순차 탐색(Sequential Search)
-
리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서부터 데이터를 하나씩 차례대로 확인하는 방법
-
시간만 충분하다면 무조거 찾을 수 있음
-
정렬되지 않은 리스트에서 데이터를 찾아야 할때 사용
def sequential_search(n,target, array):
# 각 원소를 하나씩 확인
for i in range(n):
# 현재의 원소가 찾고자 하는 원소와 동일한 경우
if array[i] == target:
return i + 1 # 현재의 위치 반환 - 인덱스는 0부터 시작하므로 1을 더한다
print("생성할 원소 개수를 입력하고 찾을 문자열을 입력")
input_data = input().split()
n = int(input_data[0]) # 원소의 개수
target = input_data[1] # 찾고자 하는 문자열
print("array 입력 구분은 띄어쓰기 한칸")
array = input().split()
if len(array) != n:
print("배열 개수 초과")
else:
# 함수 실행
print(sequential_search(n,target,array))
생성할 원소 개수를 입력하고 찾을 문자열을 입력
3 2
array 입력 구분은 띄어쓰기 한칸
3 2 1
2- 데이터의 개수가 N개일 때 최대 N번의 비교 연산이 필요하므로 순차 탐색은 최악의 경우 시간 복잡도는 O(N)이다.
이진 탐색(Binary Search) : 반으로 쪼개며 탐색하기
-
이진 탐색은 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘이다.
-
데이터가 무작위일 때는 사용할 수 없지만, 정렬되어 있다면 매우 빠르게 데이터를 찾을 수 있다.
-
이진 탐색은 위치를 나타내는 변수 3개를 사용하는데 탐색하고자 하는 범위의
시작점,끝점, 그리고중간점이다.찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 찾는다
예시) 이미 정렬된 10개의 데이터 중에서 값이 4인 원소를 찾아보자
-
시작점과 끝점을 확인한 다음 둘 사이에 중간점을 정한다. 중간점이 실수일 때는 소수점 이하을 버린다.
-
그림에서 각각의 인덱스는 시작점은 [0], 끝점은 [9], 중간점은 [4]이다.
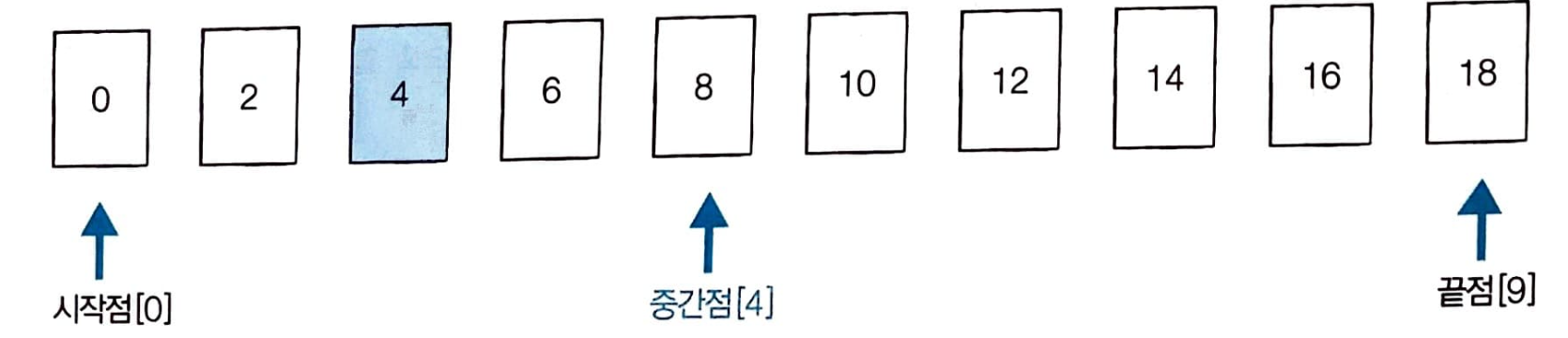
- 다음으로 중간점 [4]의 데이터 8과 찾으려는 데이터 4를 비교한다. 중간점의 데이터 8이 더 크므로 중간점 이후의 값은 확인할 필요가 없다. 끝점을 [4]의 이전인 [3]으로 옮긴다.
- 시작점은 [0], 끝점은 [3], 중간점은 [1] 이다. 중간점에 위치한 데이터 2는 찾으려는 데이터 4보다 작으므로 이번에는 값이 2 이하인 데이터는 더 이상 확인할 필요가 없다.
