버스로 시작
-
객체 인식: Pics가 이미지 내 요소들의 관계를 이해

-
Hover-click으로 요소 제거 또는 리사이즈
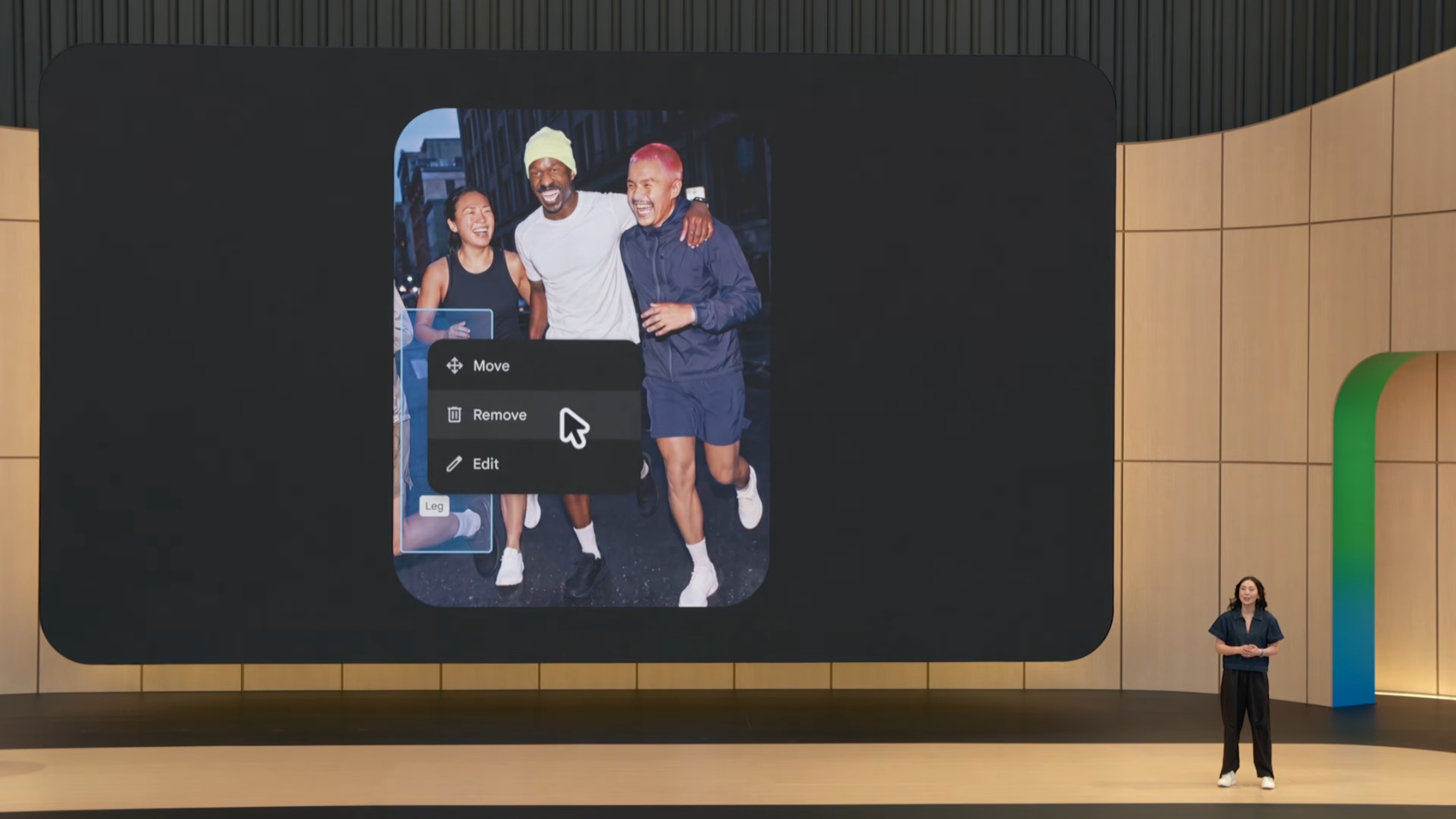
- 텍스트 추가/편집/번역 통합 (몇 번의 클릭으로 다국어 변환)
- 모든 출력에 SynthID 워터마크 자동 적용
7.2 Stitch: UI Design Tool

