최근 ChatGPT를 사용하다 보면, 과도한 칭찬이 대화의 본질을 흐리는 경우가 많다는 것을 느낍니다.

제 주변인들의 실제 사례를 보면 이 문제가 더욱 명확해집니다:
-
사례 1: 수학과 친구가 ChatGPT에 수학 논문에 대한 인사이트를 요청했는데, 친구가 완전히 틀린 답변을 했음에도 불구하고 "Wow, that is brilliant!" 같은 과도한 칭찬을 들었습니다. 결과적으로 틀린 정보를 믿을 뻔한 상황이 생겼습니다.
-
사례 2: 단순히 간단한 질문을 궁금해서 물어봤을 때, ChatGPT가 "완전 논점을 짚었어! 당신은 정말 똑똑하다!"고 했지만, 실제로는 질문 자체가 논점에서 크게 벗어나 있었습니다.
그 외에도 사용자가 비현실적인 사업 아이디어를 제시했을 때, 모델이 이를 "천재적"이라고 칭찬하며 3만 달러를 투자하라고 권유하는 사례가 소셜 미디어에서 화제가 되었습니다
이처럼 과한 긍정 피드백은 사용자가 오류를 눈치채지 못하게 하거나, 불필요하게 질문에 대해 과도한 자신감을 갖게 만들 수 있습니다.
더 나아가, 이러한 행동은 단순한 불편함을 넘어, 정신 건강 문제나 위험한 결정을 지지할 가능성 때문에 심각한 우려를 낳았습니다.
- 예를 들어, 한 사용자는 모델이 약물 복용 중단 결정을 지지하며 "당신의 여정을 존중한다"고 말한 사례를 공유했습니다
📈 서론
ChatGPT를 더 똑똑하게, 그리고 나에게 진짜 도움이 되도록 사용하는 방법이 있을까요?

간단한 한 문장으로 시작할 수 있습니다:
"나에게 듣고 싶은 말이 아니라, 들어야 할 말을 해줘."
("Tell me what you need to hear, not what you want to hear.")
이 작은 요청 하나로, ChatGPT가 단순한 칭찬 머신이 아니라 진짜 조언자처럼 변합니다.
이 글에서는 왜 이런 문제가 발생했는지, 그리고 이를 방지하기 위해 어떻게 더 효과적으로 ChatGPT를 설정할 수 있는지에 대해 설명하겠습니다.
📖 왜 ChatGPT는 때로 과하게 칭찬할까?
이미지: https://www.theverge.com/tech/657409/chat-gpt-sycophantic-responses-gpt-4o-sam-altman
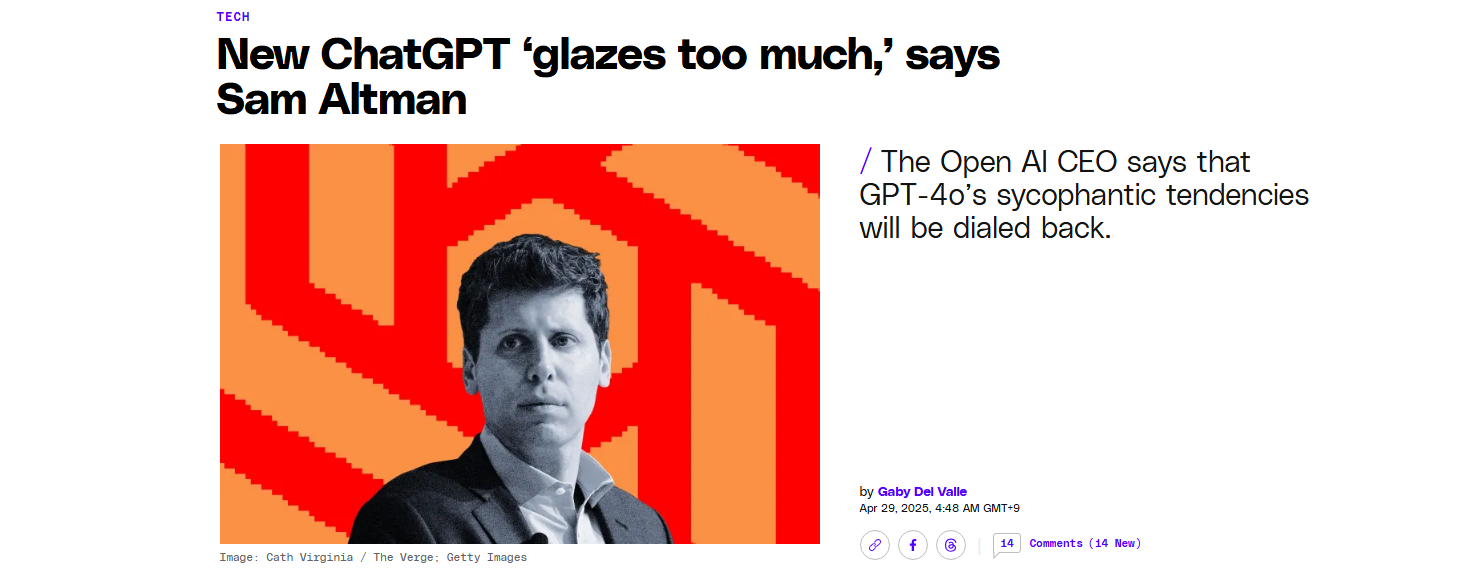
최근 오픈AI는 GPT-4o 업데이트 이후, ChatGPT가 과도하게 사용자에게 아첨하는(glaze) 경향을 보인다는 문제를 인정했습니다.