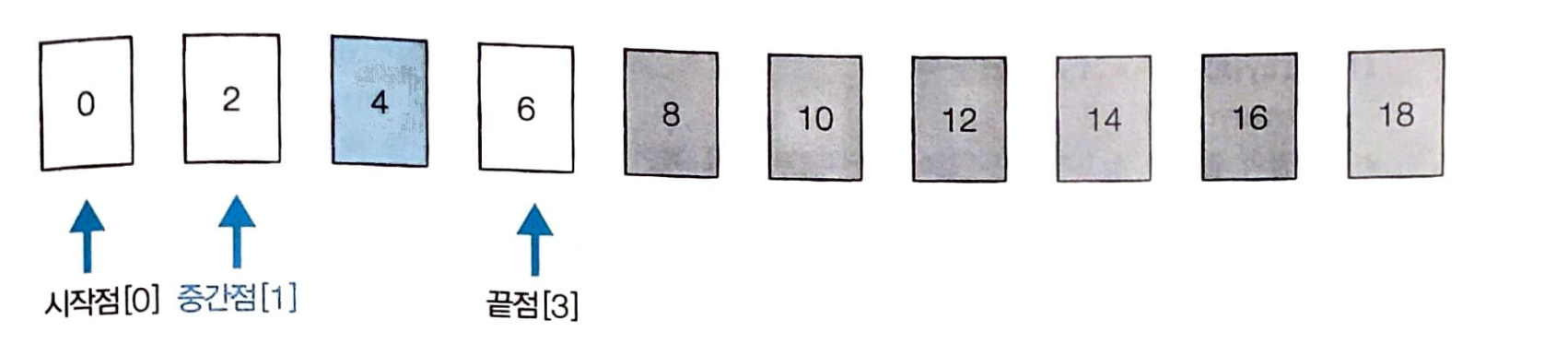
-
시작점을 [2]로 변경한다.
-
시작점은 [2], 끝점은 [3] 이다. 이때 중간점은 [2] 이고 중간점에 위치한 데이터 4는 찾으려는 데이터 4와 동일하므로 이 시점에서 탐색을 종료한다.
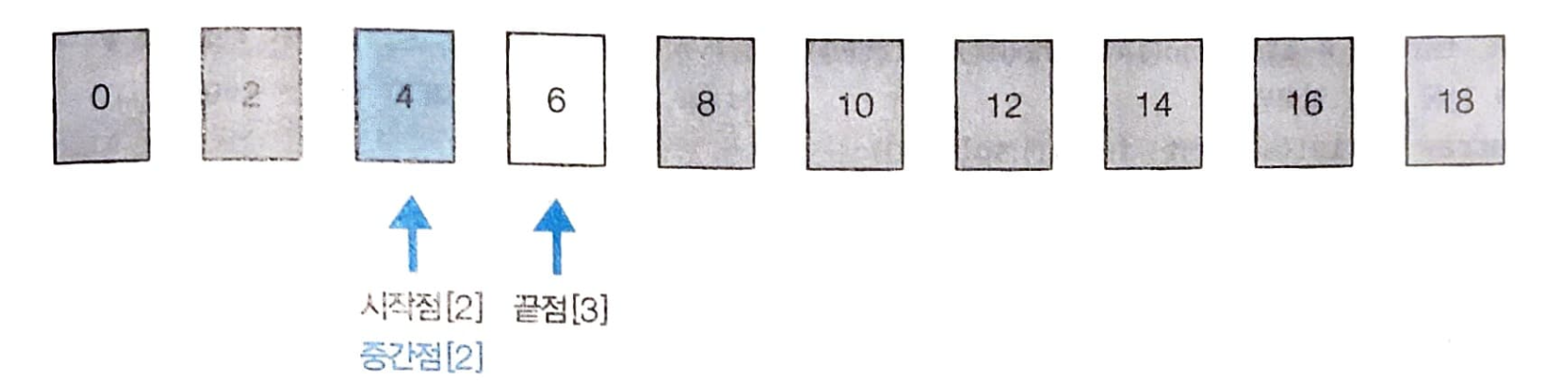
-
전체 데이터의 개수는 10개지만, 이진 탐색을 이용해 총 3번의 탐색으로 원소를 찾을 수 있었다. 이진 탐색은 한 번 확인할 때마다 확인하는 원소의 개수가
절반씩줄어든다는 점에서 시간 복잡도가O(logN)이다. -
이진 탐색을 구현하는 방법에는 2가지가 있다.