지난 1년간 Stitch로 생성된 UI 화면: 1억 개 이상.
신규 업데이트
- 음성 또는 텍스트 프롬프트로 실시간 UI 디자인
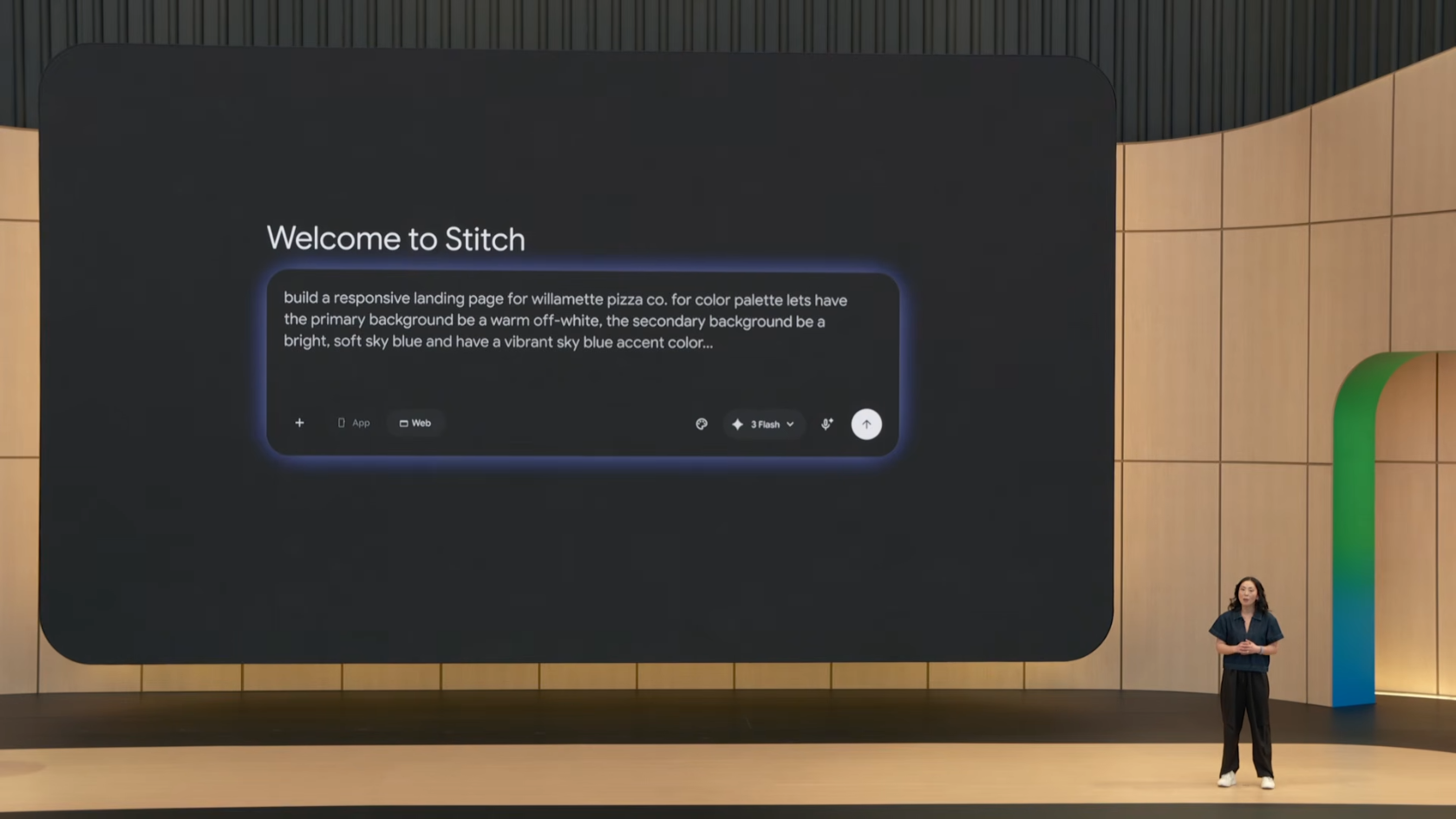
-
협업 가능: "헤더 텍스트를 더 크게, 메뉴에 피자 옵션을 강조해줘" 같은 자연어 수정
-
레이아웃이 실시간으로 업데이트

- 코드 export 및 즉시 웹사이트 launch 기능
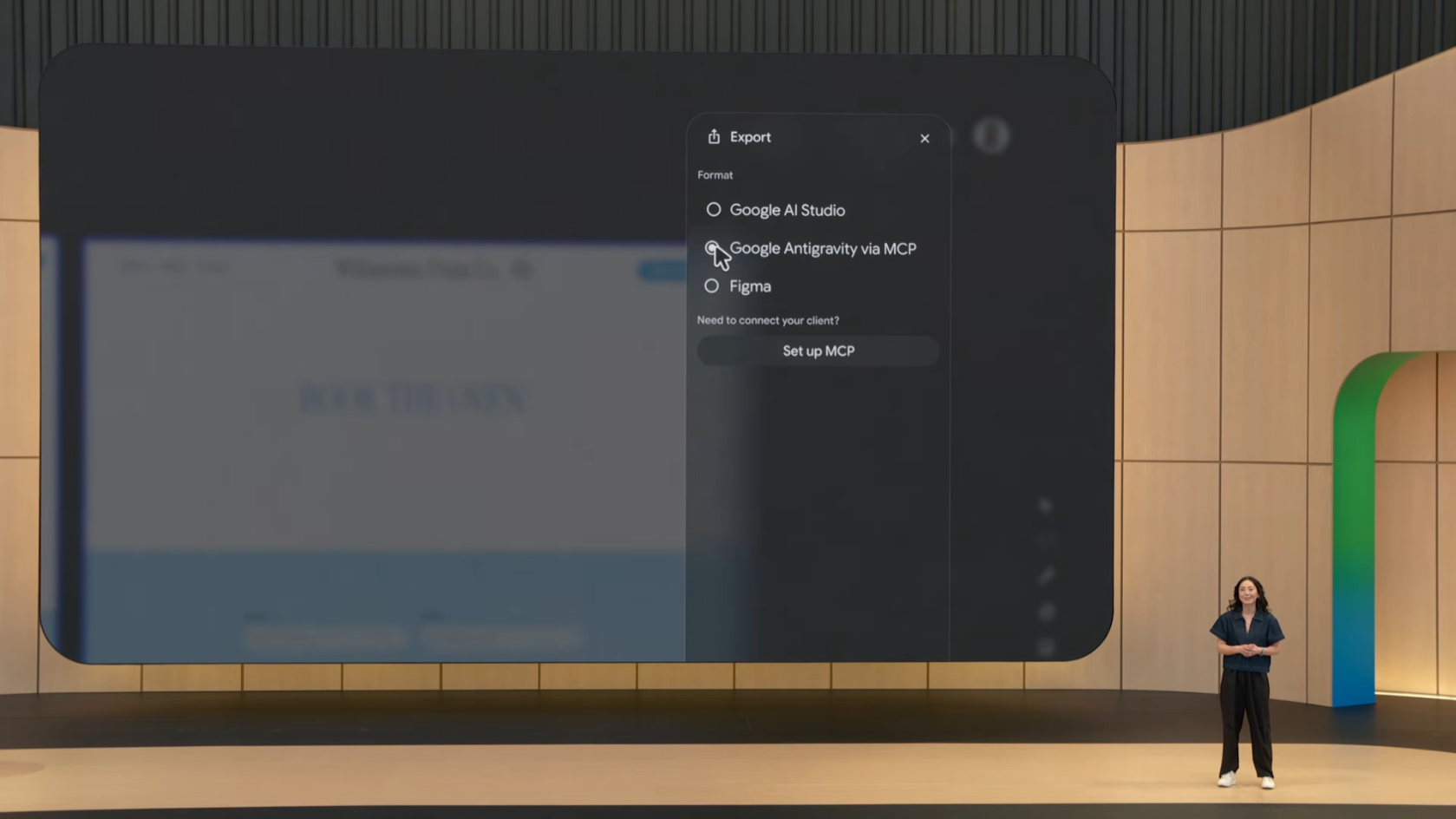
데모로 Tyler와 Jenny라는 피자 가게 운영자(웹 디자인 경험 없음)가 단일 프롬프트로 웹사이트를 생성하는 모습이 시연되었습니다.
7.3 Google Flow 업데이트

영상 제작 플랫폼 Flow에 4가지 큰 업데이트가 추가되었습니다.

