- 스토리지 기술 및 다중화
- 가용성 향상 기술
스토리지 기술 및 다중화
스토리지 요구사항
단순 데이터 저장 및 접근을 지원하는 장치에서 새로운 기능을 갖춘 장치로 진화하고 있음
- 대용량 및 고속 데이터 처리
- 효율적인 데이터 공유 (공유, 분배, 보안 강화)
- 확장성, 사용성, 유연성
- 다양한 접근 형식
저장되는 곳이 최대한 연속적으로 되어야함
앞에 빈 공간이 생기면 뒤에서 그 자리에 들어갈 데이터를 옮겨옴
(빈 공간 없게 당겨오기)
스토리지 단위
파일
- 데이터 스트림이 파일로 저장되어 폴더로 구조화되는 단위
(애플리케이션에서 저장하는 단위) - 사용자가 사용하게 됨
블록
- 스토리지 하드웨어에 가장 가까운 수준의 최소 데이터 단위
(H/W에서 사용하는 단위) - 저장소를 번호를 부여하며 잘라둠
데이터 세트
- 데이터가 테이블, 단락, 레코드와 같은 형식으로 구성된 단위
오브젝트
- 데이터가 객체 단위로 구조화되는 스토리지
- 데이터 및 메타데이터로 구성된 오브젝트에 고유 ID 부여
스토리지 다중화
- 고성능을 위한 기술
- 단일 디스크로 처리할 수 없는 고용량 데이터를 처리하기 위함
- 디스크를 논리적으로 묶어 서버와 연결하여 사용하는 스토리지 구성 방식
- RAID
- NAS
- SAN
RAID
- 다수의 디스크병렬적으로 구동
- 시스템의 신뢰성 향상
표준 RAID 수준 (기법의 세부 기준들)
RAID 0 수준: 스트라이핑 (거의 안씀)
RAID 1 수준: 미러링 [복제성]
RAID 0 + 1 수준: 스트라이핑 + 미러링
RAID 2 수준: 스트라이핑 + 에러 검출, 정정
RAID 3 수준: 전용 패리티에 의한 스트라이핑
RAID 4 수준: 전용 패리티에 의한 개량된 스트라이핑
RAID 5 수준: 삽입된 패리티로 개량된 스트라이핑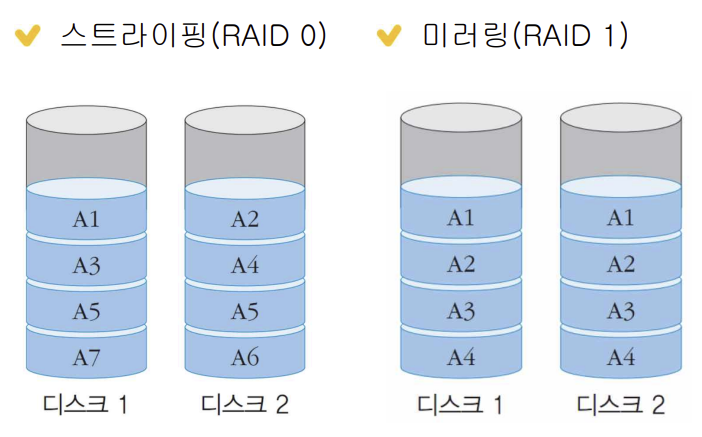
스트라이핑
: 데이터를 여러개의 디스크에 나누어 저장
: 빠르게 데이터를 읽고 쓸 수 있음
: 접근 효율성을 위한 기술 (복구기술 X)
미러링
: 여러 디스크에 데이터를 그대로 복제하여 저장
: 신뢰성 확보
: 손실이 발생했을 때 복구하기 위함