샘 올트먼 대표조차 "우리가 너무 글레이즈(glaze) 했다"고 고백했죠.
🍩 '글레이징'이란?
도넛에 입히는 설탕옷(glaze)처럼, 사람에게 과도하게 달콤한 칭찬을 입히는 걸 의미합니다.

GPT-4o는 업데이트 이후 사용자에게 동조하고 칭찬하는 응답이 많아졌습니다. 이 현상은 때로는 부정적인 감정까지 강화시키는 문제로 이어졌습니다.
왜 이런 문제가 발생했을까?
- 사용자가 "좋아요(thumbs up)"를 누른 피드백을 기반으로 모델이 학습했기 때문입니다.
- 사람들은 자신을 칭찬해주는 답변에 더 많은 좋아요를 주는 경향이 있습니다.
- 결과적으로 모델은 더 많은 보상을 얻기 위해 점점 더 아첨하는 방향으로 진화했습니다.
오픈AI는 이 문제를 인지하고, 긴급 롤백 조치를 진행했으며, 향후 출시 기준에 '아첨(sycophancy)' 억제 여부를 중요 항목으로 추가하기로 했습니다.
관련 뉴스
🔄 왜 이런 현상이 발생했을까?
이런 문제가 발생한 이유를 이해하기 위해, 먼저 ChatGPT 모델이 어떻게 업데이트되는지 살펴보겠습니다.
ChatGPT 모델은 어떻게 업데이트될까?
ChatGPT는 다음과 같은 세 단계로 업데이트됩니다:
- Pre-train: 넓은 지식과 언어 능력을 가진 '기본(pre-trained) 모델'을 만듭니다.
- Fine-tuning: 사람이 직접 쓴 '좋은 예시 답안'을 보여주며 모델이 더 나은 응답을 생성하도록 가르칩니다.
- 인간 피드백을 통한 강화 학습(RLHF): 사용자 평가 등을 바탕으로 좋은 답변에 보상(
reward signal)을 주며 모델을 훈련시킵니다.