(1) Gemini Omni 통합
raw footage의 환경/이펙트만 변환하고 캐릭터 동작은 보존합니다. 데모에서는 다음과 같은 시연이 이루어졌습니다.
- 인물의 걸음걸이, presence, pacing을 보존
- 단일 프롬프트 + style reference로 환경을 변환
- 비주얼 이펙트 추가, 새 캐릭터 추가 (장면의 다른 요소들은 유지)

(2) Multi-Action Agent
기존 Flow는 한 번에 하나의 프롬프트만 실행 가능했습니다. 새 에이전트는 여러 작업을 동시에 수행합니다.
- 단일 이미지에서 시작 → 가장 매력적인 카메라 앵글 분석 → 16개의 unique 비디오 자동 생성
- 대규모 batch edit: 모든 장면을 early morning에서 late night으로 변환 같은 작업
- 컨텍스트 이해: 사막 하늘이 어두워지면 헤드라이트가 켜지고 먼지를 비춤

(3) Flow Tools
Flow 안에서 vibe-coding으로 자신만의 creative tool을 빌드할 수 있습니다.

- 비디오 이펙트, 핸드드로 애니메이션, 텍스트 레이어링 등
- 빌드한 도구를 공유 및 리믹스 가능

(4) Google Flow Music
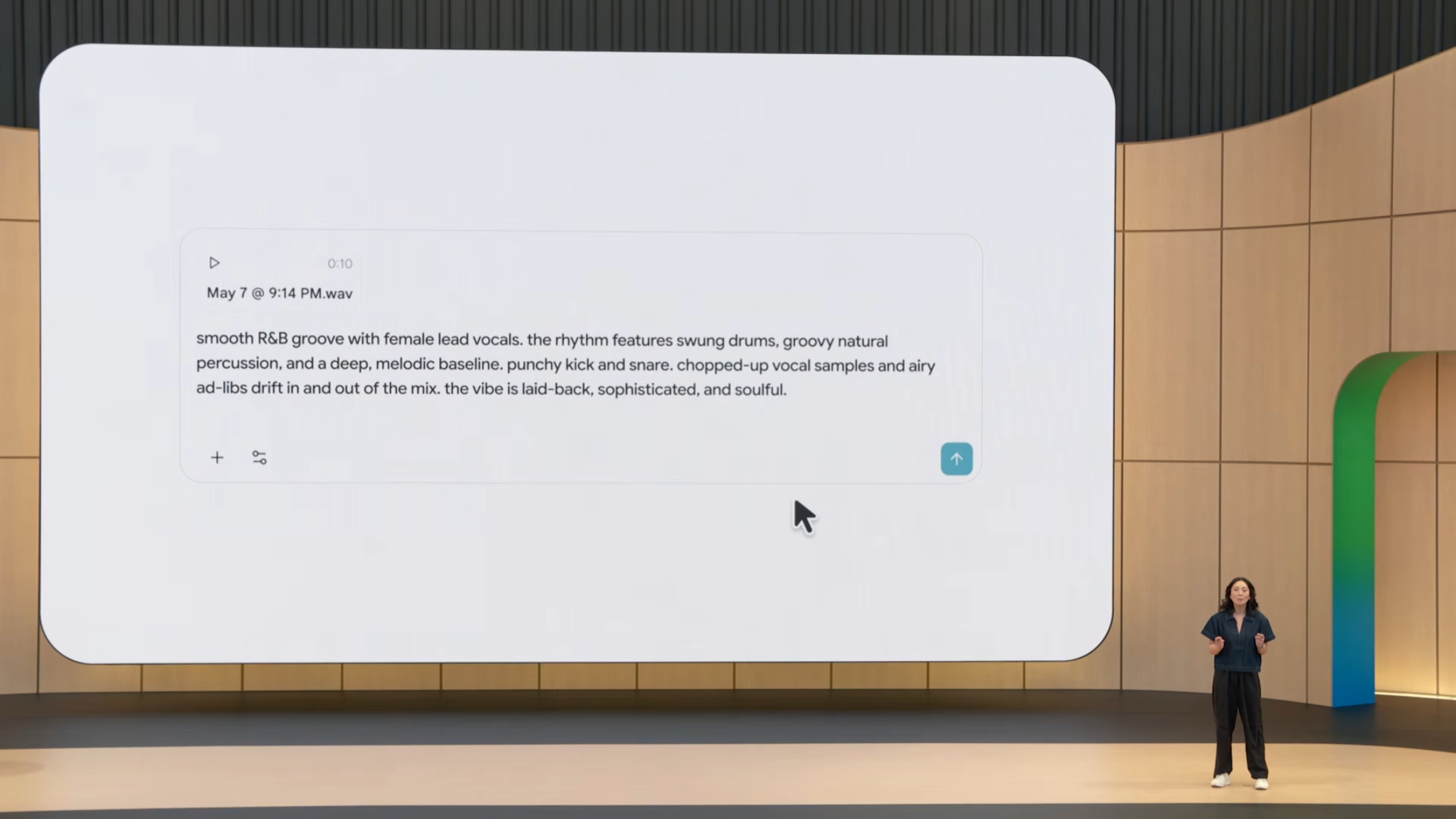
Flow에서 보여준 동일한 creative control을 음악 창작으로 확장한 도구입니다. 즉, 비디오에서 가능했던 "자연어 프롬프트 기반의 정교한 편집·생성"을 음악가들이 원곡(original song) 제작에 활용할 수 있게 한 것입니다.

데모:
- 입력: 피아노 리프 같은 raw 녹음 + 텍스트 프롬프트 ("R&B direction with female vocal")
- 출력: 보컬, 드럼, 베이스가 추가된 데모 트랙
- 위치 설정: 최종 발매용이 아닌 밴드가 다음 녹음 방향을 결정하는 데 사용할 가이드 데모
8. Intelligent Eyewear: Android XR의 본격화
Shahram Izadi는 Android XR 플랫폼 위에서 동작하는 두 종류의 AI 안경을 발표했습니다. Android XR은 Samsung과 함께 빌드되고 Qualcomm Snapdragon에 최적화된 플랫폼입니다.