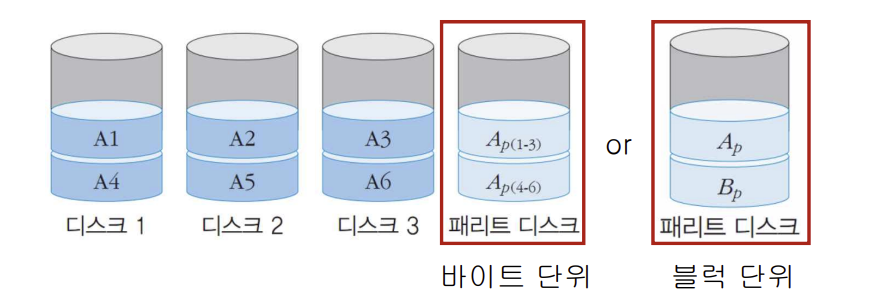
패리티
: 에러 검출 및 정정을 위한 별도의 디스크
: 바이트 단위(RAID 3) or 블록 단위(RAID 4)
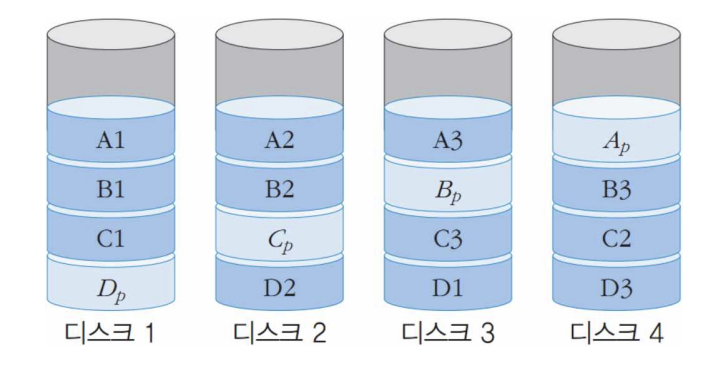
RAID 5: 패리티를 모든 디스크에 분산하여 저장
RAID의 기능
-
중복된 데이터의 분산 저장
- 중복 저장된 데이터를 기반으로 디스크 장애 발생시 손실된 데이터 복구 가능
- 미러링: 쓰기 연산 발생 시 분산되어 있는 모든 물리디스크에 기록됨 -
성능 향상
- 읽기 요청이 다수의 디스크가 나누어 처리함으로써 읽기 속도 향상
- 병렬성 향상
NAS
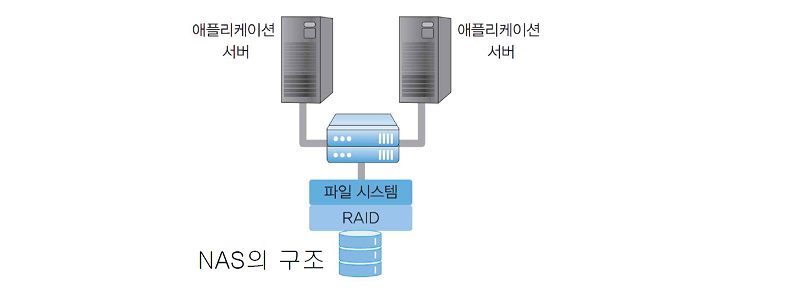
- 스위치를 통해 데이터를 송수신하는 저장장치
파일 시스템이 저장공간 위에 위치함 =종속성- 중계 역할을 하는 전용 파일 서버가 필요함
- 전용 파일 서버에서 파일의 일관성 및 무결성을 유지하며 여러 서버에서 공유 가능 =
안정성 - 대량의 I/O가 발생할 경우 지연율이 증가하여 DB와 같은 서비스에는 부적합
파일 시스템 : 포멧 시 파일 형식 지정 가능
SAN
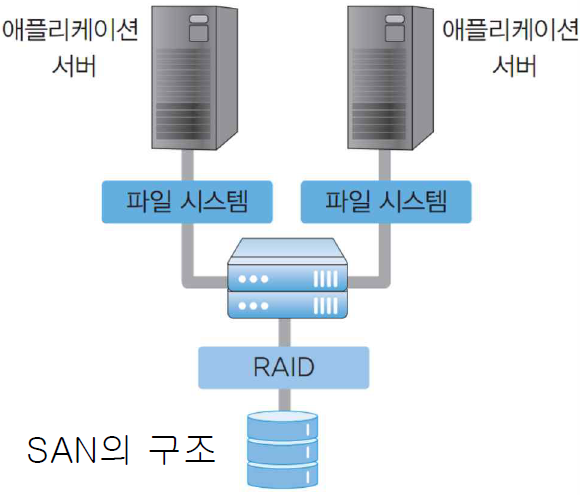
- 여러 종류의 데이터 저장 장치와 데이터를 사용할 서버를 파이버 채널을 사용하여 파이버 채널 스위치로 연결한 고속 데이터 네트워크
파일 시스템이 각 애플리케이션마다 다름 -독립성- 고속의 I/O 채널 제공
- NAS보다 빠름
- 이기종 서버 환경 미지원
스토리지 가상화
- RAID, NAS, SAN의 수백 수천개의 디스크를 관리하고 유지하는 데 많은 인력과 비요 요구
- 물리적 스토리지 시스템과 서버 사이에 스토리지 가상화 소프트웨어 층 추가
- 애플리케이션 구동 시 필요한 데이터의 위치에 대한 드라이브, 파티션, 스토리지를 인식하지 않아도 사용 가능
- 이기종 디바이스의 특징 고려할 필요 없이 단일 스토리지 계층으로 그룹화하여 운용
구조
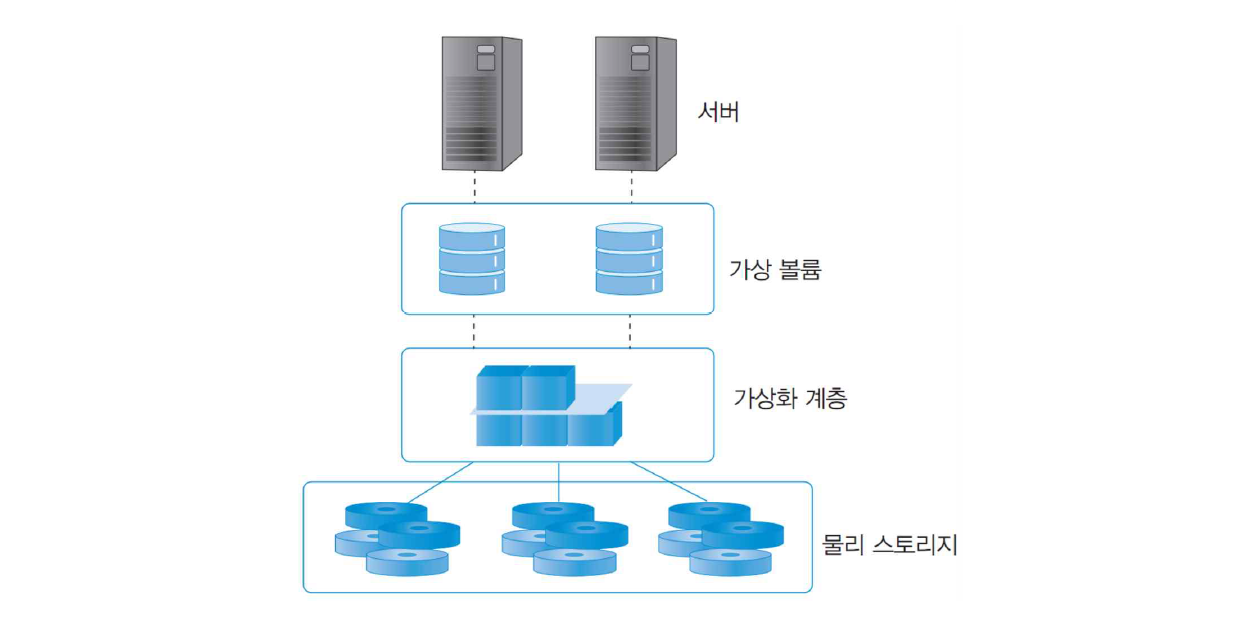
- 여러 스토리지 디바이스를 단일 리소스로 인식하고 프로비저닝
- 가용성 확보 및 무중단 서비스 가능