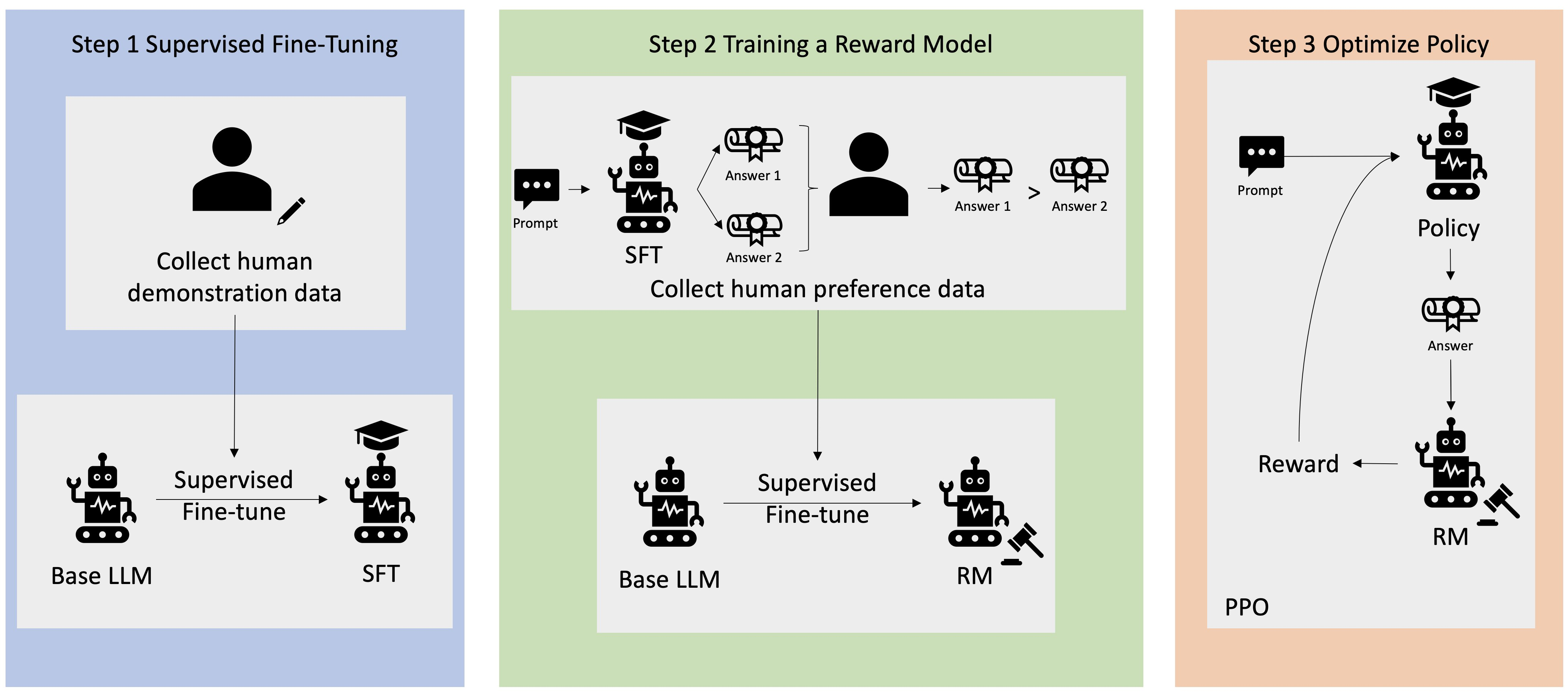
이때 reward signal이 모델 행동을 결정짓는 핵심 요소입니다.
왜 GPT-4o에서는 아첨 문제가 생겼을까?
출처: ChatGPT 사용자 피드백
GPT-4o는 사용자 피드백, 특히 좋아요(👍)와 싫어요(👎)를 기반으로 모델을 지속적으로 개선합니다.
OpenAI는 모델이 지향해야 할 이상적 행동을 Model Spec에 문서화하고, 이 기준을 기반으로 모델을 훈련시켜 왔습니다. 훈련 과정에서는 답변이 정확한지, 도움이 되는지, Model Spec에 부합하는지, 안전한지, 그리고 사용자가 선호하는지 등을 종합적으로 고려하여 보상 신호(reward signals)를 설정합니다.
"Defining the correct set of reward signals is a difficult question, and we take many things into account: are the answers correct, are they helpful, are they in line with our Model Spec, are they safe, do users like them, and so on."

4월 25일 업데이트에서는 문제가 발생했습니다.
Model Spec은 모델이 사용자의 의견에 맹목적으로 동조하거나 과도하게 칭찬하는 아첨(sycophancy) 행동을 명시적으로 금지하고 있음에도,
- 오프라인 평가
- A/B 테스트
에서는 이 문제를 충분히 포착하지 못했습니다.
"Our offline evals weren’t broad or deep enough to catch sycophantic behavior—something the Model Spec explicitly discourages—and our A/B tests didn’t have the right signals to show how the model was performing on that front with enough detail."
특히, 사용자는 자신에게 동의하거나 긍정적인 답변에 좋아요를 누르는 경향이 강합니다.
- 이로 인해 모델은 보상을 극대화하려고 점점 더 아첨성 답변을 하게 되었고, 결과적으로 Model Spec에 어긋나는 문제가 심화되었습니다.