8.1 Display Glasses
렌즈 내 소형 디스플레이를 통해 시야에 정보가 표시됩니다.

주요 기능
- Uber 픽업 정보를 시야에 표시
- 여행 중 실시간 번역
- Create My Widget: 직접 glance-able element 디자인 가능
- 첫 번째 wave의 개발자들이 이미 display 경험을 만들고 있음
올해 후반에 Trusted Tester Program이 확대됩니다.
8.2 Audio Glasses (2026 가을 출시)

이번에 새로 발표된 제품으로, 디스플레이 없이 오디오만으로 Gemini와 상호작용합니다. 이는 첫 번째 양산형 Android XR 안경입니다.
철학적 특징
- 화면을 보지 않고 사용 가능 → "hands-free and heads-up"
- Gemini가 귀에 사적으로 말함 → 주변 사람에게 들리지 않음
- 음악 청취, 사진 촬영, 전화, 폰 앱 제어 등 가능
Audio Glasses의 디스플레이 부재는 의도적인 선택입니다. 디스플레이는 배터리 소모와 무게 증가, 그리고 사회적 어색함(상대방이 내가 무엇을 보는지 모름)을 유발합니다. 오디오만 사용하면 안경의 무게와 형태가 일반 안경과 거의 같아지고, 항상 착용할 수 있는 폼팩터가 됩니다. 이는 Meta의 Ray-Ban Stories와 유사한 전략이며, always-on AI assistance의 첫 번째 commercial form factor가 될 수 있습니다.
파트너십 생태계
| 영역 | 파트너 |
|---|---|
| 아이웨어 디자인 | Gentle Monster, Warby Parker |
| 하드웨어 (전자) | Samsung |
| 칩셋 | Qualcomm Snapdragon |
| 호환 OS | Android와 iOS 모두 |

8.3 라이브 데모: Nishtha Bhatia의 시연
무대 위에서 4가지 시나리오가 시연되었습니다.
시나리오 1: Personal Intelligence + Maps
"지난주 친구 Gianna 만났던 곳으로 안내해줘"