-
재귀 함수를 이용하는 방법
-
단순하게 반복문을 이용하는 방법
-
재귀 함수와 반복문을 이용하여 구현한 이진 탐색
재귀 함수 이용으로 구현
# 재귀함수로 이진 탐색 구현
def binary_search(array, target, start,end):
if start > end:
return None
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid] == target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
return binary_search(array,target, start, mid-1)
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
elif array[mid] < target:
return binary_search(array,target, mid+1, end)
# n(원소의 개수)과 target(찾고자 하는 문자열)을 입력받기
n,target = list(map(int,input().split()))
# 전체 원소 입력받기
array = list(map(int,input().split()))
# 이진 탐색 결과 출력
result = binary_search(array,target,0, n-1)
if result == None:
print("원소 존재 안함")
else:
print(result+1)
10 7
1 3 5 7 9 11 13 15 17 19
4반복문으로 구현
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
# 찾은 경우 중간점 인덱스 반환
if array[mid]== target:
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array[mid] > target:
end = mid - 1
# 중간점의 값보다 찾고자 하는 값이 클 경우 오른쪽 확인
elif array[mid] < target:
start = mid + 1
return None
# n(원소의 개수)과 target(찾고자 하는 문자열)을 입력받기
n,target = list(map(int,input().split()))
# 전체 원소 입력받기
array = list(map(int,input().split()))
# 이진 탐색 결과 출력
result = binary_search(array,target,0, n-1)
if result == None:
print("원소 존재 안함")
else:
print(result+1)
10 7
1 3 5 7 9 11 13 15 17 19
4-
단순히 앞의 코드를 보고 이진 탐색이 단순하다고 느낄 수 있지만, 정작 참고할 소스코드가 없는 상태에서 이진 탐색의 소스코드를 구현하는 것은 상당히 어렵다.
-
이진 탐색을 처음 접했다면 자연스럽게 외워보길 바란다. 단골 문제임!!!!!
-
난이도가 높은 문제에는 이진 탐색과 더불어 다른 알고리즘과 결합하여 출제되기도 한다.
-
이진 탐색은 탐색 범위가 큰 상황에서의 탐색을 가정하는 문제가 많다. 따라서 탐색 범위가 2000만을 넘어가면 이진 탐색으로 문제에 접근하자.
트리 자료구조
-
이진 탐색은 전제 조건이 데이터 정렬이다. 예를 들어 동작하는 프로그램에서 데이터를 정렬해두는 경우가 많으므로 이진 탐색을 효과적으로 사용할 수 있다.
-
데이터베이스에서의 탐색은 이진 탐색과는 조금 다르지만, 이진 탐색과 유사한 방법을 이용해 탐색을 항상 바르게 수행하도록 설계되어 있어서 데이터가 많아도 탐색하는 속도가 빠르다
트리 자료구조가 뭔데?
-
노드와 노드의 연결로 표현하며 여기에서 노드는 정보의 단위로서 어떠한 정볼르 가지고 있는 개체로 이해할 수 있다.
-
그래프 자료구조의 일종으로 데이터베이스 시스템이나 파일 시스템과 같은 곳에서 많은 양의 데이터를 관리하기 위한 목적으로 사용한다.
트리 자료구조의 특징
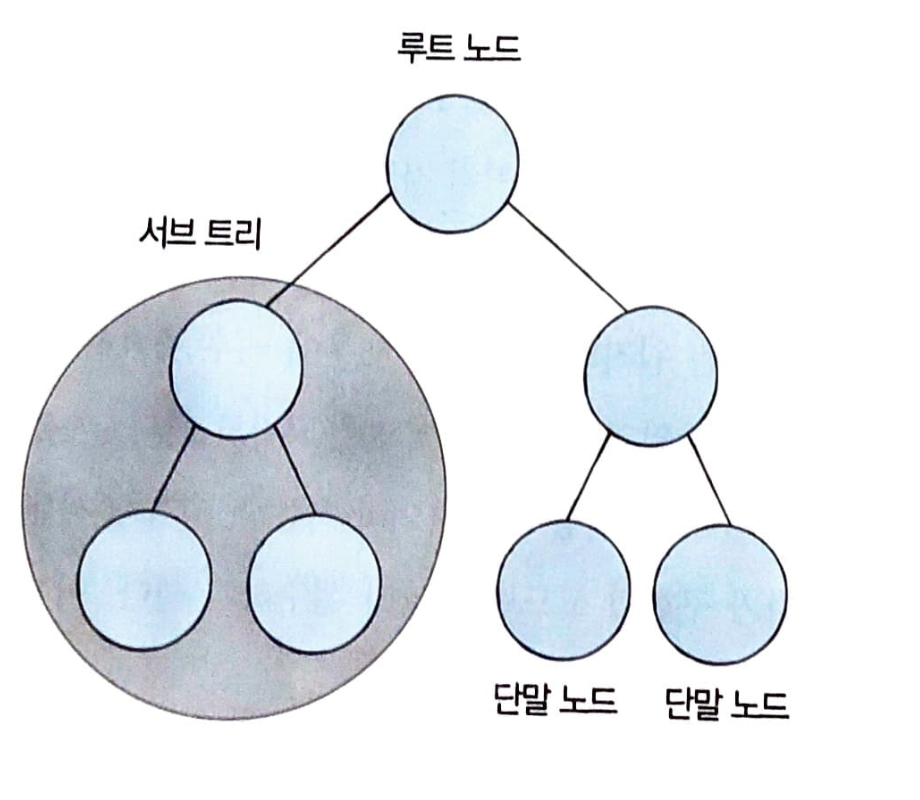
-
트리는
부모 노드와자식 노드의 관계로 표현된다. -
트리의 최상단 노드를
루트 노드라고 한다. -
트리의 최하단 노드를
단말 노드라고 한다. -
트리에서 일부를 떼어내도 트리 구조이며 이를
서브 트리라고 한다. -
트리는 파일 시스템과 같이 계층적이고 정렬된 데이터를 다루기에 적합하다.