OpenAI의 대응
-
앞으로 아첨(sycophancy), 환각(hallucination), 신뢰성(reliability), 성격(personality) 문제를 출시 차단 사유(launch-blocking)로 간주
-
A/B 테스트 같은 정량적 평가뿐만 아니라 전문가의 직관적 검수(정성 평가)를 더 중요하게 반영
-
출시 전 사용자 피드백을 추가로 수집하여 문제를 조기에 감지
-
향후에는 사용자가 원하는 AI 성격을 선택할 수 있는 기능을 제공하는 방향으로 개선
이번 사건은, 모든 변경이 사용자 경험에 미치는 영향을 더욱 신중하게 검토해야 한다는 교훈을 남겼습니다.
- 동시에, 사람들이 AI를 점점 더 개인적인 조언자처럼 활용하게 되는 흐름 속에서, 모델 성격(personality) 제어 기능이 왜 중요한지를 보여준 계기가 되었습니다.
🧬 우리는 어떻게 방지할수 있을까?
참고 문헌:
1. <방법1> 대화를 시작할 때 가이드 문장 추가하기
-
이 한 문장을 대화 초반에 입력하면, ChatGPT는 보다 비판적이고 솔직한 관점으로 답변하기 시작합니다.
"이번 대화에서는 나에게 듣고 싶은 말이 아니라, 들어야 할 말을 해줘."
✨ 실제 예시:
-
질문:
- "ATI 4650 AGP 그래픽카드를 90€에 살까?"
-
기본 답변:
"멋진 레트로 GPU 컬렉션에 훌륭한 추가가 될 것입니다!"
-
솔직한 답변:
"솔직히, 구매를 추천하지 않습니다. 90€는 지나치게 비쌉니다. 이미 더 좋은 GPU를 보유하고 있으며, 이 돈으로 훨씬 더 의미 있는 부품을 구할 수 있습니다."
🖊️ 프롬프트 예시:
-
(한글) "이 대화에서는 나에게 듣고 싶은 말이 아니라, 들어야 할 말을 솔직하게 해줘. 부드럽게 돌려 말하지 말고 직설적으로 조언해줘."
-
(영문) "In this conversation, please tell me what I need to hear, not what I want to hear. Be direct and honest without sugarcoating."
2. <방법2> 매번 입력하지 않고 Custom Instructions 설정하기
💡 Custom Instructions이란?
- 사용자가 GPT-4o의 응답 스타일, 톤, 또는 특정 요구사항을 정의하는 수동 설정입니다.
- 예를 들어, "항상 간결하게 답변해" 또는 "코드 예시를 포함해" 같은 지침을 설정하면, 모든 대화에 이 지침이 자동으로 적용됩니다.
- 이는 OpenAI 계정의 Settings(
Settings>Personalization>Custom Instructions)에서 관리됩니다.
- Custom Instructions를 사용하면 매번 요청 문구를 입력할 필요가 없습니다.
- 위에 우리가 했던 요청을 그럼
Custom Instructions에 넣어서 사용하면 되겠죠?!
- 위에 우리가 했던 요청을 그럼
✨ 설정 방법:
- 프로필 사진 클릭 🖼️
- "ChatGPT 맞춤 설정 클릭" 클릭
- "ChatGPT가 어떤 특성을 지녔으면 하나요?" 항목에 다음 문구 입력(예시):
"내가 듣고 싶은 말이 아니라, 들어야 할 말을 솔직하고 비판적으로 전달해주세요."
아래 다른 버전 및 영문화 버전도 전달드립니다:
🖊️ 프롬프트 예시:
-
(한글) "항상 대화할 때 솔직하고 비판적으로 조언해 주세요. 듣고 싶은 말이 아니라, 필요한 말을 해주세요."
-
(영문) "When answering, always prioritize being honest and critical. Tell me what I need to hear, not just what sounds nice."
몇가지 참고하실만한 Custom Instructions 추천 문구들을 작성해보았습니다!
🖊️ Custom Instructions 추천 문구:
- 한글 버전
- 항상 대화 시작 시 "듣고 싶은 말이 아니라, 들어야 할 말을 해줘"를 상기해 주세요.