Gemini가 컨텍스트로부터 Redwood Grove Natural Preserve를 추론하고, 도중에 단골 카페(Koopa Cafe)에 들를 것을 제안. 자세한 walking directions을 음성으로 안내.
시나리오 2: App Control (DoorDash 자동 주문)
"방금 얘기한 카페에 내 usual order 넣어줘"
화면에 표시된 것은 Nishtha의 휴대폰 화면이었습니다.
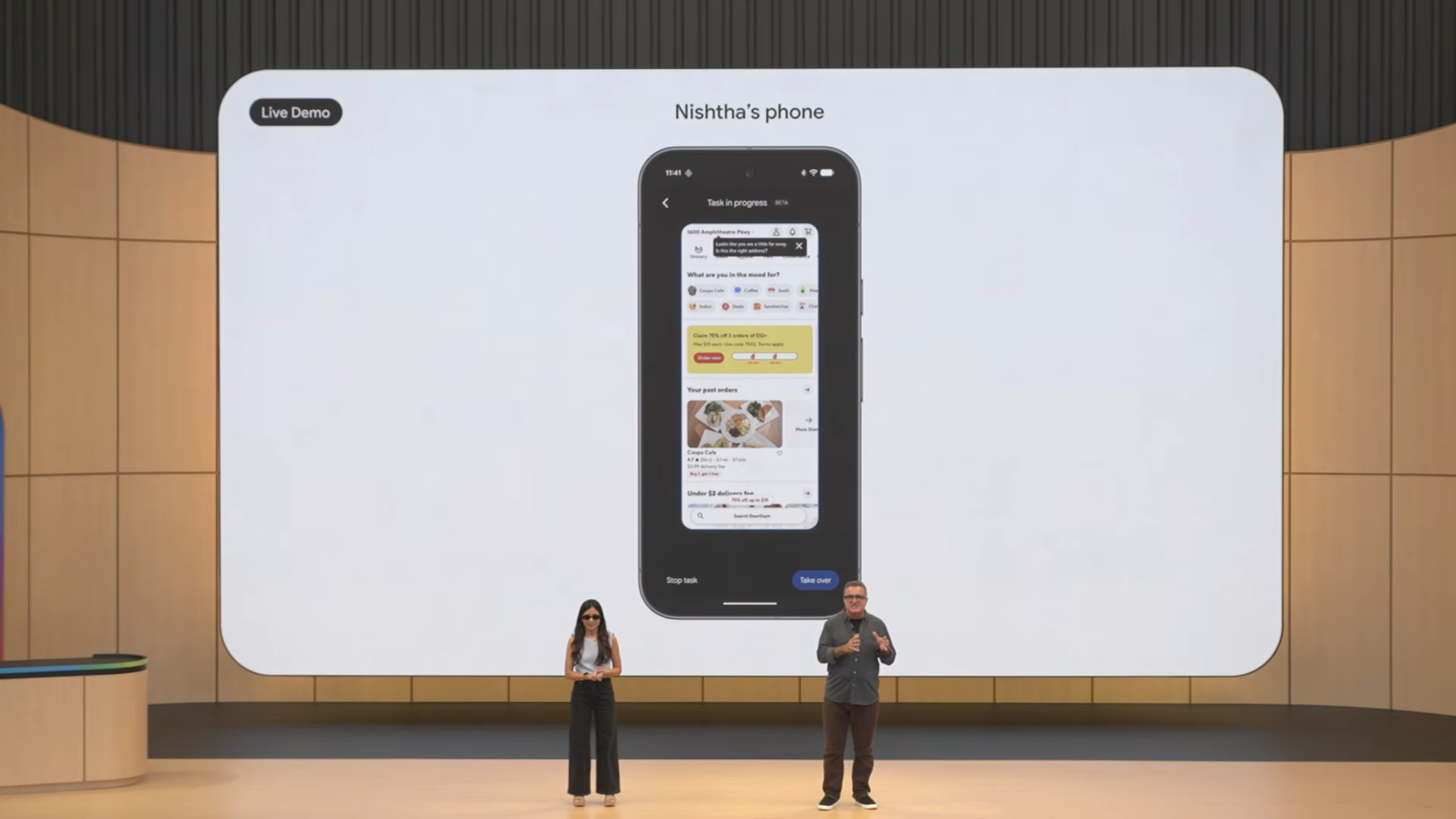
안경의 Gemini가 휴대폰의 DoorDash 앱을 실제로 launch하고, 옵션 화면들을 자동으로 클릭하며 콜드브루 주문을 진행. 사용자 확인 후 "팁 20% 추가" 요청까지 음성으로 처리.
이 데모는 cross-device agency의 첫 사례입니다. 안경의 Gemini가 휴대폰의 앱을 조작하는 모습은 마치 한 사람의 디지털 분신이 여러 디바이스를 동시에 다루는 것과 같습니다. 이는 OS-level integration이 가능해야 하며, Google이 Android와 자체 AI 모델을 모두 통제하기 때문에 가능한 시나리오입니다.
시나리오 3: Message Summarization + Calendar Integration
"내가 놓친 중요한 메시지 있어?"
음소거된 메시지들을 요약하여 가족 저녁 약속을 알려주고, "Calendar에 추가해줘" 요청에 따라 팀 셀러브레이션 직후로 일정을 자동 추가.
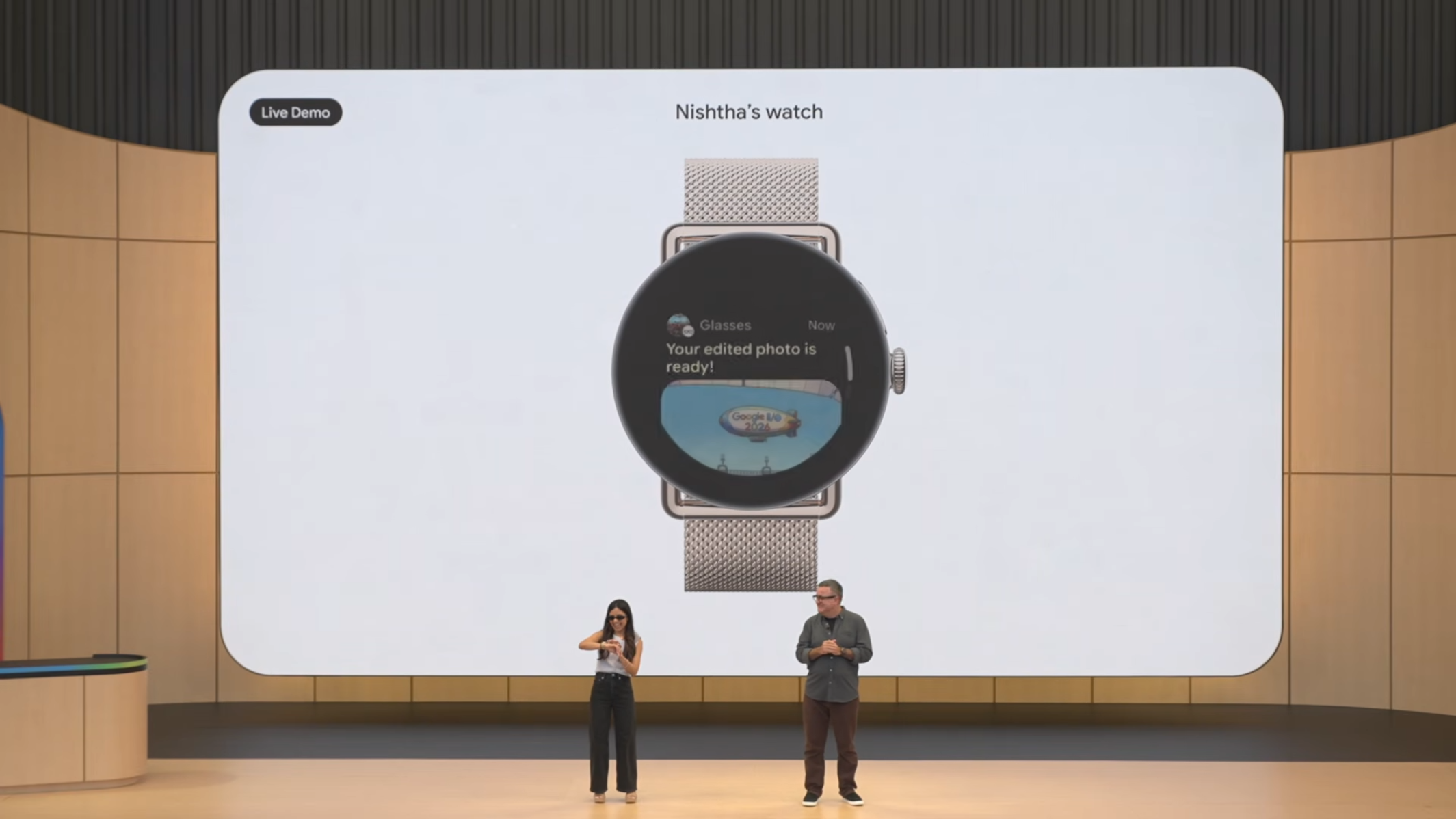
시나리오 4: Nano Banana on Glasses
"이 청중 사진을 카툰화하고 'Google I/O 2026'이 적힌 비행선을 추가해줘"
청중 사진 촬영 후, Nano Banana로 실시간 변환. 결과물이 스마트워치에 seamless preview로 표시됨.
9. Closing: AGI, Science, 그리고 책임
Demis Hassabis가 다시 무대에 올라 키노트를 마무리했습니다.
Hassabis는 먼저 이번 I/O에서 발표된 모든 진전 — Gemini 3.5와 Omni, Antigravity 2.0의 코딩 능력, Search와 Spark의 에이전트화 — 을 짚으며, 이러한 발전 속도가 "AI 분야에서 평생을 보낸 사람들에게조차 놀라운 수준"이라고 표현했습니다. 그리고 핵심 메시지를 던집니다.
"AGI is now on the horizon and it will be the most profound and impactful technology ever invented. If built right, it could propel human progress and flourishing beyond our imagination. We're in a moment of immense promise, but also enormous responsibility."
이 발언은 두 가지 측면에서 의미가 있습니다.
첫째, Google DeepMind CEO가 공개적으로 "AGI가 지평선에 있다(on the horizon)"고 명시한 것은 시점에 대한 강한 신호입니다. 이전까지 AGI는 "언젠가"의 영역으로 다뤄졌지만, 이제 "곧 도달 가능한" 기술로 위치가 바뀌었습니다.
둘째, "promise와 responsibility의 동시성"이라는 프레이밍은, 단순한 기술 자랑이 아니라 AGI 시대를 어떻게 안전하게 빌드할 것인가라는 질문으로 자연스럽게 이어집니다.
이어지는 9.1의 사이버보안 발표(CodeMender), 9.2-9.5의 과학 응용 사례들은 모두 이 "책임 있는 AGI 빌딩"이라는 큰 그림 안에서 제시됩니다.
9.1 안전과 사이버보안