- 정리하자면, 대용량의 데이터를 처리하는 소프트웨어는 대부분 데이터를 트리 자료구조로 저장해서
이진 탐색과 같은 탐색 기법을 이용해 빠르게 탐색이 가능하다.
그렇다면, 이런 트리 구조를 이용하면 정확히 어떤 방식으로 항상 이진 탐색이 가능한 걸까?
이진 탐색 트리
- 트리 자료구조 중에서 가장 간단한 형태가 이진 탐색 트리이다.
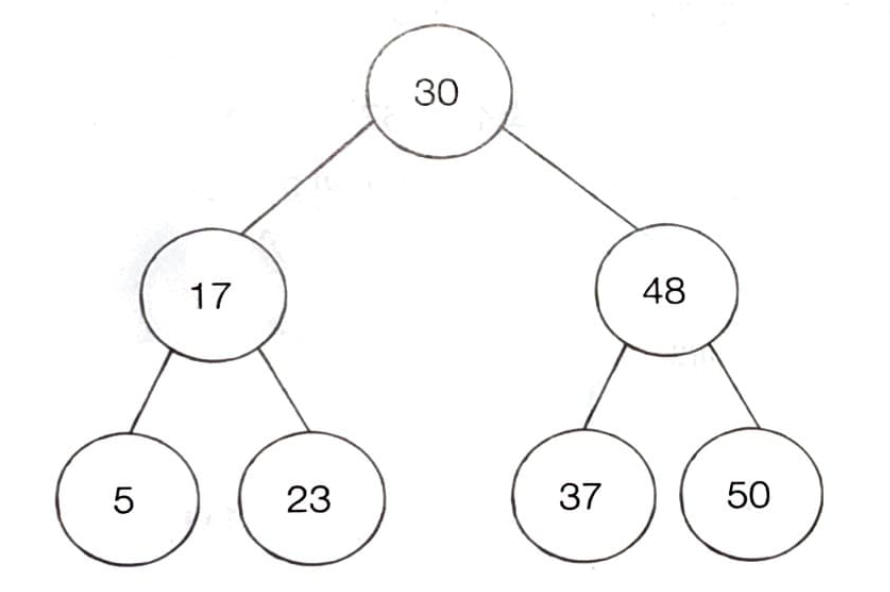
-
보통 이진 탐색 트리는 위의 그림과 같은데, 모든 트리가 다 이진 탐색 트리는 아니며, 이진 탐색 트리는 아래와 같은 특징을 가진다.
- 부모 노드보다 왼쪽 자식 노드가 작다.
- 부모 노드보다 오른쪽 자식 노드가 크다.
-
좀 더 간단하게 표현하면
왼쪽 자식 노드 < 부모 노드 < 오른쪽 자식 노드가 성립해야지 이진 탐색 트리라고 할 수 있다. -
이진 탐색 트리에 데이터를 넣고 빼는 방법은 알고리즘 보다는 자료구조에 가깝다. 이진 탐색 트리 자료구조를 구현하도록 요구하는 문제는 출제 빈도가 낮은편이다.
-
따라서, 이진 탐색 트리가 미리 구현되어 있다고 가정하고 아래의 그림과 같은 이진 탐색 트리에서 데이터를 조회하는 과정만 살펴보자. 다음은 원소가 37일 때 동작하는 과정이다.
이진 탐색 트리 데이터 조회 과정
-
이진 탐색은 루트 노드부터 방문한다. 루트 노드는 30 이고 찾는 원소 값은 37이다. 공식에 따라 부모 노드의 왼쪽 자식 노드는 30 이하 이므로 왼쪽에 있는 모든 노드를 확인할 필요는 없다.
-
따라서, 오른쪽 노드를 방문한다.