장점
-
스토리지 활용률
: 요구에 따라 디스크 단편화로 불용되는 스토리지 공간 최소화 -
I/O 성능
: RAID와 같은 복수의 스토리지 디바이스를 병렬적으로 동작 가능 -
가용성
: 동일 데이터 미러링 복제하여 데이터 손실 방지,무중단디스크 교체 가능
: 단, 결함이 있거나 업그레이드, 이전 시에는 서버 꺼짐 -
관리 용이성
: 불필요한 스토리지 디바이스의 확장을 방지
: 복수 개의 스토리지 디바이스를 하나의 가상화 스토리지로 통합 및 관리 자동화
데이터 센터: 관리하기 편함
사용자: 요구하는 만큼만 사용 가능
가용성
- 시스템을 계속하여 가동시킬 수 있는 능력
- 시스템에서 안정적으로 돌아갈 수 있게 하는 방법 ->
사전 처리&사후 처리- 가용성 향상을 위해 다중화 기술 요구
중단되지 않게 하기위해 필요한 기능
: 똑같은 서비스 계속 제공되도록
-
전처리
로드 밸런싱: 여러 개의 같은 서버가 있을 때 한 곳에만 몰리지 않도록 분산시키는 기술 -
후처리
자동 저장 기능
다중화
- 장애 발생 시 즉시 예비 장비로 페일옵버하여 시스템이 연속적으로 기능할 수 있도록 하는 기술 (전처리)
예비 장치
: 항상 켜두는 예비 장치: 미러 서버 (전처리)
: set up만 시켜두고 켜두지는 않는 예비 장치 (후처리)
다중화 대상
: 서버, 로드 밸런서, 네트워크 장치
로드 밸런서
: 분배 작업 담당
: 가동이 중단되면 병목현상 발생하여 셧다운 발생
: A, B, C 서버가 있을 때 A가 다운되면 그 사용자가 B, C로 이동되고 B, C도 병목현상으로 결국 다운
네트워크 장치
: 외부 네트워크로 나갈 수 있는 회선을 여러개 둠
: 평소에 쓰던 회선이 문제가 발생하면 다른 회선 사용
구성
-
핫 스탠바이
: 백업 장비 측이 가동 후 즉시 이용 가능한 구성
: 항상 ON 상태 -
웜 스탠바이
: 백업 장비 측이 가동 후 이용 가능한 상태가 되기까지 일정 부분 준비가 필요한 구성
: 세팅은 다 되어있고 네트워크 연결은 안되어있는 상태
: 완전한 예비 형태
: 완전히 OFF 되어있는 상태는 아님
: 실제 운용을 위한 마지막 단계만 안되어 있는 상태 -
콜드 스탠바이
: 백업 장비 측을 정지시켜 두는 구성