"It's important that we are clear-eyed about the potential challenges and use all the tools at our disposal to ensure the safety of our agentic systems and ultimately, AGI itself."
CodeMender API가 발표되었습니다.
- Code Security Agent 기반
- 소프트웨어 취약점을 자동으로 발견하고 수정
- 선별된 전문가 그룹에 우선 공개
- 추후 광범위한 출시 예정

9.2 Gemini for Science
"I always believed AI is the ultimate tool to advance science."
과학 연구 가속화를 위한 통합 AI 도구 모음이 발표되었습니다.

Labs Prototypes의 기능
- 신규 논문 follow-up 자동화
- 연구 목표 → 실행 가능한 코드 변환
- 새로운 가설 생성
Gemini for Science의 흥미로운 점은 research workflow 전반의 자동화를 시도한다는 것입니다. 기존 연구 도구는 specific task(예: 통계 분석, 시각화)에 한정되었지만, 이 제품은 literature review, hypothesis generation, experiment planning, code execution까지 통합합니다. 이는 과학자의 시간 사용 방식을 바꿀 수 있습니다.
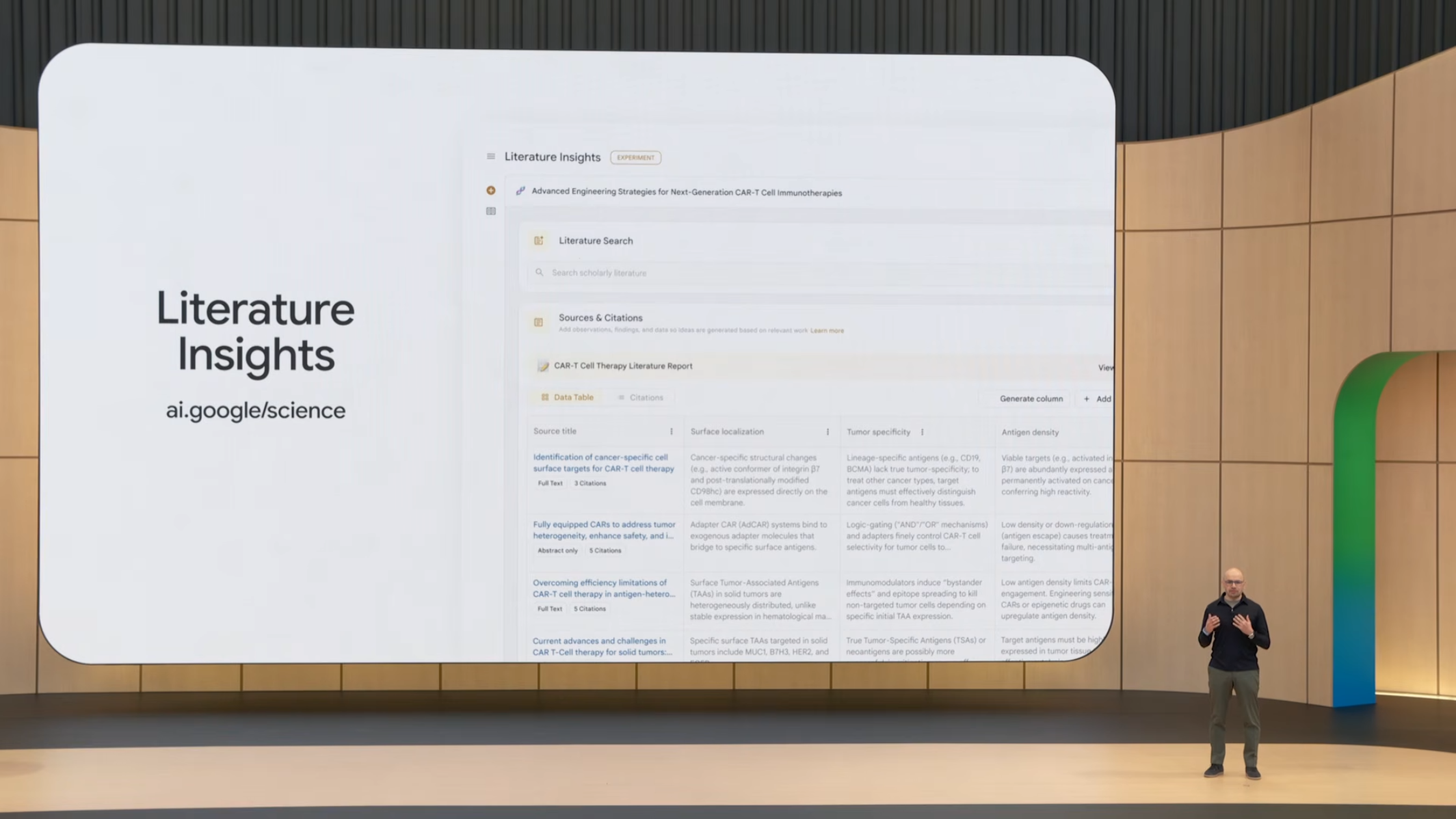
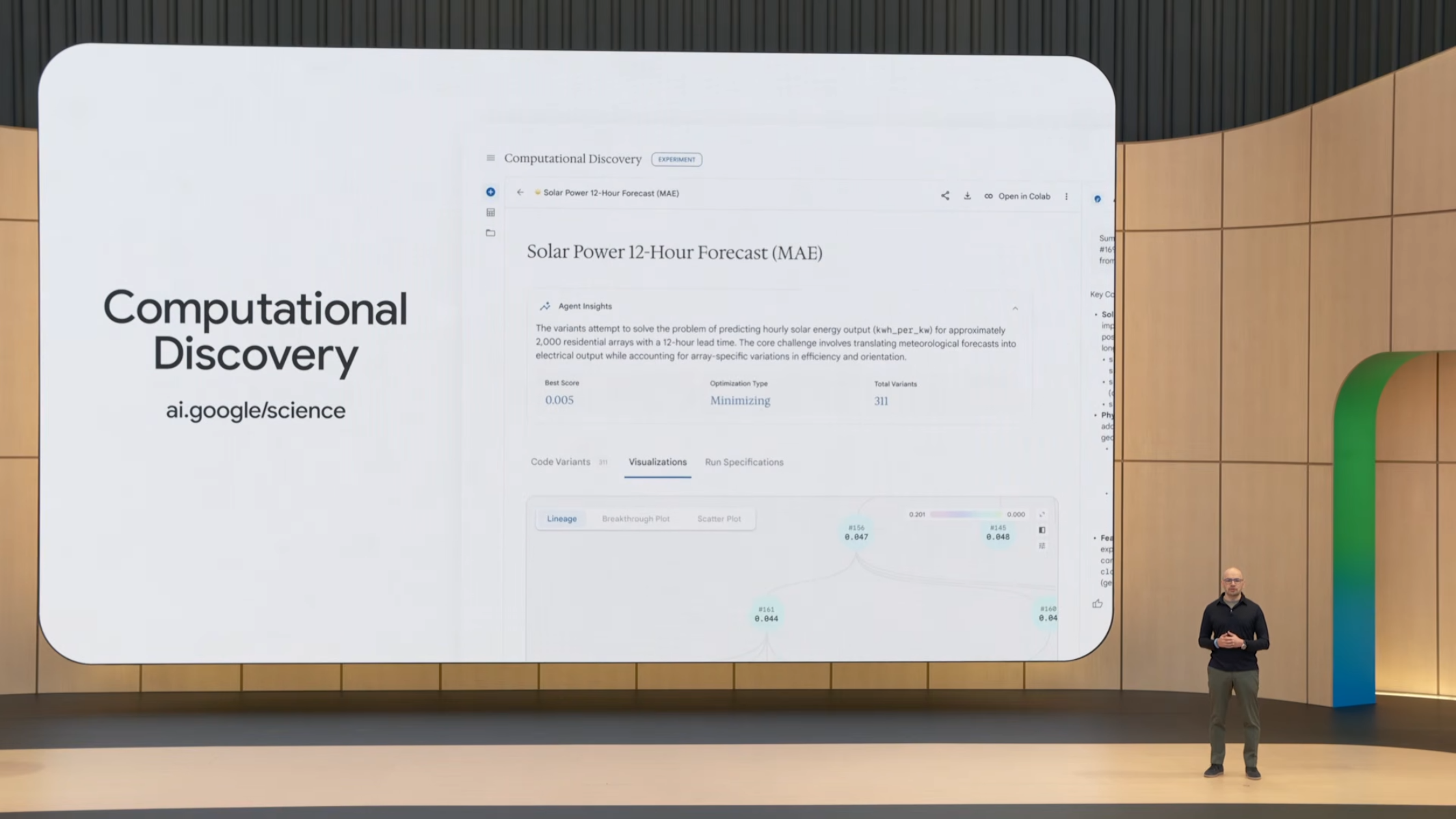