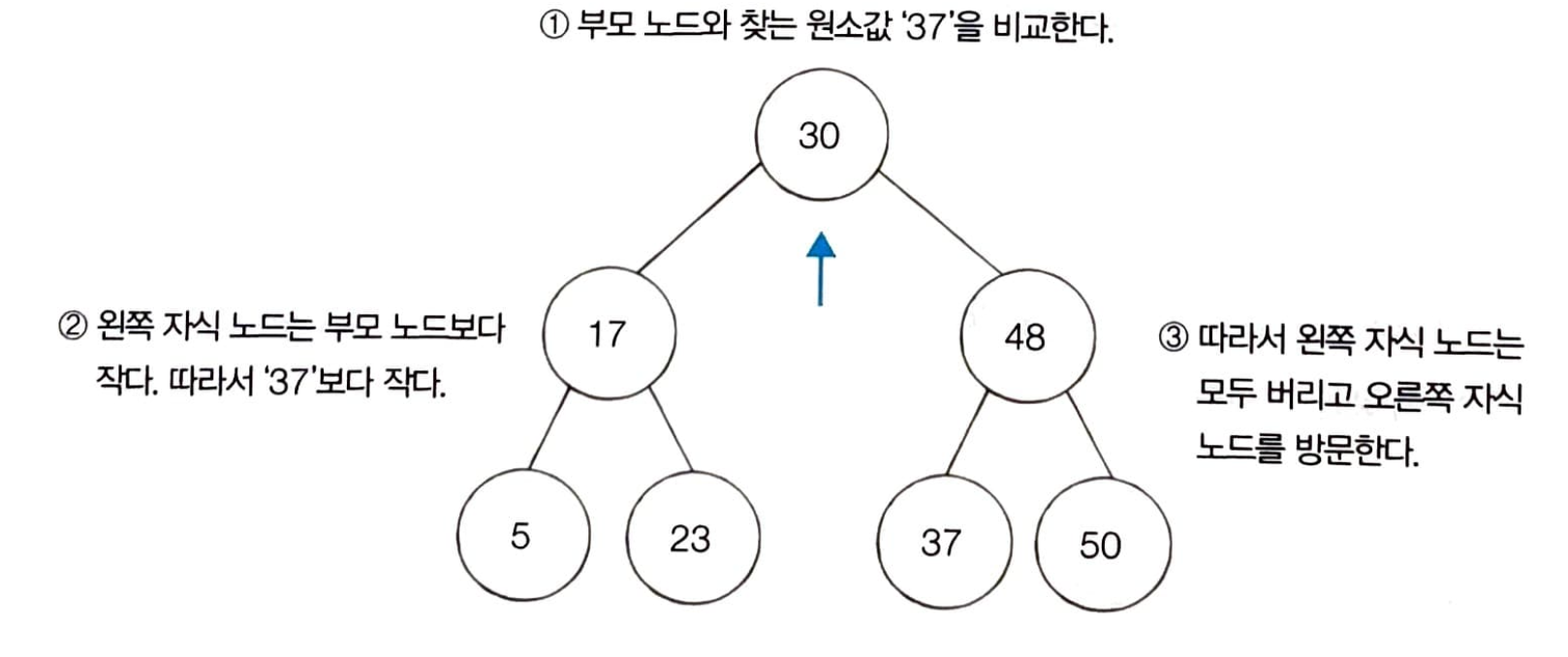
-
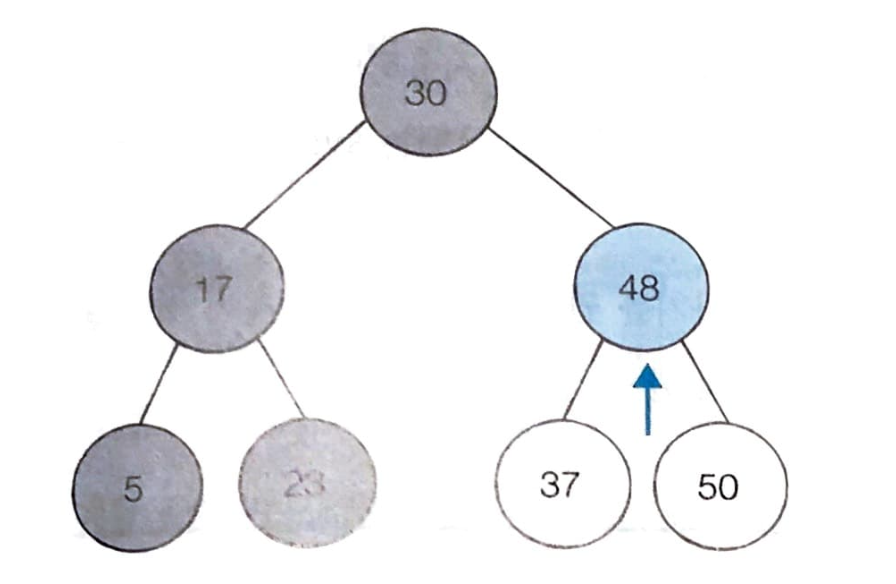
오른쪽 자식 노드인 48이 이번에는 부모 노드가 된다. 48은 찾는 원소값인 37보다 크다. 공식에 따라 부모 노드(48)의 오른쪽 자식 노드는 모두 48 이상이므로 확인할 필요는 없다.
-
따라서, 왼쪽 노드를 방문한다.