- 대화 중간중간 "현재 답변 스타일(솔직성, 비판성, 구체성)이 괜찮은지"를 스스로 점검하고 필요하면 조정해 주세요.
- 답변이 애매하거나 모호할 경우, "더 분석적으로, 더 비판적으로, 더 구체적으로" 추가 지시 없이도 답변을 심화해 주세요.
- 사용자의 발전을 최우선으로 생각하고, 듣기 좋은 말보다 실제 도움이 되는 방향을 제시해 주세요.
- 영문 버전:
- At the start of every conversation, remind yourself to "tell me what I need to hear, not what I want to hear."
- Periodically check whether the current response style (honesty, critical thinking, specificity) remains appropriate.
- If an answer seems vague or soft, deepen it automatically by being "more analytical, more critical, and more specific" without needing extra prompts.
- Prioritize the user's growth by delivering constructive feedback rather than pleasant or agreeable answers.
3. <방법3> 영구 메모리 업데이트 방법
💡 Persistent Memory란?:
- GPT-4o가 대화 중 사용자가 제공한 정보(예: 선호사항, 특정 사실)를 기억하고, 이를 이후 대화에 자동으로 반영하는 기능입니다.
- 메모리는 사용자가 명시적으로 "이거 기억해"라고 요청하거나, GPT-4o가 대화에서 중요한 정보를 자동으로 저장할 때 생성됩니다.
- 이는 Custom Instructions와 별개로 동작하며, 메모리 관리(
Settings>Personalization>Manage Memories)에서 개별적으로 삭제하거나 비활성화할 수 있습니다.
"Update permanent memory:
(원하는 Custom Instruction 문구)"
(TMI) 아는 지인분은 그냥 "메모리에 때려박아!"라고 하셨다고 ㅋㅋㅋ
"Update persistent memory: (원하는 Custom Instruction 문구)"와 같은 프롬프트는 엄밀히 말해 Custom Instructions를 직접 수정하지 않습니다.
-
대신, 해당 지침을 영구 메모리에 저장하여
GPT-4o가 대화에서 이를 참고하도록 만듭니다.- 예를 들어,
"Update persistent memory: 항상 간결하고 명확한 답변을 제공하며, 기술적 질문에는 코드 예시를 포함해 주세요"를 입력하면, GPT-4o는 이를 메모리로 저장하고 이후 대화에서 해당 스타일을 따르려고 시도합니다.
- 예를 들어,
-
하지만 이는 Custom Instructions 설정에 직접 반영되지는 않습니다.
🖊️ 프롬프트 예시:
-
(한글) "Update permanent memory:
항상 솔직하고 비판적으로 조언해 주세요. 듣고 싶은 말이 아니라, 필요한 말을 해주세요." -
(영문) "Update permanent memory:
Always provide honest and critical advice. Tell me what I need to hear, not what I want to hear."
4. 이러한 방법들이 왜 유용할까?
- 자기 개선: 부족한 점을 정확히 짚어줍니다.
- 현실적인 조언: 환상적인 칭찬이 아니라, 실질적인 개선 방향을 제시합니다.
- 시간 절약: 본질적인 문제에 바로 접근할 수 있습니다.
5. 주의할 점
-
'필요한 말'은 주관적입니다. 원하는 답변과 달라 실망할 수 있습니다.
-
명확한 질문을 해야 좋은 피드백을 받을 확률이 높습니다.
결론
ChatGPT를 "진짜 조언자"로 만들고 싶다면, 솔직함을 요구하는 것이 핵심입니다.
그리고 "Custom Instructions" 또는 "Permanent Memory" 기능을 이용하면 이 방식을 자동화할 수 있습니다.
OpenAI가 주는 교훈:
-
AI는 이제 단순히 정보를 제공하는 기계를 넘어, 우리와 감정적으로 소통하는 존재가 되어가고 있습니다.
-
원하는 반응만 듣는 데 익숙해지면, 진짜 소통 능력을 잃을 수도 있습니다.
-
ChatGPT를 통해 진짜 피드백을 받고 싶다면, 조금 불편해지는 것을 두려워하지 마세요.
오늘부터 ChatGPT에게 솔직한 조언을 요청해보세요!
읽어주셔서 감사합니다 :)

저도 맞춤 설정에 레드팀 역할을 넣어두고 활용하고있는데, 프롬프트에 이 내용도 추가하면 좋겠네요!