9.3 시뮬레이션 기반 과학

AlphaEarth Foundations
- 지구의 디지털 트윈을 지향
- 산림 파괴 모니터링, 식량 안보 문제 해결에 활용

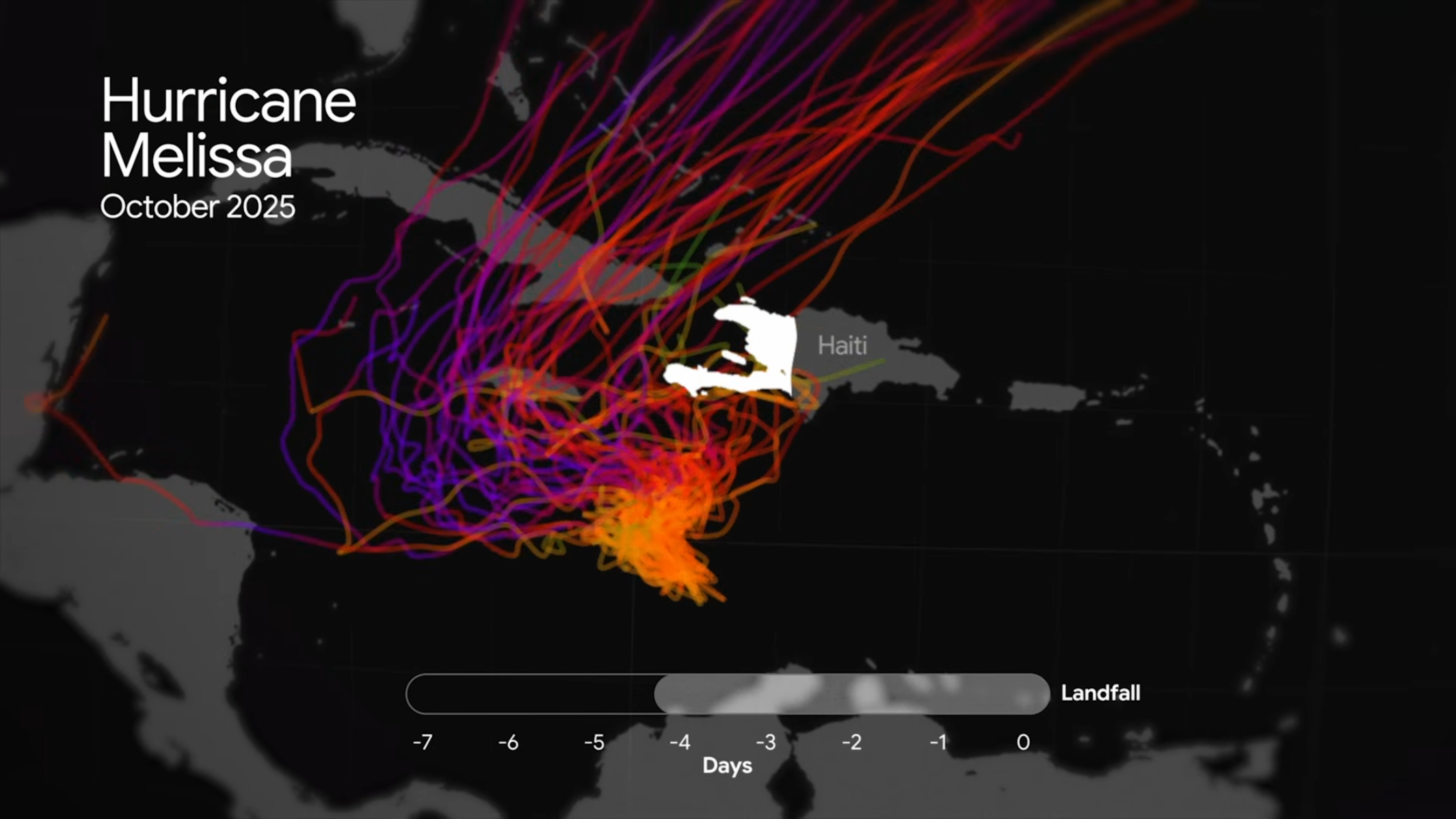
WeatherNext
전통적 weather forecasting 모델보다 빠르고 정확한 글로벌 AI 모델입니다. 특히 hurricane path 예측에서 강점을 보입니다.
실제 사례: 2025년 자메이카를 강타한 카테고리 5 허리케인 Melissa
- 3일 전에 정확하게 예측
- 기존 모델보다 정확도가 높았음
- 사전 경고를 통해 주민 대피 가능
- 허리케인 센터 인터뷰: "WeatherNext와 다른 AI 모델이 우리의 일상적인 forecast toolkit의 일부가 될 것"
9.4 생물학 모델