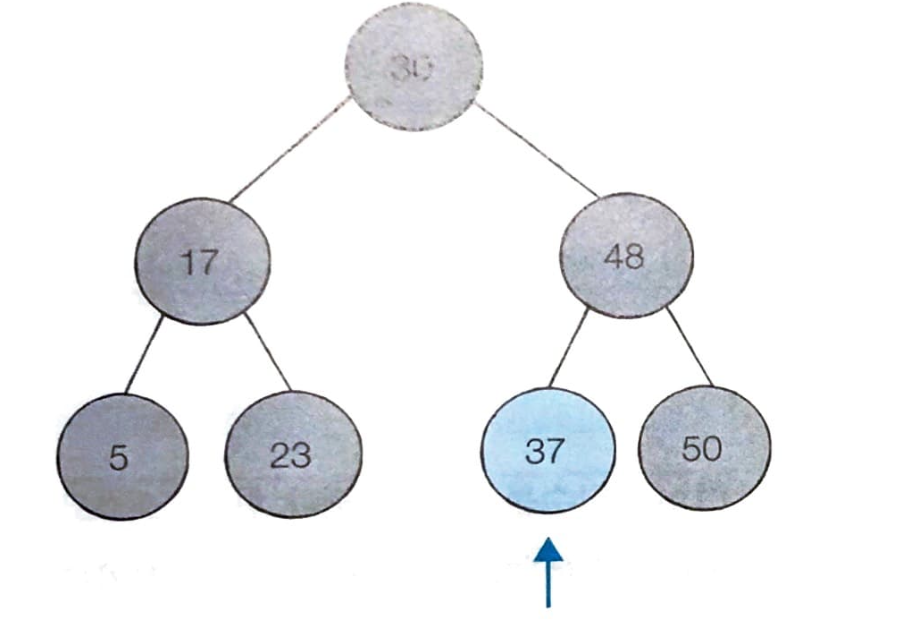
- 현재 방문한 노드의 값인 37과 찾는 원소의 값인 37이 동일하다 따라서 탐색을 종료한다.
빠르게 입력받기
-
이진 탐색 문제는 입력 데이터가 많거나, 탐색 범위가 매우 넓은 편이다. 예를 들어 데이터의 개수가 1000만개를 넘어가거나 탐색 범위의 크기가 1,000억 이상이라면 이진 탐색 알고리즘을 의심해 보자.
-
그런데 이렇게 입력 데이터의 개수가 많은 문제에
input()함수를 사용하면 동작 속도가 느려서 시간 초과가 발생할 수 있다. 이처럼 입력 데이터가 많은 무넺는sys라이브러리의readline()함수를 이용하면 시간 초과를 피할 수 있다.
import sys
# 하나의 문자열 데이터 입력받기
input_data = sys.stdin.readline().rstrip()
# 입력 받은 문자열 그대로 출력
print(input_data)
# rstrip() 함수를 사용할 때
print(len(input_data))
Hello EuiJoo!
Hello EuiJoo!
13-
sys 라이브러리를 사용할 때는 한 줄 입력받고 나서rstrip()함수를 꼭 호출해야 한다. -
소스 코드에
readline()으로 입력하면 입력 후 엔터가줄 바꿈 기호로 입력되는데, 이 공백 문자를 제거하려면rstrip()함수를 사용해야한다. -
만약
rstrip()함수를 사용하지 않았다면 아래의 결과가 나온다.
import sys
input_data = sys.stdin.readline()
print(input_data)
print(len(input_data))
Hello EuiJoo!
Hello EuiJoo!
14- 공백이 하나 생긴걸 알 수 있음!!!!
예제
1. 부품찾기 문제


-
이진 탐색으로 접근
-
이진 탐색은 데이터가 정렬되어 있어야 하므로
sort()함수를 사용하자
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
if array[mid] == target:
return mid
elif array[mid] > target:
end = mid -1
elif array[mid] < target:
start = mid + 1
return None
# 가게에 있는 부품의 개수인 N 입력
N = int(input())
# 가게에 있는 부품
array = list(map(int,input().split()))
# 이진 탐색을 수행하려면 정렬되어 있어야함
array.sort()
# 손님이 입력하는 부품의 개수 M
M = int(input())
# 손님 원하는 부품 번호
array1 = list(map(int,input().split()))
# 부품 하나씩 확인
for i in array1:
result = binary_search(array, i, 0, N-1)
if result != None:
print('yes', end =' ')
else:
print('no', end = ' ')
5
8 3 7 9 2
3
5 7 9
no yes yes이진 탐색 말고도 계수 정렬의 개념을 이용하여 문제를 풀 수 있다.