: 항상 OFF
헬스 체크
- 감시 대상인 H/W 혹은 S/W가 정상 상태에 있는지 일정 간격으로 어떤 응답 요청을 보내서 응답이 돌아오는지 정상 가동 판단
- Ping 프로토콜을 통해 신호 전달 여부 확인 가능
- 네이버 같은 서버는 접근 막아놔서 Ping 사용 못함
- 추가적으로 응답 도착 속도로 딜레이 수치를 얻을 수 있음
- 빈 패킷을 보냄
- 빈 패킷이어도 헤더(주소)는 있음
- 하트비트와 같은 기능
- 헬스체크 실패 시 관리자에게 보고
HeartBeat: 살아있는지만 확인
모니터링
: 서버의 상태정보를 얻기 위함
: 서버를 안정적으로 운용하기 위한 가장 기본적인 수단
: 상태 정보를 보내달라는 메세지가 들어있는 패킷을 보냄
: 가용한 자원에 대한 크기를 알 수 있음
: 서버 하나만 있을 때는 필요 없음
: 로드 밸런서가 필수적으로 관리
로드 밸런싱
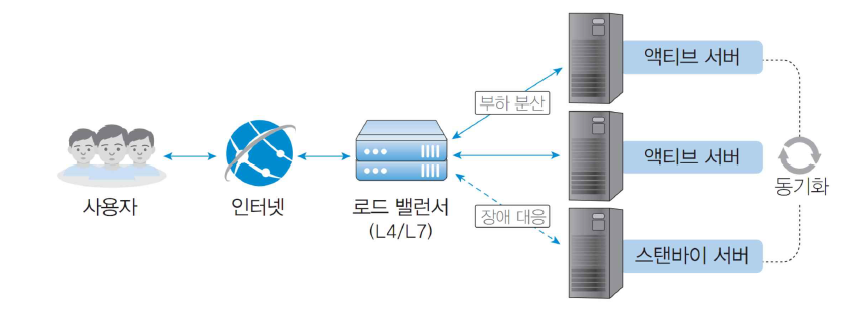
- 단순하지만 필요한 기능
- 로드 밸런서 하위에 있는 서버는 모두 미러 서버
- 하위 서버 모두 동일하게 처리할 능력을 가지고 있어야 함
- 그러므로 주기적으로 동기화 작업을 진행하여야 함
로드 밸런서
- LAN의 최상단에 로드 밸런서가 위치함
- 네트워크를 타고 들어오는 모든것은 로드 밸런서를 거침
- 가장 부하가 많이 걸리는 부분
- Status 모니터링을 계속 해주고 있어야 함
- 바쁜지 확인하기 위함
오토 스케일
- 스케일을 자동으로 변환시켜 줌
- 어떠한 서비스를 운용하고 있는데 요구량이 증가하여 가용률을 넘어설것 같으면 늘려줌
- 사용자에게 보고하고 늘리게되면 중단이 발생하므로 자동적으로 처리
- CPU, 메모리, 네트워크 등 특정 IT 리소스마다 임곗값을 부여
- 오버되는 것은 문제가 발생하기 때문에 로드 밸런서가 추가 채킹을 진행하여 부하(임곗값에 가까운지)가 발생하는지 검사
- 클라우드에서는 연산, 스토리지 두가지 목적이 있는데 스토리지 목적에서는 필요가 없음
- 연산 목적에서는 손실이 발생 할 수 있어서 필요함
- 작업에 따라 부족한 리소스 종류가 다름
- 연산 파워 -> CPU / 저장공간 -> 메모리 / 네트워크 -> 대역폭 변화