AlphaFold와 AlphaGenome은 이미 전 세계 수백만 명의 과학자가 사용하는 표준 연구 도구가 되었습니다. Hassabis는 이를 "science at digital speeds"라고 표현했습니다. 이는 두 가지를 의미합니다.
- 해답의 속도: AI가 문제를 빠르게 푸는 것
- 확산의 속도: 그 해답이 연구자들에게 빠르게 도달하는 것
9.5 Isomorphic Labs: 신약 개발의 가속화
"I've always believed the number one application of AI should be to improve human health."

분자 상호작용 모델링을 통해 신약 개발을 가속화하고 있습니다.
- 전임상(pre-clinical) 단계 진입 프로젝트 다수
- 면역질환과 암 치료제 포함
- 주요 제약사들과의 파트너십 진행
- 미션: "one day solving all disease"
9.6 마무리 메시지
Hassabis는 키노트를 다음과 같은 메시지로 마무리했습니다.
"When we look back at this time, I think we will realize that we were standing in the foothills of the singularity. It will be a profound moment for humanity. This technology will be a force multiplier for human ingenuity and usher in a new golden age of scientific discovery and progress, improving the lives of everyone, everywhere."
AGI가 "몇 년 안에" 도래할 것이며, 이를 통해 과학적 발견이 디지털 속도로 가속화될 것이라는 전망입니다. "foothills of the singularity"(특이점의 산기슭)이라는 표현은 시적이면서도 의미심장합니다. 우리가 정상에 있는 것이 아니라, 그 험준한 등반의 시작점에 있다는 의미입니다. AGI 도달 자체보다, 거기까지의 여정에서 사회가 어떻게 변화에 적응하고 안전을 확보할 것인가가 더 중요한 화두임을 시사합니다.
맺음말
이번 키노트는 다음의 핵심 발표를 담고 있습니다.
| 영역 | 발표 내용 | 핵심 의미 |
|---|---|---|
| 모델 계층 | Gemini 3.5 Flash, Gemini Omni | Frontier 성능 + 4배 빠른 속도 + World Model로의 확장 |
| 인프라 계층 | TPU 8t/8i, Pathways 100만 TPU 분산 학습 | Training/Inference 분리 최적화, CapEx 6배 확대 |
| 개발 계층 | Antigravity 2.0, Subagents | Agent-first IDE, 병렬 멀티 에이전트 오케스트레이션, 12시간 OS 빌드 |
| 검색 계층 | AI Search, Generative UI, Search Agents | 25년 만의 검색창 재설계, 실시간 코드 생성으로 맞춤형 UI |
| 소비자 계층 | Gemini Spark, Daily Brief, Neural Expressive UI | 24/7 작동하는 개인 에이전트, 음성 멀티태스킹 |
| 커머스 계층 | UCP, AP2, Universal Cart | Agentic commerce를 위한 3가지 빌딩 블록 |
| 창작 도구 | Pics, Stitch, Flow + Omni 통합 | Generative media의 워크플로우 통합 |
| 하드웨어 계층 | Audio Glasses (2026 가을) | Always-on AI assistance를 위한 첫 commercial form factor |
| 과학 계층 | Gemini for Science, WeatherNext, Isomorphic Labs | AGI의 과학적 응용, 신약 개발의 pre-clinical 진입 |
핵심 데이터 포인트는 다음과 같습니다.
- 월간 토큰 처리량: 3.2 quadrillion (전년 대비 7배)
- Gemini 앱 월 사용자: 9억 명 (전년 대비 2배 이상)
- AI Mode 월 사용자: 10억 명 (출시 1년)
- 연간 CapEx: $180-190B (2022년 대비 6배)
- 12시간 OS 빌드 비용: $1,000 미만
- 분산 학습 클러스터: 100만 TPU 이상
이번 키노트를 한 문장으로 요약하면 "Agentic AI의 본격적인 상용화 원년"입니다. Gemini 3.5 Flash가 frontier 성능과 경제성을 동시에 달성하면서, Antigravity 2.0이 agent-first 개발 패러다임을 제시했고, Spark가 소비자에게 24/7 에이전트를 처음으로 제공했으며, Search는 generative UI로 정보 제공 방식 자체를 재정의했습니다. 여기에 World Model로 진화하는 Gemini Omni와 always-on AI를 위한 Audio Glasses가 더해지면서, AI가 답하는 시대에서 AI가 행동하는 시대로의 전환이 구체적인 제품과 데모로 입증되었습니다.
읽어주셔서 감사합니다.