- 모든 원소의 번호를 포함할 수 있는 크기의 리스트를 만든 뒤에, 리스트의 인덱스에 직접 접근하여 특정한 번호의 부품이 매장에 존재하는지 확인
# N ( 가게 부품 개수) 입력 받기
N = int(input())
array = [0] * 1000000
# 가게에 있는 전체 부품 번호를 입력 받아 기록
for i in input().split():
array[int(i)] = 1 # 인덱스별로 값 입력
# M (손님이 요청한 부품의 개수) 입력 받기
M = int(input())
# 손님이 입력한 부품 번호를 공백으로 구분하여 입력
array1 = list(map(int,input().split()))
# 손님이 확인 요청한 번호 확인
for i in array1:
if array[i] == 1:
print('yes', end = ' ')
else:
print('no', end = ' ')
5
8 3 7 9 2
3
5 7 9
no yes yesset() 함수
- 위의 문제에서 단순히 특정한 수가 한 번이라도 등장했는지를 검사하면 되므로 set() 함수를 이용해서 문제를 해결할 수 있다.
set()함수는 파이썬에서 '집합'을 표현할 때 사용하는 자료형이다. 따라서 단순히 특정한 데이터가 존재하는지 검사할 때에 매우 효과적이다.
# N ( 가게 부품 개수) 입력 받기
N = int(input())
# 가게에 있는 전체 부품 번호를 입력받아서 집합 set()자료형에 기억
array = set(map(int,input().split()))
# M (손님이 요청한 부품의 개수) 입력 받기
M = int(input())
# 손님이 입력한 부품 번호를 공백으로 구분하여 입력
array1 = list(map(int,input().split()))
# 손님이 확인 요청한 번호 확인
for i in array1:
if i in array:
print('yes', end = ' ')
else:
print('no', end = ' ')
5
8 3 7 9 2
3
5 7 9
no yes yes2. 떡볶이 떡 만들기

- 전형적인 이진 탐색 문제이자
파라메트릭 서치유형의 문제이다.
파라메트릭 서치 (Parametric Search)
- 최적화 문제를 결정 문제로 바꾸어 해결하는 기법
- 원하는 조건을 만족하는 가장 알맞는 값을 찾는 문제에 자주 사용됨
- 예를 들어 범위 내에서 조건을 만족하는 가장 큰 값을 찾으라는 최적화 문제라면 이진 탐색으로 결정 문제를 해결하면서 범위를 좁혀갈 수 있다.
문제 해결 방법
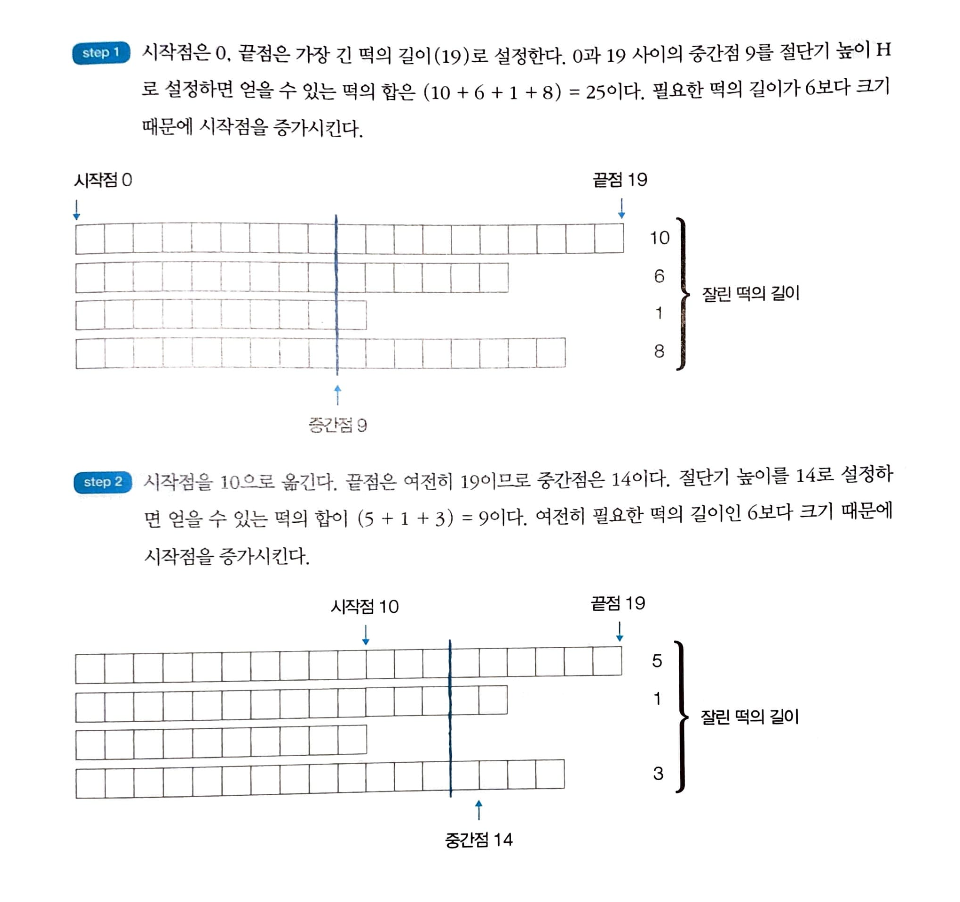
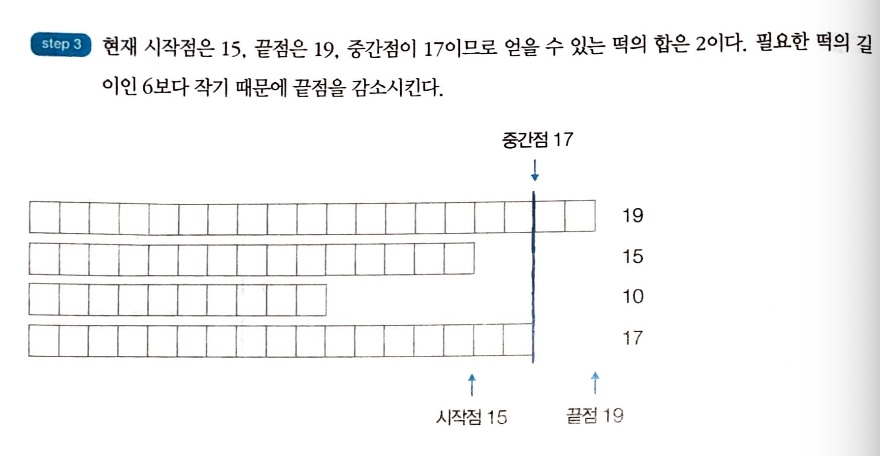
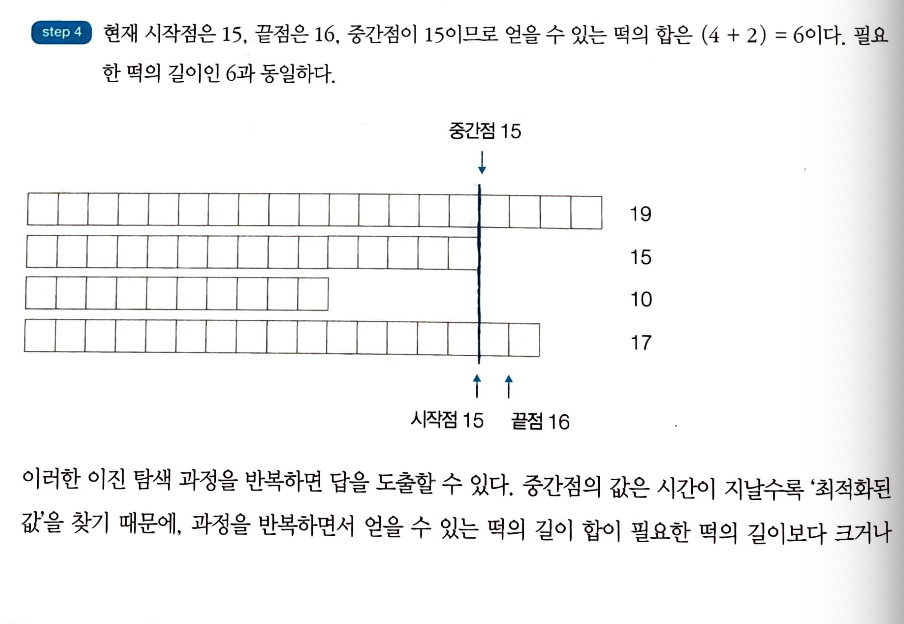
-
이 문제는 현재 얻을 수 있는 떡볶이의 양에 따라서 자를 위치를 결정해야 하기 때문에 이를 재귀적으로 구현하는 것은 귀찮은 작업이 될 수 있다.
-
파라메트릭 서치 문제 유형은 이진 탐색을 재귀적으로 구현하지 않고 반복문을 이용해 구현하면 더 간결하게 문제를 풀 수 있다.
N,M = list(map(int, input().split()))
array = list(map(int,input().split()))
# 이진 탐색을 위한 시작점 끝점 설정
start = 0
end = max(array)
# 반복문을 사용한 이진 탐색 구현
result = 0
while start <= end:
sum = 0
mid = (start + end) // 2
for i in array:
if i > mid:
sum = sum + i - mid
# 떡의 양이 부족한 경우 더 많이 자르기 (왼쪽 부분 탐색)
if sum < M:
# 떡의 양이 많은 경우 덜 자르기 (오른쪽 부분 탐색)
end = mid -1
else:
result = mid
start = mid + 1
print(result)
4 6
19 15 10 17
14참고 자료
서적 : 이것이 코딩 테스트다 with 파이썬
채널 : '동빈나' YouTube Channel
